




🌐 社群导航
🔗 点击加入➡️【AIGC/LLM/MLLM/3D/自动驾驶】 技术交流群
最新论文解读系列

论文名:DualToken: Towards Unifying Visual Understanding and Generation with Dual Visual Vocabularies
论文链接:https://arxiv.org/pdf/2503.14324
项目链接:暂无
导读
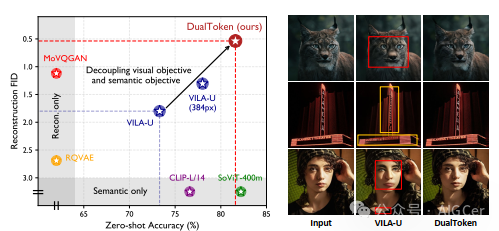
视觉理解和生成所需的不同表示空间,给在大语言模型的自回归范式内统一这两者带来了挑战。为重建而训练的视觉分词器(vision tokenizer)擅长捕捉低级感知细节,因此非常适合视觉生成,但缺乏用于理解任务的高级语义表示。相反,通过对比学习训练的视觉编码器(vision encoder)能很好地与语言对齐,但在解码回像素空间以进行生成任务时却面临困难。为了弥合这一差距,我们提出了双令牌(DualToken)方法,该方法在单个分词器中统一了理解和生成的表示。然而,在单个分词器中直接整合重建和语义目标会产生冲突,导致重建质量和语义性能均下降。双令牌(DualToken)没有强制使用单一码本处理语义和感知信息,而是通过为高级和低级特征引入单独的码本将它们分离,有效地将它们固有的冲突转化为协同关系。因此,双令牌(DualToken)在重建和语义任务中都取得了最先进的性能,同时在下游多模态大语言模型(MLLM)的理解和生成任务中表现出显著的有效性。值得注意的是,我们还表明,作为一个统一的分词器,双令牌(DualToken)超越了两种不同类型视觉编码器的简单组合,在统一的多模态大语言模型(MLLM)中提供了更优的性能。
简介
在大语言模型(LLM)的自回归范式内统一视觉理解和生成已成为当前的研究热点,催生了如CM3leon、变色龙(Chameleon)、鸸鹋3(Emu3)和VILA - U等代表性工作。为了实现多模态自回归生成,这些统一模型需要一个视觉分词器(visual
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 281
281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









