



Datawhale学术
最新评测:GraphRAG,整理:PaperAgent
6月有两篇关于GraphRAG技术评测的最新论文,涉及12种GraphRAG技术:HippoRAG、HippoRAG2、LightRAG、Fast-GraphRAG、RAPTOR、MGraphRAG、KGP、GraphRAG 、G-Retriever、DALK、ToG、GFM-RAG

论文1:When to use Graphs in RAG: A Comprehensive Analysis for Graph Retrieval-Augmented Generation
论文地址:https://arxiv.org/pdf/2506.05690
论文2:GraphRAG-Bench: Challenging Domain-Specific Reasoning for Evaluating Graph Retrieval-Augmented Generation
论文地址:https://arxiv.org/pdf/2506.02404
GraphRAG 是一种扩展的 RAG 范式,通过构建图结构来组织背景知识,其中节点代表实体、事件或主题,边代表它们之间的逻辑、因果或关联关系。它不仅检索直接相关的节点,还会遍历图以捕获相互连接的子图,从而发现隐藏的模式。
GraphRAG vs RAG
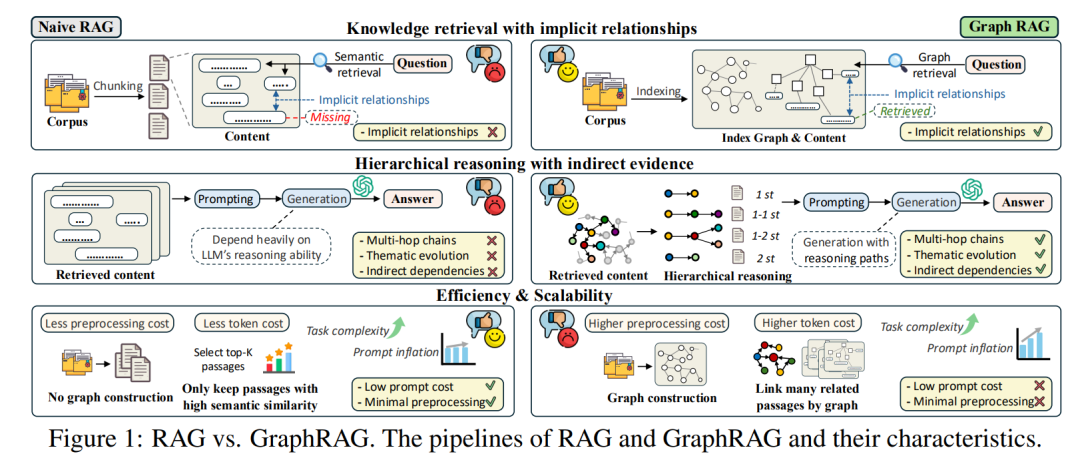
GraphRAG 是否真的有效,以及在哪些场景下图结构能为 RAG 系统带来可衡量的好处?
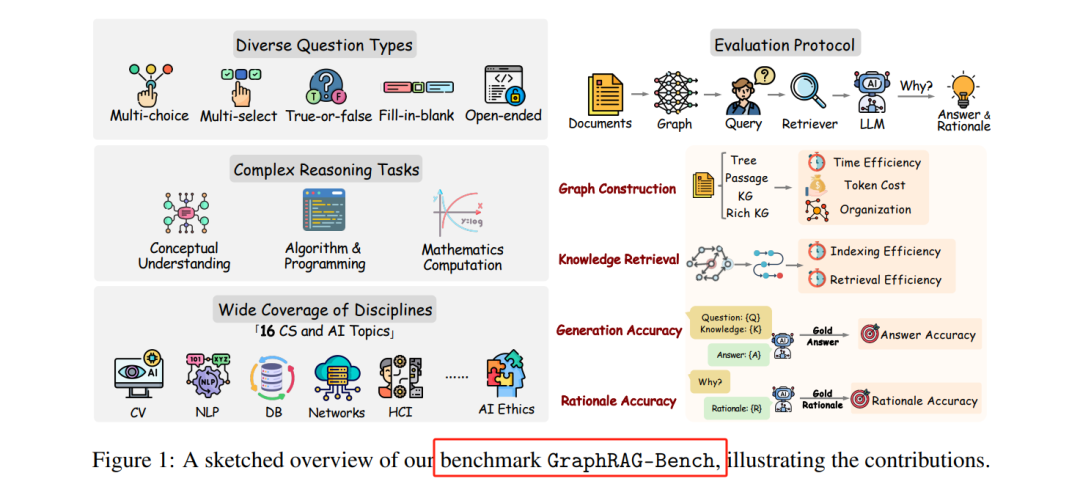
厦大和港理工提出的GraphRAG-Bench基准测试框架,旨在全面评估 GraphRAG 模型在分层知识检索和深度上下文推理中的表现:

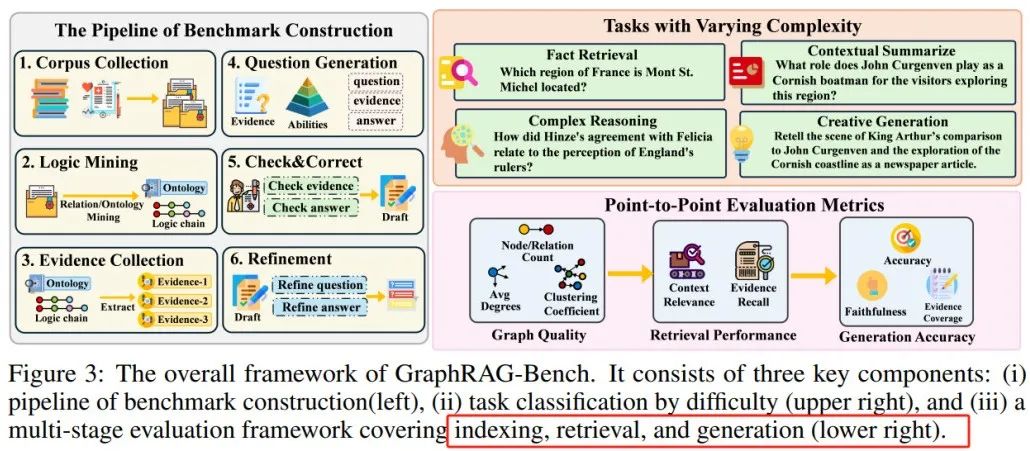
实验部分对 GraphRAG 和传统 RAG 进行了全面对比,得出以下结论:
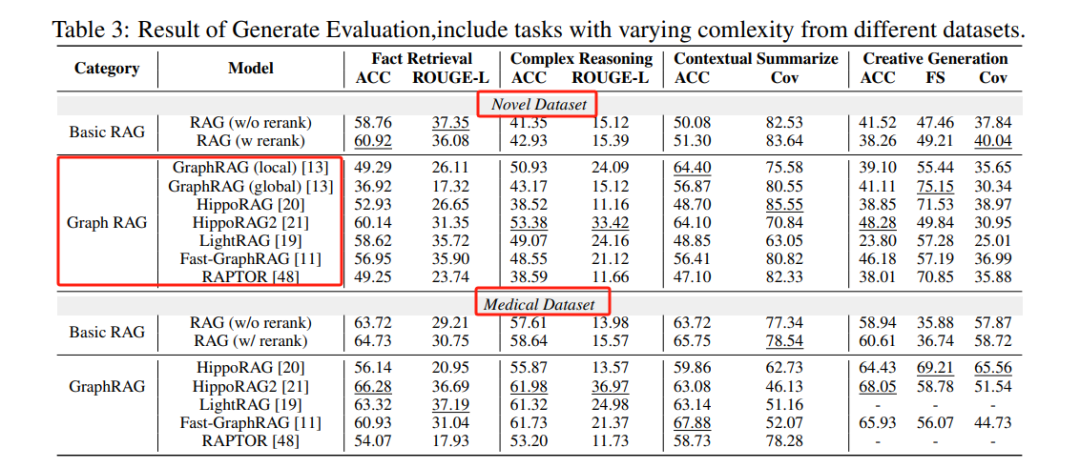
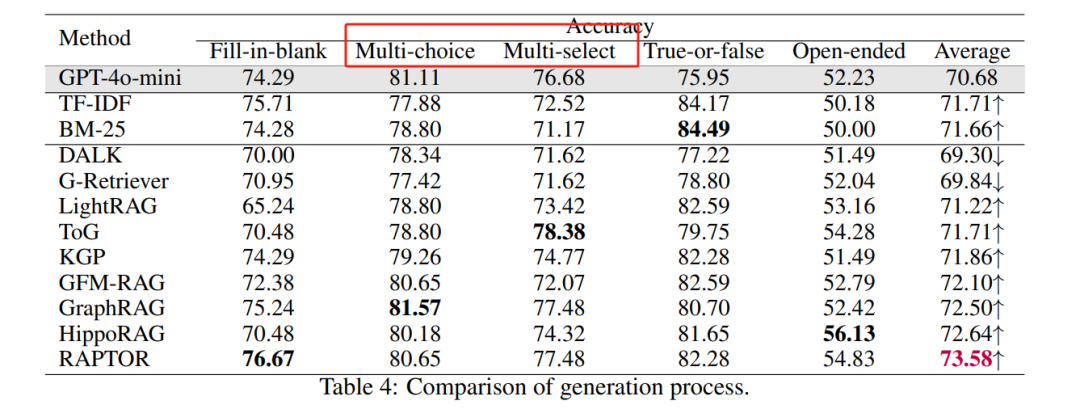
1. 生成准确性(Generation Accuracy):GraphRAG 在复杂推理、上下文总结和创造性生成任务中表现优于 RAG,但在简单事实检索任务中,RAG 的表现更好或相当。

2. 检索性能(Retrieval Performance):GraphRAG 在复杂问题上显示出优势,能够连接分散在不同文本片段中的信息,这对于多跳推理和全面总结至关重要。
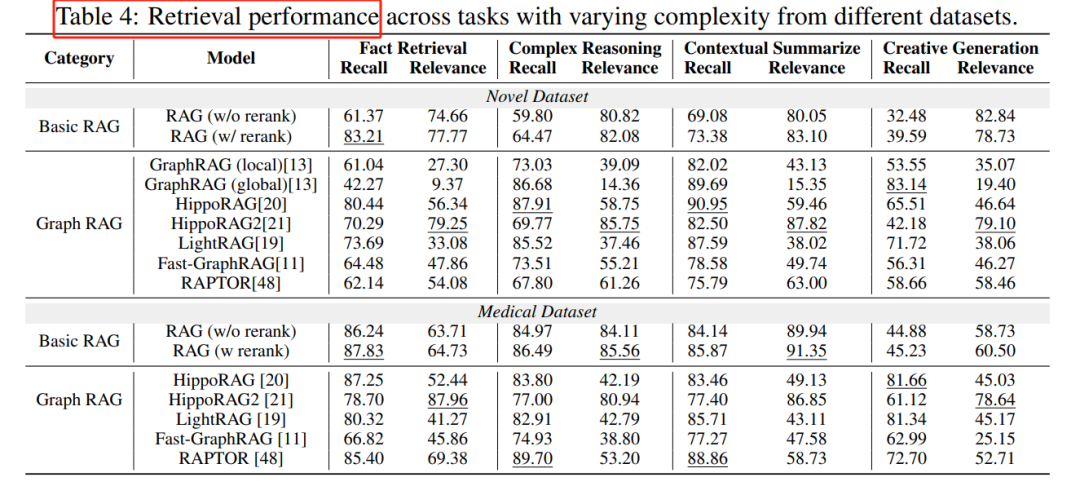
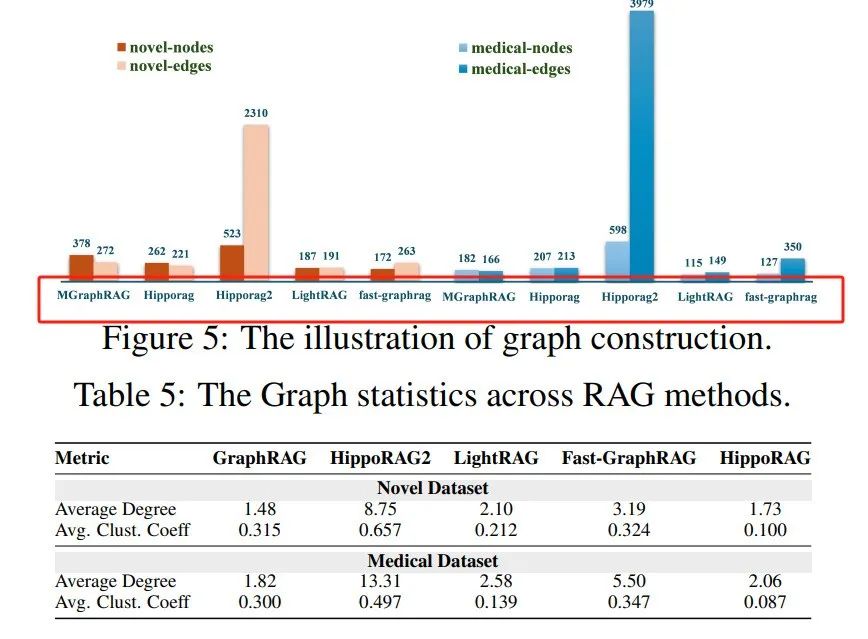
3. 图复杂性(Graph Complexity):不同的 GraphRAG 实现生成的索引图在结构上存在显著差异,例如 HippoRAG2 生成的图更为密集,节点和边的数量远超其他框架。
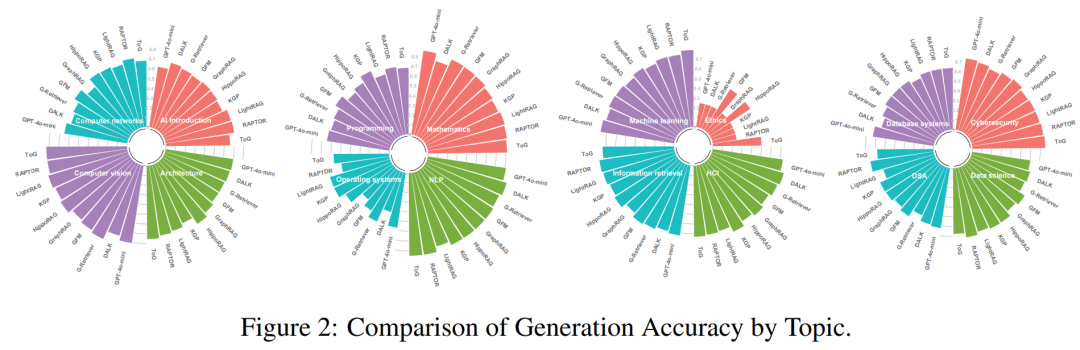
港理工和腾讯优图提出的GraphRAG-Bench更侧重于评估 GraphRAG 在特定领域推理中的表现。该基准测试包含 1018 个涵盖 16 个学科的大学水平问题,涉及多跳推理、复杂算法编程和数学计算等多种任务类型。

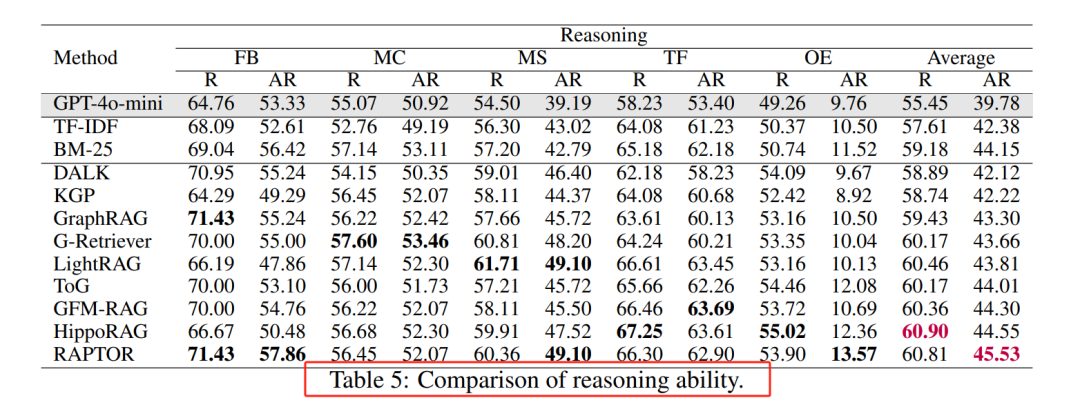
评估了九种最先进的 GraphRAG 方法,包括 RAPTOR、LightRAG、GraphRAG、G-Retriever、HippoRAG、GFM-RAG、DALK、KGP 和 ToG,得出关键结论:
GraphRAG 的优势:在复杂推理和多跳任务中,GraphRAG 显著优于传统 RAG 方法,尤其是在需要深度上下文理解和逻辑推理的任务中。
任务类型的影响:GraphRAG 在不同任务类型中的表现存在差异。例如,在数学和伦理学领域,其表现不如在计算机科学领域。
推理能力的提升:GraphRAG 方法不仅提高了生成的准确性,还显著提升了模型的推理能力,使其能够生成更符合逻辑的解释。
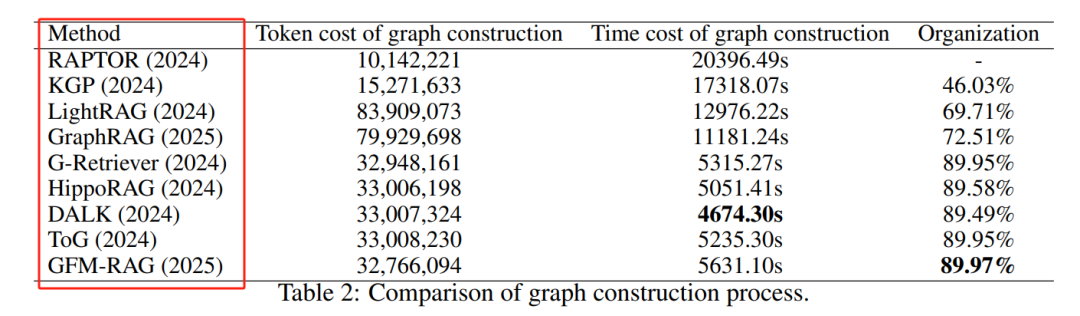
GraphRAG技术的图构建评估
RAPTOR 的图构建时间最长,但令牌消耗最少,因为它仅通过 LLM 生成总结。
KGP 的图构建时间较短,但令牌消耗较高。
GraphRAG 和 LightRAG 的图构建时间较长,且令牌消耗最多,因为它们生成了额外的描述信息。
G-Retriever 和 HippoRAG 的图构建时间最短,且非孤立节点比例最高(约 90%),表明它们在图构建质量上表现最佳。
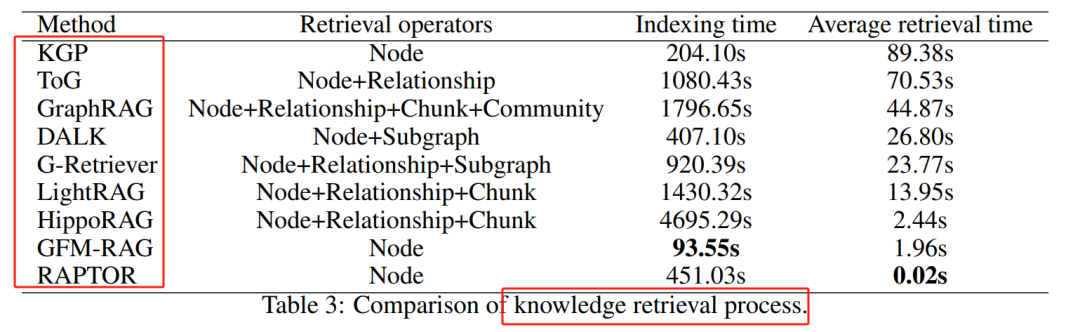
GraphRAG技术知识检索评估
GFM-RAG 的索引时间最短,因为它不构建传统的向量数据库。
RAPTOR 的平均检索时间最快,因为其树结构能够快速定位信息。
HippoRAG 和 GFM-RAG 的检索时间较短,分别利用了 GNN 和 PageRank 算法。
GraphRAG 的检索时间较长,因为它需要利用社区信息进行检索

 一起“点赞”三连↓
一起“点赞”三连↓

















 930
930

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









