



🌐 社群导航
🔗 点击加入➡️【AIGC/LLM/MLLM/3D/自动驾驶】 技术交流群
数源AI 最新论文解读系列

论文名:BlobCtrl: A Unified and Flexible Framework for Element-level Image Generation and Editing
论文链接:https://arxiv.org/pdf/2503.13434
开源代码:https://liyaowei-stu.github.io/project/BlobCtrl/
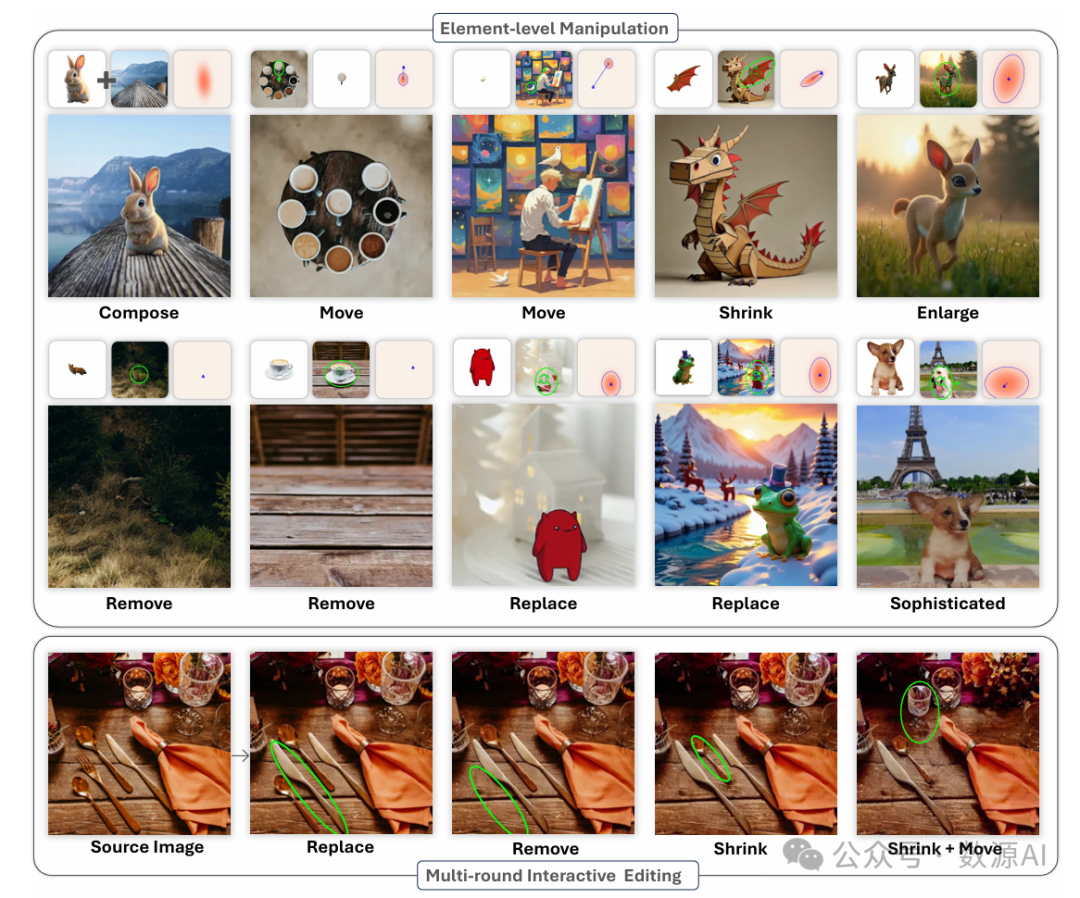
导读
元素级图像操作长期以来一直是数字艺术的目标,像Adobe Photoshop这样的工具能够对视觉元素进行精确操作。虽然最近的人工智能模型在高质量图像合成方面表现出色,但它们往往缺乏对单个元素的细粒度控制,而这正是传统工具的关键特性。像ControlNet和IP - Adapter等进展虽然提高了可控性,但仍然不支持创意工作流程中至关重要的交互式、多轮次、基于元素的操作(例如组合、调整大小、排列)。挑战包括:1)视觉元素的解耦和表示;2)连续的布局控制;3)保留外观和身份;4)保持视觉和谐;5)用于端到端训练的大规模配对训练数据稀缺。
简介
元素级视觉操作在数字内容创作中至关重要,但当前基于扩散模型的方法缺乏传统工具的精度和灵活性。在这项工作中,我们引入了,这是一个使用基于概率团块(blob)表示法来统一元素级生成和编辑的框架。通过将团块用作视觉基元,我们的方法有效地解耦并表示了空间位置、语义内容和身份信息,从而实现了精确的元素级操作。我们的主要贡献包括:1)具有分层特征融合的双分支扩散架构,用于实现前景 - 背景的无缝集成;2)采用定制数据增强和得分函数的自监督训练范式;3)可控的丢弃策略,以平衡保真度和多样性。为了支持进一步的研究,我们引入了用于大规模训练的BlobData和用于系统评估的BlobBench。实验表明,BlobCtrl在各种元素级操作任务中表现出色,同时保持了计算效率,为精确灵活的视觉内容创作提供了一个实用的解决方案。
方法与模型
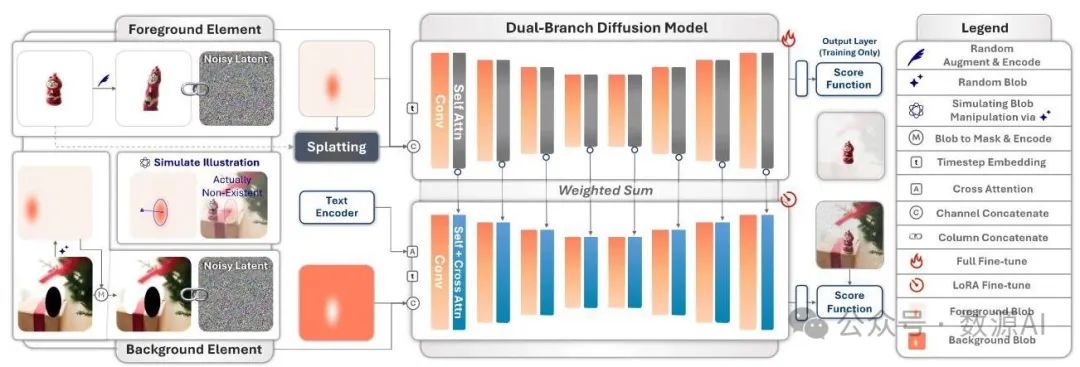
图3:BlobCtrl 概述。我们的框架包括:(1)一个双分支架构,其中前景分支用于元素身份编码,背景分支用于场景上下文保存和协调。两个分支都使用噪声潜变量和参考条件的拼接输入(第3.1节)。(2)一种通过随机位置生成和目标重建优化进行元素级操作的自监督训练范式。通过分支之间的特征融合,我们的框架在保持视觉连贯性的同时实现了对元素的精确控制。
1. 模型架构
我们提出了一种双分支扩散模型,分别处理前景和背景元素。如图3所示,我们的模型主要由两个关键组件组成:
前景分支。前景分支旨在保留前景元素的身份和外观,同时实现灵活的布局控制。如图3所示,我们将噪声潜变量 与参考前景条件 沿列维度拼接,作为前景分支的输入。这种按列拼接策略提高了模型的上下文学习能力,使其能够更有效地掌握和保留元素的特征。参考前景条件 是通过沿通道维度拼接三个关键组件构建的:(1)用于布局信息的不透明度图 ;(2)用于身份保留的空间感知语义特征 ;(3)用于外观编码的变分自编码器(VAE)潜变量 。为了确保 和 按列拼接时的维度兼容性,我们还将 和 沿 的通道维度进行拼接。前景分支的输入构建过程可以正式表示为:
其中 和 分别表示沿通道和列的拼接。
为了处理元素级的前景输入,我们使用了一个经过修改的预训练扩散主干网络,移除了交叉注意力层。这种方法有两个目的:预训练的权重为有效的前景特征处理提供了强大的生成先验,移除交叉注意力层确保模型仅关注视觉内容,而不受更广泛上下文的影响。
背景分支。背景分支作为一个扩散主干网络,旨在保留原始背景,同时将前景元素和谐地融入场景。同样,我们将噪声潜变量 与参考背景条件 沿列维度拼接作为输入,如下所示:
其中背景分支缺乏空间感知语义特征,因为它倾向于完全保留信息。
在元素级编辑中,背景是一个掩码图像,其中前景元素的原始区域和目标区域都被掩码掉。例如,当移动一只鸟时,背景在鸟的初始位置和目标位置都有掩码。
背景分支使用一个带有交叉注意力层的完整扩散主干网络。为了无缝集成前景和背景元素,我们采用分层特征融合方法,在背景分支的多个分辨率级别逐步注入前景特征。我们还使用零初始化(Zhang等人,2023a) 进行稳定训练。第i个块的特征融合公式为:
其中 和 分别是背景分支和前景分支的输入条件, 是特征融合的权重。
2. 自监督训练
虽然不同位置的对象配对数据对于训练来说是理想的,但这种数据非常稀缺。以前的方法(Chen等人,2023;Alzayer等人,2024)依赖于视频数据,但这会引入不必要的复杂性,降低模型性能。
相反,我们提出了一种自监督训练策略,采用的思路是任何图像都可以看作是一个元素操作过程的目标结果。对于每个训练图像,我们确定目标元素的位置,并在不同位置随机生成一个斑点来模拟源位置。这模拟了操作过程,如图3所示,一个玩具似乎从随机的左侧位置移动到了实际的右侧位置。我们在训练过程中使用噪声预测得分函数来优化我们的模型:
其中 是源图像的潜在表示, 是时间步 时的含噪潜在表示。该得分函数促使模型在目标布局处填充前景元素,在原始前景位置修复背景元素,并确保整个场景的和谐融合。
3. 身份保留与场景和谐
随机数据增强。为防止模型默认采用简单的复制粘贴解决方案,我们在训练期间对前景元素进行大量数据增强。这包括颜色抖动、缩放、旋转、擦除和透视变换等随机变换。这些增强有两个主要目的:迫使模型根据指定的布局和外观和谐地放置前景元素,随机擦除培养对不完整元素的强大修复能力。这种方法确保模型学会灵活且根据上下文生成和处理元素,与背景保持视觉连贯性。
身份保留得分函数。为有效分离前景和背景分支——确保前景分支注入元素级信息,而背景分支整合这些元素,我们提出了一种身份保留得分函数。在训练期间,我们保留前景分支中扩散模型的输出层(推理时丢弃),并应用仅在前景元素区域内操作的得分函数。
其中 是指示前景元素区域的前景掩码。这有助于确保准确保留前景元素外观,同时允许在背景整合方面具有灵活性。在训练期间,总体优化目标是:
其中 是控制身份保留权重的超参数。我们在训练期间将 从 1.0 逐渐衰减到 0.6,这鼓励模型在训练后期更多地关注场景和谐,同时仍保持合理的身份保留。
4. 可控的保真度 - 多样性权衡
为了在外观保真度和创意多样性之间实现灵活控制,我们在训练期间实施随机丢弃策略。首先,我们随机丢弃前景分支的权重,使模型能够在基于全局文本信息自由生成前景元素和严格保留给定的前景身份之间进行调整。其次,我们随机丢弃要散布的语义特征和前景元素的变分自编码器(VAE)特征,从而灵活控制语义和外观之间的平衡。具体来说,我们应用:
其中 是指示函数, 是均匀随机变量, 分别是分支权重、语义特征和 VAE 特征的丢弃概率。
实验与结果
1. 数据集、基准和指标
BlobData 整理。为了训练 BlobCtrl,我们构建了 Blob - Data(186 万个样本),其来源是 BrushData,包含图像、分割掩码、拟合椭圆参数(带有导出的二维高斯分布)和描述性文本。数据集整理过程包括:(1)过滤源图像,保留短边超过 480 像素且具有有效实例分割掩码的图像。(2)应用掩码过滤标准,保留面积比占图像总面积 0.01 到 0.9 之间的掩码,并排除位于图像
BlobCtrl:用于元素级图像生成和编辑的统一灵活框架边界的掩码。(3)对于过滤后的掩码,拟合椭圆参数 并导出二维高斯分布。(4)去除无效样本,特别是协方差值低于 1e - 5 的样本。(5)使用 InternVL - 2.5(Chen 等人,2024)生成详细的图像描述。
BlobBench数据集整理。现有的评估基准,如DreamBooth(Ruiz等人,2023年)、COCOE(Yang等人,2023年)、COCO Val(Lin等人,2014年)和CreatiLayout(Zhang等人,2024a),要么评估定位能力,要么评估身份保留能力,但不能同时评估两者。它们也没有涵盖元素级操作的所有范围,如组合、移动、调整大小、删除和替换。为了弥补这些不足,我们引入了BlobBench,这是一个包含100张精心挑选图像的综合基准,这些图像均匀分布在不同的元素级操作中。每张图像都由专家标注了椭圆参数、前景掩码和详细的文本描述。BlobBench包括来自不同场景(如室内和室外场景、动物和风景)的真实世界图像和人工智能生成的图像,确保了评估的公平性和有效性。
评估指标
我们使用客观指标和人工评估来评估,包括客观评估(身份保留、定位准确性、生成质量和协调性)和主观评估。有关这些指标的详细信息,请参阅附录A。
2. 实现细节
训练细节。BlobCtrl基于Stable Diffusion v1.5(Rombach等人,2022年)构建。在训练期间,所有图像和注释都被调整为像素。我们使用预训练的UNet权重初始化前景和背景分支。前景分支在移除交叉注意力层的情况下进行全量微调,而背景分支使用LoRA(Hu等人,2021年)进行微调,秩为64。我们使用Adam优化器(Kingma & Ba,2014年),学习率为1e - 5,权重衰减为0.01。该模型在我们精心整理的Blob - Data数据集上进行训练,该数据集包含个样本,使用24块NVIDIA V100 GPU,批量大小为192,训练7天。为了实现可控的保真度 - 多样性权衡,我们将丢弃概率设置为0.1。在训练过程中,身份保留损失的权重从1.0逐渐衰减到0.6。此外,为了在推理过程中实现无分类器引导,我们将字幕丢弃概率设置为0.1。
评估细节。我们在BlobBench基准上,将BlobCtrl与三种最先进的方法进行了比较:Gli - Gen(Li等人,2023年),一种基于边界框的文本到图像模型;Anydoor(Chen等人,2023年),一种基于分割掩码的图像到图像模型;以及Magic Fixup(Chen等人,2023年),该方法专门用于协调变换区域。为了系统地评估五种基本的元素级操作(组合、移动、调整大小、替换和移除),我们为基线方法适配了特定的工作流程。对于Anydoor,我们通过将背景传送到前景区域来创建干净的背景,然后通过将前景对象传送到目标位置进行编辑。对于GliGen,我们使用BlobCtrl移除元素以获得干净的背景,然后应用带有文本和图像条件的边界框约束。对于Magic Fixup,我们使用编辑操作中的刚性变换对前景元素进行变形,然后进行场景协调。
3. 定量评估
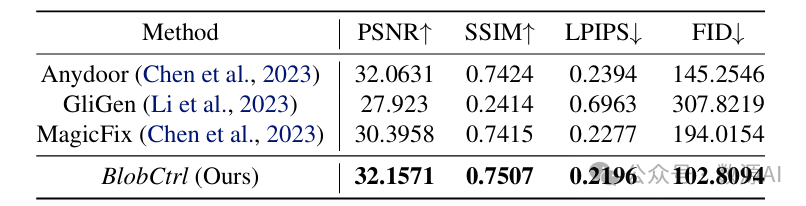
与最先进方法的比较。如表1和表2所示,BlobCtrl在所有评估指标上都比现有方法有持续且显著的改进:
-
身份保留:对于需要身份保留的任务(组合、移动、调整大小、替换),与最佳基线相比,BlobCtrl的平均CLIP - I得分(87.48对84.28)和DINO得分(87.45对81.70)显著更高。对于移除任务,我们的方法显示出更低的身份得分(CLIP - I和DINO的平均得分)(21.95对26.55),表明元素消除更彻底。

4. 定性评估
图4展示了BlobCtrl与最先进方法在各种元素级操作场景下的定性比较。结果显示了我们方法的几个关键优势:
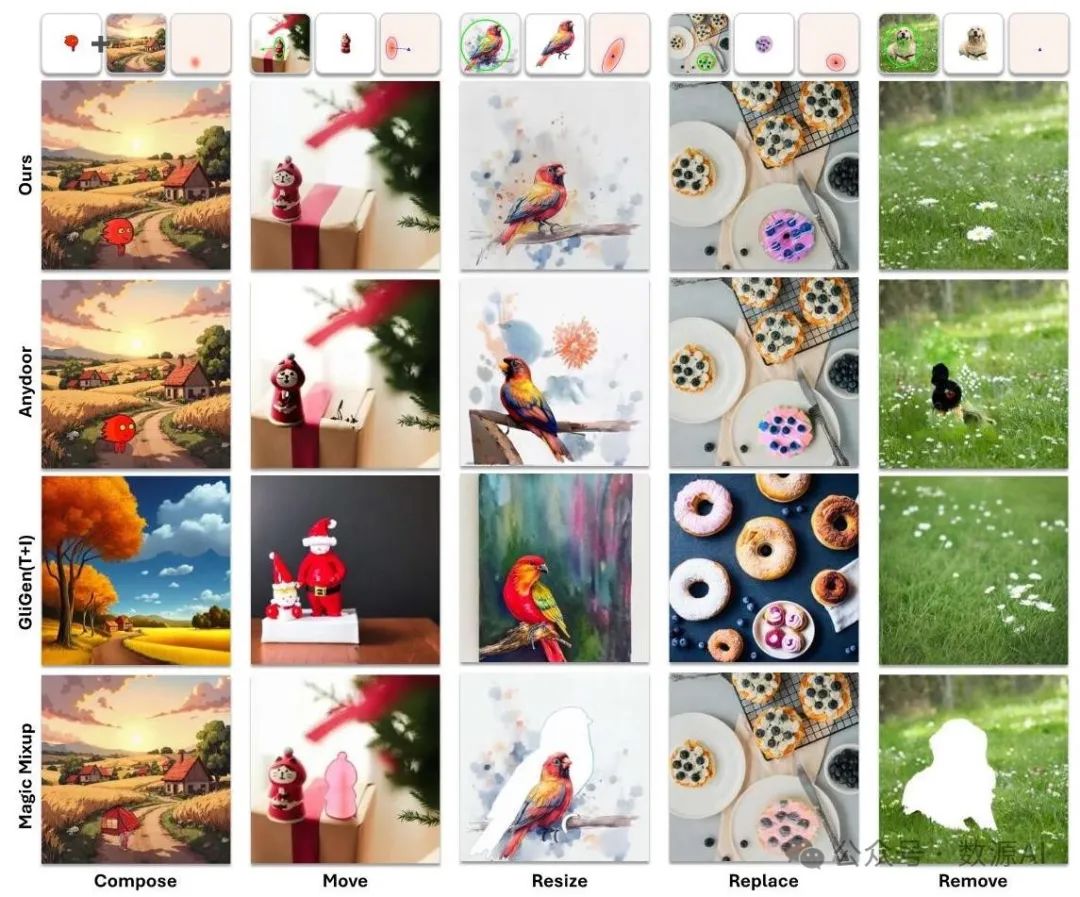
图4:不同方法在元素级操作能力上的可视化比较。我们评估了五项基本操作:组合、移动、调整大小、替换和移除。Anydoor(Chen等人,2023年)在精确保留元素身份方面存在困难,GliGen(Li等人,2023年)无法保留任何身份信息,而Magic Fixup(Chen等人,2023年)生成的结果在视觉协调性方面较差。相比之下,BlobCtrl在所有操作中都取得了卓越的效果,同时既保留了元素身份又实现了视觉和谐。我们建议放大查看源图像和元素级操作说明的细节。
-
Anydoor(Chen等人,2023年)在元素操作过程中难以准确保留元素身份,并且在元素级移除方面存在局限性,常常会留下伪影或修改不完整。
-
虽然GliGen(Li等人,2023年)具备布局控制能力,但它无法有效保留被操作元素的视觉外观和身份,导致输出结果不一致。
-
Magic Mixup(Alzayer等人,2024年)的协调能力不足,导致修改后的元素与其周围环境在视觉上不一致。
相比之下,BlobCtrl在各个方面都表现出卓越的性能——对不同场景有更好的泛化能力、更准确的身份保留以及在保持视觉连贯性的同时进行精确的布局控制。
5. 消融研究
可控性和灵活性分析 如图5所示,BlobCtrl通过调整双分支融合的控制时间步长间隔和控制强度,实现了对身份保留和多样性之间权衡的灵活控制。当仅使用带有文本提示的背景分支时,身份保留和布局准确性都会受到影响。最佳结果来自于结合空间感知语义特征和变分自编码器(VAE)特征。
身份保留得分函数的消融实验。我们进行了一项消融研究,以分析我们的身份保留得分函数的有效性。如图6所示,在相同的训练步骤下,使用身份保留得分函数的模型的噪声预测损失(0.0235)明显低于未使用该函数的模型(0.0399),这表明其收敛速度更快。为了更好地理解该得分函数如何影响生成过程,我们使用前景分支的预测噪声对去噪结果进行了可视化。

图5:灵活控制。我们的双分支融合机制通过调整控制时间步长间隔和融合强度,实现了对多样性和外观保留之间权衡的灵活控制。此外,特征丢弃机制为控制生成过程提供了更灵活的接口。
可视化结果显示,当受到身份保留得分函数的引导时,前景分支能够有效地专注于生成前景内容,这验证了我们通过该机制将前景和背景元素生成解耦的设计选择。

图6:身份保留得分函数的消融实验。对一只鹿进行缩放操作时的训练损失和去噪可视化,展示了身份保留得分函数如何在元素级操作过程中实现更快的收敛和有效的前景 - 背景解耦。
结论
本研究引入了BlobCtrl,这是一个统一的框架,它使用基于概率斑点(blob)的表示方法集成了元素级生成和编辑功能。斑点作为视觉基元,用于编码空间布局、语义和身份信息,从而实现精确的元素操作。采用自监督训练的双分支架构能够保留前景元素的身份信息并保持背景的协调性。随机数据增强和丢弃策略可在外观保真度和创意多样性之间实现灵活控制。在BlobBench上进行的大量实验表明,BlobCtrl在元素级操作任务中达到了当前的最优性能。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









