



🌐 社群导航
🔗 点击加入➡️【AIGC/LLM/MLLM/3D/自动驾驶】 技术交流群
最新论文解读系列

论文名:TRCE: Towards Reliable Malicious Concept Erasure in Text-to-Image Diffusion Models
论文链接:https://arxiv.org/pdf/2503.07389
开源代码:http://github.com/ddgoodgood/TRCE

导读
文本到图像扩散模型的最新进展使得能够生成逼真的图像,但它们也存在产生恶意内容(如不适宜内容图像)的风险。为了降低风险,人们研究了概念擦除方法,以帮助模型遗忘特定概念。然而,当前的研究难以在保留模型正常生成能力的同时,完全擦除隐式嵌入在提示词(如隐喻表达或对抗性提示词)中的恶意概念。为应对这一挑战,我们的研究提出了TRCE(两阶段概念擦除方法,Two - stage concept erasure),采用两阶段概念擦除策略,在可靠擦除和知识保留之间实现有效的平衡。首先,TRCE从擦除文本提示词中隐式嵌入的恶意语义开始。通过确定一个关键的映射目标(即嵌入),我们优化交叉注意力层,将恶意提示词映射到上下文相似但具有安全概念的提示词。这一步骤防止模型在去噪过程中受到恶意语义的过度影响。在此之后,考虑到扩散模型采样轨迹的确定性特性,TRCE通过对比学习进一步引导早期去噪预测朝着安全方向发展,远离不安全方向,从而进一步避免生成恶意内容。最后,我们在多个恶意概念擦除基准测试中对TRCE进行了全面评估,结果表明它在擦除恶意概念的同时,能更好地保留模型的原始生成能力。
简介
最近,大规模文本到图像(T2I)扩散模型(DMs)因其能够生成高度逼真的图像而受到广泛关注。这些模型在大量源自互联网的数据上进行训练,从而获得了根据文本提示生成各种视觉概念的能力。然而,由于存在有毒的训练数据,这些模型也学会了生成不适当的内容。因此,它们可能会被滥用来根据包含不适当概念的提示生成不适宜工作场合(NSFW)的图像。为了解决这些安全问题,研究人员提出了各种增强安全性的机制,例如过滤有毒数据并重新训练模型、使用安全检查器过滤输出,以及应用保障策略来引导生成过程。为了进一步增强安全性,概念擦除(CE)被提出用于限制扩散模型生成特定概念的能力。例如,如果通过概念擦除(CE)擦除了“性”这一概念,当提示中包含“裸体、色情、淫秽等”关键词时,模型将生成穿着衣服的人的图像。

图2。由于注意力机制,输入提示(例如)的特殊嵌入 承载了关于概念的丰富语义,并关注显著区域的语义。通过消除标记对生成的影响(即,将与对应的注意力图设置为 0),图像内容将受到显著影响。
预备知识
这项工作主要关注潜在扩散模型(LDMs)中的概念擦除,潜在扩散模型已成为生成高质量图像的强大工具。在本节中,我们将介绍潜在扩散模型的预备知识,以及用于进行擦除操作的相关组件。
交叉注意力层:在潜在扩散模型(LDMs)中,图像 首先使用编码器 映射到潜在表示 中。然后,该模型利用一个去噪 U 型网络(表示为 )来学习潜在空间中的去噪过程。为了生成特定的视觉概念,潜在扩散模型的一个关键方面是它们能够根据文本信息生成图像。这是通过一个 CLIP文本编码器 实现的,该编码器将文本提示 转换为嵌入 ,其中 SoT 和 EoT 分别是文本 的起始和结束特殊标记, 是 处理的最大尺寸, 是提示中单词的数量。然后, 通过交叉注意力机制融入生成过程:
其中 和 表示在扩散步骤 时,U 型网络(U-Net)中带有潜在变量 的隐藏状态。
无分类器引导:为了提高生成图像的保真度和可控性,潜在扩散模型(LDMs)采用了无分类器引导(classifier-free guidance,c.f.g)机制。这种方法包括训练模型在有条件(基于文本提示 )和无条件(基于空文本 )两种情况下预测噪声,训练目标变为:
其中 表示在时间步 通过对 应用噪声 得到的潜在特征。模型以概率 丢弃条件 进行训练,即进行无条件训练。
通过对该策略进行训练,CFG(条件生成式对抗网络,Conditional Generative Adversarial Network)可以通过调整噪声预测来指导模型推理,以增强文本提示 的影响,这一过程可表述如下:
其中 表示引导强度。最后,在这种引导下,推理过程从随机高斯噪声 开始,并使用调整后的噪声预测
在 步内对其进行迭代去噪,以逼近潜在代码 。然后,将 输入图像解码器 来重建最终图像 。
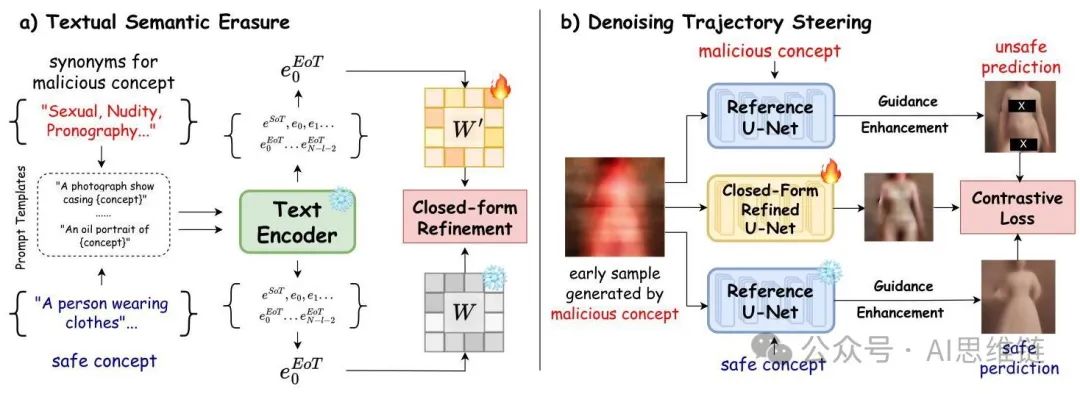
图3. 所提出的TRCE(可信概念擦除,Trustworthy Concept Erasure)的整体框架,该框架涉及两阶段模型细化,以实现可靠的恶意概念擦除。a) 文本语义擦除(第4.1节):在第一阶段,我们通过闭式解来细化交叉注意力层的“键”(Key)和“值”(Value)矩阵,以消除嵌入在输入提示中的特定概念的文本语义。b) 去噪轨迹引导(第4.2节):在第二阶段,对第一阶段细化后的U型网络(U-Net)进行微调,将早期去噪预测引导至安全方向,远离不安全方向,从而进一步避免生成恶意视觉内容。
方法
如图3所示,TRCE由两个阶段组成,即文本语义擦除(第4.1节)和去噪轨迹引导(第4.2节),以可靠地擦除文本到图像(T2I)扩散模型中的恶意概念。在本节中,我们将介绍这两个阶段的详细方法。
1. 文本语义擦除
在这个阶段,TRCE(文本鲁棒性内容编辑,Text Robust Content Editing)首先消除输入提示中恶意语义的影响。我们采用了一种闭式交叉注意力细化方法,该方法广泛应用于基于注意力的网络中的知识编辑。在这些研究中,交叉注意力层的“键”和“值”投影矩阵和被调整,以将概念嵌入映射到目标嵌入(例如,将“裸露”一词映射为空文本∅)。在此过程中,为了保留知识,不相关的嵌入必须保持不受影响。目标函数的形式如下:
(4)
其中 表示精炼投影矩阵, 控制擦除能力和先验保留之间的平衡。
在本研究中,我们通过找出更有效的映射目标,改进了应用公式 4 的策略,以在保持先验保留的同时提高擦除效果。详细分析如下。
特殊嵌入的作用:正如之前与文本到图像(T2I)扩散模型相关的研究所示,特殊嵌入在图像生成中的作用可总结为:
-
[序列起始符(SoT)] 的嵌入对视觉内容生成的贡献最为显著,尤其影响整体构图。修改 [SoT] 的嵌入会导致生成内容快速变化。
-
[序列结束符(EoT)] 的嵌入专注于显著区域,并承载整个提示的语义。修改 [EoT] 会在保留提示总体上下文的同时改变图像内容。
-
特定概念(例如,代表“裸露”的概念)的关键词嵌入 [KEY] 从提示上下文(prompt context)中获取的语义较少,并且通常呈现出这些概念独特的语义。因此,对这些嵌入进行广泛的重新映射会导致快速的知识遗忘。
综上所述,基于上述分析,TRCE 仅优化嵌入以提高擦除效果,同时避免因优化或关键词嵌入而导致的图像质量下降。这种方法使 TRCE 能够有针对性地擦除特定概念相关的语义,同时保留整个提示的上下文。因此,它既提高了擦除效果,又保留了知识。
闭式精修:给定一个预训练的扩散U型网络 ,我们的目标是消除恶意概念 的语义,以获得一个精修后的U型网络 。为实现这一目标,首先,如图3 (a) 所示,我们通过大语言模型(LLMs)进行概念增强,列出 的同义词及其相反的安全概念 ,并将它们应用于各种提示模板,这些模板用于在不同的视觉上下文中呈现该概念。完成这一步后,我们得到带有恶意概念 的擦除提示集 ,并得到带有相反安全概念 的目标提示集 (例如,“一个穿着衣服的人”是“裸露”的相反概念)。按照同样的方法,我们得到用于保留知识的保留提示集 ,其设置与先前的工作相同。使用文本编码器 提取 和 中提示的嵌入,由于多个嵌入携带相似的信息,我们可以仅优化每个提示中的第一个标记。最后,用于优化的嵌入表示为 和 。根据公式4,我们精修 中相关的注意力矩阵,并且这个优化目标产生一个闭式解:
(5)
进行此细化操作后,我们得到细化矩阵 ,用于将预训练的 更新为我们目标中的 ,使其具备从文本输入中消除恶意语义的能力。
2. 去噪轨迹引导
为了在进一步增强擦除效果的同时避免降低生成能力,在第二阶段,TRCE(轨迹引导擦除,Trajectory-guided Removal of Content and Effects)进一步微调模型的早期去噪预测,引导扩散采样轨迹朝着更安全的内容生成方向发展。
图4展示了引导去噪轨迹以消除恶意视觉内容的主要思路。通常,扩散采样最初会生成图像的大致轮廓。在采样中期的一个转折点,模型开始生成特定视觉概念的细节。基于这一观察,我们对第一阶段的精炼模型进行微调,在这个转折点之前引导其去噪预测。在这个阶段,为了忽略文本输入的依赖性,我们仅微调的视觉层(自注意力层和交叉注意力层的“q”矩阵),旨在获得最终的安全模型
轨迹准备:利用原始的U-Net 和4.1节中使用的恶意提示,我们缓存模型推理的早期采样轨迹。每个轨迹表示为,其中是最大时间步长,我们根据经验将初始步随机选择用于微调。此外,我们为正则化项生成一组无条件采样轨迹(文本为空∅)。
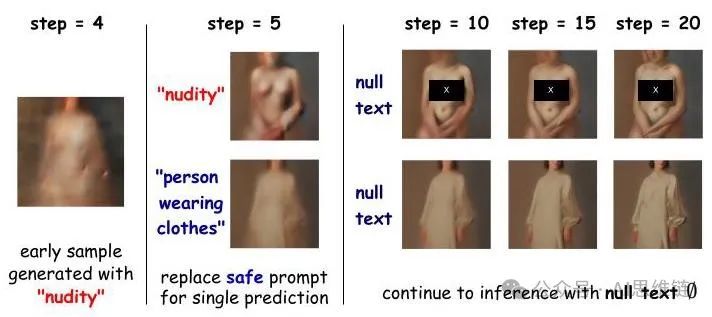
图4。基于扩散模型采样中常微分方程(ODE)轨迹的确定性特性,可以通过在早期去噪阶段修改单个去噪预测来简单地控制去噪轨迹。
引导增强:给定从缓存轨迹中采样得到的 ,我们的目标是将其条件和无条件去噪预测 或 引导至安全方向,同时远离不安全方向。为了对这些方向进行建模,我们使用参考 U 型网络 (原始版本),利用公式 3 来构建 和 的语义增强去噪预测:
(6)
表示引导尺度, 和 分别表示增强后的不安全预测和安全预测。
微调目标:我们使用标准三元组边界损失作为对比函数,其表达式如下:
该目标函数使当前的去噪预测更偏向安全方向,同时远离不安全方向,其中裕度(margin)为裕度值,将优化方向约束为更倾向于 。此外,使用无条件预测的对齐作为正则化项,以确保模型原有的生成能力不受影响。该优化目标公式如下:
为了在整个采样过程中保留模型的预测,我们使用从 中均匀采样的 来应用这个正则化项。最后,整体微调目标按照 进行优化,并且使用 来平衡擦除能力和先验保留能力。经过这次微调,我们得到最终模型 ,该模型具有更可靠的擦除性能,可减少恶意视觉内容的生成。
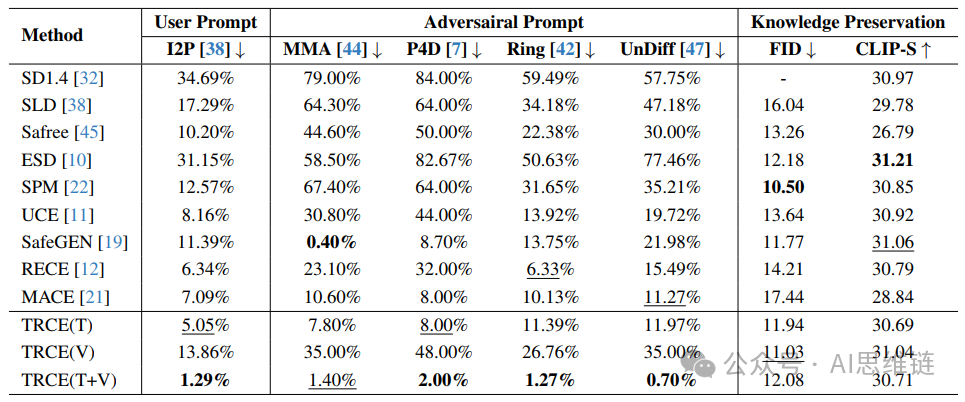
表1. 当前概念擦除方法在擦除不安全概念“性相关”时的攻击成功率(ASR)和知识保留能力。ASR由NudeNet以0.45的阈值进行测量。FID分数通过将生成的图像与默认的StableDiffusion V1.4(SD V1.4)输出进行比较来测量,以验证知识保留能力。TRCE(T)和TRCE(V)分别指第一阶段和第二阶段的应用,而TRCE(T + V)表示两个阶段都应用。
实验
在本节中,我们通过一系列实验评估TRCE的有效性。遵循先前工作的设置,我们使用StableDiffusion V1.4(SD V1.4)作为基础模型,评估其在“性相关内容擦除”(第5.2节)和“多恶意概念擦除”(第5.3节)任务中的恶意概念擦除能力。对于对比方法,我们使用它们官方提供的实现进行评估。
1. 实现细节
我们使用Diffusers库实现所有实验,并使用DDIM调度器以30步生成图像。在第一阶段,我们使用GPT - 4 - o将概念关键词扩展为20个同义词,并将它们应用于15个提示模板,共计生成300个提示用于闭式细化。公式4中的 默认设置为0.01。在第二阶段,引导尺度 和保留尺度 分别设置为15和100。对于色情/多概念擦除任务,我们生成100和300个轨迹样本,使用学习率为 的Adam优化器进行3个轮次的微调。在单张RTX 4090 GPU上,微调过程大约需要300秒。更多详细实现请参考附录A. 3。
2. 色情内容擦除
在本节中,我们使用不安全概念“性相关(sexual)”评估TRCE和基线方法的擦除能力,该概念已通过红队攻击方法得到广泛研究。评估基准。遵循先前的工作,我们评估恶意概念擦除方法针对网络来源的用户提示和对抗性提示的防护能力。对于用户提示,我们使用
I2P(不适当图像提示,Inappropriate Image Prompts)数据集,并评估标记为“性相关”的931条提示。对于对抗性提示,我们使用由红队工具生成的四个对抗性提示数据集:MMA-diffusion(MMA)、Prompt4Debugging(P4D)、Ring-A-Bell(Ring)、UnlearnDiff(UnDiff)。
评估指标。我们采用攻击成功率(Attack Success Rate,ASR)来衡量对恶意内容的防护能力。对于色情内容擦除任务,我们使用NudeNet检测器来识别图像是否包含裸露身体部位。我们遵循文献将检测器的阈值设置为0.45,以获得更高的检测灵敏度。对于多概念擦除任务,我们使用Q16检测器来识别图像是否包含恶意内容。为了验证知识保留能力,我们使用COCO中的提示,使用默认的StableDiffusion V1.4(SD V1.4)生成模型,并通过每种方法生成的3000个样本评估弗雷歇 inception 距离(Frechet Inception Distance,FID),以衡量概念擦除是否保持了原始模型的生成能力。此外,我们使用CLIP分数(CLIP-Score)来衡量文本 - 图像的一致性。
结果分析。定量实验结果如表1所示。在擦除效果方面,所提出的TRCE(轨迹引导擦除,Trajectory-guided Removal of Content, TRCE)取得了最佳性能。仅消除文本语义时,TRCE (T) 通过识别更合适的优化目标([EoT]中的语义)已经展现出强大的擦除能力。当单独应用去噪轨迹偏移策略时,TRCE (V) 的性能相对较差。这是因为即使引导了早期的去噪轨迹,提示中的恶意语义仍会在去噪后期导致出现色情内容。因此,通过结合这两个阶段,TRCE (T+V) 可以实现显著更强的擦除鲁棒性。此外,我们在图5中展示了TRCE和对比方法的一些生成案例。可以观察到,TRCE在保留输入提示整体上下文的同时,有效擦除了不安全语义,且未显著影响无关区域。这表明TRCE能更精细地擦除恶意概念,从而更好地保留生成能力。
表2. I2P基准测试中擦除多个恶意概念的评估结果。我们报告了由Q16检测器检测到的不当率。
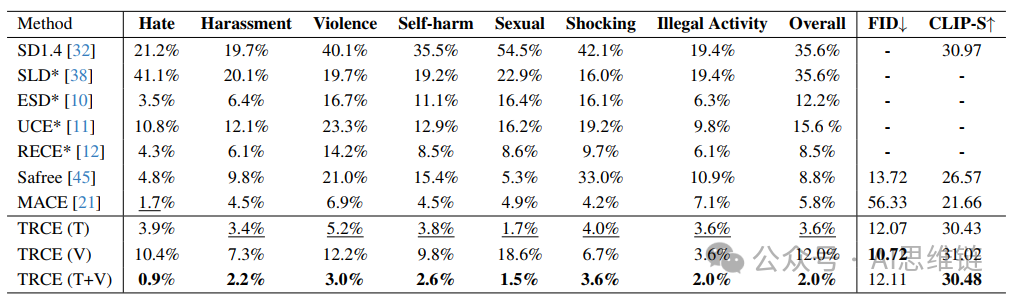

图5. 当前方法对抗对抗性提示的可视化结果。更多可视化结果请参考附录E
3. 多恶意概念擦除
为了进一步证明文本风险概念擦除(TRCE)在擦除更大类别的显式内容方面的有效性,我们遵循文献的实验设置,对擦除I2P数据集中的所有有害概念进行了实验,这些概念包括:“仇恨、骚扰、暴力、自残、色情、惊悚和非法活动”。实验结果报告于表2中。由于我们无法获取先前研究擦除多个显式概念的实验设置,部分先前研究的结果取自文献以供比较。实验结果表明,即使仅应用第一阶段,TRCE也能实现最佳的擦除性能。此外,第二阶段能够更充分地擦除多个有害概念,从而带来更好的擦除效果。值得注意的是,我们发现现有方法在同时擦除多个有害概念时会对通用生成能力产生显著影响。相比之下,TRCE即使在进行多概念擦除时也能很好地保留知识,这极大地提高了TRCE作为防止恶意内容的保障措施的实际适用性。

图6。该可视化展示了TRCE(文本相关概念擦除,Text Relevant Concept Erasure)从I2P(图像到文本,Image-to-Text)中擦除多个恶意概念的能力。出于安全考虑,我们对包含冒犯性内容的图像进行了模糊处理。
4. 模块分析
在本节中,我们使用第5.2节介绍的相同实验设置进行消融研究,以验证我们提出的关键组件的有效性。在这部分,我们报告四个对抗性提示基准内的平均自动语音识别率(ASR,Automatic Speech Recognition)作为指标“Adv”。
表3. 文本语义擦除性能的定量消融,以及在不同知识保留率下进一步应用去噪轨迹引导的情况。
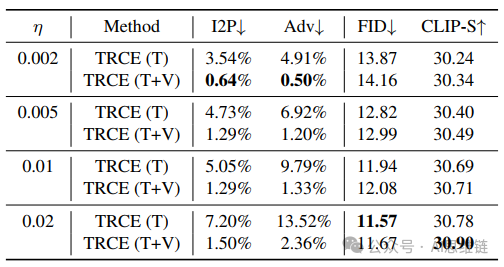
两阶段设计的有效性。TRCE(轨迹引导概念擦除,Trajectory-guided Concept Erasure)的核心思想是将文本语义擦除(TRCE (T))和去噪轨迹引导(TRCE (V))相结合,以实现可靠的恶意概念擦除。如表3所示,我们分析了在不同知识保留率 下,将TRCE (V) 与TRCE (T) 结合应用的效果。正如4.2节所讨论的,可以观察到TRCE (T) 的性能对 高度敏感,而TRCE (V) 则在知识保留方面做出较小牺牲的情况下,持续提高概念擦除能力。值得注意的是,在 值较高时,TRCE (V) 在防御对抗性提示鲁棒性方面表现出更显著的提升。总体而言,当TRCE (T) 难以平衡擦除强度时,TRCE (V) 的作用是通过修改去噪预测来增强擦除效果。同时,由于TRCE (T) 可以消除大多数恶意语义对生成过程的影响,这使其成为TRCE (V) 有效性的必要因素。最后,这两个阶段的协作能够在更有效地擦除概念的同时,更好地保留模型知识。
[文本结束符(EoT)]优化的有效性。表4展示了在文本语义擦除中对不同标记进行优化的结果。如表所示,当仅优化[关键词(KEY)]时,模型难以防止不安全内容。这是因为在注意力机制的作用下,[关键词(KEY)]携带的语义信息比[文本结束符(EoT)]少。在所有评估结果中,仅优化[文本结束符(EoT)]嵌入在实现最佳擦除性能的同时,还具备良好的知识保留能力。然而,同时微调[文本起始符(SoT)]和[关键词(KEY)]会降低擦除能力和知识保留能力,这证明了仅优化[文本结束符(EoT)]这一策略的有效性。有关[文本结束符(EoT)]的更多分析,请参阅附录B。
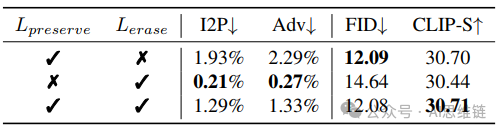
所提出的损失函数的有效性。表5展示了在第二阶段微调中应用不同损失函数的消融实验结果。该表清晰地表明,在维持模型原有的生成能力方面起着至关重要的作用。虽然移除可以加速微调的收敛,但会显著降低生成图像的质量。对于用于概念擦除的对比损失,与仅使用安全预测进行对齐相比,对比学习策略增强了对去噪预测中恶意语义的识别能力。这为引导去噪轨迹提供了更明确的指导,从而有效提高了概念擦除的效果。
表4. 针对文本语义擦除优化不同标记的定量消融实验结果(第4.1节)。知识保留率默认设置为。
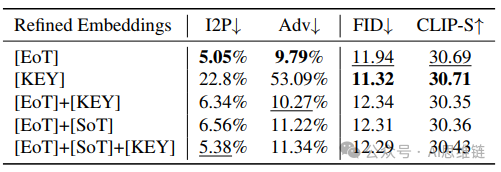
表5. 应用不同的微调目标进行去噪轨迹引导的定量消融实验结果(第4.2节)。“不使用 ”的设置表示我们仅应用安全引导对齐,而不进行对比学习。
总结
本文提出了TRCE(两阶段擦除协作方法,Two - stage erasing Cooperation for Reliable malicious Concept Erasure),该方法利用两阶段擦除的协作来实现可靠的恶意概念擦除。在第一阶段,TRCE通过将嵌入识别为关键映射目标,通过闭式解优化模型参数来消除文本语义,从而有效消除生成过程中恶意语义的影响。在第二阶段,TRCE进一步微调扩散模型的早期去噪预测,通过对比学习将采样轨迹引导至安全方向。最后,我们在多个基准测试上对TRCE进行了全面评估。结果证实,TRCE在可靠地擦除恶意概念的同时,能更好地保留模型的原始生成能力。

















 4885
4885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









