





思路
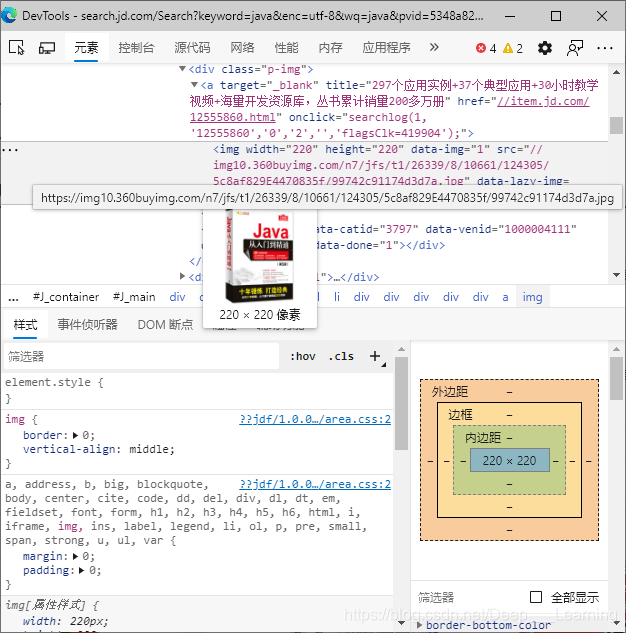
我们可以通过构造URL来获取相应的商品页面,然后从页面中提取想要的信息即可,这里以Java为关键字,提取商品的名称、商品的价格和商品封面图片的地址。
使用了Jsoup库来解析页面和提取信息,并且写了一个商品类,用ArrayList来存储每次爬到的商品,最后用BufferedWriter将全部商品的信息保存到txt文件中。

代码
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.net.URL;
import java.util.ArrayList;
/**
* 爬取京东商品数据
* 如何爬取数据?
* 获取请求返回的页面,从页面中筛选出我们想要的数据
*/
public class JDCommoditySpider {
public static void main(String[] args) throws Exception {
String keyword = "java";
String url = "https://search.jd.com/Search?keyword=" + keyword;
ArrayList<Commodity> arrayList = new ArrayList<>();
Document document = Jsoup.parse(new URL(url), 30000);
Element element = document.getElementById("J_goodsList");
// 获取所有的li标签
Elements elements = element.getElementsByTag("li");
for (Element el : elements) {
String imgURL = el.getElementsByTag("img").eq(0).attr("src");
String price = el.getElementsByClass("p-price").eq(0).text();
String name = el.getElementsByClass("p-name").eq(0).text();
if (!imgURL.equals("") && !price.equals("") && !name.equals("")) {
arrayList.add(new Commodity(name, price, imgURL));
}
}
BufferedWriter bufferedWriter = new BufferedWriter(new FileWriter(new File("src/result/jdData.txt")));
for (Commodity item : arrayList) {
System.out.println(item.toString());
bufferedWriter.write(item.toString()+"\n");
}
bufferedWriter.flush();
bufferedWriter.close();
}
}
/**
* 商品类
*/
class Commodity {
private String name; // 商品的名称
private String price; // 商品的价格
private String imgURL; // 商品图片的地址
public Commodity(String name, String price, String imgURL) {
this.name = name;
this.price = price;
this.imgURL = imgURL;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPrice() {
return price;
}
public void setPrice(String price) {
this.price = price;
}
public String getImgURL() {
return imgURL;
}
public void setImgURL(String imgURL) {
this.imgURL = imgURL;
}
@Override
public String toString() {
return "Commodity{" +
"name='" + name + '\'' +
", price='" + price + '\'' +
", imgURL='" + imgURL + '\'' +
'}';
}
}
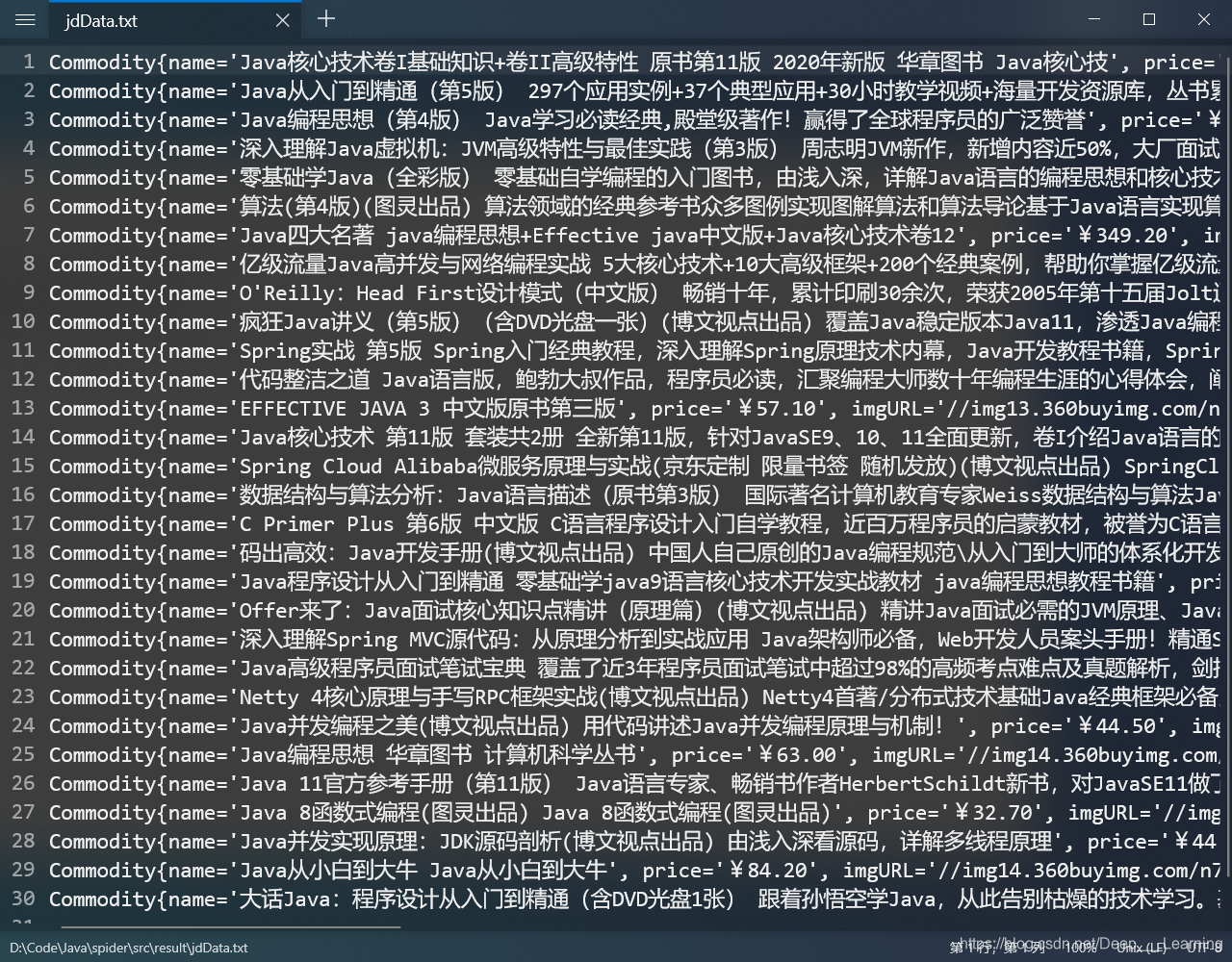
结果

总结
这次只爬取了一页的商品信息,对于其他页面的商品信息,构造URL即可(在URL中加入对应的页码参数),操作和思路都是一样的。



















 1278
1278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









