




 本文介绍了语义分割的关键步骤,包括语义标签图、单通道掩膜和Onehot编码,并通过Pascal VOC 2012数据集展示了实际操作,涉及数据集读取、颜色映射及编码转换。
本文介绍了语义分割的关键步骤,包括语义标签图、单通道掩膜和Onehot编码,并通过Pascal VOC 2012数据集展示了实际操作,涉及数据集读取、颜色映射及编码转换。
Datawhale干货
作者:游璐颖,福州大学,Datawhale成员
图像分割是计算机视觉中除了分类和检测外的另一项基本任务,它意味着要将图片根据内容分割成不同的块。相比图像分类和检测,分割是一项更精细的工作,因为需要对每个像素点分类。
如下图的街景分割,由于对每个像素点都分类,物体的轮廓是精准勾勒的,而不是像检测那样给出边界框。

图像分割可以分为以下三个子领域:语义分割、实例分割、全景分割。

由对比图可发现,语义分割是从像素层次来识别图像,为图像中的每个像素制定类别标记,目前广泛应用于医学图像和无人驾驶等;实例分割相对更具有挑战性,不仅需要正确检测图像中的目标,同时还要精确的分割每个实例;全景分割综合了两个任务,要求图像中的每个像素点都必须被分配给一个语义标签和一个实例id。
01 语义分割中的关键步骤
在进行网络训练时,时常需要对语义标签图或是实例分割图进行预处理。如对于一张彩色的标签图,通过颜色映射表得到每种颜色所代表的类别,再将其转换成相应的掩膜或Onehot编码完成训练。这里将会对于其中的关键步骤进行讲解。
首先,以语义分割任务为例,介绍标签的不同表达形式。
1.1 语义标签图
语义分割数据集中包括原图和语义标签图,两者的尺寸大小相同,均为RGB图像。
在标签图像中,白色和黑色分别代表边框和背景,而其他不同颜色代表不同的类别:

1.2 单通道掩膜
每个标签的RGB值与各自的标注类别对应,则可以很容易地查找标签中每个像素的类别索引,生成单通道掩膜Mask。
如下面这种图,标注类别包括:Person、Purse、Plants、Sidewalk、Building。将语义标签图转换为单通道掩膜后为右图所示,尺寸大小不变,但通道数由3变为1。
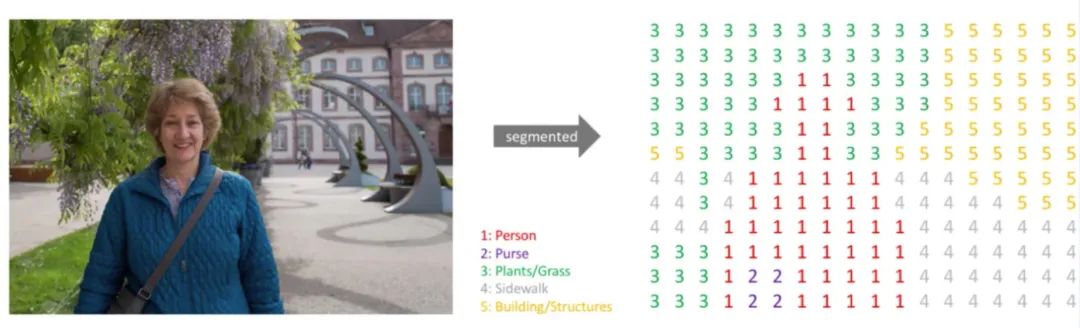
每个像素点位置一一对应。

1.3 Onehot编码
Onehot作为一种编码方式,可以对每一个单通道掩膜进行编码。
比如对于上述掩膜图Mask,图像尺寸为,标签类别共有5类,我们需要将这个Mask变为一个5个通道的Onehot输出,尺寸为,也就是将掩膜中值全为1的像素点抽取出生成一个图,相应位置置为1,其余为0。再将全为2的抽取出再生成一个图,相应位置置为1,其余为0,以此类推。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 737
737




 到【灌水乐园】发言
到【灌水乐园】发言







