



Datawhale干货
作者:周远哲,Kaggle全球排名第一
作者是 Kaggle 目前全球排名第一选手,获得多个大规模量化竞赛的 top3,专注于时序预测、量化建模领域。
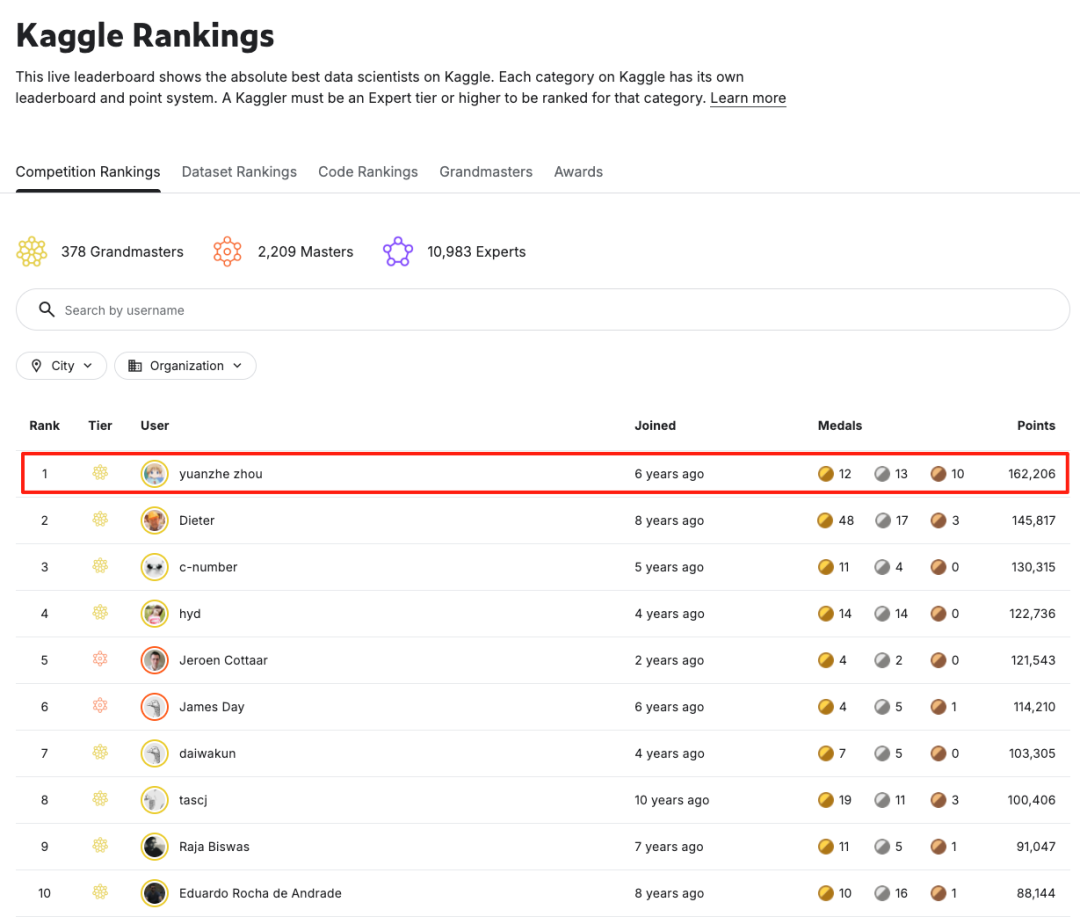
这篇分享将介绍我在两个月内获得五枚金牌并达成Kaggle Competition Grandmaster的一些经验和发现,以及我在五个Kaggle比赛中获得金牌的方案。在赢得这5枚金牌后,我也正式登顶了Kaggle全球排名第一。
掌控风险,赢得比赛
Kaggle上的赛题可粗略分为确定性高的赛题与确定性低的赛题。
确定性高的赛题通常竞争激烈,因为大家都知道公榜高分就是金牌,往往会有同一公司的几名员工组成多个团队参赛,有些人带着公司的KPI参加比赛,竞争自然更加激烈
确定性低的赛题一般竞争较弱,但由于比赛的不确定性大,最终获奖的机会也不会特别大
由于大部分人对不同比赛的确定性定义不同,这其中存在套利空间。如果能更精确地定义比赛的确定性与风险,就能极大提升获取金牌的机会。
对于不同能力的选手来说,比赛的风险程度也不同。例如,擅长CV的选手认为CV相关比赛等于白送一枚金牌,而对我而言,参加CV相关比赛则风险较大。类似地,如果能通过独特途径低成本对冲风险,那么获取收益的能力就会大大提升。
一般来说,比赛最大的忌讳是随机和路人组队,经常看到有人抱怨路人队友。但由于我多次和一些从未获得过金牌的潜力型路人选手组队,帮助他们拿到人生第一块金牌,因此我对他们离金牌所欠缺的因素有所了解。大部分人在能力上是有机会获得金牌的,许多人主要欠缺的是对方案风险(例如过拟合)的清晰认知。提升对这些方面的理解,就能极大增加获取金牌的机会。
目前Kaggle上与大模型相关的比赛越来越多,但很多赛题定义不佳,或者是暂时悬而未决的类型,这类题目可以在短时间内轻松实现金牌方案。例如"Make Data Count - Finding Data References"比赛,只需爬取比赛方的官方数据集就能获得接近金牌的分数。还有一些题目,只需将预测值放大或缩小就能取得前几名。
接下来就有一个最新的过拟合实际案例,我会讲讲自己如何避免过拟合、验证集设计和比赛策略的经验。
最新过拟合实际案例
最近刚结束的Mitsui量化比赛中,有一个日本选手开源的notebook被很多人fork并提交。这个选手在特征中没有引入未来信息,但是通过验证集引入了大量的未来信息。这个notebook如果直接提交会发现最高分数为0.556,这已经是一个非常高的分数了。
但是如果简单去掉训练集最后134天数据再进行训练,可以发现分数跌到了0.113。由此可以发现这个notebook实际上在做的事情是:验证集如果分数高就选择最好的round预测,如果分数低就预测历史均值(round0)。这样的话等于是在fit之后再根据验证集的表现做了424次筛选。建模中最容易过拟合的一种方式便是筛选数据进行过拟合,这也是为什么这个notebook在公榜上可以取得较高分数。
反过来说,如果模型不进行数据筛选依然可以取得比较高的分数,那么模型的可靠度就会更高。
由于这个比赛没有公私榜,榜单分数和我提供的baseline计算出来的分数完全一致,因此提交其实没有任何意义,反而会影响迭代速度,可以说所有的参赛者都是"零拳超人"。
这里给出我的验证集分数作为参考。我选择了最后的500天作为我的验证集(过拟合),而没有选择去过拟合最近的134天数据,因为最近的这一段数据似乎特别容易拟合。
最终的结果如下:
最后500天分数:
sharpe ~7.0
score ~0.53
最后134天分数:
sharpe ~10.0
score ~0.65
60天滑动窗口最低score为0.41
60天滑动窗口最高score为1.0+
目前来看,由于实际数据量较小,这个赛题最大的风险应该是模型分数为负数的情况,这种情况不如随机预测可以获得的0分。
以上是我在两个月内获得五枚金牌并达成Kaggle Competition Grandmaster的经验分享。希望这些思路和方法对大家参加Kaggle比赛有所帮助!
接下来,介绍我在这两个月内的五个Kaggle比赛中获得金牌的方案。
这五个比赛分别是:
BirdCLEF+ 2025
Yale/UNC-CH - Geophysical Waveform Inversion
Jane Street Real-Time Market Data Forecasting
Konwinski Prize
CMI - Detect Behavior with Sensor Data
其中两枚金牌在几个月前的比赛中已基本确定能够获得,只是在最近两个月的时间窗口内正式达成。下面将按顺序介绍各比赛的主要思路,感兴趣的同学可以自行查看。
BirdCLEF+ 2025
赛题介绍
这是一个用于生物多样性监测的声景识别数据集,旨在通过音频分析技术自动识别哥伦比亚雨林中的动物叫声。

🌿 生态保护背景
研究区域:数据采集自哥伦比亚El Silencio自然保护区
保护意义:准确识别物种叫声有助于科学家更有效地监测动物种群,为保护生物学提供重要工具
🎧 数据构成数据集包含三种类型的音频数据:
训练音频(train_audio):来自三个数据库的单个物种叫声片段
Xeno-canto.org(鸟类)
iNaturalist(多类生物)
哥伦比亚声音档案馆
测试声景(test_soundscapes):约700段1分钟环境录音,包含混合物种声音
训练声景(train_soundscapes):未标注的现场环境录音
🐦 物种覆盖
4大类群:鸟类、两栖动物、哺乳动物、昆虫
206个具体物种:每个物种都有唯一的识别代码
多标签标注:部分录音标注了同时出现的多个物种
📊 数据特色
真实场景挑战:测试声景包含复杂的自然环境声音
地理多样性:提供录音地点的经纬度信息,考虑地域性叫声差异
质量评级:部分训练数据有1-5星质量评分
多源数据整合:融合了专业机构与公民科学家的贡献
方案介绍
BirdCLEF是Kaggle上非常传统的赛事,每年举办一次。去年我遗憾地位居金牌区边缘,今年便卷土重来。今年的比赛相较于往年有一些改进:一是评估指标使用了AUC,使AB榜单更加稳定;二是加入了非鸟类类别。
由于时间有限,我在比赛结束前一周才开始认真研究题目。Fork了开源代码并修复一些bug后,分数已接近金牌区。这里必须感谢高质量的开源代码,稍作修改就能获得不错的分数。BirdCLEF系列比赛有一个传统,即使用伪标签与数据蒸馏进行训练,本次比赛也不例外。能够正确实现并利用伪标签的队伍基本都能进入金牌区附近。主要的模型贡献来自组队后的队友,我主要尝试在提升单模型性能后,通过伪标签融合进一步提升效果。
这场比赛比较遗憾的是最后一天多次提交出错,其实只要有一次成功提交就能进入前五甚至更好。这也给了我一个宝贵的教训:比赛时最好在倒数第二天就准备好最终提交方案,以留出更多的容错空间。
Yale/UNC-CH - Geophysical Waveform Inversion

这个比赛没有太多特别之处。由于可以无限生成数据,加上开源方案已经达到了较高分数,只需要有足够的算力就能稳定获得金牌。我在比赛结束前三天才开始认真训练模型,导致模型在比赛结束时远未收敛。如果比赛时间再长一些,按照当时的提升速度,应该能稳定进入前三名。
这个比赛最重要的一个技术点是充分利用CUDA计算,将数据生成速度提升了几十倍。这一点其实也是比赛前排选手的常规操作——利用 GPU并行加速数据生成,比用 CPU 快很多倍。
Jane Street Real-Time Market Data Forecasting
赛题介绍
数据概览:
特征:包含79个匿名市场特征(
feature_00至feature_78)目标:共有9个匿名响应变量(
responder_0至responder_8),其中responder_6是本次竞赛唯一需要预测并用于评分的指标结构:每条数据记录代表在某个特定时间点(由
date_id和time_id定义)的某一只金融工具(由symbol_id定义)
方案介绍
这个比赛应该是大多数人最感兴趣的,因为获得金牌就可以作为绝大多数私募机构的敲门砖。

这个比赛数据量较大,因此AB榜单相对稳定。从最终结果来看,直接将之前Optiver比赛的方案迁移过来,不做太多修改就能进入前三名,这让我感觉有些尴尬……或许比赛第一天就"躺平"也是个不错的选择?
比赛一个有趣的现象是:最后两天有几个队伍的分数提升了超过10个基点(basic point),这一巨大提升很可能来自于特征工程。分析比赛数据可以发现,数据类型主要分为:
分钟频率特征
日频率特征
这里的分钟频率特征只包含当天的统计信息,而不包含前几天或更早的历史信息(可能包含但不多)。从建模角度来看,这些匿名特征缺失了不少信息。只需简单地使用前一天的数据构建一些特征,就能提升十几个基点。相信很多银牌队伍通过添加这类特征,可以直接跃升至前四名。
比赛的另一个重要提升点是对数据的选择。我在比赛初期发布的基线模型中就主动加入了这一部分,例如去除了最初500天的数据,这为帮助许多参赛者节省了探索时间。
Konwinski Prize
赛题介绍
这是一个出乎我的意料能这么稳地拿到金牌的比赛,总共只投入了几个小时。
这个比赛的核心目标是开发一个能解决真实世界GitHub问题的智能体。竞赛基于著名的SWE-bench基准测试,并采用了一种创新的竞赛机制以确保公平性。
下表汇总了该数据集的核心信息:
关键方面 | 具体说明 |
|---|---|
竞赛目标 | 构建能解决真实GitHub问题的AI智能体,在防止数据污染的测试集上评估性能 |
数据核心 | 基于SWE-bench,但使用了在模型训练完成之后才收集的GitHub问题作为私有测试集 |
竞赛机制 | 分为两个阶段:模型训练期(使用历史数据)和预测期(使用未来新数据) |
测试环境 | 采用Kaggle的forecasting格式,测试实例随机且逐个通过API提供 |
关键特征 | 包含problem_statement(问题描述)、patch(解决方案补丁)、base_commit(基准提交)及单元测试列表 |
技术挑战 | 需要处理完整的代码库、进行多文件修改,并确保通过严格的fail_to_pass单元测试 |
🔍 数据集的独特性与挑战
这个数据集和竞赛最显著的特点是致力于解决AI领域一个棘手的问题——数据污染(即模型训练时,如果训练数据中已混入基准测试内容,会导致评估结果失真)。
纯净的排行榜:竞赛主办方Andy设立100万美元奖金,旨在激励开发者创建在"未见过的"GitHub问题上表现卓越的模型,产生真正反映模型泛化能力的排行榜
真实世界的任务:与仅生成代码片段的测试不同,此竞赛要求AI智能体像人类开发者一样,在复杂代码库中导航,理解问题,并实施正确且能通过测试的修改。测试任务通常涉及多文件、上百行的代码变更
严格的评估标准:解决方案的成功不仅在于让失败的测试通过(FAIL_TO_PASS),还必须确保所有原本通过的测试依然通过(PASS_TO_PASS),以验证修复没有引入新错误
方案思路
这个比赛的一个有趣之处在于,可以通过跳过一些问题来避免无效回答,因为模型当前能力尚不足,而评价指标对错误回答的惩罚很大。这种做法与量化交易策略类似:只在把握较大时进行"交易",即使一个原本可能不盈利的策略也能被利用来盈利。
开源notebook通过仅回答前6个问题实现了高分,这是一种风险很大的筛选方式,但同时也带来了机会:当许多队伍对风险缺乏认知时,正确处理风险可以轻松取胜。
赛题中存在不同类型的问题,有些问题的解决率较高,有些则较低,难易程度差异明显,因此存在很大的"套利空间"。只需排除错误率较高的题目,就能保证获得前排分数。
我通过更智能地选择要回答的问题,在公榜期间通过重复提交发现结果非常稳定,从而轻松获得了一枚金牌。
CMI - Detect Behavior with Sensor Data
赛题介绍
这是CMI系列比赛的第三场,竞争异常激烈,前Kaggle世界排名第一的Psi和Guanshuo Xu都参加了比赛。我参加这场比赛是因为发现CV和LB的相关度很高,同时它也是我比较擅长的时间序列相关赛题,因此对获得第一名比较有把握。比赛中的主要困难始终是如何确保百分之百锁定第一名,也非常幸运能够在最后获得第一名并且登顶Kaggle全球第一名!感谢队友、所有参赛者以及主办方让这个比赛变得十分精彩。
比赛的核心是验证多模态数据是否有助于基于加速度计数据预测行为。
数据介绍
🎯 研究目标分类8种BFRB手势和10种非BFRB手势,通过手腕佩戴的传感器识别重复性行为模式。
📡 多传感器配置设备包含三种传感器类型:
1个IMU传感器:提供加速度(acc_x/y/z)和旋转姿态(rot_w/x/y/z)
5个热堆传感器(thermopile):测量温度(thm_1-5)
5个飞行时间传感器(ToF):测量距离,每个传感器提供8×8=64个像素数据(tof_1-5_v0-63)
🗂 数据特色
序列化结构:每个sequence包含Transition、Pause、Gesture三个阶段
多被试数据:包含不同受试者的人口统计信息(年龄、性别、身高等)
真实场景挑战:存在传感器通信故障导致的缺失数据
测试集设计:50%序列仅包含IMU数据,用于评估不同传感器的贡献
模型思路
1. 寻找预训练数据
时间序列模型训练的一个痛点是数据不足,因此我最初的思路是寻找额外数据对模型进行预训练,再进行微调。多次尝试后发现,预训练确实可以加速模型收敛,但对最终分数几乎没有提升,因此最终放弃了这一思路。
2. 尝试预训练模型
通过尝试不同的预训练backbone作为encoder或decoder,我发现对分数有一定提升,但这种提升对于最终模型融合的效果微乎其微。而且预训练模型尺寸较大,成本效益不高,因此这一思路也被放弃。
3. 尝试最新论文中的思路
这是回报最差的探索方向。总结下来,获取到有效方法的论文通常与时间序列无关,而专门研究时间序列的论文帮助不大。这可能与个人的研究深度有关,由于我已了解目前能查到的前沿信息,因此可能觉得没有收益。
建模思路
这个赛题有两种不同的数据:一种包含多模态数据,一种仅包含IMU数据。这带来了多种建模选择:可以训练仅处理IMU数据的模型、仅处理多模态数据的模型,或者训练能同时处理两种数据的模型。例如,让两种数据共享同一个backbone可能使模型具有更好的泛化性能。
我们的最终方案是分开训练这两种模型,然后分别进行集成。
我选择的模型只采用了LSTM/GRU以及CNN1D这两种简单结构,偶尔配合attention结构,主要依靠特征工程和更精细的数据处理来提升分数。
我们在开源特征的基础上进行了扩充,去除了不合理的特征,包括:
时间序列上的差分
时间序列上的差分的差分
xyz相关数据的模长
通过开源代码中conv1d实现的低通或高通滤波器
转换坐标轴后的差分特征
等等
我的方案通过双塔设计分别处理转换后的坐标轴信息(相对坐标轴)和原始坐标轴信息(绝对坐标轴),这种分开处理的方式对最终分数也有不可忽视的提升。
左右手处理
由于不同记录者对左右手的使用偏好不同,会导致不同的佩戴方式。通过将数据统一处理到右手坐标系中,可以稳定提升0.01的分数。以下是统一坐标系的处理代码:
def preprocess_left_handed(self, l_tr):
def handle_quaternion_missing_values(rot_data: np.ndarray) -> np.ndarray:
"""
Handle missing values in quaternion data intelligently
Key insight: Quaternions must have unit length |q| = 1
If one component is missing, we can reconstruct it from the others
"""
rot_cleaned = rot_data.copy()
for i in range(len(rot_data)):
row = rot_data[i]
missing_count = np.isnan(row).sum()
if missing_count == 0:
# No missing values, normalize to unit quaternion
norm = np.linalg.norm(row)
if norm > 1e-8:
rot_cleaned[i] = row / norm
else:
rot_cleaned[i] = [0.0, 0.0, 0.0, 0.0] # Identity quaternion
elif missing_count == 1:
# One missing value, reconstruct using unit quaternion constraint
# |w|² + |x|² + |y|² + |z|² = 1
missing_idx = np.where(np.isnan(row))[0][0]
valid_values = row[~np.isnan(row)]
sum_squares = np.sum(valid_values**2)
if sum_squares <= 1.0:
missing_value = np.sqrt(max(0, 1.0 - sum_squares))
# Choose sign for continuity with previous quaternion
if i > 0andnot np.isnan(rot_cleaned[i-1, missing_idx]):
if rot_cleaned[i-1, missing_idx] < 0:
missing_value = -missing_value
rot_cleaned[i, missing_idx] = missing_value
rot_cleaned[i, ~np.isnan(row)] = valid_values
else:
rot_cleaned[i] = [0.0, 0.0, 0.0, 0.0]
else:
# More than one missing value, use identity quaternion
rot_cleaned[i] = [0.0, 0.0, 0.0, 0.0]
return rot_cleaned
rot_cleaned = handle_quaternion_missing_values(l_tr[["rot_w","rot_x", "rot_y", "rot_z"]].to_numpy())
rot_scipy = rot_cleaned[:, [1, 2, 3, 0]]
norms = np.linalg.norm(rot_scipy, axis=1)
if np.any(norms < 1e-8):
# Replace problematic quaternions with identity
mask = norms < 1e-8
rot_scipy[mask] = [0.0, 0.0, 0.0, 1.0] # Identity quaternion in scipy format
r = R.from_quat(rot_scipy)
tmp = r.as_euler("xyz")
tmp[:,1] = - tmp[:,1]
tmp[:,2] = - tmp[:,2]
r = R.from_euler("xyz", tmp)
tmp = r.as_quat()
if np.any(norms < 1e-8):
mask = norms < 1e-8
tmp[mask] = [0.0, 0.0, 0.0, 0.0]
l_tr = l_tr.with_columns(pl.DataFrame(tmp, schema=["rot_x", "rot_y", "rot_z", "rot_w"]))
l_tr = l_tr.with_columns(-pl.col("acc_x"))
tmp = l_tr[["thm_3", "thm_5"]]
tmp.columns = ["thm_5", "thm_3"]
l_tr = l_tr.with_columns(tmp)
swap_1_2_4_base = [[0,7],[1,6],[2,5],[3,4], [4,3], [5,2],[6,1],[7,0]]
swap_3_5_base = [[0,56],[8,48],[16,40], [24,32],[32,24], [40,16],[48,8], [56,0]]
swap_1_2_4 = list()
for i in range(0,64,8):
ll = list()
for (k,l) in swap_1_2_4_base:
ll.append([k+i, l+i])
swap_1_2_4 += ll
swap_3_5 = list()
for i in range(8):
ll = list()
for (k,l) in swap_3_5_base:
ll.append([k+i, l+i])
swap_3_5 += ll
l_df = l_tr
for (k,l) in zip(["tof_3_v" + str(x) for x in range(64)], ["tof_5_v" + str(x) for x in range(64)]):
l_tr = l_tr.with_columns(l_df[k].alias(l))
for (k,l) in zip(["tof_3_v" + str(x) for x in range(64)], ["tof_5_v" + str(x) for x in range(64)]):
l_tr = l_tr.with_columns(l_df[l].alias(k))
l_df = l_tr
for i in [1,2,4]:
for (k, l) in swap_1_2_4:
l_tr = l_tr.with_columns(l_df["tof_" + str(i) + "_v"+str(k)].alias("tof_" + str(i) + "_v"+str(l)))
for i in [3,5]:
for (k, l) in swap_3_5:
l_tr = l_tr.with_columns(l_df["tof_" + str(i) + "_v"+str(k)].alias("tof_" + str(i) + "_v"+str(l)))
return l_tr后处理
分析后发现,比赛数据存在非常强的先验分布,利用这一先验分布可以略微提升最终分数。后处理的一个问题是:预测时数据是随机顺序的,因此需要在后处理时考虑使用更稳健的方法。我们通过线下验证集验证,发现分数浮动相对于提升幅度几乎可以忽略不计。
总结
最终的模型融合中,我和两名队友在没有后处理的模型中的贡献基本均等,不进行后处理的模型也可以拿到很高的金牌排名。加上后处理后,我们可能达到的最低分比其他队伍声称可能达到的最高分还要高。
时间序列问题的建模没有统一的方法论,需要根据不同问题进行调整。我们通过结合先验与后验信息,建立了相对于其他队伍的优势。我们最终提交的最低分比其他队伍的最高分还要高,确实达成了100%拿到第一名的目标。
实际建模不必迷信新颖的网络结构设计,许多论文中的方法未经充分验证,花费大量时间帮作者验证往往得不偿失。我们仅使用简单的RNN与CNN思路就取得了第一名,说明模型的创新并不是唯一的途径,充分分析数据和建模也可以达到最好的效果。
当然,模型创新带来的提升也不可忽视,我个人就拥有许多从未见过任何人使用过的创新方法,其中有些方法在博客中有所提及,属于静待有缘人了。但时间序列领域真正的创新往往不会公开发表,因此最好不要期望能从论文中获取太多有效信息。

一起“点赞”三连↓

















 4985
4985

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









