




一、径向基函数神经网络(RBF)
1.简述
RBF神经网络是一种前馈神经网络。由输入层、隐藏层、输出层组成。
输入层负责接收外部输入数据,其神经元数量等于输入特征的数量;
隐含层由多个 RBF 神经元组成每个 RBF 神经元都有一个中心向量和一个宽度参数。RBF 神经元的激活函数通常采用高斯函数等径向基函数(径向基函数以中心点为基准,输出值取决于输入数据与该中心点的距离),输入数据经过隐藏层的径向基函数从原始的输入空间映射到一个高维的特征空间,在高维空间中进行线性或非线性的操作;
输出层将隐含层的输出进行线性组合,产生最终的输出。输出层神经元的数量取决于要预测的目标数量。
确定了隐含层的参数后可以采用最小二乘法或梯度下降法来计算输出层的权重。

下面代码使用RBF神经网络对光谱数据进行回归分析,预测汽油样本的辛烷值。
2.代码
clear
clc
%导入数据
load spectra_data.mat
%随机产生训练集和测试集
%对得到的训练集和测试集进行转置,确保每个数据集的列都表示样本的个数,用于构建神经网络
temp = randperm(size(NIR, 1));
% 训练集
train_x = NIR(temp(1 : 50), :)';
train_y = octane(temp(1 : 50), :)';
% 测试集
test_x = NIR(temp(51 : end), :)';
test_y = octane(temp(51 : end), :)';
N = size(test_x, 2);
%创建RBF神经网络
%第三个传入参数表示径向基函数的散布,传入参数越大,函数逼近就越平滑
net = newrbe(train_x, train_y, 30);
%测试
sim_y = sim(net, test_x);
%计算相对误差
error = abs(sim_y - test_y) ./ test_y;
%计算决定系数R^2
R2 = (N * sum(sim_y .* test_y) - sum(sim_y) * sum(test_y))^2 / ((N * sum((sim_y).^2) - (sum(sim_y))^2) * (N * sum((test_y).^2) - (sum(test_y))^2));
%绘图
figure
plot(1 : N, test_y, 'b:*', 1 : N, sim_y, 'r-o');
%legend函数为每个绘制的数据序列创建一个带有描述性标签的图例
legend('真实值','预测值');
xlabel('预测样本');
ylabel('辛烷值');
3.运行结果

二、广义回归神经网络(GRNN)、概率神经网络(PNN)
1.简述
GRNN神经网络
GRNN神经网络属于径向基神经网络的一种变形形式,由输入层、模式层、求和层、输出层组成
输入层的输入层节点数与输入向量的维数相等,各个节点直接将输入样本传输到模式层中。
模式节点数与输入层节点数相同,模式层的传递函数为径向基函数,与RBF神经网络相同
求和层包含两个子层,分别是加权求和层和非线性求和层。加权求和层计算所有模式层节点输出的加权和,非线性求和层计算所有加权值的非线性函数值。
输出层根据求和层提供的结果生成最终的输出结果。输出层通常只包含一个节点,该节点的值为加权求和层的输出除以非线性求和层的输出。输出结果与平滑因子相关,平滑因子过大时,会导致测量结果趋于样本数据的均值;平滑因子过小会导致测量结果接近训练样本值,使神经网络的泛化性能变差。
PNN神经网络
PNN同样由输入层、模式层、求和层、输出层组成。
输入层和模式层与GRNN相类似,使用径向基函数计算输入向量与训练集中每个样本之间的相似度。将输入空间映射到一个高维空间,在高维空间中执行分类。
模式层的输出被传递给求和层。求和层中的对应节点累加所有属于每个类别的模式层节点的输出值,计算新样本属于某一类别的证据总和。本质是基于贝叶斯分类理论,目的是为了计算每个类别的后验概率。
输出层从求和层提供的信息中确定最终的分类结果,选择具有最大后验概率的类别作为预测结果。

下面代码使用GRNN和PNN神经网络对鸢尾花数据集进行分类并对比测试结果。
2.代码
clear
clc
% 导入数据
load iris_data.mat
% 随机产生训练集和测试集
%初始化训练集和测试集
%由于后续需要执行拼接操作,无法提前确定训练集和测试集的大小,因此用[]来初始化空矩阵
train_x = [];
train_y = [];
test_x = [];
test_y = [];
%数据中一共有三个类别,需循环遍历三个类别,分段划分三个训练集和测试集再拼接在一起
for i = 1:3
%temp临时存储每一类的数据
temp_input = features((i - 1) * 50 + 1 : i * 50, :);
temp_output = classes((i - 1) * 50 + 1 : i * 50, :);
n = randperm(50);
%执行拼接操作并转置
train_x = [train_x temp_input(n(1:40), :)'];
train_y = [train_y temp_output(n(1:40), :)'];
test_x = [test_x temp_input(n(41:50), :)'];
test_y = [test_y temp_output(n(41:50), :)'];
end
%分别初始化GRNN和PNN的结果存储矩阵
%矩阵的每一列表示使用不同特征组合时的预测结果
result_grnn = [];
result_pnn = [];
%遍历每个可能的输入特征起始点
for i = 1:4
%遍历每个可能的输入特征终点
for j = i:4
%根据当前的起始和结束点选取对应的训练集和测试集输入特征
train_X = train_x(i : j, :);
test_X = test_x(i : j, :);
%%
%创建GRNN神经网络
net_grnn = newgrnn(train_X, train_y);
%测试得到预测结果
t_sim_grnn = sim(net_grnn, test_X);
%将预测结果取整
T_sim_grnn = round(t_sim_grnn);
%通过拼接存储预测结果
result_grnn = [result_grnn T_sim_grnn'];
%%
%将训练集的结果转换为向量形式,目的是将类别索引转换成一个稀疏矩阵,保证其中的每一列对应一个样本,每一行对应一个类别
train_yc = ind2vec(train_y);
% 创建PNN神经网络
net_pnn = newpnn(train_X, train_yc);
%将测试集的结果转换为向量形式
test_yc = ind2vec(test_y);
%测试得到预测结果
t_sim_pnn = sim(net_pnn, test_X);
%反向操作,将结果转换回整形
T_sim_pnn = vec2ind(t_sim_pnn);
%通过拼接存储预测结果
result_pnn = [result_pnn T_sim_pnn'];
end
end
%计算两个模型的正确率
% 初始化空向量用于存储GRNN和PNN在不同特征组合下的正确率
accuracy_grnn = [];
accuracy_pnn = [];
%%
%循环遍历每个特征组合的结果并将其拼接到正确率向量内
for i = 1:10
%计算在某个特征组合下的两个模型的正确率
%用find函数判断实际结果与预测结果在相应位置上的值是否相等
%用length函数计算find函数返回值的长度,即预测正确的样本数量
%result_grnn(:,i)表示第i种特征组合对应的预测结果
%将test_y转置为行向量,以便与result_grnn(:,i)进行比较
accuracy_1 = length(find(result_grnn(:,i) == test_y'))/length(test_y); % 对于GRNN模型,计算其预测结果与测试集真实标签匹配的比例,即准确率
accuracy_2 = length(find(result_pnn(:,i) == test_y'))/length(test_y); % 对于PNN模型,同样计算其预测结果与测试集真实标签匹配的比例,即准确率
%将当前两个模型的准确率添加到准确率向量中
accuracy_grnn = [accuracy_grnn accuracy_1];
accuracy_pnn = [accuracy_pnn accuracy_2];
end
%将GRNN和PNN模型的正确率合并成一个矩阵,便于绘图和比较
accuracy = [accuracy_grnn; accuracy_pnn];
%%
%绘图
figure(1)
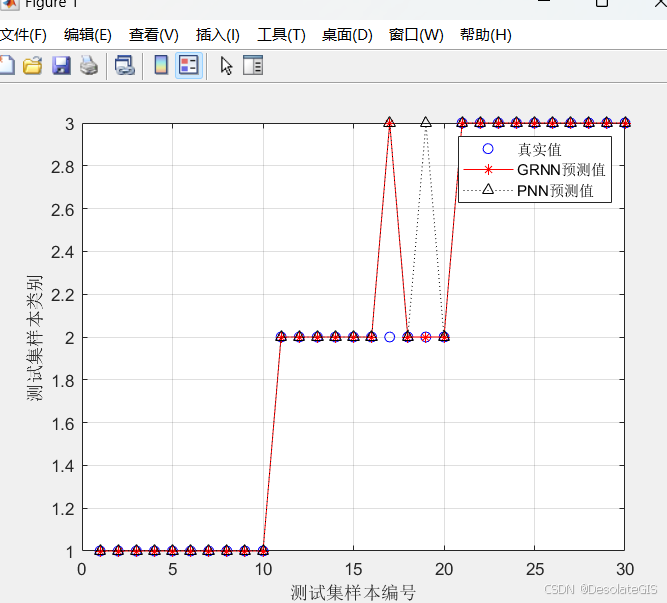
%绘制在一个特征组合下的真实值和预测值进行对比
plot(1:30, test_y, 'bo', 1:30, result_grnn(:,4), 'r-*', 1:30, result_pnn(:, 4), 'k:^')
%打开网格线
grid on
%设置x,y轴标签
xlabel('测试集样本编号')
ylabel('测试集样本类别')
%用legend函数添加图例,标识不同的数据
legend('真实值', 'GRNN预测值', 'PNN预测值')
figure(2)
%绘制10个特征组合下两模型测试集的正确率对比图
plot(1:10, accuracy(1, :), 'r-*', 1:10, accuracy(2, :), 'b:o')
grid on
xlabel('模型编号')
ylabel('测试集正确率')
legend('GRNN', 'PNN')
3.运行结果


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









