




 项目数据量增大使Mongo数据库压力增加,为进一步优化系统采用读写分离。介绍了Java端采用副本集部署方式进行读写分离的XML配置,支持五种read preference模式,还阐述了Mongo的三种集群方式,包括副本集、主从和分片集群。
项目数据量增大使Mongo数据库压力增加,为进一步优化系统采用读写分离。介绍了Java端采用副本集部署方式进行读写分离的XML配置,支持五种read preference模式,还阐述了Mongo的三种集群方式,包括副本集、主从和分片集群。
背景
最近项目数据量越来越大,导致mongo的数据库压力也越来越大。在结构优化、索引优化之后,为了进一步优化系统,想到读写分离。
java端配置读写分离
这里,mongo采用的是副本集(Replica Set)的部署方式
这里采用的事xml配置文件形式:
read-preference=“SECONDARY_PREFERRED”,这个配置
<!--读写分离详细说明:
mongodb复制集对读写分离的支持是通过Read Preferences特性进行支持的,这个特性非常复杂和灵活。
应用程序驱动通过read reference来设定如何对复制集进行读写操作,默认客户端驱动所有的读操作都是直接访问primary节点的,从而保证了数据的严格一致性。
支持五种 read preference模式:
1.primary:主节点,默认模式,读操作只在主节点,如果主节点不可用,报错或者抛出异常。
2.primaryPreferred:首选主节点,大多情况下读操作在主节点,如果主节点不可用,如故障转移,读操作在从节点。
3.secondary:从节点,读操作只在从节点,如果从节点不可用,报错或者抛出异常。
4.secondaryPreferred:首选从节点,大多情况下读操作在从节点,特殊情况(如单主节点架构)读操作在主节点。
5.nearest:最邻近节点,读操作在最邻近的成员,可能是主节点或者从节点,关于最邻近的成员请参考。-->
<mongo:mongo-client id="mongo" replica-set="${mongo.replicationSet}">
<mongo:client-options
write-concern="NORMAL"
connections-per-host="${mongo.connectionsPerHost}"
threads-allowed-to-block-for-connection-multiplier="${mongo.threadsAllowedToBlockForConnectionMultiplier}"
connect-timeout="${mongo.connectTimeout}"
read-preference="SECONDARY_PREFERRED"
max-wait-time="${mongo.maxWaitTime}"
socket-keep-alive="${mongo.socketKeepAlive}"
socket-timeout="${mongo.socketTimeout}"
/>
</mongo:mongo-client>
支持五种 read preference模式:
1.primary:主节点,默认模式,读操作只在主节点,如果主节点不可用,报错或者抛出异常。
2.primaryPreferred:首选主节点,大多情况下读操作在主节点,如果主节点不可用,如故障转移,读操作在从节点。
3.secondary:从节点,读操作只在从节点,如果从节点不可用,报错或者抛出异常。
4.secondaryPreferred:首选从节点,大多情况下读操作在从节点,特殊情况(如单主节点架构)读操作在主节点。
5.nearest:最邻近节点,读操作在最邻近的成员,可能是主节点或者从节点,关于最邻近的成员请参考。
mongo的集群方式有三种:
- 1、副本集(Replica Set)
其实简单来说就是集群当中包含了多份数据,保证主节点挂掉了,备节点能继续提供数据服务,提供的前提就是数据需要和主节点一致
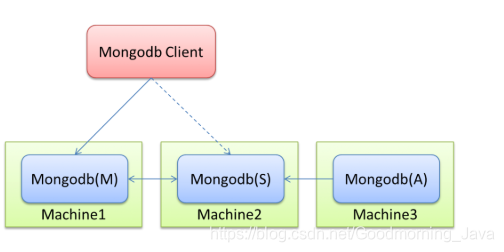
- 2、Master-Slaver(主从)
也就是主备,官方已经不推荐使用。 - 3、Sharding(分片集群)
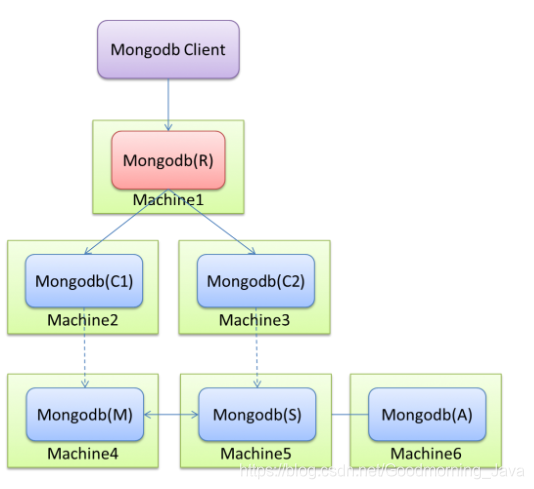

















 603
603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









