




🌐 社群导航
🔗 点击加入➡️【AIGC/LLM/MLLM/3D/自动驾驶】 技术交流群
最新论文解读系列

论文名:DreamLayer: Simultaneous Multi-Layer Generation via Diffusion Model
论文链接:https://arxiv.org/pdf/2503.12838
开源代码:https://ll3rd.github.io/DreamLayer/
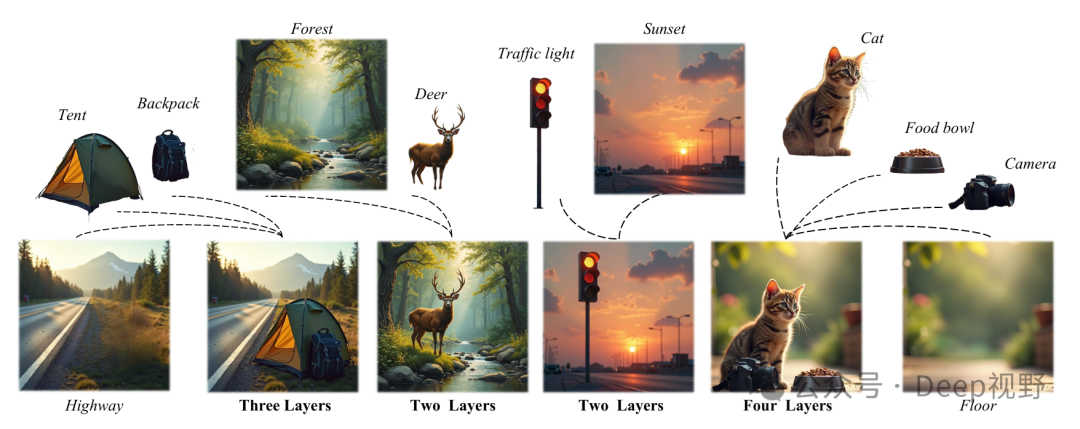
导读
近年来,基于扩散模型的文本到图像生成技术已展现出从文本提示中创建高质量、细节丰富图像的强大能力。然而,大多数方法专注于生成单个完整的图像,这极大地限制了它们在内容编辑和图形设计等严重依赖分层合成的应用中的潜力。分层结构对于包含多个对象的图像特别有利,因为它们允许进行更灵活和多样的编辑及创意修改。本文研究了如何通过简单的文本驱动过程,应用扩散模型生成连贯的多层图像。
简介
近年来,使用扩散模型进行文本驱动的图像生成受到了广泛关注。为了实现更灵活的图像操作和编辑,近期的研究已从单图像生成扩展到透明图层生成和多层合成。然而,现有方法往往未能对多层结构进行全面探索,导致层间交互不一致,如遮挡关系、空间布局和阴影效果等。在本文中,我们提出了梦境图层(Dream-Layer)这一新颖框架,通过显式建模透明前景和背景图层之间的关系,实现了连贯的文本驱动多层图像生成。梦境图层包含三个关键组件,即用于全局 - 局部信息交换的上下文感知交叉注意力机制(Context-Aware Cross-Attention,CACA)、用于建立稳健层间连接的层共享自注意力机制(Layer-Shared Self-Attention,LSSA)以及用于在潜在层面细化融合细节的信息保留协调机制(Information Retained Harmonization,IRH)。通过利用连贯的全图像上下文,梦境图层通过注意力机制建立层间连接,并应用协调步骤实现无缝的图层融合。为了促进多层生成的研究,我们构建了一个高质量、多样化的多层数据集,包含 个样本。大量实验和用户研究表明,梦境图层生成的图层更加连贯且对齐良好,具有广泛的适用性,包括潜在空间图像编辑和图像到图层分解。
方法与模型
定义。直观地说,一个层图像由一个背景层、前景层和一个全局层组成。每个层由一个三通道彩色图像和一个alpha通道 组成,其中alp
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









