






本文记录一下使用diffusers库实现controlNet过程遇到的问题
1. ControlNet
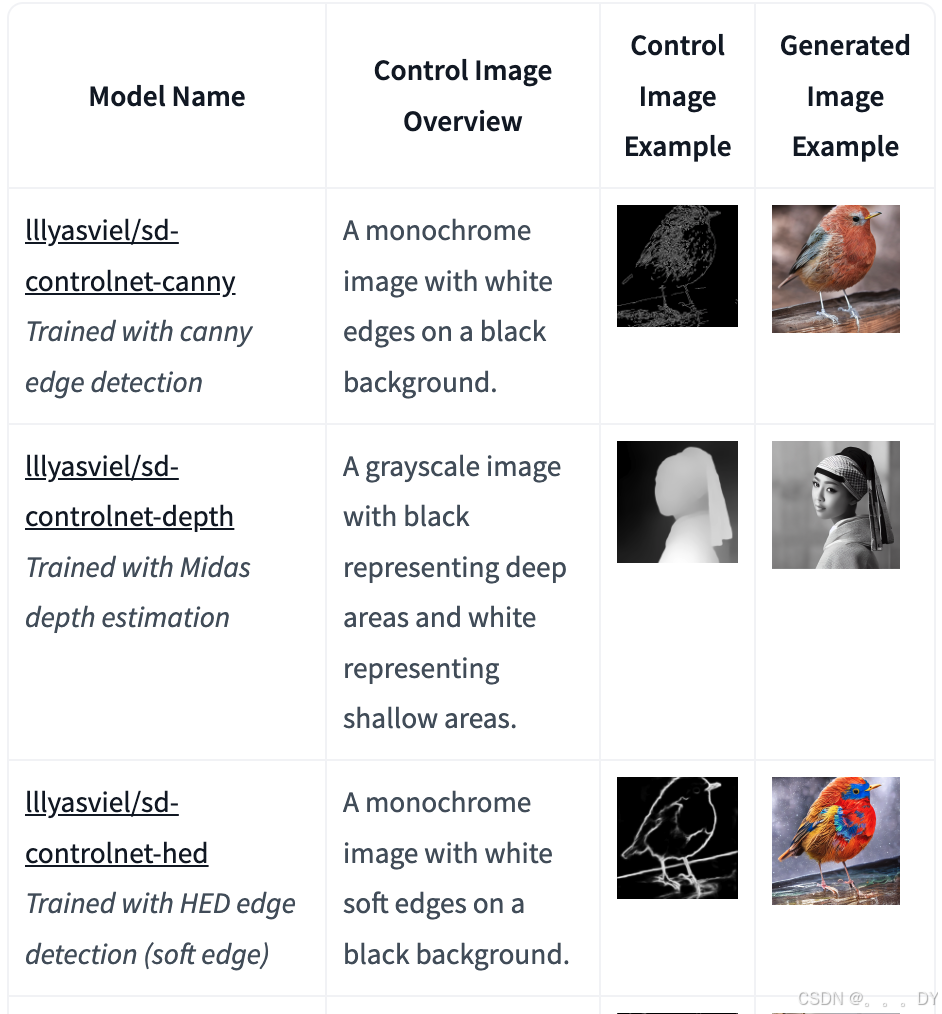
ControlNet项目就不用介绍了,这里说明一下如何从huggingface上下载权重文件。
hf链接:https://huggingface.co/lllyasviel/sd-controlnet-normal
这里包含depth,normal等条件的模型,并且还有代码参考实例。替换不同条件模型时,只需要替换对应的Model Nome,注意中间用-连接。
2.diffusers
使用diffusers库来使用T2I或者I2I非常便捷
pip install diffusers不过需要注意的是,在使用它来实现controlNet时,有时会出现问题:
TypeError: forward() takes 2 positional arguments but 3 were given
我运行github上项目,使用StableDiffusionControlNetPipeline这个pipe。
解决方法:
安装0.26.0版本的diffusers库,不同版本diffusers对应的huggingface版本可能也不同。
pip install huggingface_hub==0.25.0
pip install diffusers==0.26.0
3.ControlNet 详细代码
代码基于Tech 中 guidance.py 修改,保留了其中计算SDS部分
from transformers import CLIPTextModel, CLIPTokenizer, logging,CLIPProcessor,CLIPVisionModel
from diffusers import AutoencoderKL, UNet2DConditionModel, PNDMScheduler, DDIMScheduler, ControlNetModel
from diffusers.utils import load_image
# suppress partial model loading warning
logging.set_verbosity_error()
from torchvision import transforms
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.transforms as T
import torchvision
import numpy as np
import PIL
from torch.cuda.amp import custom_bwd, custom_fwd
import clip
class SpecifyGradient(torch.autograd.Function):
@staticmethod
@custom_fwd
def forward(ctx, input_tensor, gt_grad):
ctx.save_for_backward(gt_grad)
return torch.zeros([1], device=input_tensor.device, dtype=input_tensor.dtype) # dummy loss value
@staticmethod
@custom_bwd
def backward(ctx, grad):
gt_grad, = ctx.saved_tensors
batch_size = len(gt_grad)
return gt_grad / batch_size, None
def seed_everything(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
#torch.backends.cudnn.deterministic = True
#torch.backends.cudnn.benchmark = True
class StableDiffusion(nn.Module):
def __init__(self, device, sd_version='2.1', hf_key=None, sd_step_range=[0.2, 0.98], controlnet=None, lora=None, cfg=None, head_hf_key=None):
super().__init__()
self.cfg = cfg
self.device = device
self.sd_version = sd_version
print(f'[INFO] loading stable diffusion...')
if hf_key is not None:
print(f'[INFO] using hugging face custom model key: {hf_key}')
model_key = hf_key
elif self.sd_version == '2.1':
model_key = "stabilityai/stable-diffusion-2-1-base"
elif self.sd_version == '2.0':
model_key = "stabilityai/stable-diffusion-2-base"
elif self.sd_version == '1.5':
model_key = "runwayml/stable-diffusion-v1-5"
else:
raise ValueError(f'Stable-diffusion version {self.sd_version} not supported.')
self.clip_model, _ = clip.load("ViT-L/14", device=self.device, jit=False, download_root='clip_ckpts')
self.clip_model = self.clip_model.eval().requires_grad_(False).to(self.device)
self.clip_preprocess = T.Compose([
T.Resize((224, 224)),
T.Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711)),
])
# Create model
self.vae = AutoencoderKL.from_pretrained(model_key, subfolder="vae").to(self.device)
self.tokenizer = CLIPTokenizer.from_pretrained(model_key, subfolder="tokenizer")
self.text_encoder = CLIPTextModel.from_pretrained(model_key, subfolder="text_encoder").to(self.device)
self.unet = UNet2DConditionModel.from_pretrained(model_key, subfolder="unet").to(self.device)
self.use_head_model = head_hf_key is not None
if self.use_head_model:
self.tokenizer_head = CLIPTokenizer.from_pretrained(head_hf_key, subfolder="tokenizer")
self.text_encoder_head = CLIPTextModel.from_pretrained(head_hf_key, subfolder="text_encoder").to(self.device)
self.unet_head = UNet2DConditionModel.from_pretrained(head_hf_key, subfolder="unet").to(self.device)
else:
self.tokenizer_head = self.tokenizer
self.text_encoder_head = self.text_encoder
self.unet_head = self.unet
self.scheduler = DDIMScheduler.from_pretrained(model_key, subfolder="scheduler")
self.num_train_timesteps = self.scheduler.config.num_train_timesteps
self.min_step = int(self.num_train_timesteps * sd_step_range[0])
self.max_step = int(self.num_train_timesteps * sd_step_range[1])
self.alphas = self.scheduler.alphas_cumprod.to(self.device) # for convenience
if controlnet is None:
self.controlnet = None
else:
self.controlnet = ControlNetModel.from_pretrained(controlnet).to(self.device)
if lora is not None:
self.unet.load_attn_procs(lora)
self.processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
self.image_encoder = CLIPVisionModel.from_pretrained("openai/clip-vit-base-patch32").to(self.device)
print(f'[INFO] loaded stable diffusion!')
def img_clip_loss(self, rgb1, rgb2):
image_z_1 = self.clip_model.encode_image(self.clip_preprocess(rgb1))
image_z_2 = self.clip_model.encode_image(self.clip_preprocess(rgb2))
image_z_1 = image_z_1 / image_z_1.norm(dim=-1, keepdim=True) # normalize features
image_z_2 = image_z_2 / image_z_2.norm(dim=-1, keepdim=True) # normalize features
loss = - (image_z_1 * image_z_2).sum(-1).mean()
return loss
def img_text_clip_loss(self, rgb, prompts):
image_z_1 = self.clip_model.encode_image(self.aug(rgb))
image_z_1 = image_z_1 / image_z_1.norm(dim=-1, keepdim=True) # normalize features
text = clip.tokenize(prompt).to(self.device)
text_z = self.clip_model.encode_text(text)
text_z = text_z / text_z.norm(dim=-1, keepdim=True)
loss = - (image_z_1 * text_z).sum(-1).mean()
return loss
def get_text_embeds(self, prompt, negative_prompt, is_face=False):
print('text prompt: [positive]', prompt, '[negative]', negative_prompt)
if not is_face:
tokenizer = self.tokenizer
text_encoder = self.text_encoder
else:
tokenizer = self.tokenizer_head
text_encoder = self.text_encoder_head
# prompt, negative_prompt: [str]
# Tokenize text and get embeddings
text_input = tokenizer(prompt, padding='max_length', max_length=tokenizer.model_max_length, truncation=True, return_tensors='pt')
with torch.no_grad():
text_embeddings = text_encoder(text_input.input_ids.to(self.device))[0]
# Do the same for unconditional embeddings
uncond_input = tokenizer(negative_prompt, padding='max_length', max_length=tokenizer.model_max_length, return_tensors='pt')
with torch.no_grad():
uncond_embeddings = text_encoder(uncond_input.input_ids.to(self.device))[0]
# Cat for final embeddings
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
return text_embeddings
def get_img_embeds(self, images: list):
# 检查输入是否是列表,如果是单个图像,转换为列表
if not isinstance(images, list):
images = [images]
# 使用 CLIPProcessor 处理图像:调整大小、标准化等
inputs = self.processor(images=images, return_tensors="pt").to(self.device)
# 获取图像嵌入
with torch.no_grad():
image_embeddings = self.image_encoder(**inputs).last_hidden_state
# 构建无条件的图像嵌入
uncond_image_embeddings = torch.zeros_like(image_embeddings) # 这里使用全零向量作为无条件的图像嵌入
# 拼接无条件和条件图像嵌入
final_image_embeddings = torch.cat([uncond_image_embeddings, image_embeddings])
return final_image_embeddings
def train_step(self, text_embeddings, pred_rgb, guidance_scale=100, controlnet_hint=None, controlnet_conditioning_scale=1.0, clip_ref_img=None, is_face=False, **kwargs):
if is_face:
unet = self.unet_head
else:
unet = self.unet
# interp to 512x512 to be fed into vae.
# _t = time.time()
pred_rgb_512 = F.interpolate(pred_rgb, (512, 512), mode='bilinear', align_corners=False)
#pred_rgb_512 = pred_rgb
if controlnet_hint:
assert self.controlnet is not None
controlnet_hint = self.controlnet_hint_conversion(controlnet_hint, 512, 512)
# torch.cuda.synchronize(); print(f'[TIME] guiding: interp {time.time() - _t:.4f}s')
# timestep ~ U(0.02, 0.98) to avoid very high/low noise level
t = torch.randint(self.min_step, self.max_step + 1, [1], dtype=torch.long, device=self.device)
# encode image into latents with vae, requires grad!
# _t = time.time()
latents = self.encode_imgs(pred_rgb_512)
# torch.cuda.synchronize(); print(f'[TIME] guiding: vae enc {time.time() - _t:.4f}s')
# predict the noise residual with unet, NO grad!
# _t = time.time()
with torch.no_grad():
# add noise
noise = torch.randn_like(latents)
latents_noisy = self.scheduler.add_noise(latents, noise, t)
# pred noise
latent_model_input = torch.cat([latents_noisy] * 2)
if controlnet_hint is not None:
down_block_res_samples, mid_block_res_sample = self.controlnet(
latent_model_input,
t,
encoder_hidden_states=text_embeddings,
controlnet_cond=controlnet_hint,
conditioning_scale=controlnet_conditioning_scale,
return_dict=False
)
noise_pred = unet(latent_model_input, t, encoder_hidden_states=text_embeddings,
down_block_additional_residuals=down_block_res_samples,
mid_block_additional_residual=mid_block_res_sample,).sample
else:
noise_pred = unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
# torch.cuda.synchronize(); print(f'[TIME] guiding: unet {time.time() - _t:.4f}s')
# perform guidance (high scale from paper!)
if self.scheduler.config.prediction_type == "v_prediction":
alphas_cumprod = self.scheduler.alphas_cumprod.to(
device=latents_noisy.device, dtype=latents_noisy.dtype
)
alpha_t = alphas_cumprod[t] ** 0.5
sigma_t = (1 - alphas_cumprod[t]) ** 0.5
noise_pred = latent_model_input * torch.cat([sigma_t] * 2, dim=0).view(
-1, 1, 1, 1
) + noise_pred * torch.cat([alpha_t] * 2, dim=0).view(-1, 1, 1, 1)
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
if clip_ref_img is not None and t < self.cfg.clip_step_range * self.num_train_timesteps:
guidance_scale = self.cfg.clip_guidance_scale
noise_pred = noise_pred_text + guidance_scale * (noise_pred_text - noise_pred_uncond)
self.scheduler.set_timesteps(self.num_train_timesteps)
de_latents = self.scheduler.step(noise_pred, t, latents_noisy)['prev_sample']
imgs = self.decode_latents(de_latents)
loss = 0
if self.cfg.lambda_clip_img_loss > 0:
loss = loss + self.img_clip_loss(imgs, clip_ref_img) * self.cfg.lambda_clip_img_loss
if self.cfg.lambda_clip_text_loss > 0:
text = self.cfg.text.replace('sks', '')
loss = loss + self.img_text_clip_loss(imgs, [text]) * self.cfg.lambda_clip_text_loss
else:
noise_pred = noise_pred_text + guidance_scale * (noise_pred_text - noise_pred_uncond)
# w(t), sigma_t^2
w = (1 - self.alphas[t])
# w = self.alphas[t] ** 0.5 * (1 - self.alphas[t])
grad = w * (noise_pred - noise)
# clip grad for stable training?
# grad = grad.clamp(-10, 10)
grad = torch.nan_to_num(grad)
# since we omitted an item in grad, we need to use the custom function to specify the gradient
# _t = time.time()
loss = SpecifyGradient.apply(latents, grad)
# torch.cuda.synchronize(); print(f'[TIME] guiding: backward {time.time() - _t:.4f}s')
return loss
def produce_latents(self, text_embeddings, height=512, width=512, num_inference_steps=50, guidance_scale=7.5, latents=None, controlnet_hint=None):
if latents is None:
latents = torch.randn((text_embeddings.shape[0] // 2, self.unet.in_channels, height // 8, width // 8), device=self.device)
self.scheduler.set_timesteps(num_inference_steps)
with torch.autocast('cuda'):
for i, t in enumerate(self.scheduler.timesteps):
# expand the latents if we are doing classifier-free guidance to avoid doing two forward passes.
latent_model_input = torch.cat([latents] * 2)
# predict the noise residual
with torch.no_grad():
if controlnet_hint is not None:
controlnet_hint = self.controlnet_hint_conversion(controlnet_hint, 512, 512)
down_block_res_samples, mid_block_res_sample = self.controlnet(
latent_model_input,
t,
encoder_hidden_states=text_embeddings,
controlnet_cond=controlnet_hint,
conditioning_scale=1,
return_dict=False
)
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeddings,
down_block_additional_residuals=down_block_res_samples,
mid_block_additional_residual=mid_block_res_sample,).sample
else:
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeddings)['sample']
# perform guidance
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_text + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents)['prev_sample']
return latents
def decode_latents(self, latents):
latents = 1 / 0.18215 * latents
with torch.no_grad():
imgs = self.vae.decode(latents).sample
imgs = (imgs / 2 + 0.5).clamp(0, 1)
return imgs
def encode_imgs(self, imgs):
# imgs: [B, 3, H, W]
imgs = 2 * imgs - 1
posterior = self.vae.encode(imgs).latent_dist
latents = posterior.sample() * 0.18215
return latents
def prompt_to_img(self, prompts, negative_prompts='', height=512, width=512, num_inference_steps=50, guidance_scale=7.5, latents=None, controlnet_hint=None,is_text=True):
if isinstance(prompts, str):
prompts = [prompts]
if isinstance(negative_prompts, str):
negative_prompts = [negative_prompts]
if is_text:
# Prompts -> text embeds
text_embeds = self.get_text_embeds(prompts, negative_prompts)
else:
text_embeds = self.get_img_embeds(prompts)
# # Prompts -> text embeds
# text_embeds = self.get_text_embeds(prompts, negative_prompts) # [2, 77, 768]
# Text embeds -> img latents
latents = self.produce_latents(text_embeds, height=height, width=width, latents=latents, num_inference_steps=num_inference_steps, guidance_scale=guidance_scale,controlnet_hint=controlnet_hint) # [1, 4, 64, 64]
# Img latents -> imgs
imgs = self.decode_latents(latents) # [1, 3, 512, 512]
# Img to Numpy
imgs = imgs.detach().cpu().permute(0, 2, 3, 1).numpy()
imgs = (imgs * 255).round().astype('uint8')
return imgs
def controlnet_hint_conversion(self, controlnet_hint, height, width, num_images_per_prompt=1):
channels = 3
if isinstance(controlnet_hint, torch.Tensor):
# torch.Tensor: acceptble shape are any of chw, bchw(b==1) or bchw(b==num_images_per_prompt)
shape_chw = (channels, height, width)
shape_bchw = (1, channels, height, width)
shape_nchw = (num_images_per_prompt, channels, height, width)
if controlnet_hint.shape in [shape_chw, shape_bchw, shape_nchw]:
controlnet_hint = controlnet_hint.to(dtype=self.controlnet.dtype, device=self.controlnet.device)
if controlnet_hint.shape != shape_nchw:
controlnet_hint = controlnet_hint.repeat(num_images_per_prompt, 1, 1, 1)
return controlnet_hint
else:
raise ValueError(
f"Acceptble shape of `controlnet_hint` are any of ({channels}, {height}, {width}),"
+ f" (1, {channels}, {height}, {width}) or ({num_images_per_prompt}, "
+ f"{channels}, {height}, {width}) but is {controlnet_hint.shape}"
)
elif isinstance(controlnet_hint, np.ndarray):
# np.ndarray: acceptable shape is any of hw, hwc, bhwc(b==1) or bhwc(b==num_images_per_promot)
# hwc is opencv compatible image format. Color channel must be BGR Format.
if controlnet_hint.shape == (height, width):
controlnet_hint = np.repeat(controlnet_hint[:, :, np.newaxis], channels, axis=2) # hw -> hwc(c==3)
shape_hwc = (height, width, channels)
shape_bhwc = (1, height, width, channels)
shape_nhwc = (num_images_per_prompt, height, width, channels)
if controlnet_hint.shape in [shape_hwc, shape_bhwc, shape_nhwc]:
controlnet_hint = torch.from_numpy(controlnet_hint.copy())
controlnet_hint = controlnet_hint.to(dtype=self.controlnet.dtype, device=self.controlnet.device)
controlnet_hint /= 255.0
if controlnet_hint.shape != shape_nhwc:
controlnet_hint = controlnet_hint.repeat(num_images_per_prompt, 1, 1, 1)
controlnet_hint = controlnet_hint.permute(0, 3, 1, 2) # b h w c -> b c h w
return controlnet_hint
else:
raise ValueError(
f"Acceptble shape of `controlnet_hint` are any of ({width}, {channels}), "
+ f"({height}, {width}, {channels}), "
+ f"(1, {height}, {width}, {channels}) or "
+ f"({num_images_per_prompt}, {channels}, {height}, {width}) but is {controlnet_hint.shape}"
)
elif isinstance(controlnet_hint, PIL.Image.Image):
if controlnet_hint.size == (width, height):
controlnet_hint = controlnet_hint.convert("RGB") # make sure 3 channel RGB format
controlnet_hint = np.array(controlnet_hint) # to numpy
controlnet_hint = controlnet_hint[:, :, ::-1] # RGB -> BGR
return self.controlnet_hint_conversion(controlnet_hint, height, width, num_images_per_prompt)
else:
raise ValueError(
f"Acceptable image size of `controlnet_hint` is ({width}, {height}) but is {controlnet_hint.size}"
)
else:
raise ValueError(
f"Acceptable type of `controlnet_hint` are any of torch.Tensor, np.ndarray, PIL.Image.Image but is {type(controlnet_hint)}"
)
if __name__ == '__main__':
import argparse
import matplotlib.pyplot as plt
# parser = argparse.ArgumentParser()
# parser.add_argument('prompt', type=str)
# parser.add_argument('--negative', default='', type=str)
# parser.add_argument('--sd_version', type=str, default='2.1', choices=['1.5', '2.0', '2.1'], help="stable diffusion version")
# parser.add_argument('--hf_key', type=str, default=None, help="hugging face Stable diffusion model key")
# parser.add_argument('-H', type=int, default=512)
# parser.add_argument('-W', type=int, default=512)
# parser.add_argument('--seed', type=int, default=0)
# parser.add_argument('--steps', type=int, default=50)
# opt = parser.parse_args()
seed_everything(0)
control_img_path = "/home/clothAvatar/normals_06.png"
device = torch.device('cuda')
img = load_image(control_img_path)
transform = transforms.Compose([
transforms.ToTensor(), # 将 PIL 图像转换为 [C, H, W] Tensor
transforms.Resize((512, 512)), # 调整大小为 512x512
])
control_image = transform(img).unsqueeze(0)
# controlnet="lllyasviel/sd-controlnet-openpose"
controlnet="lllyasviel/sd-controlnet-normal"
# controlnet = "lllyasviel/sd-controlnet-depth"
# hf_key="/home/TeCH/exp/examples/name/sd_model"
# lora = "/home/add_detail.safetensors"
sd = StableDiffusion(device, '1.5', hf_key=None,controlnet=controlnet)
prompt_ = "a sks man, dark brown short and slightly messy hair, neutral, slightly frowning, sks light grey plain, casual hoodie, sks grey regular fit jeans pants, hands are slightly spread out and relaxed"
prompt_ = prompt_.replace('sks',"")
# prompt_ = "A man with a piece of Brown Sweatshirt."
# prompt_ = PIL.Image.open("/home/color_000001.png").convert("RGB")
# visualize image
imgs = []
for _ in range(4):
img = sd.prompt_to_img(prompt_, "", 512, 512, 50,controlnet_hint=control_image)
# img = sd.prompt_to_img(prompt_, "", 512, 512, 50,is_text=False)
img = img / 255.
imgs.append(torch.from_numpy(img))
print("done one")
imgs = torch.cat(imgs, dim=0)
# save image as a grid
imgs = imgs.permute(0, 3, 1, 2)
img_grid = torchvision.utils.make_grid(imgs, nrow = 5, padding = 10)
torchvision.utils.save_image(img_grid, '/home/img_grid3.png')
print('Image saved as img_grid.png')4. 使用自定义扩散模型
网上会有一些可以下载的已经训练好的扩散模型和lora等,通常可以使用别人写的web-ui来实现。
这里简单记录一下,其中pipe需要与原模型提供的相符。
import torch
from diffusers import StableDiffusionXLPipeline,AutoencoderKL
from diffusers import EulerDiscreteScheduler
ckpt_path = "/home/ps/dy/downloads/noobaiXLNAIXL_epsilonPred10Version.safetensors"
lora_path = "/home/ps/dy/ahemaru_n.safetensors"
vae = AutoencoderKL.from_pretrained("stabilityai/sdxl-vae").to("cuda")
pipe = StableDiffusionXLPipeline.from_single_file(
ckpt_path,
use_safetensors=True,
torch_dtype=torch.float32,
)
pipe.vae = vae # 将VAE绑定到Pipeline
# pipe.unet.load_attn_procs(lora_path,alpha=0.1)
# scheduler_args = {"prediction_type": "epsilon", "rescale_betas_zero_snr": True}
pipe.scheduler = EulerDiscreteScheduler.from_config(pipe.scheduler.config, None)
# pipe.enable_xformers_memory_efficient_attention()
pipe = pipe.to("cuda")
prompt = """masterpiece, best quality, chromatic aberration, cute \(theme\), limited palette, high contrast, color contrast, hot colors, while theme, \(medium\)"""
negative_prompt = "nsfw, worst quality, old, early, low quality, lowres, signature, username, logo, bad hands, mutated hands, mammal, anthro, furry, ambiguous form, feral, semi-anthro"
image = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
width=832,
height=1216,
num_inference_steps=28,
guidance_scale=7.5,
generator=torch.Generator().manual_seed(0),
).images[0]
image.save("/home/ps/dy/output.png")
















 3007
3007

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









