








 超级会员免费看
超级会员免费看


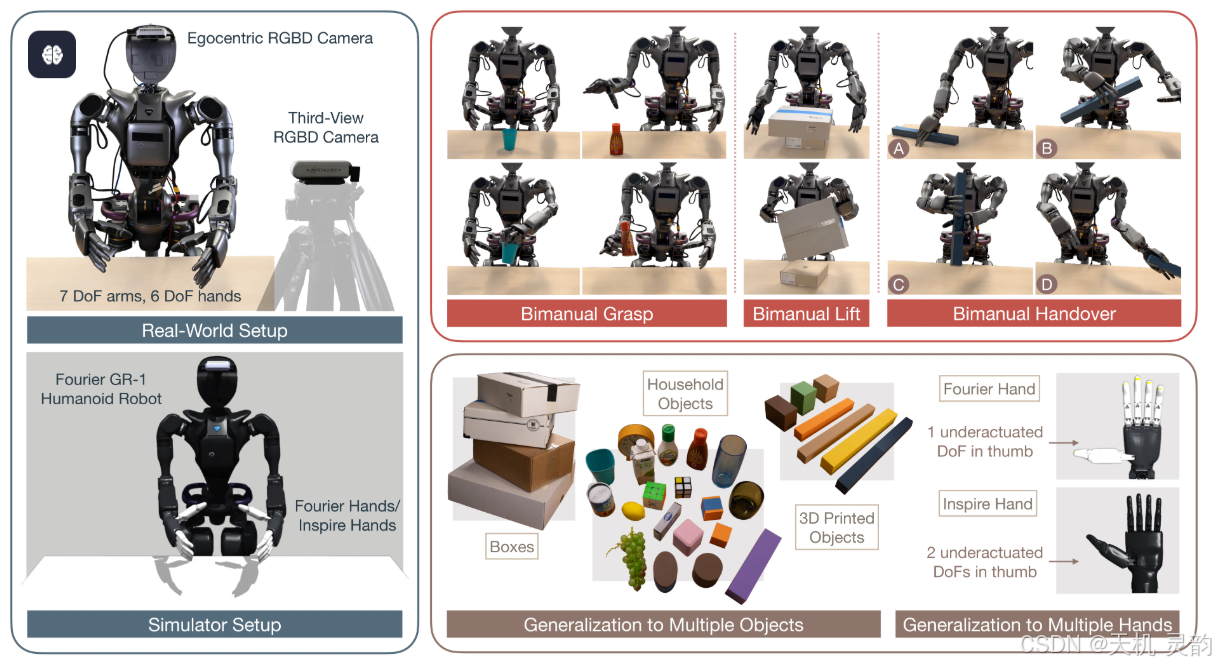
文章 《Sim-to-Real Reinforcement Learning for Vision-Based Dexterous Manipulation on Humanoids》 的核心内容可总结如下:
研究目标
提出一种基于仿真到现实(Sim-to-Real)强化学习(RL)的框架,使 人形机器人 通过视觉输入实现灵巧操作任务 (如双手机械抓取、提升、传递等),并解决真实场景中数据稀缺、安全性及泛化能力的挑战。
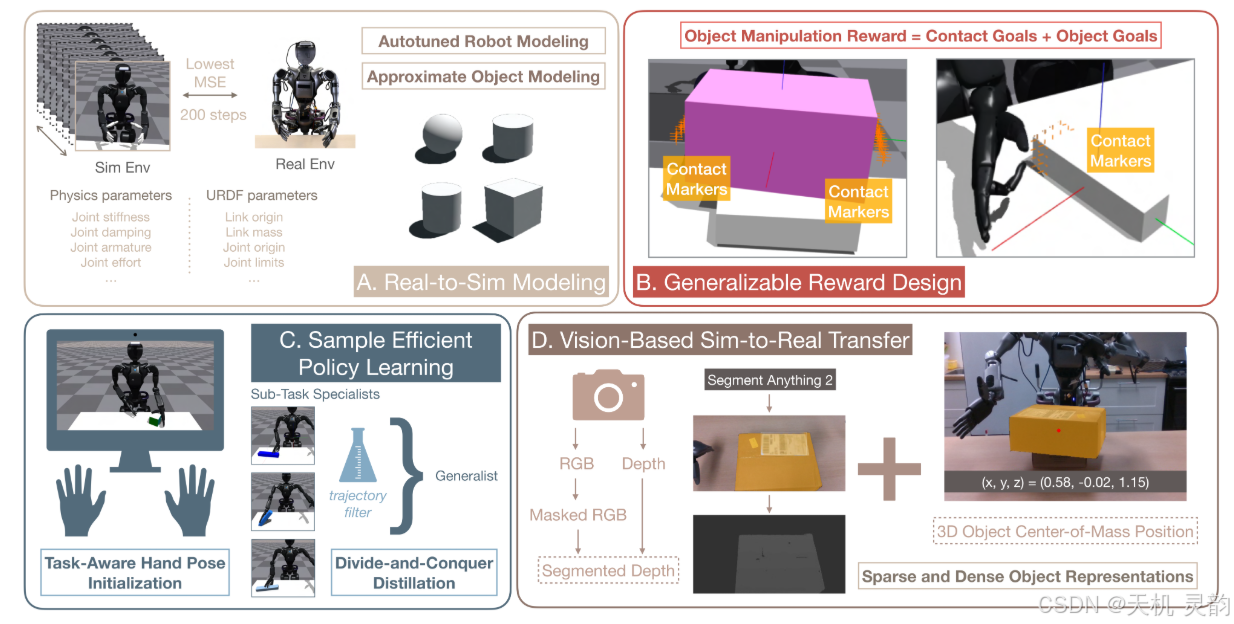
方法与技术亮点
-
视觉驱动的强化学习 采用摄像头图像作为唯一输入 ,避免依赖精确的物体姿态或触觉传感器。
- 通过对比学习 增强视觉表征的鲁棒性,适应不同光照和背景干扰。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 257
257

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











