



↑↑↑关注后"星标"Datawhale
每日干货 & 每月组队学习,不错过
Datawhale开源
来自:Datawhale????数据可视化小组
开源初衷
Matplotlib可以说是python数据可视化最重要且常见的工具之一,几乎每个和数据打交道的人都不可避免,还有大量可视化工具是基于它的二次开发。
开源教程的设计初衷源于笔者最初用python做数据可视化时面临两大痛点,
绘图时现用现查,用过即忘,效率极低
只会复制粘贴,不知其所以然,面对复杂图表一筹莫展
如果屏幕前的你,也正在面临这两个痛点,那么学习本项目教程将会是一个不错的选择。
本项目重点希望在两个层面帮助读者构建matplotlib的知识体系(文末有开源教程地址):
从图形,布局,文本,样式等多维度系统梳理matplotlib的绘图方法,构建对于绘图方法的整体理解
从绘图API层级,接口等方面阐明matplotlib的设计理念,摆脱只会复制粘贴的尴尬处境
关于本项目的名称,Fantastic-Matplotlib,在笔者精读过官网文档之后,才愈发觉得精妙,仿佛看到了一角下的广袤冰山,被它强大的功能和精巧的设计惊艳到了,之前对于matplotlib的了解还是过于浅薄,因此想用fantastic来表示笔者的感慨,也希望能够通过这样一个开源教程带领读者领略的matplotlib的精彩之处。
开源教程
Fantastic-Matplotlib共有5个章节,笔者为每一个章节写了一句小诗作为回目名,因为在笔者看来,可视化不仅仅是一项技术,更是一件充满了艺术性的事情,在使用可视化库画图表时,常常想象自己在一块画布上自由地画水粉画。
第一回:Matplotlib初相识
第二回:艺术画笔见乾坤
第三回:布局格式定方圆
第四回:文字图例尽眉目
第五回:样式色彩秀芳华
这五个章节将从不同的维度(matplotlib概述,绘图元素,布局格式,文字图例,样式色彩)介绍如何进行可视化绘图。
第一回:Matplotlib初相识
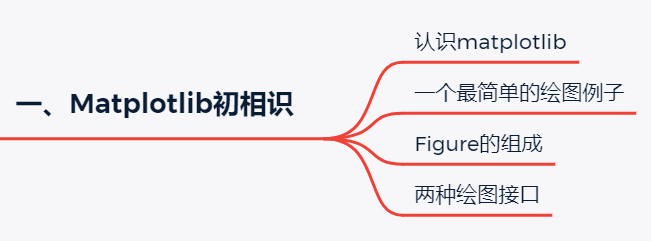
第一回是引子,首先介绍了matplotlib可视化绘图包的特点,然后通过一个极简的可视化例子告诉读者如何用最简单的几行代码画出一幅可视化图表,最后简单介绍一幅可视化图表figure的组成和两种绘图接口。
两种绘图接口对初学者来说是一个难点,两种最常用的绘图接口特点如下:
显式创建figure和axes,在上面调用绘图方法,也被称为OO模式(object-oriented style);
依赖pyplot自动创建figure和axes,并绘图。
他们的区别在于OO模式更为底层,是一种面向对象的思路,从代码上更为复杂,但同时也更灵活。pyplot是面向过程的思路,matplotlib对其做了更高级的封装,使用时只用关注想要实现什么效果即可,而不用涉及到对象本身,代码上更为简洁,但在灵活性上不够OO模式自由。
通过第一章的学习,即使是零基础的读者也能够对matplotlib具有初步的了解,作为可视化的入门,学习如何画一个最简单的可视化例子。
第二回:艺术画笔见乾坤
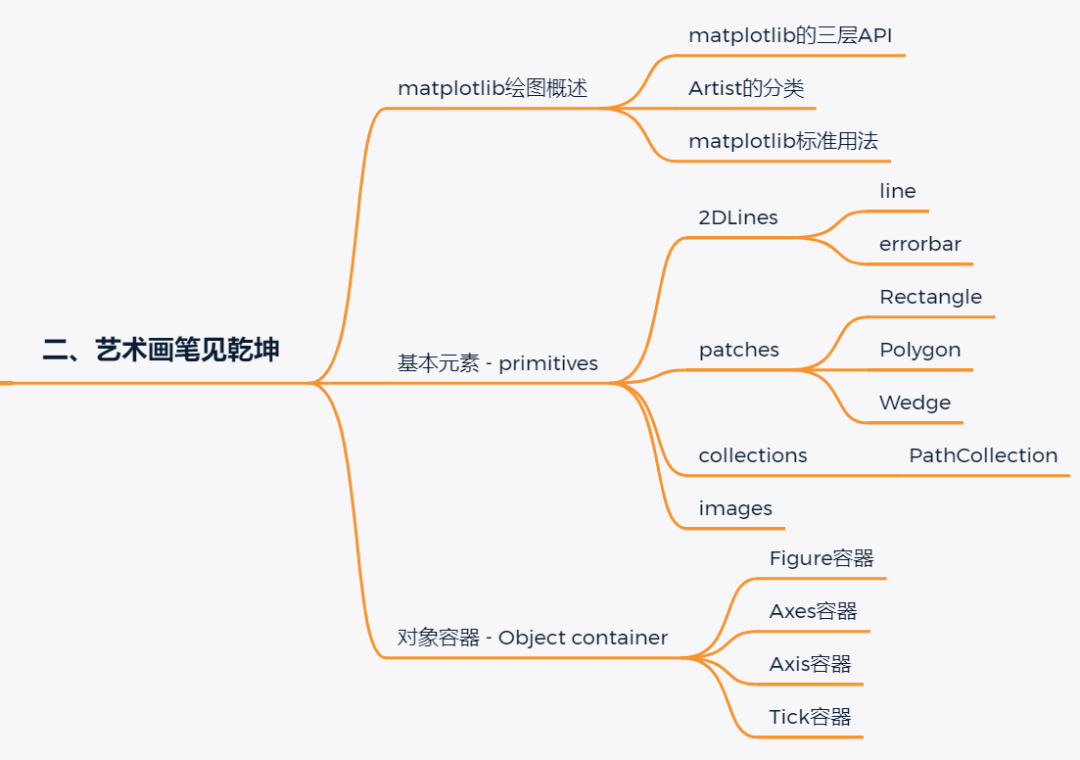
第二回是这个数据可视化教程中最重要的一个章节,整个章节都围绕Artist对象展开。Artist对象在matplotlib宇宙中是一个极为重要的概念,实际上我们在做可视化时几乎接触到的所有对象元素都属于artist对象。
Artist对象可以分为两大类,基本元素primitives和容器对象container。基本元素指的是我们想在可视化画布上填上的标准元素,比如一条线,一个矩形,一段文字,一张外部图片,以上这些都属于基本元素的范畴。而容器对象指的是用来放置那些基本元素的对象,如Figure(完整的画布),Axes(子图),Axis(坐标轴)。按照官网的说法,我们在用matplotlib做可视化图表时,95%的时间都是在和Artist打交道,因此熟练掌握artist是学好数据可视化的关键。
本章首先介绍了matplotlib画图的三层API,其中前两层都属于底层API,通常我们打交道的都位于最上层的API中,进而引入了最上层API中artist的概念和分类,然后介绍matplotlib的标准使用流程,简单来说分为三步:
创建一个
Figure实例;使用
Figure实例创建一个或者多个Axes或Subplot实例;使用
Axes实例的辅助方法来创建primitive。
在介绍完以上这些概念后,本章节详细讲解了常用基本元素和容器对象的使用方法。通过本章的学习,所有常见图表(折线图,柱状图,饼图等)的雏形都已经可以画出来了,并且你还可以根据实际需要自由组合不同基本元素搭建更为复杂的图表。
在本章中还针对artist元素,重点演示两种绘图接口的使用方法,对于常见的基本元素,matplotlib都提供了OO模式和pyplot模式的现成方法供使用者选择。
本质上我们绘制一幅可视化图表就是在容器对象(container)上填充和组合基本元素(primitive)的过程,像极了现实中绘画的过程。
第三回~第五回
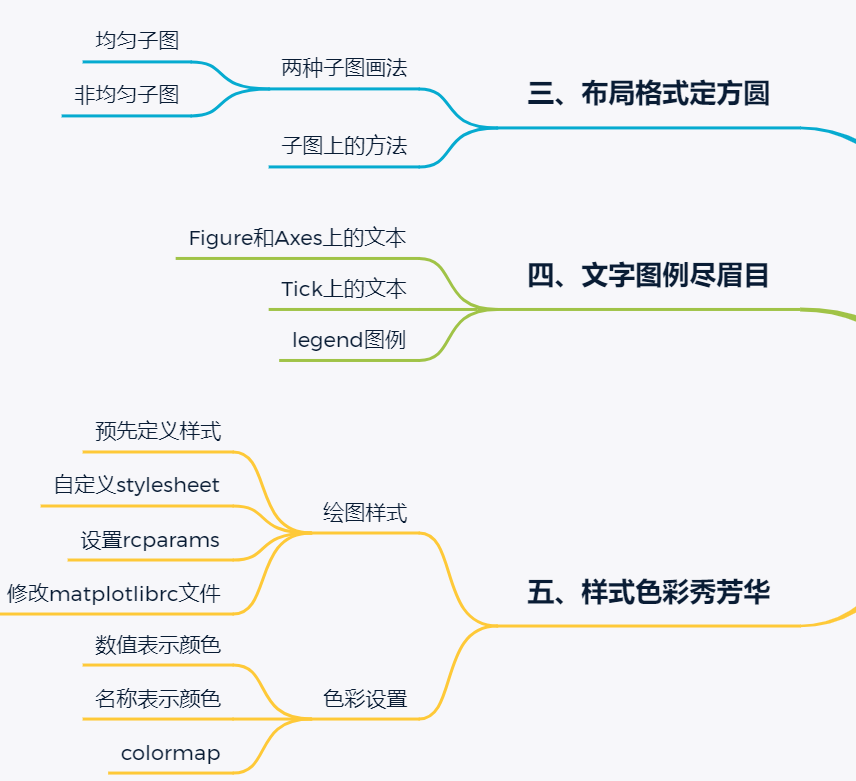
第三~五章是对于一幅可视化图表的进一步修饰与加工,分别从布局格式,文字图例,样式色彩三方面对图表进行修饰。
第三章重点讲解了如何在一张大画布上划分均匀和非均匀的子图以进行多图展示,丰富图表内容。
第四章重点讲解了如何在图表上的不同功能区(figure,axes,tick,legend)上添加文字,修改文字样式和显示内容,精准的文字表述也是可视化图表的一个重要组成元素。
第五章重点讲解了如何在图表上设置图表的样式和色彩,从而让可视化图表更美观,看起来更像是一幅艺术作品。
最后还想说的是,对于学习完本教程的读者,若是仍然觉得学有余力不过瘾,强烈建议按需阅读官方文档,相信你一定会有所收获的。
核心贡献者:杨剑砺、杨煜、居凤霞、耿远昊、李运佳
Fantastic-Matplotlib开源地址
https://github.com/datawhalechina/fantastic-matplotlib
或点击阅读原文获取,欢迎star!

为开源贡献者点赞↓

















 2万+
2万+




 到【灌水乐园】发言
到【灌水乐园】发言







