







LVI-SAM激光点云辅助视觉特征深度提取
1. 特征深度关联(本质:激光雷达深度点与视觉特征关联
3.1.1.2 特征深度关联(本质:激光雷达深度点与视觉特征关联)
用于将激光雷达深度点与视觉特征关联,通过以下核心步骤实现:
- 激光雷达深度堆叠:为了获得更密集的深度图,堆叠多个激光雷达帧,处理稀疏的3D激光雷达扫描。
- 投影到单位球体:将视觉特征和激光雷达深度点投影到以相机为中心的单位球体上,以统一坐标系。
- 深度点下采样:对激光雷达深度点进行下采样,确保在球体上以极坐标存储,保持恒定的点密度。
- K-D 树搜索最近点:构建二维 K-D 树,利用视觉特征的极坐标,在球体上搜索最近的三个深度点。
- 计算特征深度:通过找到的三个深度点构建的平面,计算视觉特征与相机中心形成的直线与平面的交点来确定特征的深度。
- 验证深度一致性:通过检查三个深度点之间的最大距离,如果超过2米则拒绝该深度关联,以避免堆叠不同物体深度点引起的模糊和错误估计。
- 深度关联展示:投影深度点到相机图像上并标注成功关联深度的视觉特征,确保有效的深度关联并标记验证失败的区域。
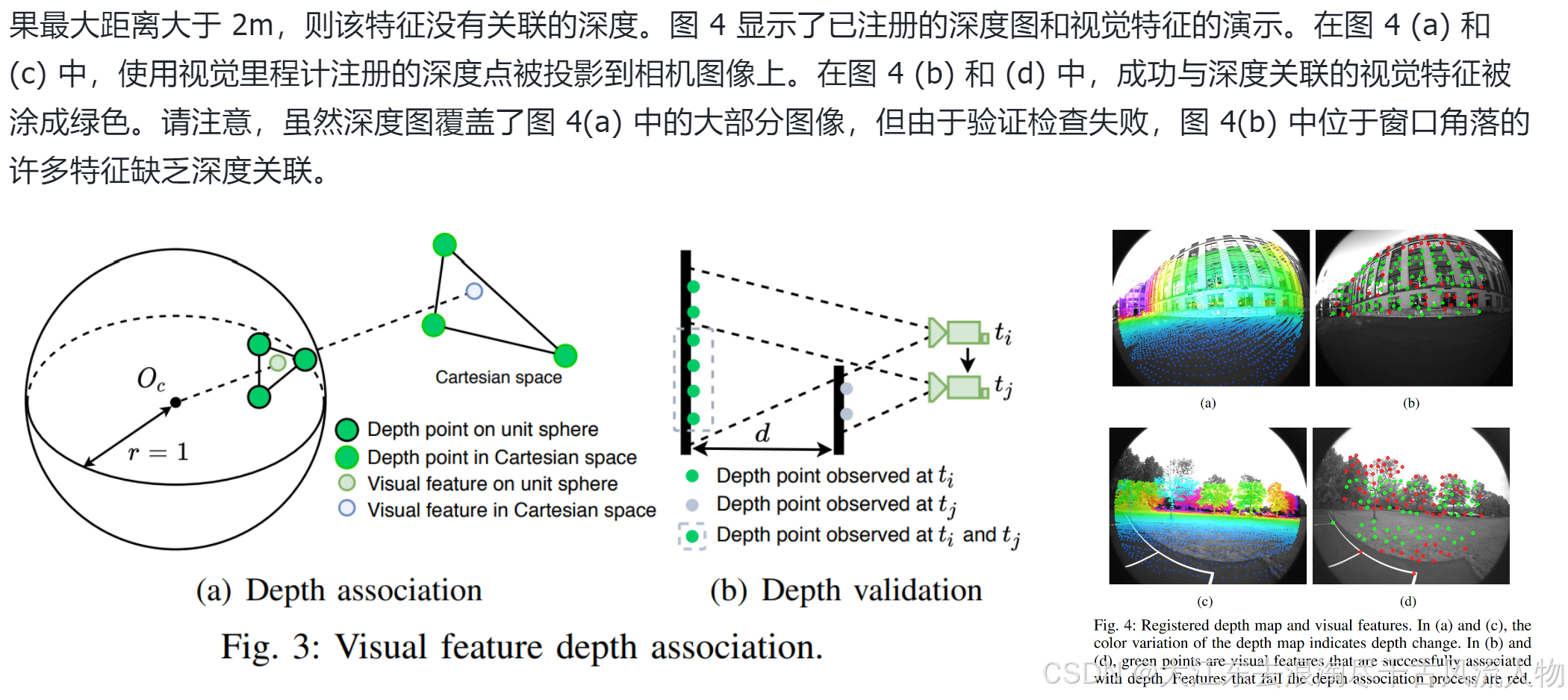
在初始化 VIS 时,我们使用估计的视觉里程计将激光雷达帧注册到相机帧。由3D 激光雷达通常会产生稀疏扫描,因此我们堆叠多个激光雷达帧以获得密集的深度图。为了将特征与深度值关联起来,首先将视觉特征和激光雷达深度点投影到以相机为中心的单位球体上。然后对深度点进行下采样并使用其极坐标存储,以在球体上保持恒定密度。使用视觉特征的极坐标搜索二维 K-D 树,找到球体上最近的三个深度点以查找视觉特征。最后,特征深度是视觉特征和相机中心 Oc 形成的线的长度,该线与笛卡尔空间中三个深度点形成的平面相交。图 3(a) 显示了此过程的可视化效果,其中特征深度是虚线直线的长度。通过检查三个最近深度点之间的距离来进一步验证相关特征深度。这是因为堆叠来自不同时间戳的激光雷达帧可能会导致不同物体的深度模糊。图 3(b) 显示了这种情况的说明。在时间 ti 观察到的深度点以绿色表示。相机移动到 tj 时的新位置并观察颜色为灰色的新深度点。然而,由于激光雷达帧堆叠,在 tj 时可能仍然可以观察到在 ti 处的深度点(用虚线灰色线圈出)。使用来自不同物体的深度点关联特征深度会导致不准确的估计。与 [17] 类似,通过检查特征的深度点之间的最大距离来拒绝此类估计。如果最大距离大于 2m,则该特征没有关联的深度。图 4 显示了已注册的深度图和视觉特征的演示。在图 4 (a) 和 © 中,使用视觉里程计注册的深度点被投影到相机图像上。在图 4 (b) 和 (d) 中,成功与深度关联的视觉特征被涂成绿色。请注意,虽然深度图覆盖了图 4(a) 中的大部分图像,但由于验证检查失败,图 4(b) 中位于窗口角落的许多特征缺乏深度关联。
这段代码的核心任务是将激光点云中的点与图像上的特征点进行对应,并计算图像特征点的深度。具体来说,它通过几个步骤将3D点云数据和2D图像特征点联系起来,最终估计出每个图像特征点的深度。下面是详细解释:
2. 更加详细的步骤描述
1. 坐标系转换
首先,代码会将激光点云从世界坐标系转换到相机坐标系。
- 步骤 0.3:使用TF库查找并获取当前时刻的相机位姿(
vins_world到vins_body_ros的变换)。通过这些数据,代码将世界坐标系下的点云转换到相机坐标系中。 - 步骤 0.4:调用
pcl::transformPointCloud函数,将激光点云从世界坐标系转换到相机坐标系下。这一步是将激光点云数据与相机的视角对齐,为后续操作做准备。
2. 构建单位球面坐标系下的图像特征点和激光点云
这一步的目的是将图像上的2D特征点和3D激光点投影到单位球面上,使得它们能够在相同的空间内进行比较。
- 步骤 0.5:将归一化后的图像特征点(z=1)投影到单位球面上。通过归一化处理,每个2D特征点被转换为一个3D方向向量。
- 步骤 5:同样的,将转换到相机坐标系后的激光点云也投影到单位球面上。每个激光点的深度信息被保存在
intensity字段中。
3. 构建深度直方图并过滤激光点云
这一部分的目的是通过构建一个深度直方图,过滤掉冗余的激光点,只保留距离相机最近的激光点。
- 步骤 3:将相机坐标系下的激光点投影到一个二维平面(深度直方图)上。通过这种方式,同一个bin内的多个激光点将被简化为距离最近的那个点。
- 步骤 4:根据深度直方图,从激光点云中提取出最接近的点,并构建一个过滤后的点云。这些点云点是与相机视角最近的点,将被用于后续的深度估计。
4. 最近邻搜索与深度估计
通过将图像特征点和激光点云在单位球面上的位置进行匹配,代码使用KD树查找激光点云中与每个图像特征点最近的三个激光点,并计算其深度。
- 步骤 6:为过滤后的激光点云构建一个KD树,以加速最近邻搜索。
- 步骤 7:对于每个图像特征点,在单位球面上查找与之最接近的三个激光点。通过这三个点的深度信息,以及它们在单位球面上的位置,利用几何方法估计图像特征点的深度。
5. 深度投影与可视化
最后,代码将深度信息投影回到图像平面,并可视化结果。
- 步骤 7:如果找到足够多的匹配点,将估计的深度值赋给图像特征点,并发布这些深度信息用于可视化。
- 步骤 8:将激光点云投影回图像平面,并对比显示。图像上显示的点根据其深度显示不同的颜色,方便用户直观地看到激光点云与图像特征的对应关系。
总结
这个流程目的是为了将激光雷达的3D信息与相机的2D图像特征点相结合。通过这种结合,可以为每个2D特征点估计一个深度值,从而帮助更准确地构建场景的3D结构。这对于视觉SLAM、3D重建等应用非常重要,因为它利用了激光雷达精确的深度测量来增强仅依赖视觉特征的深度估计。
sensor_msgs::ChannelFloat32 get_depth(const ros::Time& stamp_cur, const cv::Mat& imageCur,
const pcl::PointCloud<PointType>::Ptr& depthCloud,
const camodocal::CameraPtr& camera_model ,
const vector<geometry_msgs::Point32>& features_2d) // 去畸变后的归一化坐标 xy1
{
// 0.1 initialize depth for return 深度通道, 用于作为结果返回
sensor_msgs::ChannelFloat32 depth_of_point;
depth_of_point.name = "depth";
depth_of_point.values.resize(features_2d.size(), -1);
// 0.2 check if depthCloud available
if (depthCloud->size() == 0)
return depth_of_point;
// 0.3 look up transform at current image time
try{
listener.waitForTransform("vins_world", "vins_body_ros", stamp_cur, ros::Duration(0.01));
listener.lookupTransform("vins_world", "vins_body_ros", stamp_cur, transform);
}
catch (tf::TransformException ex){
// ROS_ERROR("image no tf");
return depth_of_point;
}
double xCur, yCur, zCur, rollCur, pitchCur, yawCur;
xCur = transform.getOrigin().x();
yCur = transform.getOrigin().y();
zCur = transform.getOrigin().z();
tf::Matrix3x3 m(transform.getRotation());
m.getRPY(rollCur, pitchCur, yawCur);
Eigen::Affine3f transNow = pcl::getTransformation(xCur, yCur, zCur, rollCur, pitchCur, yawCur);
// 0.4 transform cloud from global frame to camera frame
// 激光点云: 世界坐标系 ---> 相机坐标系
pcl::PointCloud<PointType>::Ptr depth_cloud_local(new pcl::PointCloud<PointType>());
pcl::transformPointCloud(*depthCloud, *depth_cloud_local, transNow.inverse());
// 0.5 project undistorted normalized (z) 2d features onto a unit sphere
// 将视觉特征点的归一化坐标投影到单位球上
pcl::PointCloud<PointType>::Ptr features_3d_sphere(new pcl::PointCloud<PointType>());
for (int i = 0; i < (int)features_2d.size(); ++i)
{
// normalize 2d feature to a unit sphere
Eigen::Vector3f feature_cur(features_2d[i].x, features_2d[i].y, features_2d[i].z); // z always equal to 1
feature_cur.normalize();
// convert to ROS standard
PointType p;
p.x = feature_cur(2);
p.y = -feature_cur(0);
p.z = -feature_cur(1);
p.intensity = -1; // intensity will be used to save depth
features_3d_sphere->push_back(p);
}
// 3. project depth cloud on a range image, filter points satcked in the same region
// 构造激光点云的深度直方图, 对激光点云进行采样 (类似于 LOAM 和 VoxelGrid)
float bin_res = 180.0 / (float)num_bins; // currently only cover the space in front of lidar (-90 ~ 90)
cv::Mat rangeImage = cv::Mat(num_bins, num_bins, CV_32F, cv::Scalar::all(FLT_MAX)); // 深度直方图
for (int i = 0; i < (int)depth_cloud_local->size(); ++i)
{
PointType p = depth_cloud_local->points[i];
// filter points not in camera view
if (p.x < 0 || abs(p.y / p.x) > 10 || abs(p.z / p.x) > 10)
continue;
// 当前激光点在深度直方图上的索引
// find row id in range image
float row_angle = atan2(p.z, sqrt(p.x * p.x + p.y * p.y)) * 180.0 / M_PI + 90.0; // degrees, bottom -> up, 0 -> 360
int row_id = round(row_angle / bin_res);
// find column id in range image
float col_angle = atan2(p.x, p.y) * 180.0 / M_PI; // degrees, left -> right, 0 -> 360
int col_id = round(col_angle / bin_res);
// id may be out of boundary
if (row_id < 0 || row_id >= num_bins || col_id < 0 || col_id >= num_bins)
continue; // 超出索引范围
// only keep points that's closer 仅仅保留最近的激光点深度
float dist = pointDistance(p);
if (dist < rangeImage.at<float>(row_id, col_id))
{
rangeImage.at<float>(row_id, col_id) = dist; // 深度
pointsArray[row_id][col_id] = p; // 激光点
}
}
// 4. extract downsampled depth cloud from range image
// 在深度直方图中, 每个bin只保留最近的一个激光点
pcl::PointCloud<PointType>::Ptr depth_cloud_local_filter2(new pcl::PointCloud<PointType>());
for (int i = 0; i < num_bins; ++i)
{
for (int j = 0; j < num_bins; ++j)
{
if (rangeImage.at<float>(i, j) != FLT_MAX)
depth_cloud_local_filter2->push_back(pointsArray[i][j]);
}
}
*depth_cloud_local = *depth_cloud_local_filter2;
publishCloud(&pub_depth_cloud, depth_cloud_local, stamp_cur, "vins_body_ros");
// 5. project depth cloud onto a unit sphere
// 将保留下来的激光点投影到单位球上
pcl::PointCloud<PointType>::Ptr depth_cloud_unit_sphere(new pcl::PointCloud<PointType>());
for (int i = 0; i < (int)depth_cloud_local->size(); ++i)
{
PointType p = depth_cloud_local->points[i];
float range = pointDistance(p);
p.x /= range;
p.y /= range;
p.z /= range;
p.intensity = range;
depth_cloud_unit_sphere->push_back(p);
}
if (depth_cloud_unit_sphere->size() < 10)
return depth_of_point;
// 6. create a kd-tree using the spherical depth cloud
pcl::KdTreeFLANN<PointType>::Ptr kdtree(new pcl::KdTreeFLANN<PointType>());
kdtree->setInputCloud(depth_cloud_unit_sphere);
// 7. find the feature depth using kd-tree
// 在单位球上, 寻找与视觉特征点最近的三个激光点, 来估计视觉特征点的深度
vector<int> pointSearchInd;
vector<float> pointSearchSqDis;
float dist_sq_threshold = pow(sin(bin_res / 180.0 * M_PI) * 5.0, 2);
for (int i = 0; i < (int)features_3d_sphere->size(); ++i)
{
kdtree->nearestKSearch(features_3d_sphere->points[i], 3, pointSearchInd, pointSearchSqDis);
if (pointSearchInd.size() == 3 && pointSearchSqDis[2] < dist_sq_threshold)
{
// 单位球上最近的三个激光点 A B C (实际坐标)
float r1 = depth_cloud_unit_sphere->points[pointSearchInd[0]].intensity; // A的深度
Eigen::Vector3f A(depth_cloud_unit_sphere->points[pointSearchInd[0]].x * r1,
depth_cloud_unit_sphere->points[pointSearchInd[0]].y * r1,
depth_cloud_unit_sphere->points[pointSearchInd[0]].z * r1);
float r2 = depth_cloud_unit_sphere->points[pointSearchInd[1]].intensity;
Eigen::Vector3f B(depth_cloud_unit_sphere->points[pointSearchInd[1]].x * r2,
depth_cloud_unit_sphere->points[pointSearchInd[1]].y * r2,
depth_cloud_unit_sphere->points[pointSearchInd[1]].z * r2);
float r3 = depth_cloud_unit_sphere->points[pointSearchInd[2]].intensity;
Eigen::Vector3f C(depth_cloud_unit_sphere->points[pointSearchInd[2]].x * r3,
depth_cloud_unit_sphere->points[pointSearchInd[2]].y * r3,
depth_cloud_unit_sphere->points[pointSearchInd[2]].z * r3);
// 视觉特征点在单位球上的坐标 V
// https://math.stackexchange.com/questions/100439/determine-where-a-vector-will-intersect-a-plane
Eigen::Vector3f V(features_3d_sphere->points[i].x,
features_3d_sphere->points[i].y,
features_3d_sphere->points[i].z);
// 估计视觉特征点的深度 s
Eigen::Vector3f N = (A - B).cross(B - C);
float s = (N(0) * A(0) + N(1) * A(1) + N(2) * A(2)) // (BA X CB) * OA
/ (N(0) * V(0) + N(1) * V(1) + N(2) * V(2)); // (BA X CB) * OV
float min_depth = min(r1, min(r2, r3));
float max_depth = max(r1, max(r2, r3));
if (max_depth - min_depth > 2 || s <= 0.5)
{
continue;
} else if (s - max_depth > 0) {
s = max_depth;
} else if (s - min_depth < 0) {
s = min_depth;
}
// convert feature into cartesian space if depth is available
features_3d_sphere->points[i].x *= s;
features_3d_sphere->points[i].y *= s;
features_3d_sphere->points[i].z *= s;
// the obtained depth here is for unit sphere, VINS estimator needs depth for normalized feature (by value z), (lidar x = camera z)
features_3d_sphere->points[i].intensity = features_3d_sphere->points[i].x; // ???
}
}
// visualize features in cartesian 3d space (including the feature without depth (default 1))
publishCloud(&pub_depth_feature, features_3d_sphere, stamp_cur, "vins_body_ros");
// update depth value for return
for (int i = 0; i < (int)features_3d_sphere->size(); ++i)
{
if (features_3d_sphere->points[i].intensity > 3.0)
depth_of_point.values[i] = features_3d_sphere->points[i].intensity;
}
// visualization project points on image for visualization (it's slow!)
if (pub_depth_image.getNumSubscribers() != 0)
{
vector<cv::Point2f> points_2d;
vector<float> points_distance;
for (int i = 0; i < (int)depth_cloud_local->size(); ++i)
{
// convert points from 3D to 2D
Eigen::Vector3d p_3d(-depth_cloud_local->points[i].y,
-depth_cloud_local->points[i].z,
depth_cloud_local->points[i].x);
Eigen::Vector2d p_2d;
camera_model->spaceToPlane(p_3d, p_2d);
points_2d.push_back(cv::Point2f(p_2d(0), p_2d(1)));
points_distance.push_back(pointDistance(depth_cloud_local->points[i]));
}
cv::Mat showImage, circleImage;
cv::cvtColor(imageCur, showImage, cv::COLOR_GRAY2RGB);
circleImage = showImage.clone();
for (int i = 0; i < (int)points_2d.size(); ++i)
{
float r, g, b;
getColor(points_distance[i], 50.0, r, g, b);
cv::circle(circleImage, points_2d[i], 0, cv::Scalar(r, g, b), 5);
}
cv::addWeighted(showImage, 1.0, circleImage, 0.7, 0, showImage); // blend camera image and circle image
cv_bridge::CvImage bridge;
bridge.image = showImage;
bridge.encoding = "rgb8";
sensor_msgs::Image::Ptr imageShowPointer = bridge.toImageMsg();
imageShowPointer->header.stamp = stamp_cur;
pub_depth_image.publish(imageShowPointer);
}
return depth_of_point;
}



















 777
777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











