






一、前言
DMTet 和 FelxiCubes (FC)分别是 NVIDIA 在 NeurIPS 2021 和 SIGGRAPH 2023 发布的两个关于可微渲染的工作。在三维重建和生成中使用二维图片作为约束的方法越来越多,特别是现在还有许多2D的大模型的情况下,可微渲染几乎成为标配。
传统Marching Cubes一般是在CPU上进行,现在的方法通常使用DMTet进行可微渲染,也有一些方法使用FC渲染。因此本文简单记录一下两个方法在重建上的效果。
二、实验设置
任务:重建人体(实际上重建T-pose人体然后使用LBS形变,但我冻结了LBS部分)
参考代码:TeCH (每个Epoch中100个随机视角,保留了代码中针对头部的渲染)
使用数据:一个Mesh
三、个人结论
重建质量:FC更好一点
FC的分辨率设置与DMTet不同,在两者都重建出8-9w个点的情况下,个人感觉FC效果好一点,感觉更平滑。但在手部区域FC出现了断指的问题,应该是我训练设置问题。
FC重建的网格拓扑更好一点,这点论文里也提到了。
收敛速度:相当
1个epoch衣物纹理可以处理,10多个Epoch重建的质量就可以了
FC的问题:
1. 需要额外学习weights
个人理解隐式场是可以随意设置提取网格的分辨率,但FC中学习weights的输入与设置分辨率有关,那尽管我得到了学习好的SDF场,但我没有对应的weights(?)。这也是我最不理解的地方,等相关使用FC的代码开源我去参考一下。
2. 可能更依赖2D loss
在初始化时仅使用SMPLX的SDF值做约束,在少量轮次下重建效果DMTet要远好于FC
3. 好像不能重建非水密的网格
在使用SMPLX的SDF初始化时,如果有缺口会导致重建失败。这应该与SDF值计算有关,但DMTet竟然可以。
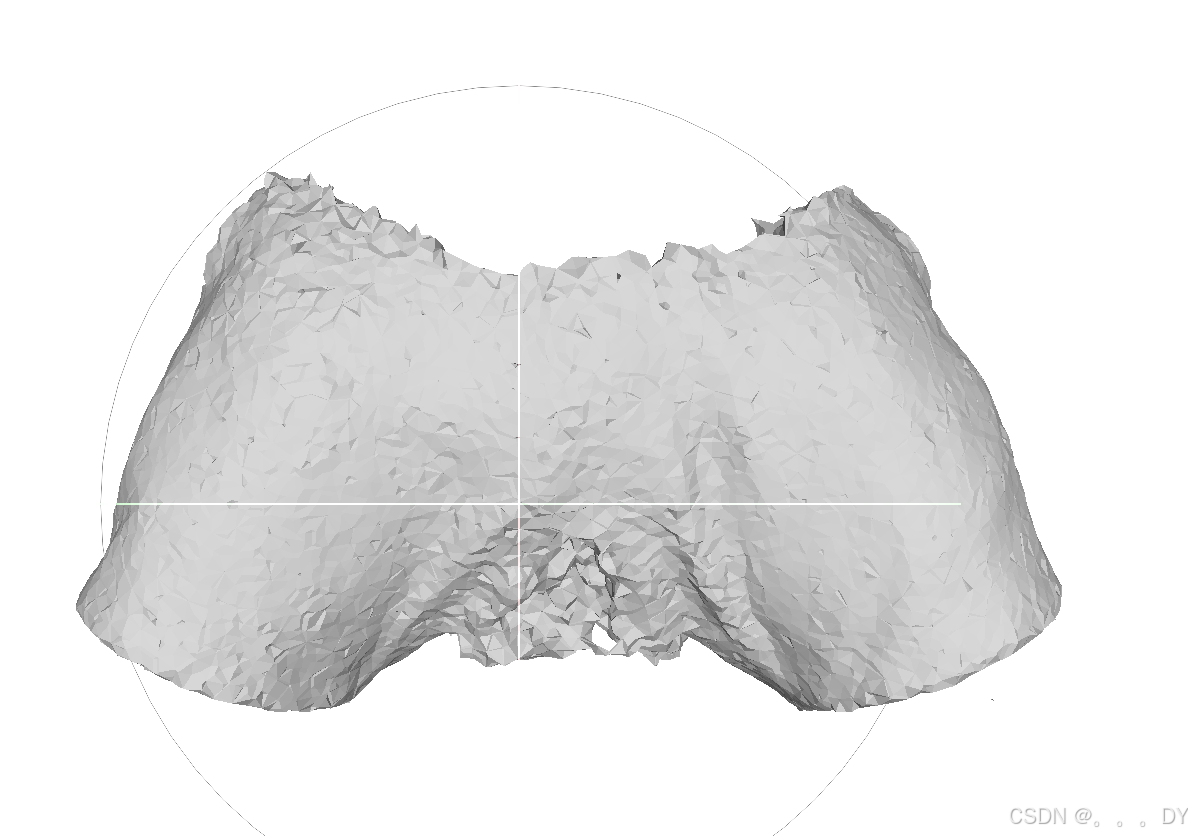
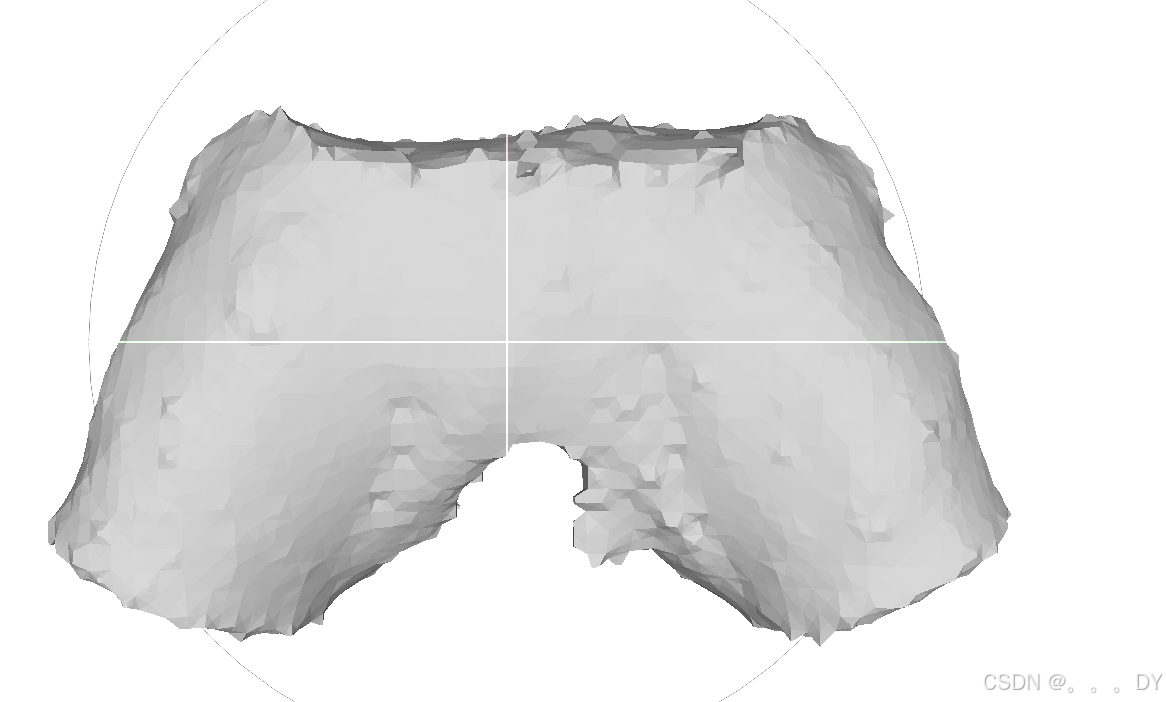
并且重建的结果也都是封闭的,例如裤子👖,DMTet倒可以重建出中空区域(效果很差)
DMTet的问题:
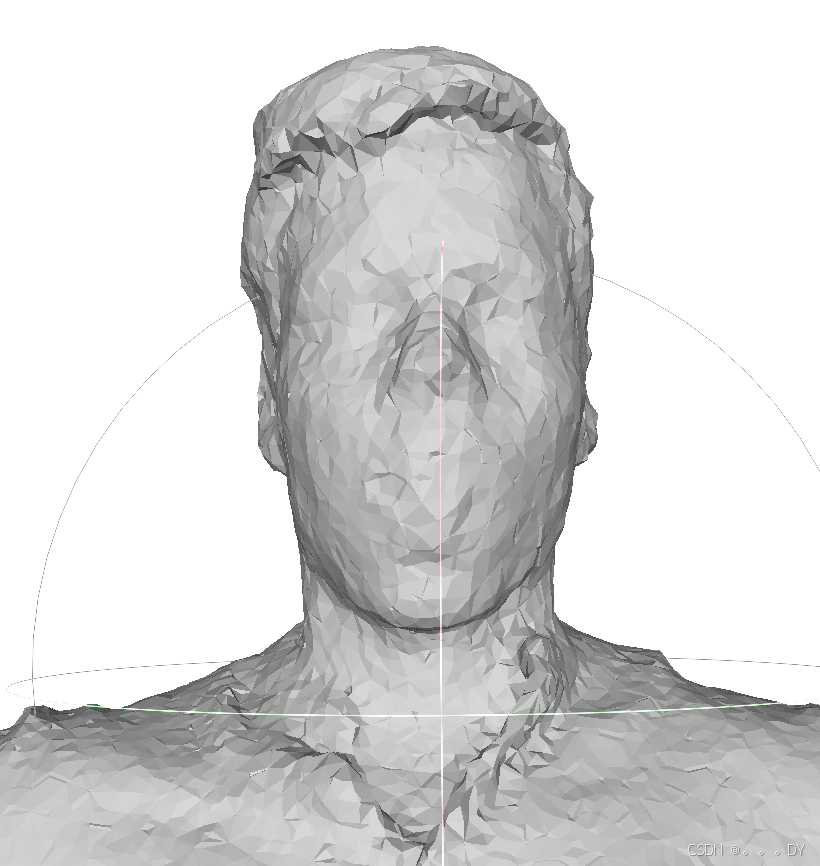
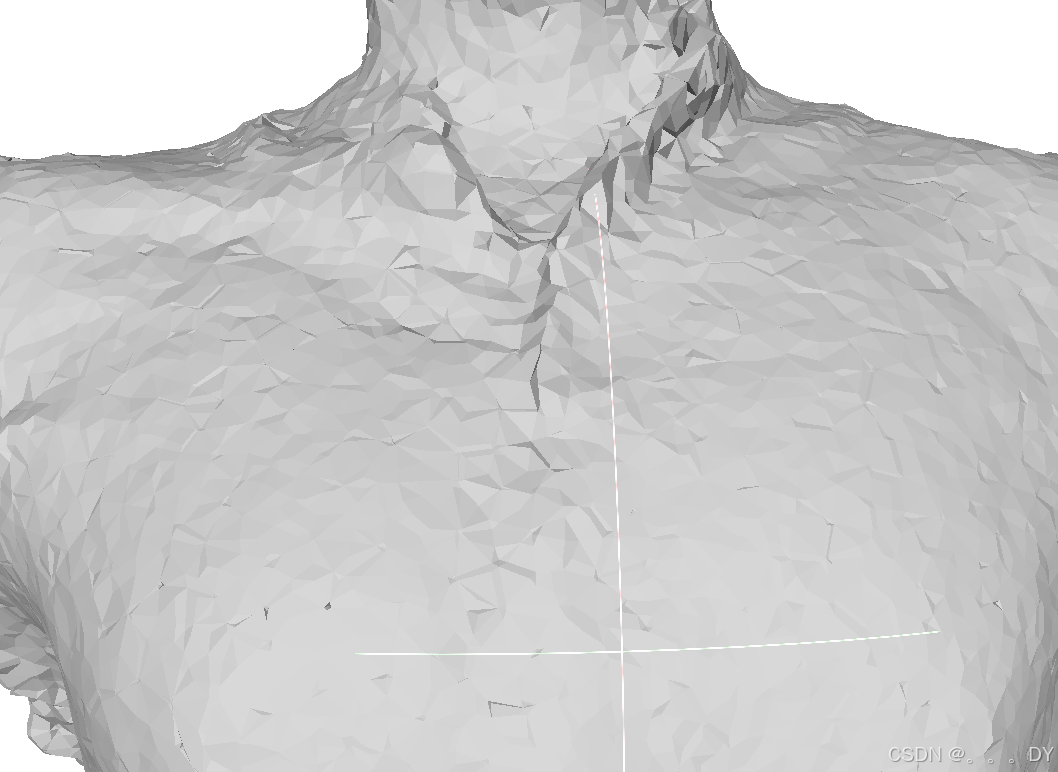
1. 表面感觉不是很光滑
使用DMTet重建的物体,缩小看还可以,但放大看会很明显。在重建的方法中,本人感觉效果最好的还是MC,网格规律且平滑。
四、结果记录
DMTet:
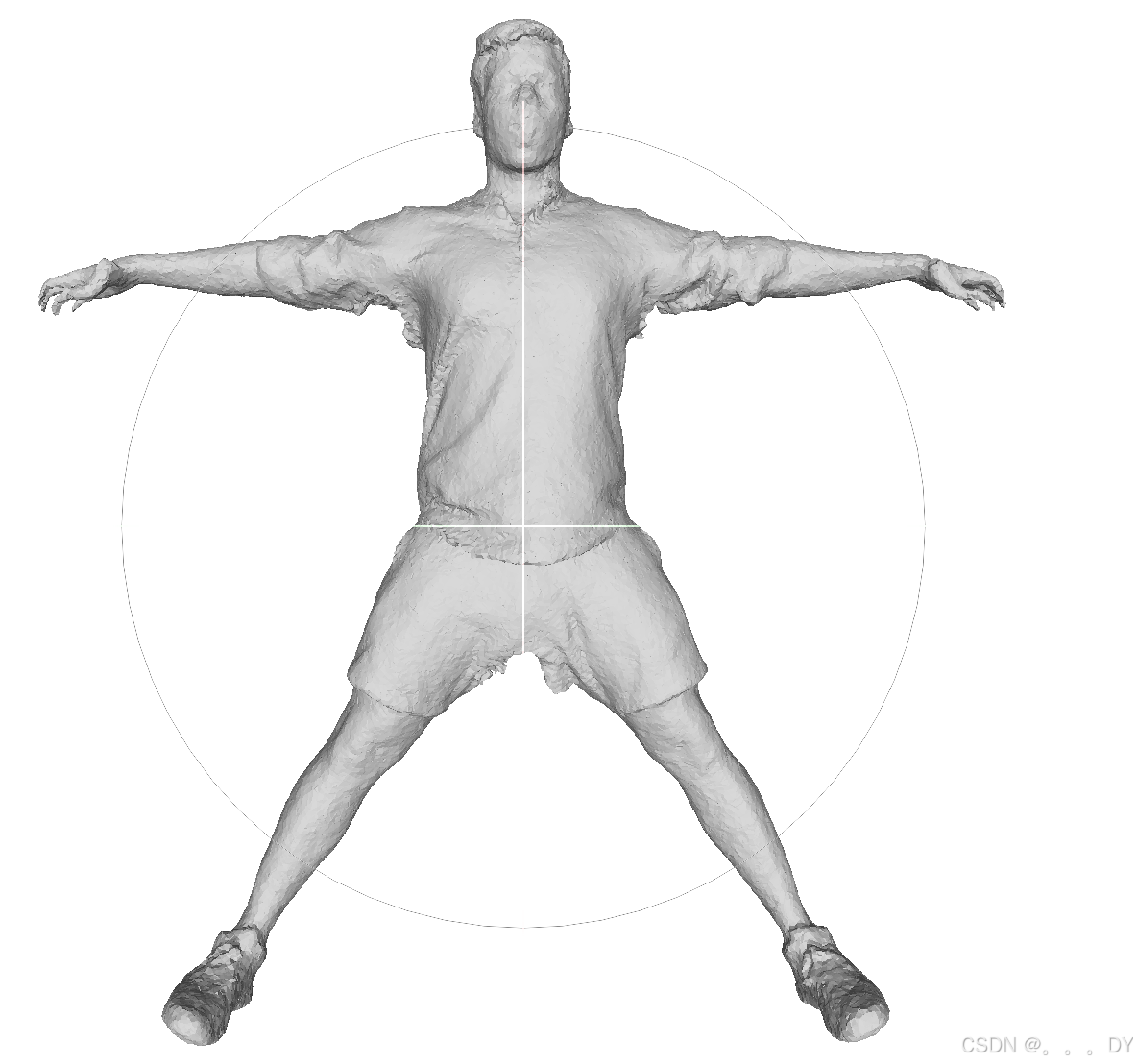
局部放大:
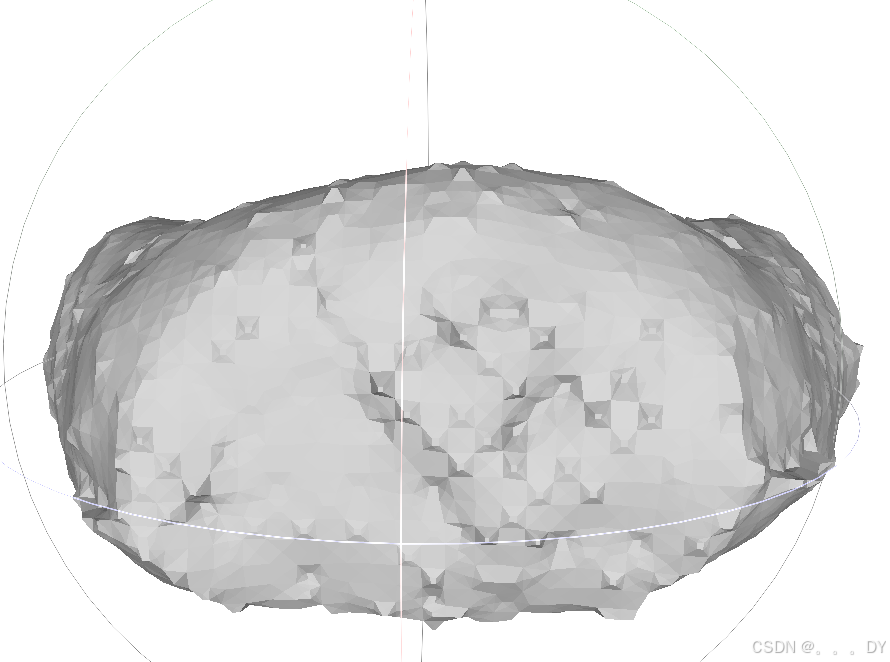
不同视角的短裤:
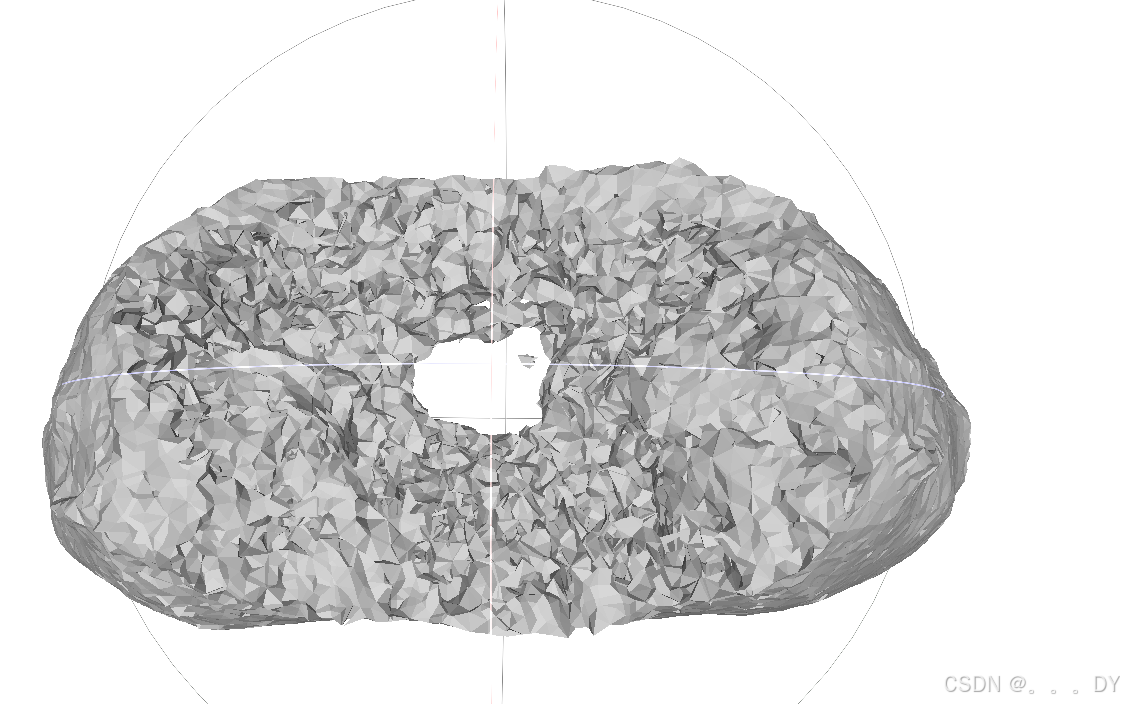
FC:
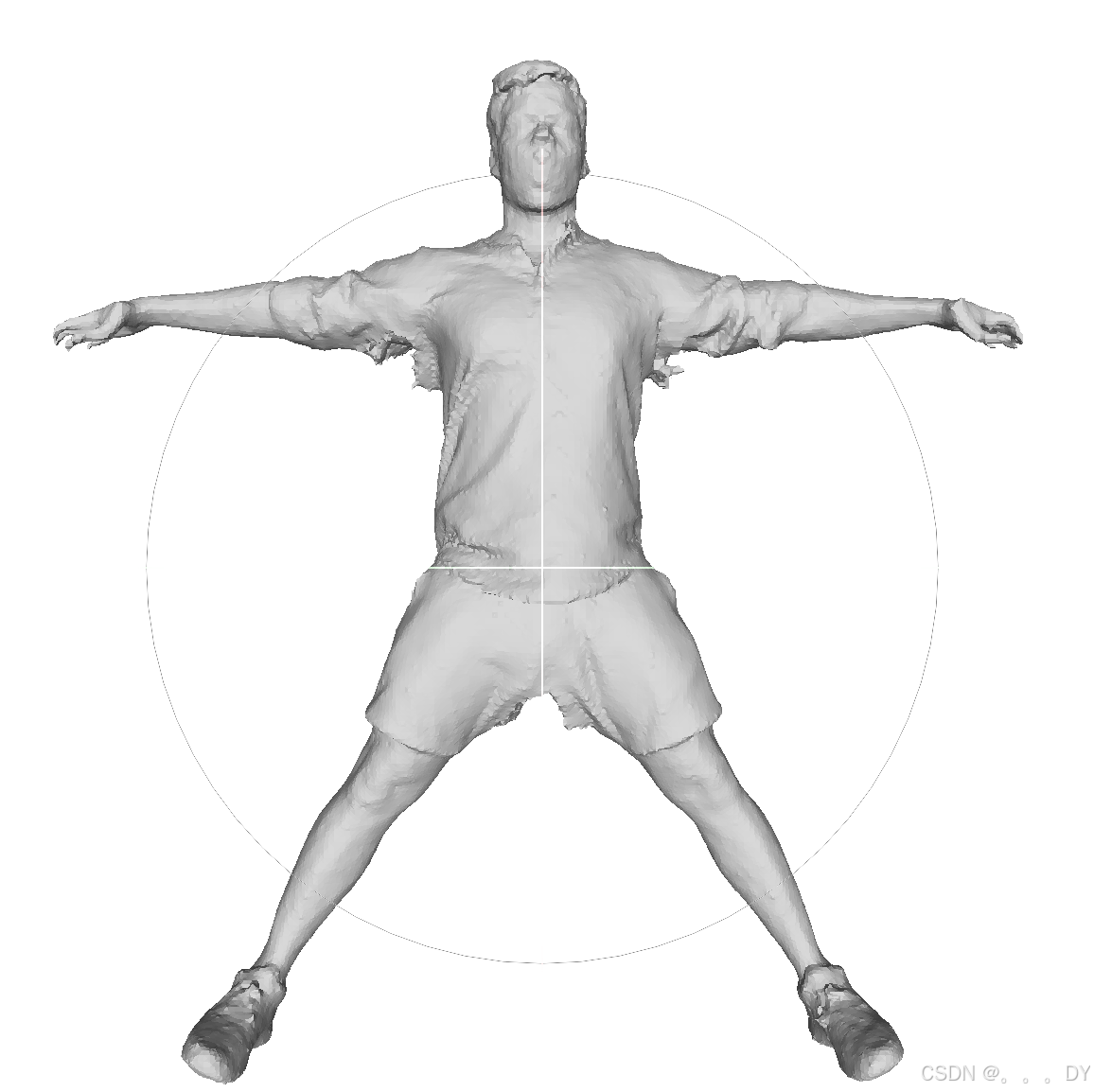
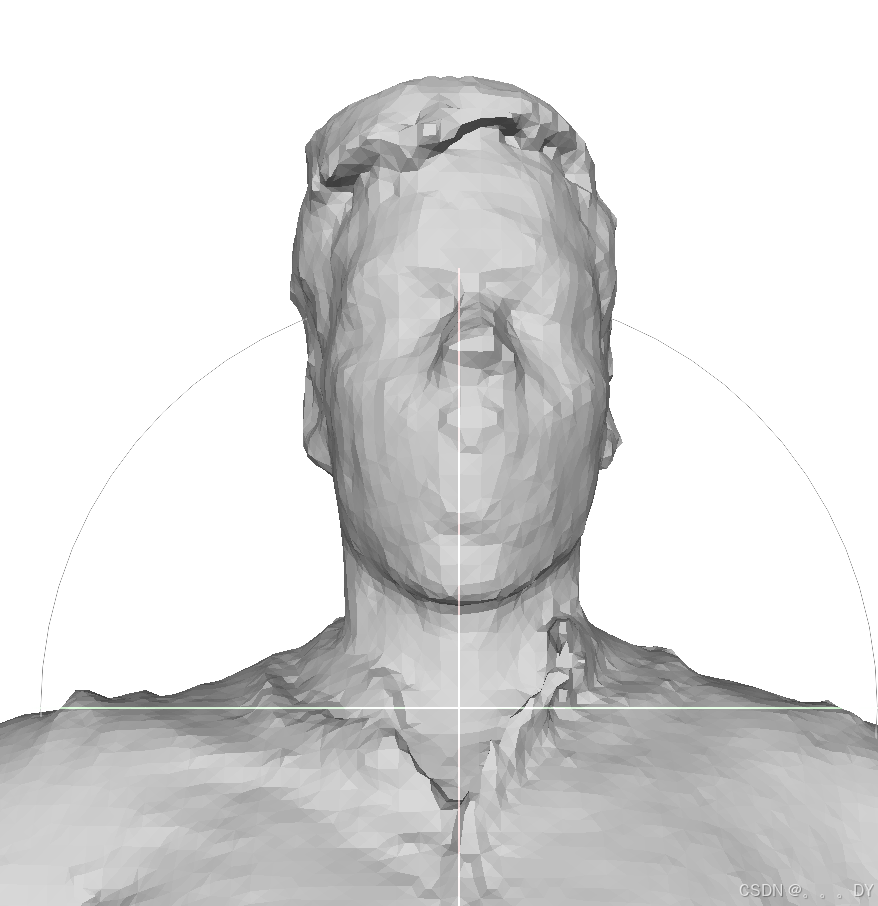
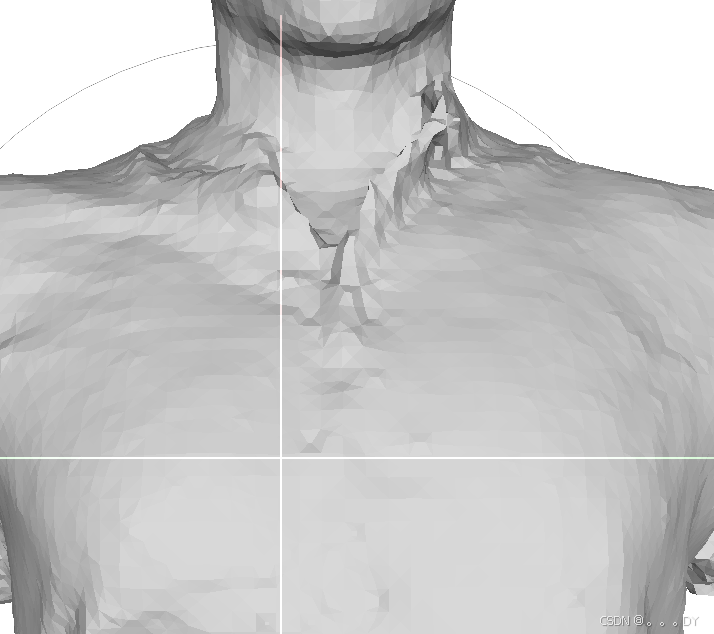
不同视角的短裤:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









