




 本文介绍了如何使用selenium替代requests+正则解析猫眼电影榜单,详细解析了爬取过程和数据可视化,包括主演分布、电影名称长度、发行国家等,并展示了相关可视化结果。
本文介绍了如何使用selenium替代requests+正则解析猫眼电影榜单,详细解析了爬取过程和数据可视化,包括主演分布、电影名称长度、发行国家等,并展示了相关可视化结果。
如果你在学习爬虫,那么你一定爬取过豆瓣或猫眼电影的榜单,但大多数教程都是用的requests+正则,但对于很多新手来讲,requests获取网页容易,但是用正则表达式解析网页就难的多了。那么,让我们告别看不懂,也写不好的正则吧,本文通过HTML解析器来爬取猫眼榜单电影,并基于爬取的数据做一个简单的数据分析。
1.爬虫
如果你看过网易云音乐上万首hiphop歌曲解析rapper们的最爱(爬虫篇)一文,那么selenium你一定熟悉,然而,那篇文章用到的PhantomJS已经被抛弃了,所以在使用的时候会显示warning。所以,本文需要用webdriver.Chrome()直接模拟浏览器。在开始之前,请确保已经正确安装好Chrome浏览器并配置好了ChromeDriver;另外,还需要正确安装Python的Selenium库。配置部分直接百度,就有大量文章介绍。
第一步呢,肯定是分析网页啦。

我们要爬取就是该部分的内容,通过翻页,观察一下url的变化。
第二页:

第三页:

聪明的你一定发现了,变化只是offset后面的值,也就是每页都加了10,倒推回第一页,对应的是offset=0。那么我们爬取页面的时候,只需要变换该部分就OK了。
网页分析的常规操作,看元素:

我们想要的就在<dl class="board-wrapper">下面的<dd>里面。在具体分析其中一个<dd>:
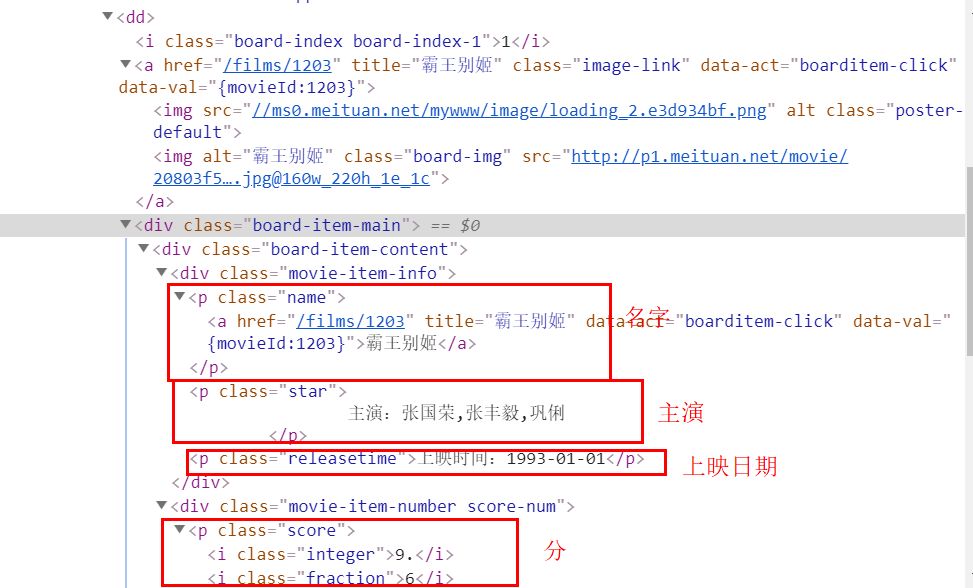
那么接下来就非常简单了。直接上代码:
1from tqdm import tqdm
2import time
3from selenium import webdriver
4from selenium.common.exceptions import TimeoutException, WebDriverException
5import pandas as pd
6
7def get_one_page(url):
8  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2034
2034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









