



聚簇索引、非聚簇索引、覆盖索引
本篇将带你搞懂什么是聚簇索引、非聚簇索引、覆盖索引,并且通过画图的方式了解索引查找的过程,明白什么是回表查询
索引(Index)是数据库中一种用于快速查找和访问表中数据的结构,它类似于书的目录,通过索引可以快速定位到目标数据,而无需遍历整个表,索引的存在可以显著提高查询速度,尤其是在处理大量数据时
MySQL中默认使用索引的数据结构是B+树,详细可以参考:MySQL索引为什么是B+数-优快云博客
那什么又是聚簇索引、非聚簇索引、覆盖索引?
聚簇索引
聚簇索引也叫聚集索引,是一种将数据行的物理存储顺序与索引的逻辑顺序相同的索引,换句话说,数据是直接存储在索引的叶子节点中,通过主键查找到某一行数据,这一行数据的全部内容都存放在这个叶子节点中,聚簇索引必须有,而且只能有一个
以下面这个表为例:
| id | name | username | age |
|---|---|---|---|
| 1001 | 张三 | zhangsan | 20 |
| 1002 | 李四 | lisi | 18 |
| 1003 | 王九 | wangjiu | 35 |
| 1004 | 赵六 | zhaoliu | 22 |
| 1005 | 王八 | wangba | 17 |
| 1006 | 李白 | libai | 40 |
| 1007 | 杜甫 | dufu | 33 |
| … | … | … | … |
以主键id来为其生成一个简单的B+树索引为:
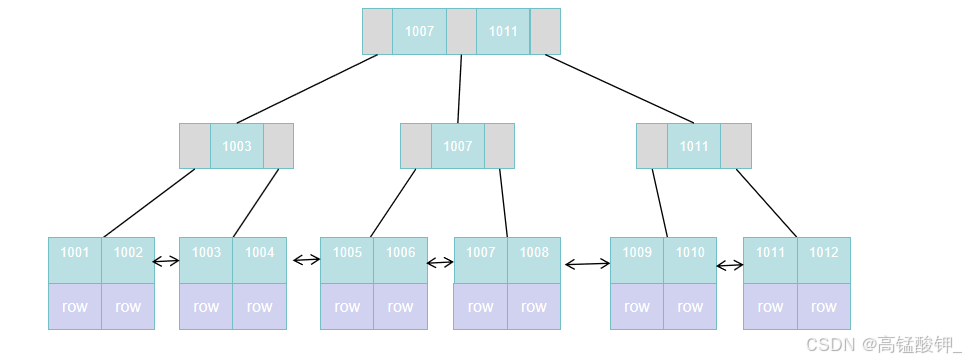
这个利用主键字段来生成的索引就是一个聚簇索引,当我们通过id查找某一个用户时,通过查找算法,找到了他所在的叶子节点,那么在这个叶子节点中,就存放了该用户的整行数据,包括姓名、账号、年龄:
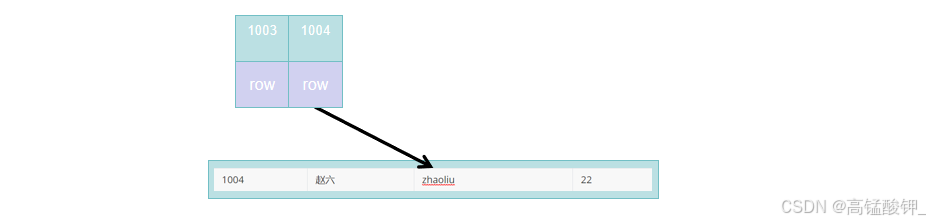
如果定义了主键,MySQL会自动将主键列作为聚簇索引;如果没有主键,MySQL会选择一个唯一非空索引;如果没有唯一索引,MySQL会生成一个隐藏的rowid作为主键来生成聚簇索引
非聚簇索引
相比于聚簇索引,非聚簇索引也叫二级索引,它的叶子节点存储的是索引列的值以及指向实际数据行的指针(或主键值),而不是完整的数据行,也就是说,非聚簇索引的叶子节点中,存放的不再是整行数据,而是该行数据的主键
当我们为上表建立索引时,使用的不是id,而是username:
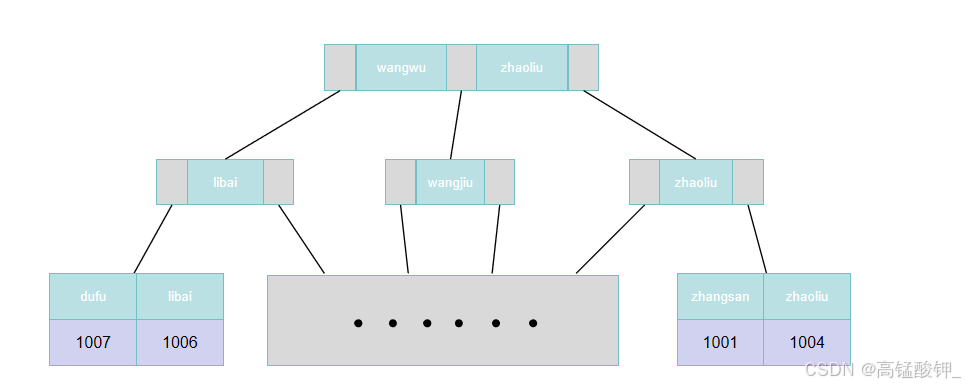
默认会使用字母顺序来进行排序,但是其叶子节点中存储的不再是整行数据,而是该行数据的索引值
回表查询
回表查询是数据库查询中的一个术语,指的是在使用非聚簇索引(或普通索引)时,数据库查询引擎需要通过索引查找到对应的行号(或主键值),然后再回到表中查找完整的行数据的过程
以上表为例,我们想要查询username为zhaoliu的用户全部信息:
select * from user where username = 'zhaoliu'
1.此时回先到username的非聚簇索引中去查找
通过username的比对查找,找到了zhaoliu所在的叶子节点,但是叶子节点中并没有我们需要的全部用户信息,只有该用户的主键值id
2.这时就会拿着id去聚簇索引中比对查找
找到该用户的叶子节点,再把叶子节点中的整行数据返回
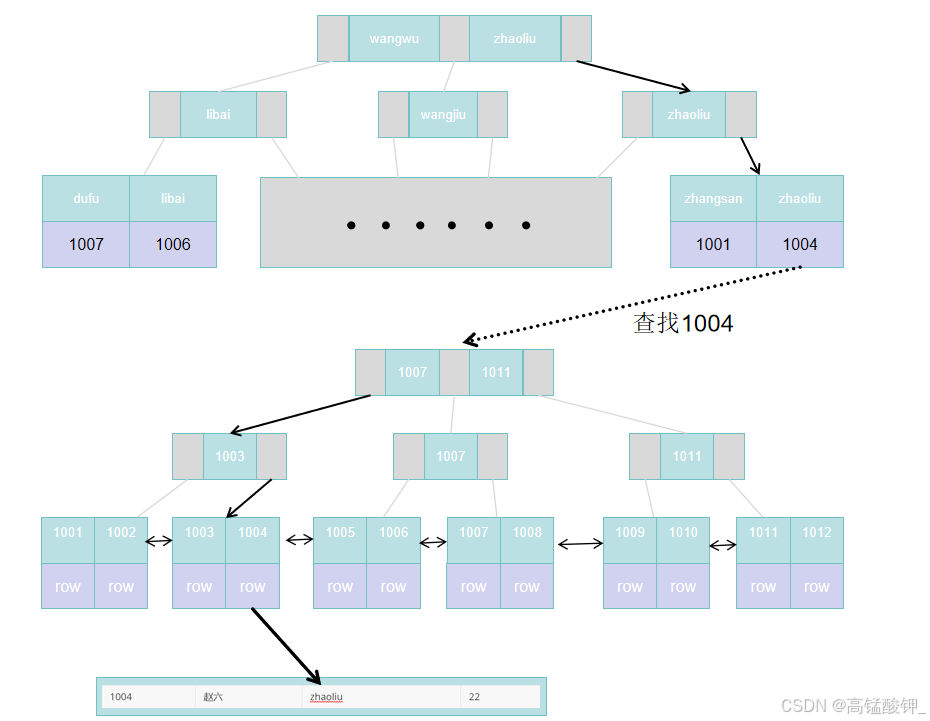
回表查询增加了 I/O 操作,尤其是表数据量大时会显著降低性能,所以我们在设计索引时,尽量要避免出现回表查询
当查询的字段较少且频率较高时,建议使用覆盖索引优化查询
覆盖索引
覆盖索引(Covering Index) 是一种索引优化技术,指的是查询所需的所有字段都可以直接从索引中获取,无需再回表查询。这种方式可以显著提高查询性能,因为避免了回表操作
也就是说,当我们建立索引时,不再使用单一字段来建立索引,而是包含多个字段,这样在利用索引进行查询信息时,叶子节点中可以包含全部的所需数据,不必再到其他索引中查询,因此可以避免回表查询
比如之前以username建立的索引,如果我们不查询用户的全部数据,而是只需要返回username和id:
select id,name from user where name = 'zhangsan'
以username建立的索引中已经包含了想要的全部数据:username和id,因此不需要再去查询其他的索引,这就是覆盖索引
在建立索引时,可以设置多字段建立索引:
CREATE INDEX idx_name_age ON users(name, age)
这样索引的叶子节点中就存放了更多的数据
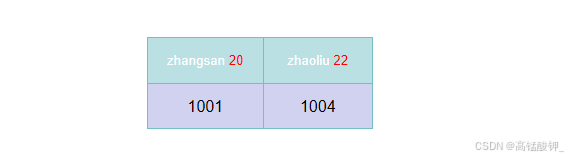
当我们查询所需要的信息name 和 age时,索引 idx_name_age 包含 name 和 age,因此查询所需的字段完全覆盖,无需回表
SELECT name, age FROM users WHERE name = 'John'
但是覆盖索引也有一些弊端
- 增加存储开销
- 索引存储需要额外空间,字段越多,索引越大。
- 写性能受影响
- 插入、更新、删除操作需要同时更新覆盖索引,导致写入开销增加。
- 适用场景有限
- 覆盖索引适用于查询固定字段的场景,但无法应对动态字段需求。

















 2971
2971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









