




 本文介绍了一个使用Python和requests库实现的豆瓣图片爬虫。通过解析JSON数据,爬虫可以抓取与关键词“周星驰”相关的图片,并将其保存到本地。文章详细展示了代码实现过程,包括如何发送HTTP请求、解析返回的JSON数据以及下载图片。
本文介绍了一个使用Python和requests库实现的豆瓣图片爬虫。通过解析JSON数据,爬虫可以抓取与关键词“周星驰”相关的图片,并将其保存到本地。文章详细展示了代码实现过程,包括如何发送HTTP请求、解析返回的JSON数据以及下载图片。
效果演示
废话不多说,先看下代码和效果
代码
# coding:utf-8
import requests
import json
def download(src,id):
dir = './'+str(id)+'.jpg'
try:
pic = requests.get(src,timeout=10)
except requests.exceptions.ConnectionError:
print('timeout error')
fp= open(dir,'wb')
#write
fp.write(pic.content)
#close
fp.close()
query ='周星驰'
for i in range(0,38958,20):
url = 'https://www.douban.com/j/search_photo?q='+query+'&limit=20&start='+str(i)# open
html = requests.get(url).text# get
response = json.loads(html,encoding='utf-8')
for image in response['images']:
print(image['src'])# 测试路径
download(image['src'],image['id'])
效果
星爷当年如此帅气

爬虫流程
打开网页
首先打开豆瓣官网,输入关键词‘周星驰’进行搜索,结果出来后,我们选择图片选项,注意选择图片前要打开chrome的开发者工具,然后我们可以活动请求的链接地址了
https://www.douban.com/j/search_photo?q=周星驰&limit=20&start=0
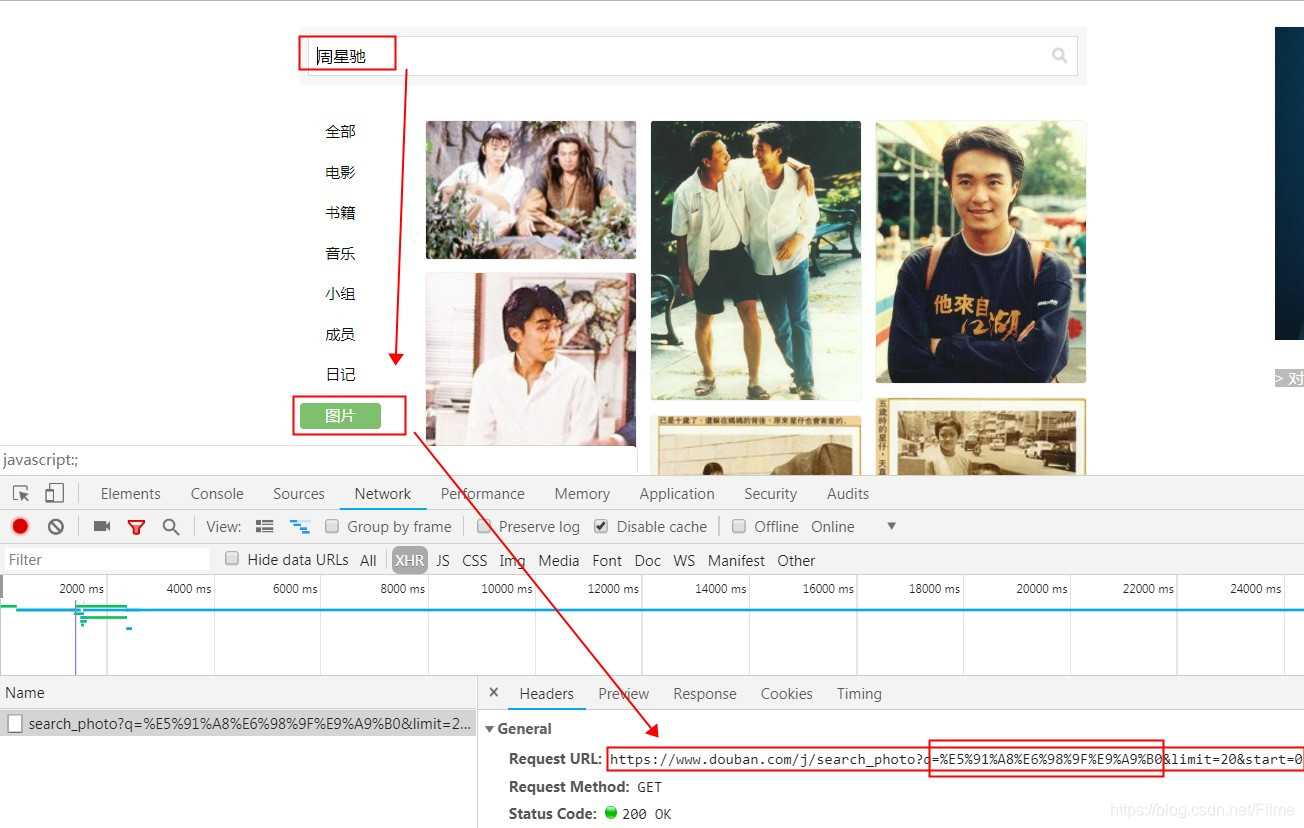
这里有三个参数q,limit,start.q表示搜索的关键词,limit表示每页的显示数量,start表示每页的起始序号,注意默认是从0开始
获取数据
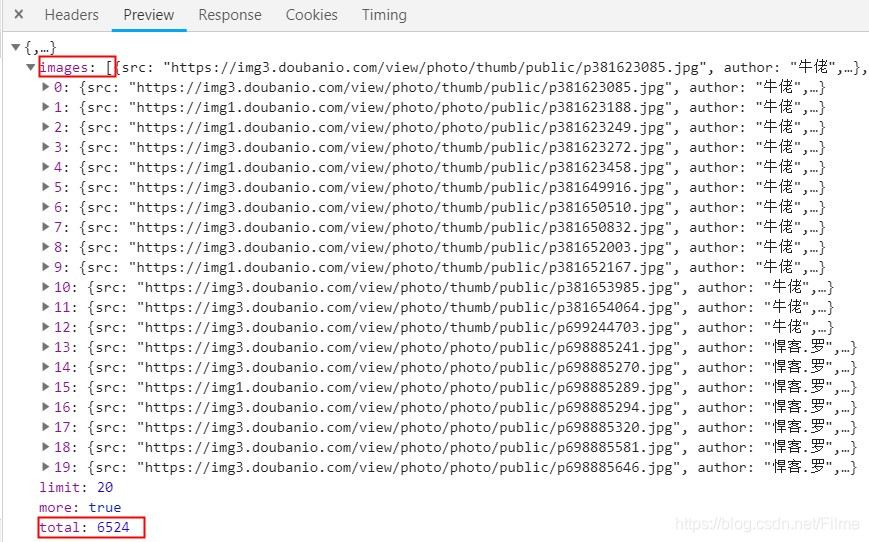
搜索结果是json 结果的数据,具体内容是一个数组images,数组的元素是字典
保存数据
def download(src,id):
dir = './'+str(id)+'.jpg'
try:
pic = requests.get(src,timeout=10)
except requests.exceptions.ConnectionError:
print('timeout error')
fp= open(dir,'wb')
#write
fp.write(pic.content)
#close
fp.close()

















 1269
1269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









