



Datawhale干货
作者:张龙斐,Datawhale鲸英助教
上一次我们学习了如何部署ragflow,本次我们学习如何使用ragflow+dify搭建本地问答系统。
为什么要和dify结合呢,是因为dify的智能体功能非常强大,ragflow中虽然有类似的功能,但是并没有dify那么强大;但是ragflow可以解决dify解析和检索短板。
对应的,ragflow的资源消耗比较大,大家可以注意一下!
最后,如果大家有疑问和建议非常欢迎批评指正!
面向人群:计算机小白
阅读时间:10分钟
安装dify
- 确保电脑上安装了docker,git,vscode三个软件
Windows Docker 安装 | 菜鸟教程
:https://www.runoob.com/docker/windows-docker-install.html
- git:https://cloud.tencent.com/developer/article/2099150
- vscode:https://zhuanlan.zhihu.com/p/264785441
- 开始安装dify
首先在文件夹中点击鼠标右键,open git bash here,之后执行命令:git clone https://github.com/langgenius/dify.git --branch 0.15.3。完成后关闭git bash窗口,可以看到有一个dify的文件夹,打开这个文件夹并进入到docker文件夹下,右键菜单栏点击在终端中打开。
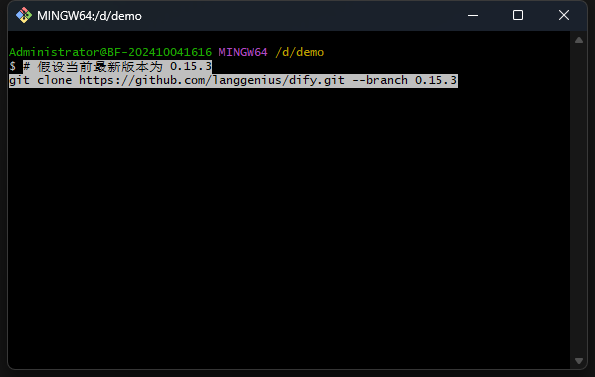

之后在终端中逐行执行以下命令:
copy .env.example .env # 复制环境文件 copy middleware.env.example middleware.env # 复制环境文件 docker compose -p dify up -d # 启动为dify名称,避免compose冲突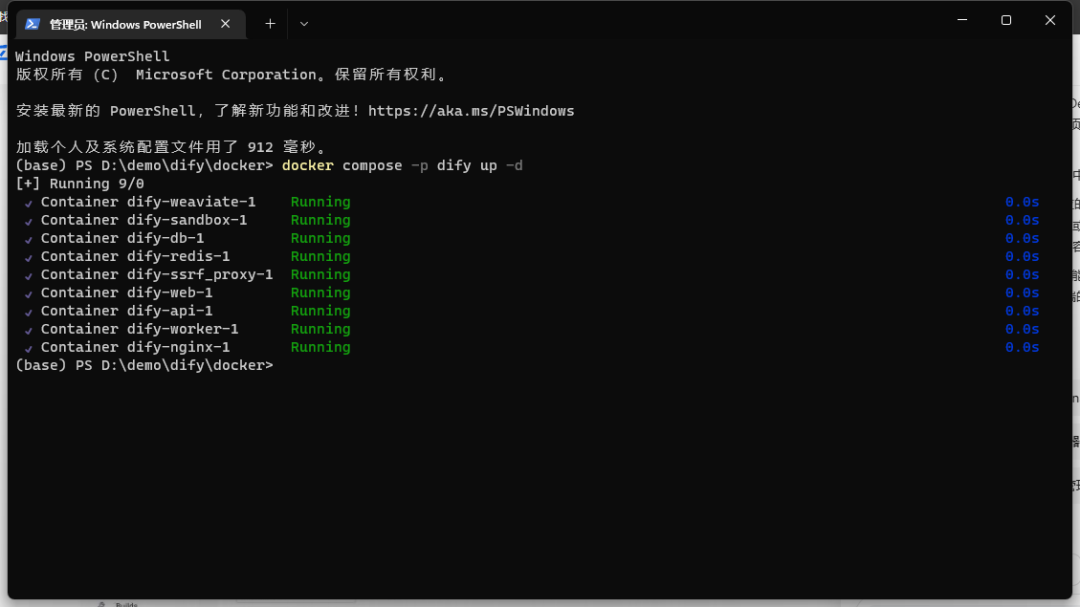
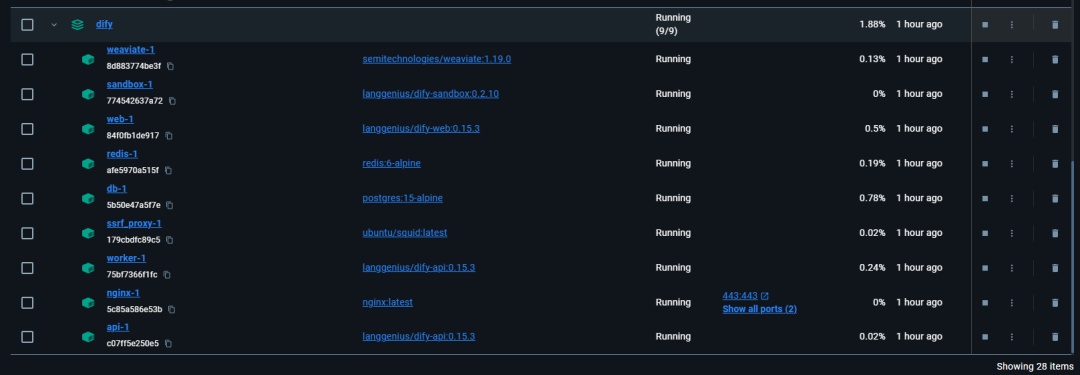
看到9个容器都在运行中即是部署成功了。此时打开docker容器可以看到dify后端运行情况:
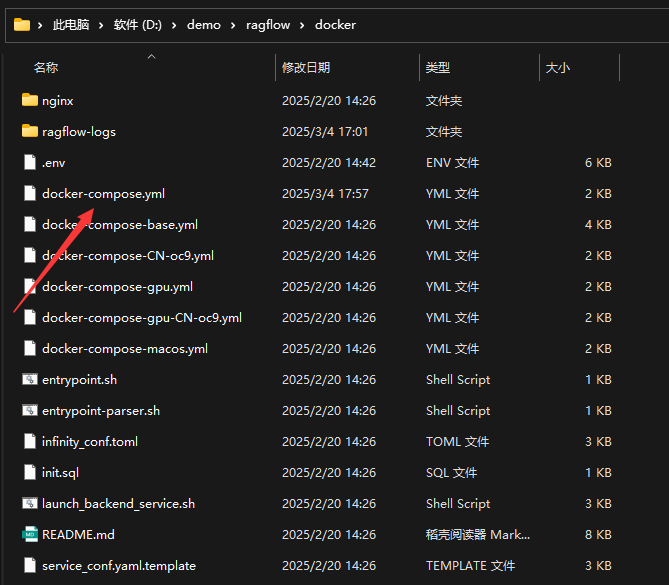
- 解决端口冲突
找到上次存放ragflow的文件夹,进入docker中,用vscode打开docker-compose.yml文件,修改其中的端口。
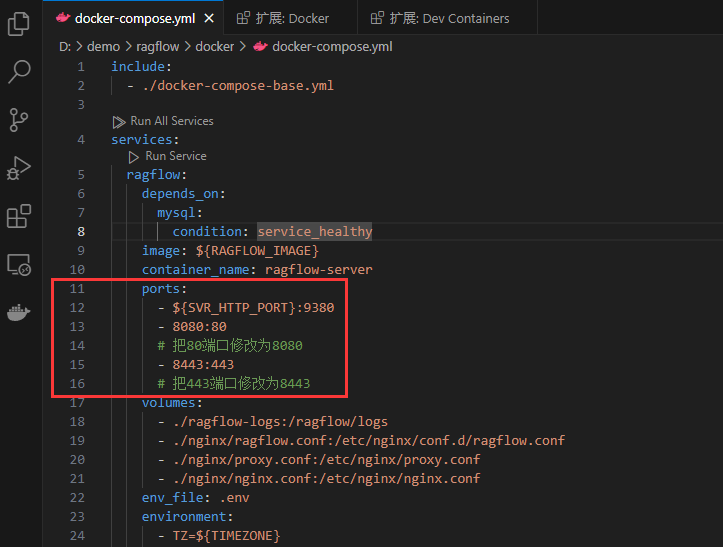
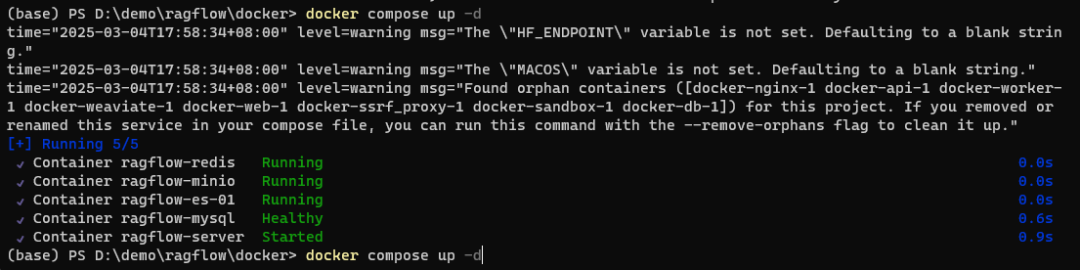
之后在此文件夹(路径一定要正确,相当于在特定的房间里启动这台机器)下右键打开命令行,输入: docker compose up -d
可以看到ragflow服务也成功启动了,避免了端口冲突。当然这里也可以命名为ragflow服务docker compose -p ragflow up -d
搭建本地问答系统
创建ragflow知识库+ragflow api
这里我们可以继续选择使用deepseek的api来搭建,也可以设置为本地或者其他服务的接口。
输入网址:localhost:8080 打开ragflow界面,填入注册的账号和密码登录。
💢
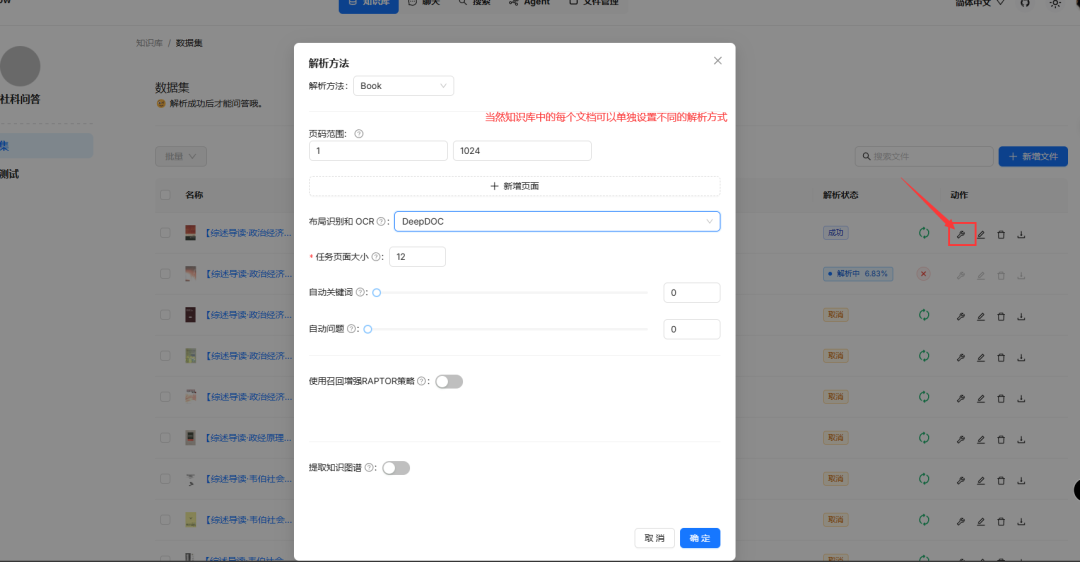
文档解析会非常慢,请大家耐心等候,目前没有找到批处理的方案,手动一个一个点击解析吧(据我测试一次解析3个比较稳妥)
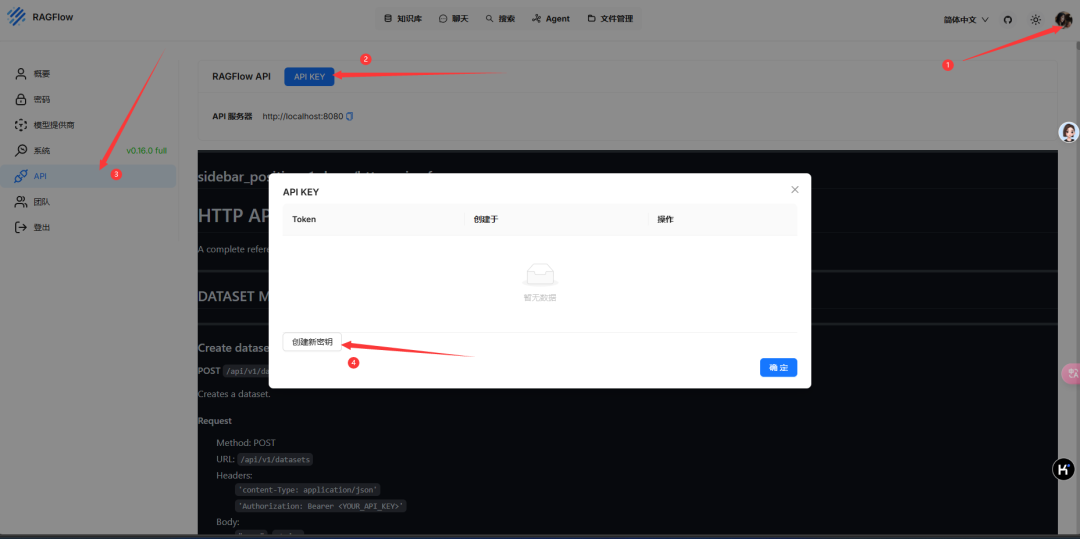
这一步我们创建ragflow的API,以便之后接入dify中。
ragflow进行本地问答
- 进行检索测试,测试检索命中准确度如何
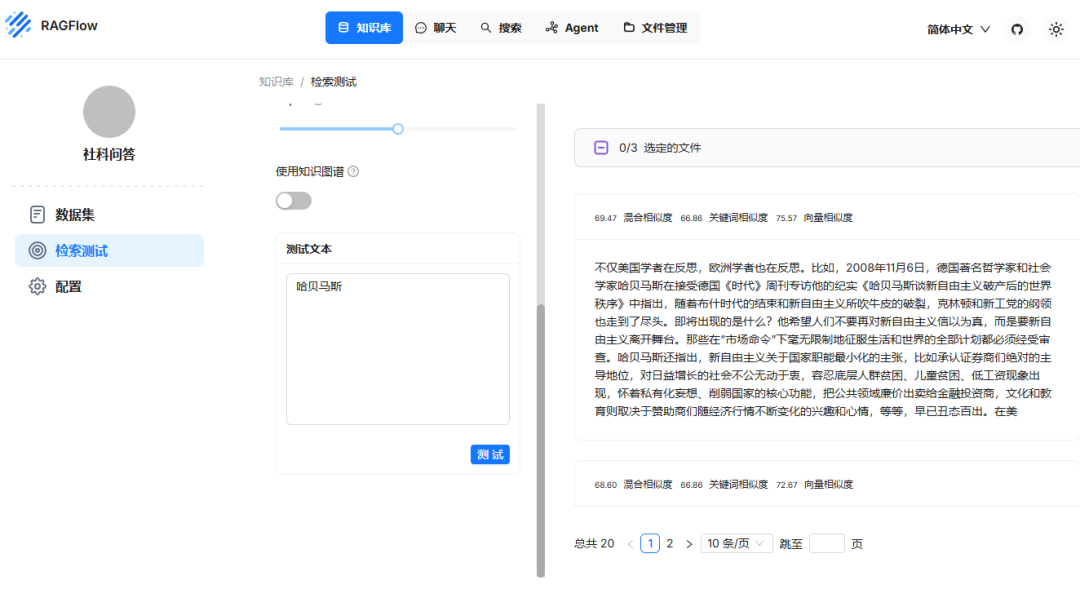
- 直接使用搜索功能查询名词,或者给出解释。
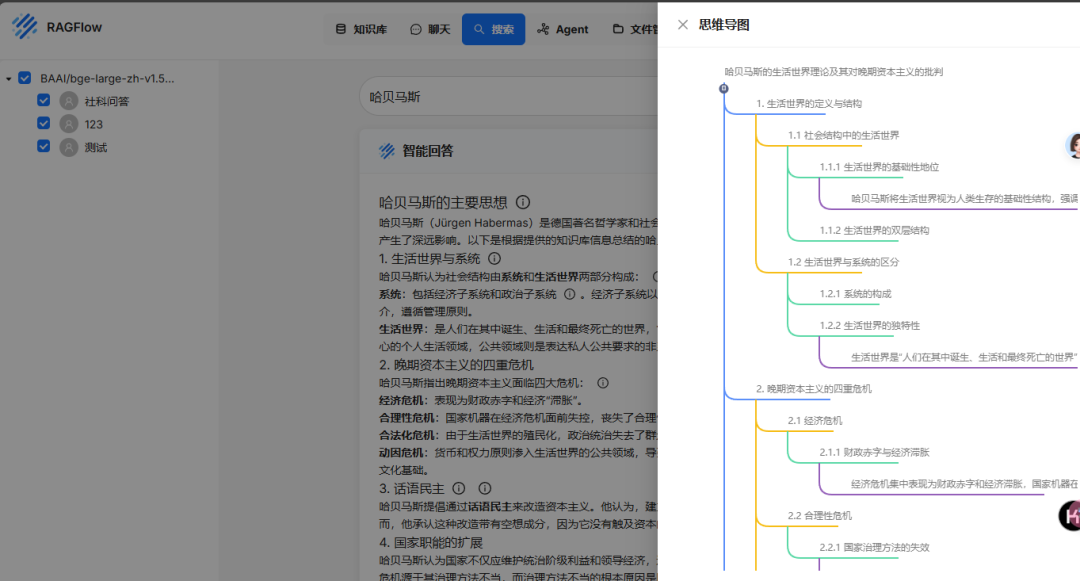
- 聊天这里创建简易的智能体
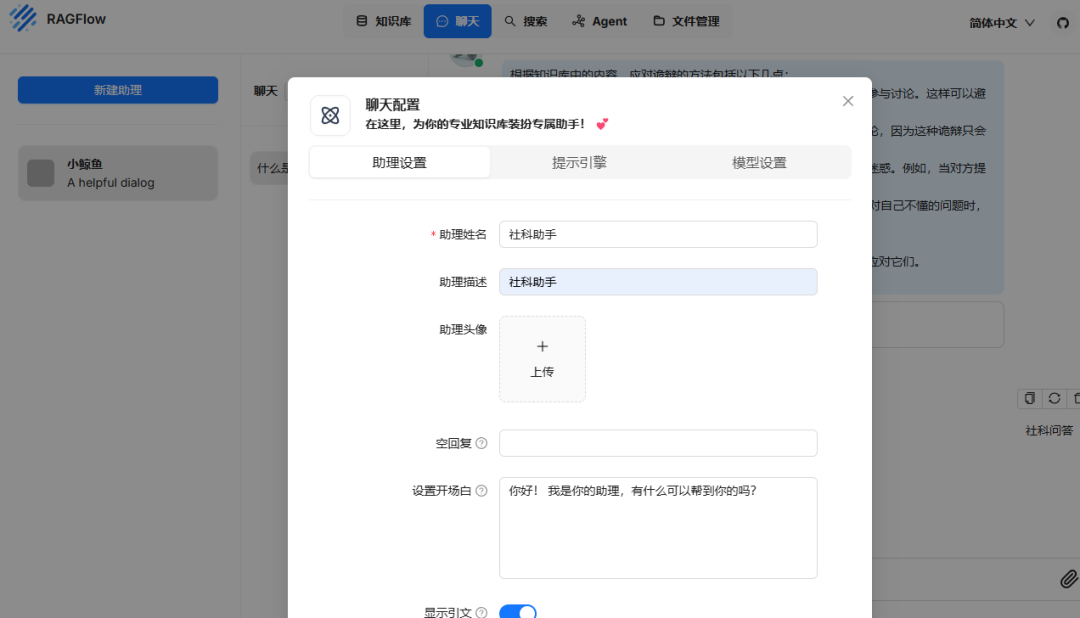
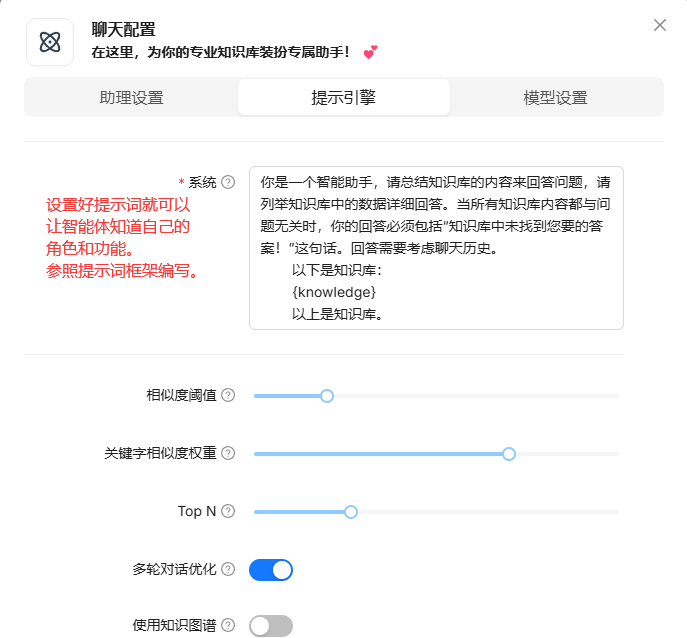
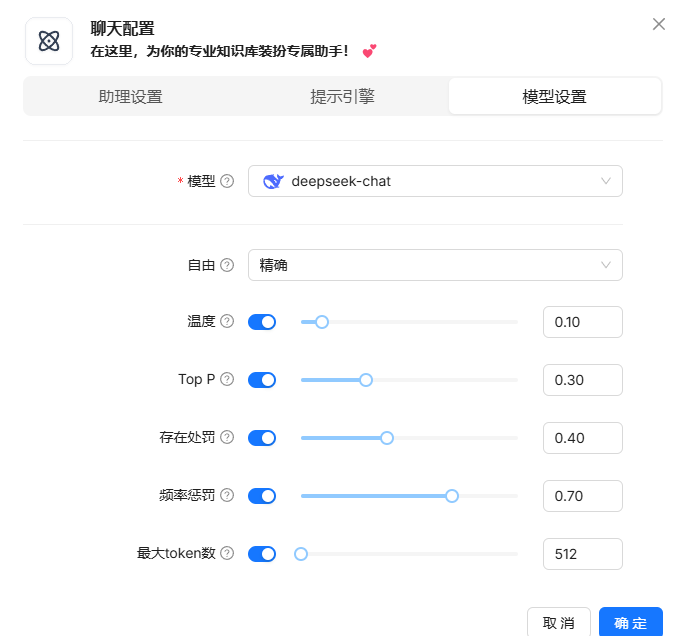
- 这里我们可以邀请团队成员一起使用这个知识库
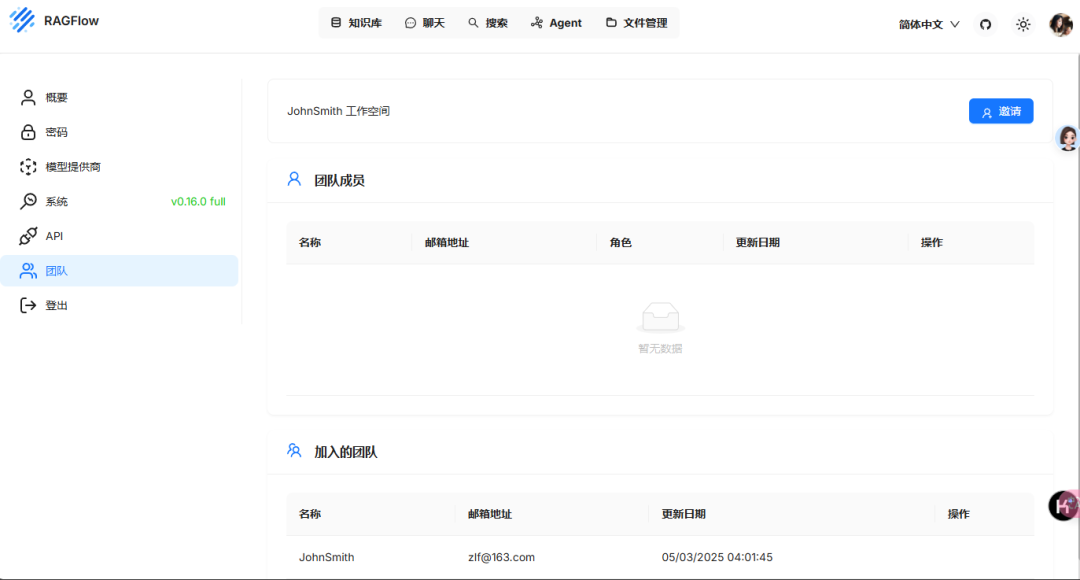
Dify与ragflow联通
同样的我们在浏览器地址栏输入:localhost:80 即可打开Dify
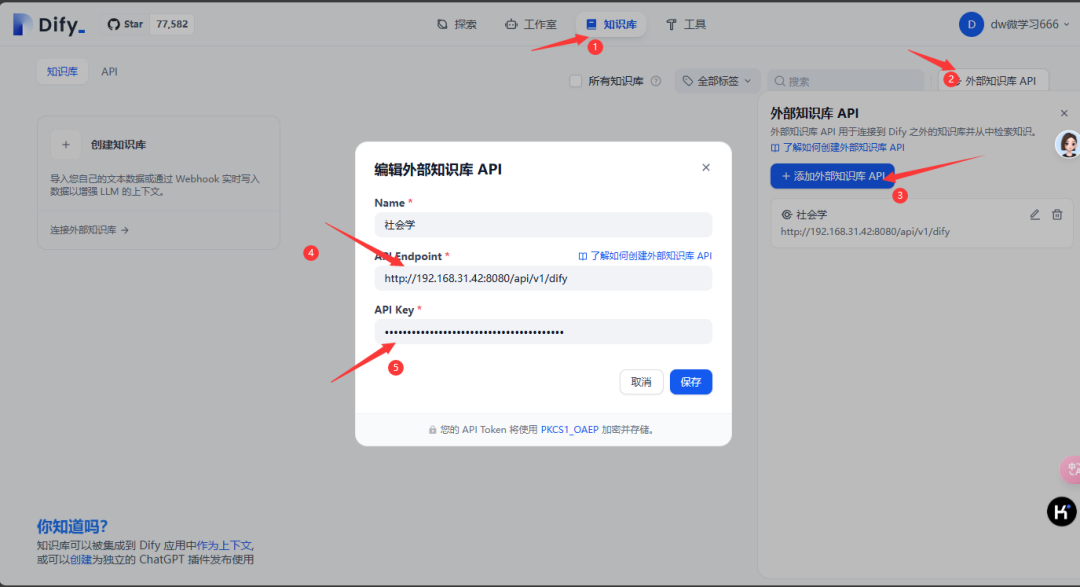
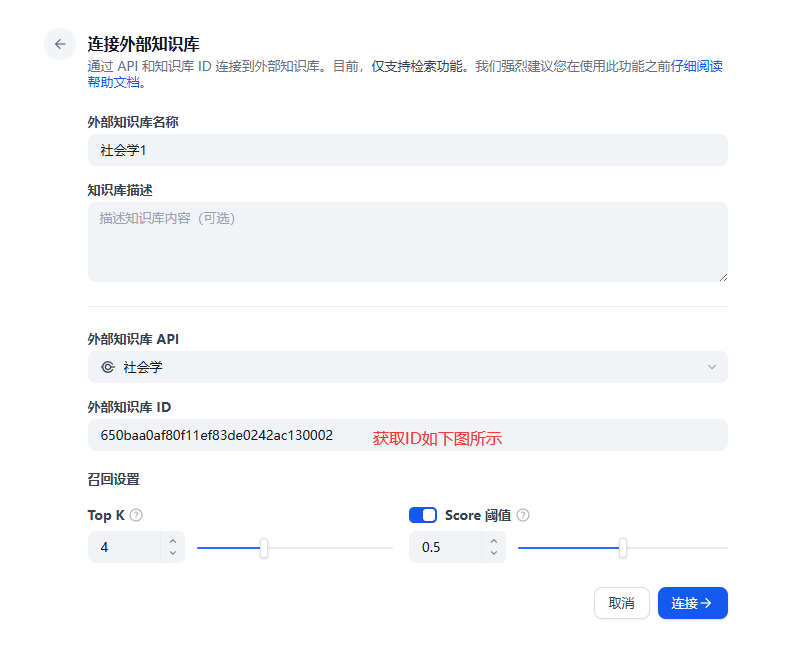
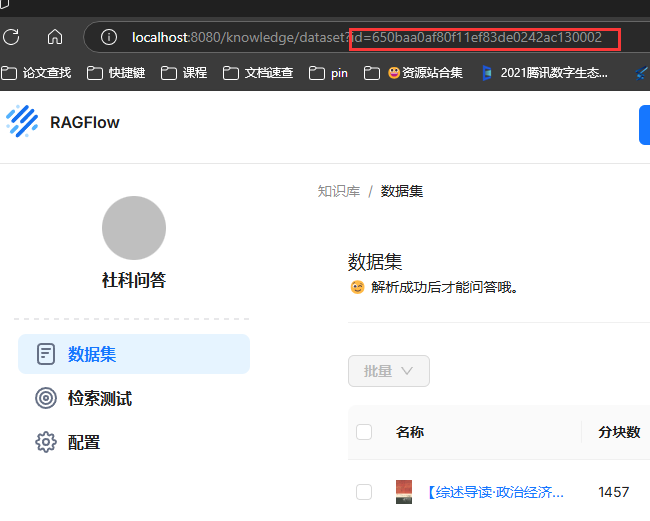
图中第4步骤需要填本地ip地址,http://本地IP:8080/api/v1/dify
apikey为上一步创建的ragflow api,复制填入即可。
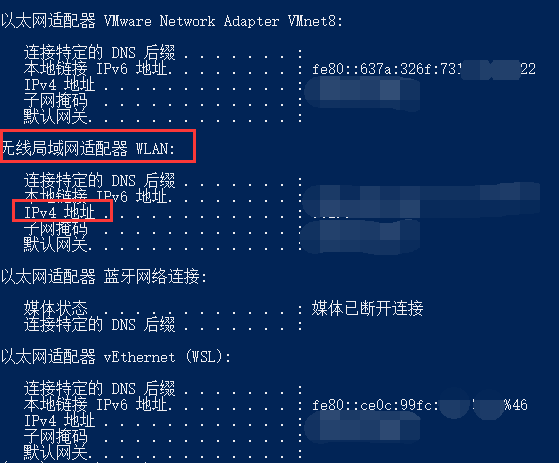
本地ip 查看方法:打开powershell,输入 ipconfig,找到下图对应的IPv4地址:
之后我们点击下图所示的
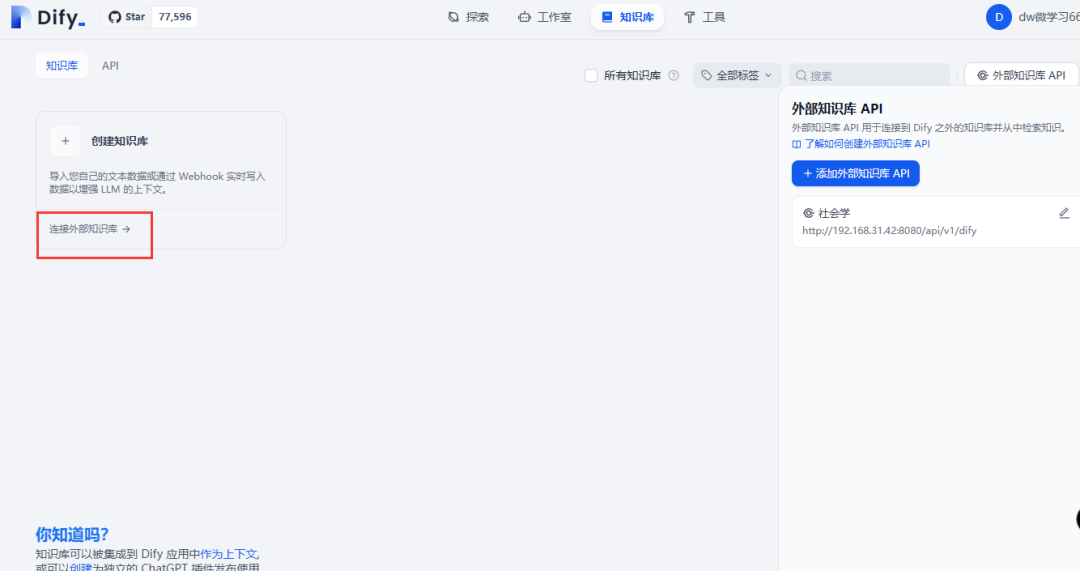
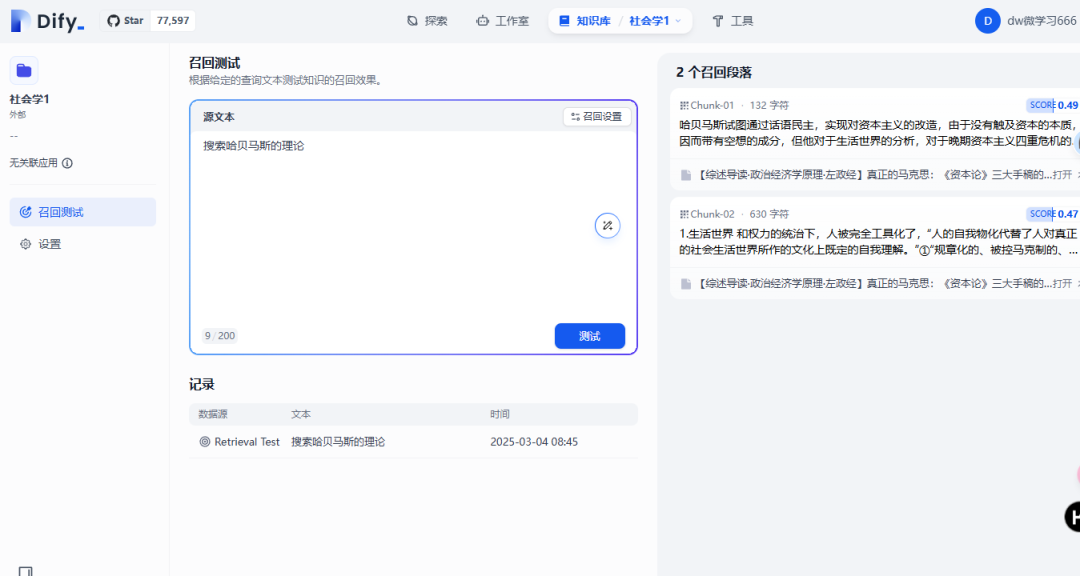
可以看到我们的知识库是调用成功了。
Dify的使用
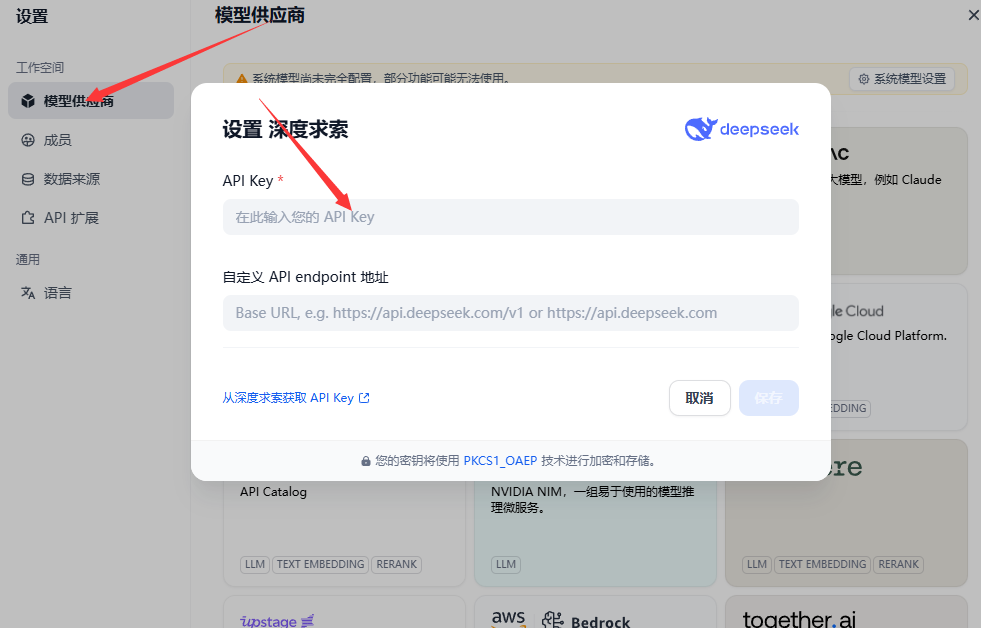
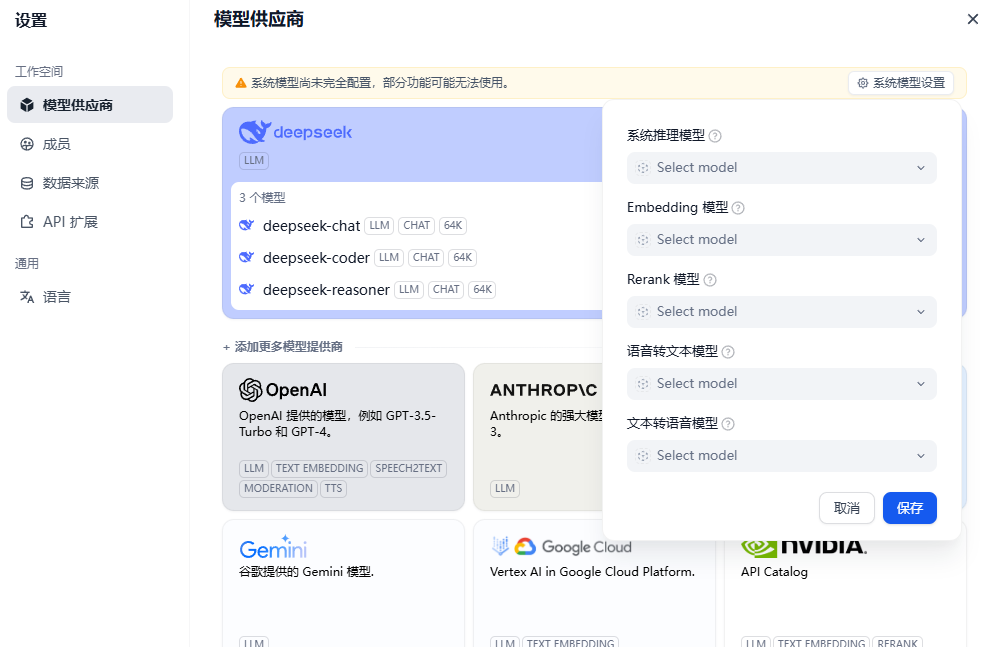
我们可以看到这里有非常多的模型配置选择,在ragflow中有embedding模型和rerank模型,不过它们都没有发布为api,无法调用。这里我们可以去硅基流动平台或者阿里百炼平台或者火山引擎,它们都提供了多种模型的api服务,申请api后填入key即可。
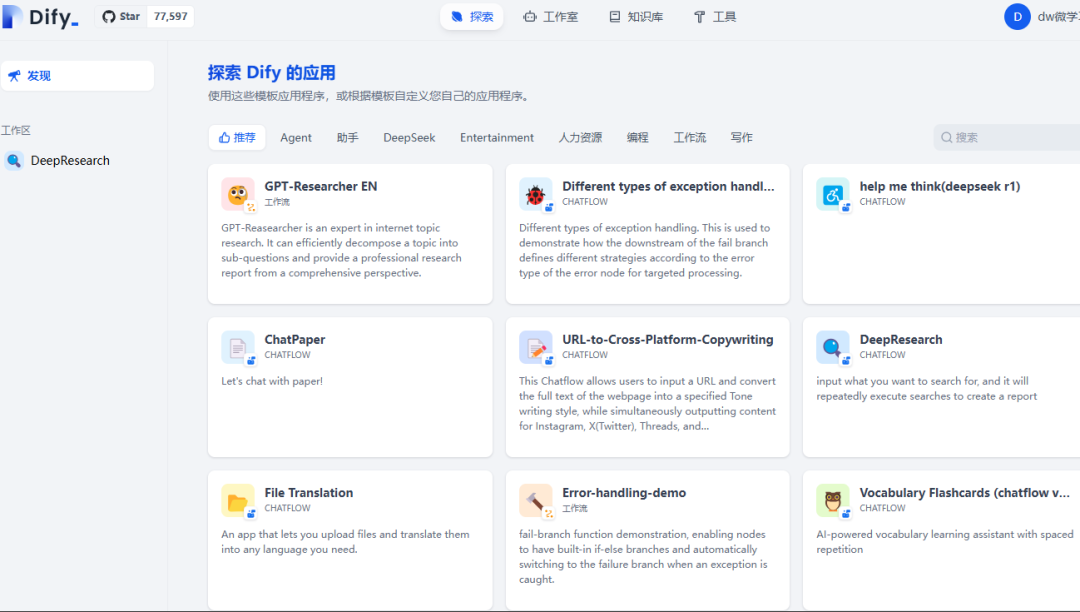
在探索页面有非常多的应用开发模板提供,按照自己的应用场景选择合适的即可,比如我想要一个社会学领域知识深度搜索的应用,就选择DeepResearch模板。
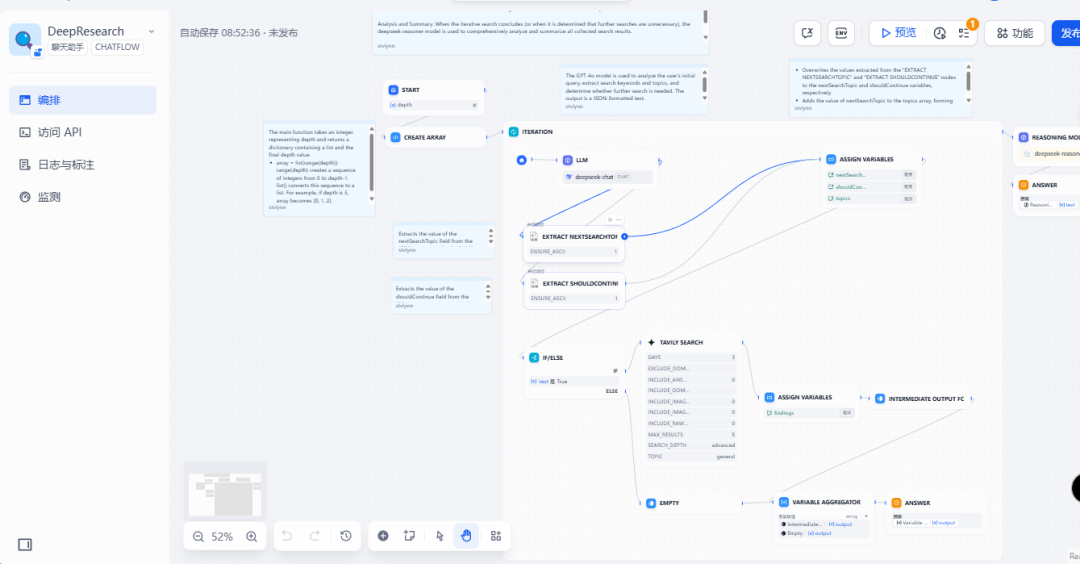
最后我们开发好工作流应用就可以啦,把配置好的应用发布为服务或者API都可以。
应用启动与更新
1. 应用启动:打开docker界面,把对应的容器服务全部开启。
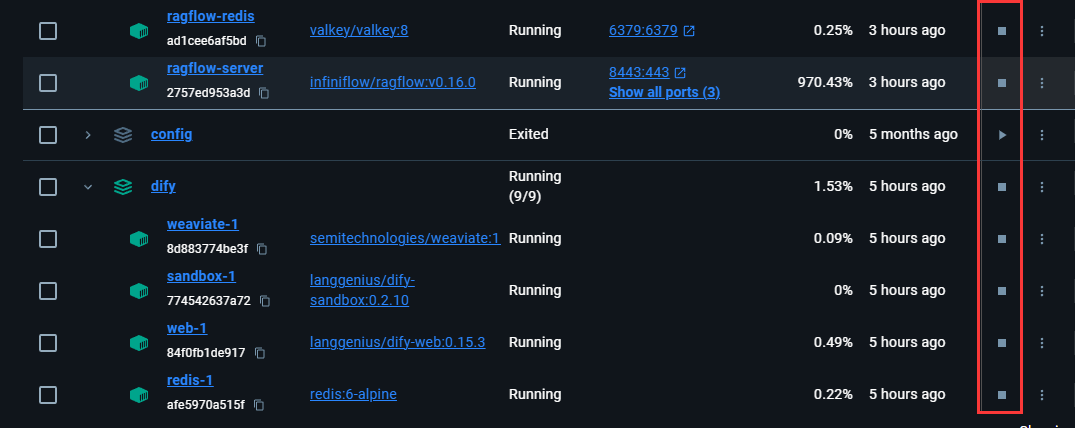
浏览器分别输入:localhost:80 与 localhost:8080 打开dify 和 ragflow。
2. 应用更新: 在对应的文件夹位置打开命令行,更新哪个就在哪个文件夹(docker文件夹)下打开,并键入以下命令:
docker compose down
git pull origin main
docker compose pull
docker compose up -d同时,请更新环境变量配置:
- 如果 .env.example 文件有更新,请同步更新您本地的 .env 文件。
- 检查 .env 文件中的所有配置项,确保它们与您的实际运行环境相匹配。您可能需要将 .env.example 文件中的新变量和更新后的值添加到 .env 文件中。
Rag最全梳理:《最全梳理:一文搞懂RAG技术的5种范式!》
DeepSeek+Ragflow:《DeepSeek接入个人知识库,保姆级教程来了!》
 一起“点赞”三连↓
一起“点赞”三连↓

















 695
695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









