



学习率衰减策略
学习率衰减策略,是在训练过程中动态改变学习率本身的一种方法,与AdaGrad等调整学习率的方法不同的是:
学习率衰减策略是同一参数不同时刻的改变(改变本身)
自适应优化算法是不同参数的改变(本身不变,通过历史梯度的累加改变计算结果)
常见的衰减策略
等间隔学习率衰减
在固定的训练轮次间隔降低学习率
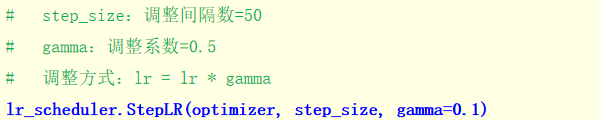
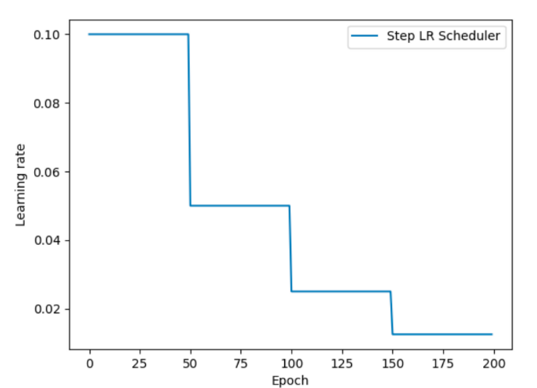
指定间隔学习率衰减
在不同训练阶段设置不同的衰减间隔

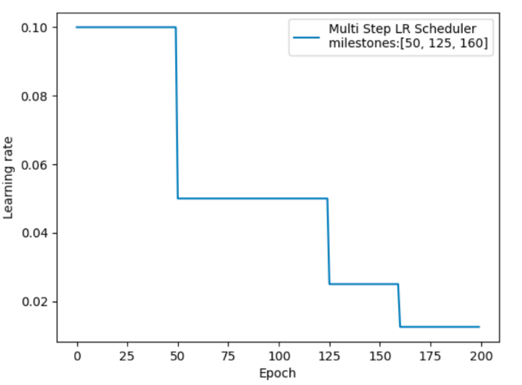
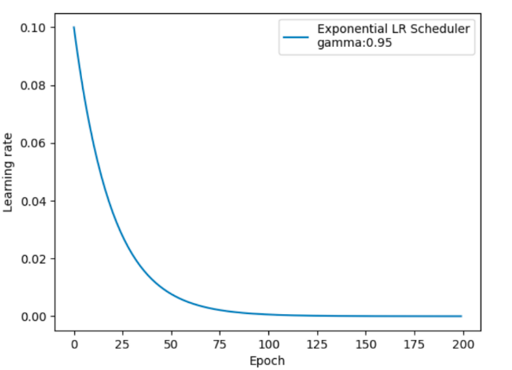
按指数学习率衰减
每个训练轮次都按指数规律衰减

代码演示
import torch
import torch.optim as optim
import matplotlib.pyplot as plt
x=torch.tensor([1.0],dtype=torch.float)
y_true=torch.tensor([2.1],dtype=torch.float)
w=torch.tensor([0.2],requires_grad=True,dtype=torch.float)
optimizer=optim.SGD([w],lr=0.01,momentum=0.9)
#不同策略参考上面贴下来就行
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.5)
epochs, iteration = 200, 10
lr_list, epoch_list = [], []
for epoch in range(epochs): # epoch: 0 ~ 199
# 获取当前轮数 和 学习率, 并保存到列表中.
epoch_list.append(epoch)
lr_list.append(scheduler.get_last_lr()) # 获取最后的lr(learning rate, 学习率)
# 循环遍历, 每轮每批次进行训练.
for batch in range(iteration):
# 先计算预测值, 然后基于损失函数计算损失.
y_pred = w * x
# 计算损失, 最小二乘法.
loss = (y_pred - y_true) ** 2
# 梯度清零 + 反向传播 + 优化器更新参数.
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 更新学习率.
scheduler.step()
print(f'lr_list: {lr_list}') # [0.1, 0.1, 0.1..., 0.05........,0.025........., 0.0125...]
# 可视化.
# x轴: 训练的轮数, y轴: 每轮训练用的学习率
plt.plot(epoch_list, lr_list)
plt.xlabel('Epoch')
plt.ylabel('Learning Rate')
plt.show()
小结
-
调度器初始化:基于优化器实例创建学习率调度器
-
更新时机:在每个训练轮次(epoch)后调用
scheduler.step() -
获取学习率:使用
scheduler.get_last_lr()查看当前学习率 -
策略选择:
-
StepLR:等间隔衰减,简单稳定 -
MultiStepLR:多阶段衰减,更灵活 -
ExponentialLR:平滑衰减,训练过程更稳定
-
这样的学习率衰减策略能够帮助模型在训练初期快速收敛,在后期精细调优,获得更好的性能表现。


















 37万+
37万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









