




 本文详细介绍了如何在ApacheFlink的TableAPI和SQL中使用用户定义的函数,包括标量函数、表函数、聚合函数和表聚合函数的定义、注册和使用方法,以及在流处理环境中的实际操作示例。
本文详细介绍了如何在ApacheFlink的TableAPI和SQL中使用用户定义的函数,包括标量函数、表函数、聚合函数和表聚合函数的定义、注册和使用方法,以及在流处理环境中的实际操作示例。
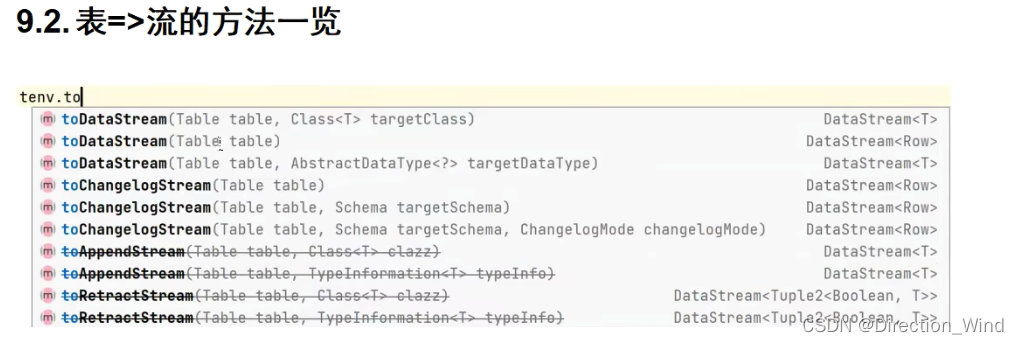
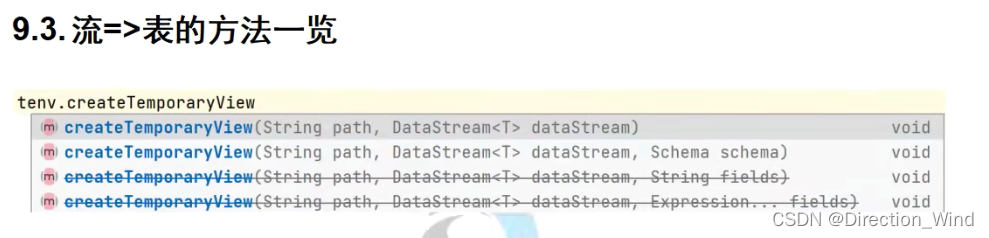
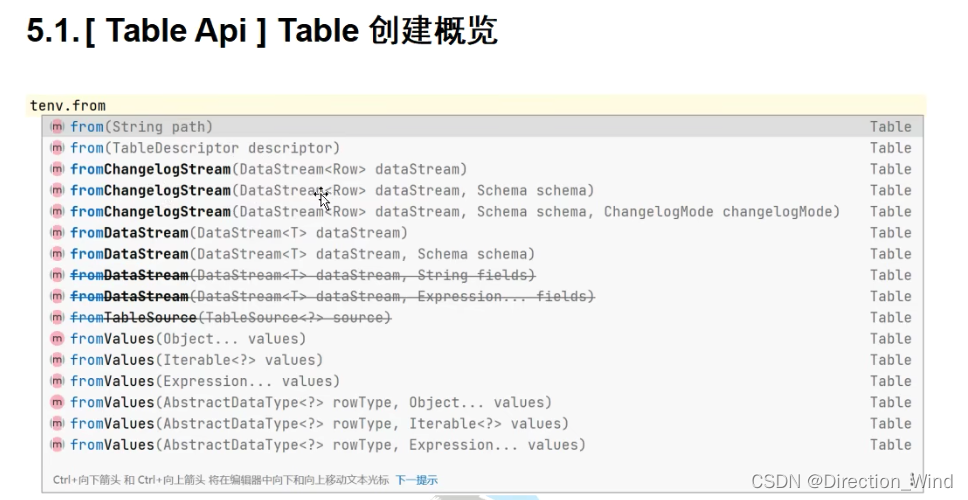
1、在大多数情况下,用户定义的函数必须先注册,然后才能在查询中使用。不需要专门为 Scala 的 Table API 注册函数。
2、函数通过调用 registerFunction()方法在 TableEnvironment 中注册。当用户定义的函数 被注册时,它被插入到 TableEnvironment 的函数目录中,
这样 Table API 或 SQL 解析器就可 以识别并正确地解释它
函数总结,函数总分为四大类

1、标量函数
用户定义的标量函数,可以将 0、1 或多个标量值,映射到新的标量值。
为了定义标量函数,必须在 org.apache.flink.table.functions 中扩展基类 Scalar Function, 并实现(一个或多个)求值(evaluation,eval)方法。标量函数的行为由求值方法决定, 求值方法必须公开声明并命名为 eval(直接 def 声明,没有 override)。求值方法的参数类型 和返回类型,确定了标量函数的参数和返回类型。
package table.tableUdf
import com.yangwj.api.SensorReading
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.table.api.{EnvironmentSettings, Table, Tumble}
import org.apache.flink.table.api.scala._
import org.apache.flink.table.functions.ScalarFunction
import org.apache.flink.types.Row
/**
* @author yangwj
* @date 2021/1/15 23:40
* @version 1.0
*/
object ScalarFunctionTest {
def main(args: Array[String]): Unit = {
//1、创建表执行环境、就得使用流式环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val settings: EnvironmentSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build()
val tableEnv: StreamTableEnvironment = StreamTableEnvironment.create(env,settings)
//2、连接外部系统,读取数据,注册表
//2.1读取文件
val inputFile:String = "G:\\Java\\Flink\\guigu\\flink\\src\\main\\resources\\sensor.txt"
val inputStream: DataStream[String] = env.readTextFile(inputFile)
val dataStream: DataStream[SensorReading] = inputStream.map(data => {
val arr: Array[String] = data.split(",")
SensorReading(arr(0), arr(1).toLong, arr(2).toDouble)
}).assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[SensorReading](Time.seconds(1)) {
override def extractTimestamp(t: SensorReading): Long = t.timestamp * 1000L
})
//tp.proctime 处理时间,注意,使用表达式,一定要引用隐式转换,否则无法使用
val sensorTable: Table = tableEnv.fromDataStream(dataStream, 'id, 'temperature, 'timestamp.rowtime as 'ts)
//调用自定义hash函数,对id进行hash运算
//1、table api
//首先new一个UDF的实例
val hashCode = new HashCode(23)
val apiResult: Table = sensorTable
.select('id, 'ts, hashCode('id))
//2、sql调用
//需要在环境注册UDF
tableEnv.createTemporaryView("sensor",sensorTable)
tableEnv.registerFunction("hashCode",hashCode)
val udfResult: Table = tableEnv.sqlQuery(
"""
|select id,ts,hashCode(id)
|from sensor
""".stripMargin)
apiResult.toAppendStream[Row].print("apiResult")
udfResult.toAppendStream[Row].print("udfResult")
env.execute("udf test")
}
}
//自定义标量函数
class HashCode(factor:Int) extends ScalarFunction{
//必须叫 eval
def eval(s:String): Int ={
s.hashCode * factor - 10000
}
}
2、表函数
- 1、与用户定义的标量函数类似,用户定义的表函数,可以将 0、1 或多个标量值作为输入 参数;与标量函数不同的是,它可以返回任意数量的行作为输出,而不是单个值。
、为了定义一个表函数,必须扩展 org.apache.flink.table.functions 中的基类 TableFunction 并实现(一个或多个)求值方法。表函数的行为由其求值方法决定,求值方法必须是 public 的,并命名为 eval。 求值方法的参数类型,决定表函数的所有有效参数。 - 2、返回表的类型由 TableFunction 的泛型类型确定。求值方法使用 protected collect(T)方 法发出输出行。
- 3、在 Table API 中,Table 函数需要与.joinLateral 或.leftOuterJoinLateral 一起使用。
- 4、joinLateral 算子,会将外部表中的每一行,与表函数(TableFunction,算子的参数是它 的表达式)计算得到的所有行连接起来。
- 5、而 leftOuterJoinLateral 算子,则是左外连接,它同样会将外部表中的每一行与表函数计 算生成的所有行连接起来;并且,对于表函数返回的是空表的外部行,也要保留下来。
- 6、在 SQL 中,则需要使用 Lateral Table(),或者带有 ON TRUE 条件的左连接
package guigu.table.udf
import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api.{DataTypes, Table}
import org.apache.flink.table.api.scala._
import org.apache.flink.table.descriptors.{Csv, FileSystem, Schema}
import org.apache.flink.table.functions.TableFunction
import org.apache.flink.types.Row
/**
* @program: demo
* @description: 表函数:一行对应多行(表)数据输出
* @author: yang
* @create: 2021-01-16 16:07
*/
object tableFunc {
def main(args: Array[String]): Unit = {
//1、基于流执行环境创建table执行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val tableEnv: StreamTableEnvironment = StreamTableEnvironment.create(env)
//2、读取文件,注册表视图
tableEnv.connect(new FileSystem().path("E:\\java\\demo\\src\\main\\resources\\file\\data5.csv"))
.withFormat(new Csv())
.withSchema(new Schema()
.field("id", DataTypes.STRING())
.field("ts",DataTypes.BIGINT())
.field("temperature",DataTypes.DOUBLE()))
.createTemporaryTable("sensorTable")
//3、table api
val split = new Split("_") // new一个UDF实例
val sensorTable: Table = tableEnv.from("sensorTable")
val resutTable = sensorTable.joinLateral(split('id) as ('word,'length))
.select('id,'ts,'word,'length)
//4、sql 实现
tableEnv.registerFunction("split",split)
val sqlResult: Table = tableEnv.sqlQuery(
"""
|select id ,ts ,word ,length
|from sensorTable,
|lateral table ( split(id) ) as splitid(word,length) # splitid 为 split和字段的id的组合
""".stripMargin)
resutTable.toAppendStream[(Row)].print("api")
sqlResult.toAppendStream[(Row)].print("sql")
env.execute("table function")
}
}
//输出类型(String,Int)
class Split(separator:String) extends TableFunction[(String,Int)]{
def eval(str:String): Unit ={
str.split(separator).foreach(
word => collect((word,word.length))
)
}
}
3、聚合函数
-
1、用户自定义聚合函数(User-Defined Aggregate Functions,UDAGGs)可以把一个表中的 数据,聚合成一个标量值。用户定义的聚合函数,是通过继承 AggregateFunction 抽象类实 现的
-
2、AggregateFunction 的工作原理如下:
首先,它需要一个累加器,用来保存聚合中间结果的数据结构(状态)。可以通过 调用 AggregateFunction 的 createAccumulator()方法创建空累加器。
随后,对每个输入行调用函数的 accumulate()方法来更新累加器。
处理完所有行后,将调用函数的 getValue()方法来计算并返回最终结果。 -
3、AggregationFunction 要求必须实现的方法:createAccumulator() 、accumulate()、 getValue()
-
4、除了上述方法之外,还有一些可选择实现的方法。其中一些方法,可以让系统执行查询 更有效率,而另一些方法,对于某些场景是必需的。例如,如果聚合函数应用在会话窗口
(session group window)的上下文中,则 merge()方法是必需。 retract() merge() resetAccumulator()
package guigu.table.udf
import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api.{DataTypes, Table}
import org.apache.flink.table.api.scala._
import org.apache.flink.table.descriptors.{Csv, FileSystem, Schema}
import org.apache.flink.table.functions.AggregateFunction
import org.apache.flink.types.Row
/**
* @program: demo
* @description: 聚合函数:多行数据聚合输出一行数据
* @author: yang
* @create: 2021-01-16 16:41
*/
object aggFunc {
def main(args: Array[String]): Unit = {
//1、基于流执行环境创建table执行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val tableEnv: StreamTableEnvironment = StreamTableEnvironment.create(env)
//2、读取文件,注册表视图
tableEnv.connect(new FileSystem().path("E:\\java\\demo\\src\\main\\resources\\file\\data5.csv"))
.withFormat(new Csv())
.withSchema(new Schema()
.field("id", DataTypes.STRING())
.field("ts",DataTypes.BIGINT())
.field("temperature",DataTypes.DOUBLE()))
.createTemporaryTable("sensorTable")
val sensorTable: Table = tableEnv.from("sensorTable")
//table api
val aggTemp = new AggTemp()
val apiResult: Table = sensorTable.groupBy('id).aggregate(aggTemp('temperature) as 'vagTemp).select('id, 'vagTemp)
//sql 实现
tableEnv.registerFunction("avgTemp",aggTemp)
val sqlResult: Table = tableEnv.sqlQuery(
"""
|select id,avgTemp(temperature)
|from sensorTable
|group by id
""".stripMargin)
apiResult.toRetractStream[Row].print("apiResult")
sqlResult.toRetractStream[Row].print("sqlResult")
env.execute("agg Func")
}
}
//定义一个类,专门用于聚合的状态
class AvgTempAcc{
var sum :Double = 0.0
var count:Int = 0
}
//自定义一个聚合函数,求每个传感器的平均温度值,保存状态(tempSum,tempCount)
class AggTemp extends AggregateFunction[Double,AvgTempAcc]{
//处理计算函数
def accumulate(accumulator:AvgTempAcc,temp:Double): Unit ={
accumulator.sum += temp
accumulator.count += 1
}
//计算函数
override def getValue(accumulator: AvgTempAcc): Double = accumulator.sum / accumulator.count
//初始化函数
override def createAccumulator(): AvgTempAcc = new AvgTempAcc
}
4、表聚合函数
-
1、用户定义的表聚合函数(User-Defined Table Aggregate Functions,UDTAGGs),可以把一 个表中数据,聚合为具有多行和多列的结果表。
这跟 AggregateFunction 非常类似,只是之 前聚合结果是一个标量值,现在变成了一张表。用户定义的表聚合函数,是通过继承 TableAggregateFunction 抽象类来实现的。 -
2、TableAggregateFunction 的工作原理如下:
首先,它同样需要一个累加器(Accumulator),它是保存聚合中间结果的数据结构。 通过调用 TableAggregateFunction的createAccumulator()方法可以创建空累加器。
随后,对每个输入行调用函数的 accumulate()方法来更新累加器。
处理完所有行后,将调用函数的 emitValue()方法来计算并返回最终结果。 -
3、AggregationFunction 要求必须实现的方法: createAccumulator() 、accumulate()
除了上述方法之外,还有一些可选择实现的方法:retract()、 merge() 、resetAccumulator()、 emitValue()、emitUpdateWithRetract()
package guigu.table.udf
import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api.{DataTypes, FlatAggregateTable, Table}
import org.apache.flink.table.api.scala._
import org.apache.flink.table.descriptors.{Csv, FileSystem, Schema}
import org.apache.flink.table.functions.TableAggregateFunction
import org.apache.flink.types.Row
import org.apache.flink.util.Collector
/**
* @program: demo
* @description: 多行数据聚合输出多行数据
* @author: yang
* @create: 2021-01-16 18:48
*/
object tableAggFunc {
def main(args: Array[String]): Unit = {
//1、基于流执行环境创建table执行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val tableEnv: StreamTableEnvironment = StreamTableEnvironment.create(env)
//2、读取文件,注册表视图
tableEnv.connect(new FileSystem().path("E:\\java\\demo\\src\\main\\resources\\file\\data5.csv"))
.withFormat(new Csv())
.withSchema(new Schema()
.field("id", DataTypes.STRING())
.field("ts",DataTypes.BIGINT())
.field("temperature",DataTypes.DOUBLE()))
.createTemporaryTable("sensorTable")
val sensorTable: Table = tableEnv.from("sensorTable")
//table api
val top2Temp = new Top2Temp()
val resultTable: Table = sensorTable.groupBy('id).flatAggregate(top2Temp('temperature) as('temp, 'rank))
.select('id,'temp,'rank)
resultTable.toRetractStream[Row].print("flat agg")
env.execute(" table agg func")
}
}
//定义一个类,表示表聚合函数的状态
class Top2TempAcc{
var highestTemp:Double = Double.MinValue
var secondHighestTemp:Double = Double.MinValue
}
//自定义表聚合函数,提取所有温度值中最高的两个温度,输出(temp,rank)
class Top2Temp extends TableAggregateFunction[(Double,Int),Top2TempAcc]{
//初始化函数
override def createAccumulator(): Top2TempAcc = new Top2TempAcc()
//实现计算聚合结果的函数accumulate
//注意:方法名称必须叫accumulate
def accumulate(acc:Top2TempAcc,temp:Double): Unit ={
//判断当前温度值是否比状态值大
if(temp > acc.highestTemp){
//如果比最高温度还高,排在第一,原来的顺到第二位
acc.secondHighestTemp = acc.highestTemp
acc.highestTemp = temp
}else if(temp > acc.secondHighestTemp){
//如果在最高和第二高之间,那么直接替换第二高温度
acc.secondHighestTemp = temp
}
}
//实现一个输出结果的方法,最终处理完表中所有的数据时调用
//注意:方法名称必须叫emitValue
def emitValue(acc:Top2TempAcc,out:Collector[(Double,Int)]): Unit ={
out.collect((acc.highestTemp,1))
out.collect((acc.secondHighestTemp,2))
}
}



















 2541
2541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











