




| Time Limit: 1000MS | Memory Limit: 65536K | |
| Total Submissions: 11520 | Accepted: 8188 |
Description
In the Fibonacci integer sequence, F0 = 0, F1 = 1, and Fn = Fn − 1 + Fn − 2 for n ≥ 2. For example, the first ten terms of the Fibonacci sequence are:
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, …
An alternative formula for the Fibonacci sequence is
 .
.
Given an integer n, your goal is to compute the last 4 digits of Fn.
Input
The input test file will contain multiple test cases. Each test case consists of a single line containing n (where 0 ≤ n ≤ 1,000,000,000). The end-of-file is denoted by a single line containing the number −1.
Output
For each test case, print the last four digits of Fn. If the last four digits of Fn are all zeros, print ‘0’; otherwise, omit any leading zeros (i.e., print Fn mod 10000).
Sample Input
0 9 999999999 1000000000 -1
Sample Output
0 34 626 6875
Hint
As a reminder, matrix multiplication is associative, and the product of two 2 × 2 matrices is given by
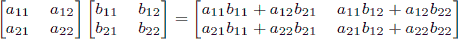 .
.
Also, note that raising any 2 × 2 matrix to the 0th power gives the identity matrix:

#include <iostream>
#include <cstdio>
using namespace std;
const int mod = 10000;
struct matrix { //用一个结构体来存矩阵
int node[2][2];
}ans, tem;
matrix muti(matrix a, matrix b) { //矩阵a乘b返回结果矩阵
matrix temp;
for (int i = 0; i < 2; i++) {
for (int j = 0; j < 2; j++) {
temp.node[i][j] = 0;
for (int k = 0; k < 2; k++) {
temp.node[i][j] = (temp.node[i][j] + (a.node[i][k] * b.node[k][j])) % mod;
}
}
}
return temp;
}
int quick_m(int b) {
ans.node[0][0] = ans.node[1][1] = 1; //ans初始化为单位矩阵
ans.node[0][1] = ans.node[1][0] = 0;
tem.node[0][0] = tem.node[0][1] = tem.node[1][0] = 1;
tem.node[1][1] = 0;
while (b) { //快速幂使用到矩阵乘法中
if (b & 1) {
ans = muti(ans, tem);
}
tem = muti(tem, tem);
b >>= 1;
}
return ans.node[0][1]; //注意返回的是F(n)
}
int main()
{
int n;
while (~scanf("%d", &n) && n != -1) {
printf("%d\n", quick_m(n));
}
return 0;
}

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









