




 本文详细介绍了3D Gaussian Splatting技术,它是NeRF领域的突破性工作,能实现高质量的实时渲染。内容涵盖了3D高斯的数学推导、光栅化、Splatting、交叉优化和自适应控制等核心概念,以及其在SLAM和三维重建中的应用。通过对3D高斯的优化和快速可微光栅化,该技术提高了渲染效率,降低了计算成本。
本文详细介绍了3D Gaussian Splatting技术,它是NeRF领域的突破性工作,能实现高质量的实时渲染。内容涵盖了3D高斯的数学推导、光栅化、Splatting、交叉优化和自适应控制等核心概念,以及其在SLAM和三维重建中的应用。通过对3D高斯的优化和快速可微光栅化,该技术提高了渲染效率,降低了计算成本。
【3D-GS】Gaussian Splatting SLAM——基于3D Gaussian Splatting的定SLAM
3D-GS 与 Nerf 和 Gaussian Splatting
3D Gaussian Splatting for Real-Time Radiance Field Rendering
论文:link
code:link
1. 开山之作 Nerf
一切的开始都是起源于 NERF 开山之作 这里由详细的学习与拆解
【NERF】入门学习整理(一)
【NeRF数据集】LLFF格式数据集处理colmap结果记录
基于上面的了解,这个模型的输入:是一个五维的相机位姿(x,y,z,Yaw,Pitch);输出:4D(R G B 不透明度);
那这个模型有啥缺点和优点呢?
逼真的渲染效果: NERF 可以生成逼真的图像和视频,与真实照片和视频难以区分。
灵活性和可扩展性: NERF 可以用于渲染各种形状和大小的 3D 场景,包括室内和室外场景。
易于使用: NERF 只需要少量数据即可训练,并且可以使用标准的硬件进行训练和推理。
缺点包括:
计算成本高: NERF 的训练和推理过程需要大量的计算资源。
数据需求: NERF 需要大量的数据才能训练出高质量的模型。
泛化能力差: NERF 模型通常只适用于训练数据所代表的场景。
以下是 NERF 算法的一些具体应用:
虚拟现实和增强现实: NERF 可以用于创建逼真的虚拟环境和增强现实体验。
3D 建模: NERF 可以用于从照片或视频中生成 3D 模型。
逆向渲染: NERF 可以用于从图像或视频中恢复 3D 场景的几何形状和材质。
以下是 NERF 算法的一些研究方向:
提高计算效率: 研究人员正在开发更有效的 NERF 训练和推理算法。
提高数据效率: 研究人员正在开发能够从少量数据中学习的 NERF 模型。
提高泛化能力: 研究人员正在开发能够泛化到新场景的 NERF 模型。
总体而言,NERF 是一种具有巨大潜力的 3D 表示和渲染技术。随着研究的不断深入,NERF 算法将有望在更多的领域得到应用。
此外,NERF 还存在一些潜在的风险和挑战,包括:
模型偏见: NERF 模型可能会受到训练数据的偏见影响,从而导致生成不准确或偏颇的结果。
滥用风险: NERF 技术可能会被滥用来生成虚假信息或宣传材料。
2. 扛鼎之作 3D Gaussian Splatting
3D Gaussian Splatting是最近NeRF方面的突破性工作,它的特点在于重建质量高的情况下还能接入传统光栅化,优化速度也快(能够在较少的训练时间,实现SOTA级别的NeRF的实时渲染效果,且可以以 1080p 分辨率进行高质量的实时(≥ 30 fps)新视图合成)。开山之作就是论文“3D Gaussian Splatting for Real-Time Radiance Field Rendering”是2023年SIGGRAPH最佳论文。
首先,3DGS可以认为是NeRF的一种,做的任务也是新视图的合成。
对于NeRF而言,它属于隐式几何表达(Implicit Geometry ),这里我们在上面的【NERF】入门学习整理系列已经有了更加完整的百表达和分析;顾名思义,不表达点的具体位置,而表示点与点的关系。通过选取空间坐标作为采样点输入,隐式场景将输出这些点的几何密度是多少,颜色是什么。而所谓的神经隐式几何则是用神经网络转换上述输入输出的方法(输入三维空间坐标和观测视角,输出对应点的几何密度和颜色)。把光线上的一系列采样点加权积起来就渲染得到一个像素颜色,这便是NeRF神经辐射场渲染的流程。
此外,何的隐式表达可以分为体积类表达和表面类表达两种:
体积类表达:NeRF 属于体积类表达,通过几何密度决定采样点颜色的贡献度。
表面类表达:在表面类表达方式中,输入采样点,符号距离函数 SDF 输出空间中距离该点最近的表面的距离,正值表示表面外,负值表示表面内,表面类方法判定越靠近表面的采样点颜色贡献度越高。
既然有隐式,那么就有显式几何表达( Explicit geometry),就是类似点云、三角mesh这类可以沿着存储空间遍历所有元素。(通过某些方式,真正的把物体上的点都表示出来)
对于渲染,NeRF是非常典型的backward mapping过程,即计算出每个像素点受到每个体素影响的方式来生成最终图像,对每个像素,投出一条视线,并累积其颜色和不透明度
而3DGaussian Splatting是forward mapping的过程,将每个体素视作一个模糊的球,投影到屏幕上。在Splatting中,我们计算出每个体素如何影响每个像素点.
2.1 什么是3D高斯?高斯由1D推广到3D的数学推导
对于高常说的高斯函数,其实是1D的高斯,也就是正态分布:
f
(
x
)
=
1
σ
2
π
e
−
(
x
−
μ
)
2
2
σ
2
f(x) = \frac{1}{\sigma \sqrt{2\pi}} e^{-\frac{(x-\mu)^2}{2\sigma^2}}
f(x)=σ2π1e−2σ2(x−μ)2
其中:
μ 是正态分布的 均值,代表数据中心的位置。
σ 是正态分布的 标准差,代表数据离散程度。
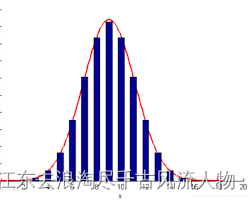
对于一段x区间,进行积分可以得到分布中的数据落在这一-区间的概率,其中绝大多数落在3sigma区域(概率是0.9974)。因此,一组
m
u
mu
mu 和
/
s
i
g
m
a
/sigma
/sigma 可以确定一个1D高斯分布函数,进而确定一条1D线段通过改变这两个值就可以表达1D数轴上的一根线段。类似地,将这个思路从1D拓展到3D,那么就可以确定一个空间的椭球形,这个椭球分别以xyz轴对称,
从对称轴的垂直面切出来的横截面都是椭圆。不过由于这个椭球可以旋转移动,所以它的xyz对称轴不一定和世界坐标系重叠。对于标准的3DGaussians标准形式,是:
G
(
x
)
=
1
2
π
σ
2
exp
[
−
(
x
−
μ
)
2
2
σ
2
]
\begin{equation} G(x) = \frac{1}{\sqrt{2 \pi \sigma^2}} \exp \left[ -\frac{(x - \mu)^2}{2 \sigma^2} \right] \end{equation}
G(x)=2πσ21exp[−2σ2(x−μ)2]
该公式是一维高斯分布的概率密度函数,其中:

和标准形式对比可以看到去掉了指数部分前面的尺度系数(不影响椭球几何):默认模型坐标中心在原点,方便旋转放缩,放入世界空间时再加上平移。那么对于初始化这个高斯椭球,目前就只有协方差矩阵这一个参数了。论文给出了初始化的方法如下表达
高斯3D是指三维高斯分布,其概率密度函数 (PDF) 为:
f
(
x
,
y
,
z
)
=
1
(
2
π
)
3
/
2
σ
3
e
−
(
x
−
μ
x
)
2
+
(
y
−
μ
y
)
2
+
(
z
−
μ
z
)
2
2
σ
2
(
2
)
f(x, y, z) = \frac{1}{(2\pi)^{3/2} \sigma^3} e^{-\frac{(x-\mu_x)^2 + (y-\mu_y)^2 + (z-\mu_z)^2}{2\sigma^2}} (2)
f(x,y,z)=(2π)3/2σ31e−2σ2(x−μx)2+(y−μy)2+(z−μz)2(2)
其中:
μ
x
、
μ
y
、
μ
z
μ_x、μ_y、μ_z
μx、μy、μz 是高斯3D的均值,代表数据中心在三个维度上的位置。
σ 是高斯3D的标准差,代表数据在三个维度上的离散程度。
从高斯1D到高斯3D的过程可以概括为以下几个步骤:
扩展均值: 将高斯1D的均值 μ 扩展为三维向量
μ
=
(
μ
x
,
μ
y
,
μ
z
)
μ = (μ_x, μ_y, μ_z)
μ=(μx,μy,μz)。
扩展方差: 将高斯1D的方差
σ
2
σ^2
σ2 扩展为三维对角矩阵
Σ
=
d
i
a
g
(
σ
2
,
σ
2
,
σ
2
)
Σ = diag(σ^2, σ^2, σ^2)
Σ=diag(σ2,σ2,σ2)。
**使用多维高斯分布公式:**使用多维高斯分布公式计算联合概率密度函数。
以下是详细的数学推导:
- 扩展均值
高斯1D的均值 μ μ μ 代表数据中心的位置。在三维空间中,数据中心的位置可以用三维向量 μ = ( μ x , μ y , μ z ) μ = (μ_x, μ_y, μ_z) μ=(μx,μy,μz) 表示。
- 扩展方差
高斯1D的方差 σ 2 σ^2 σ2 代表数据离散程度。在三维空间中,数据在三个维度上的离散程度可以用三维对角矩阵 Σ = d i a g ( σ 2 , σ 2 , σ 2 ) Σ = diag(σ^2, σ^2, σ^2) Σ=diag(σ2,σ2,σ2) 表示。
- 使用多维高斯分布公式
多维高斯分布的概率密度函数 (PDF) 为:
f
(
x
)
=
1
(
2
π
)
n
/
2
∣
Σ
∣
1
/
2
e
−
(
x
−
μ
)
T
Σ
−
1
(
x
−
μ
)
2
(
3
)
f(x) = \frac{1}{(2\pi)^{n/2} |\Sigma|^{1/2}} e^{-\frac{(x-\mu)^T \Sigma^{-1} (x-\mu)}{2}} (3)
f(x)=(2π)n/2∣Σ∣1/21e−2(x−μ)TΣ−1(x−μ)(3)
其中:
n
n
n 是数据维度。
Σ
Σ
Σ 是协方差矩阵,协方差矩阵则是控制椭球在3轴向的伸缩和旋转(模型空间),其中协方差矩阵的特征向量就是椭球对称轴。
μ
μ
μ 是均值向量,对应的三位空间中即是椭球的中心(控制世界空间位置平移的起点)
将上述公式代入高斯3D的定义,即可得到高斯3D的概率密度函数:
f ( x , y , z ) = 1 ( 2 π ) 3 / 2 σ 3 e − ( x − μ x ) 2 + ( y − μ y ) 2 + ( z − μ z ) 2 2 σ 2 ( 4 ) f(x, y, z) = \frac{1}{(2\pi)^{3/2} \sigma^3} e^{-\frac{(x-\mu_x)^2 + (y-\mu_y)^2 + (z-\mu_z)^2}{2\sigma^2}} (4) f(x,y,z)=(2π)3/2σ31e−2σ2(x−μx)2+(y−μy)2+(z−μz)2(4)
类似地,将这个思路从1D拓展到3D,那么就可以确定一个椭球的图形,这个椭球分别以xyz轴对称,从对称轴的垂直面切出来的横截面都是椭圆(或圆)。不过由于这个椭球可以旋转移动,所以它的xyz对称轴不一定和世界坐标系重叠。对于标准的3D Gaussians标准形式,如公式4所示
但是在实际的论文中,根据实际情况做了模型的简化:论文中的3D Gaussians表达为公式5
f ( x ) = e − ( x ) T Σ − 1 ( x ) 2 ( 5 ) f(x) = e^{-\frac{(x)^T \Sigma^{-1} (x)}{2}} (5) f(x)=e−2(x)TΣ−1(x)(5)
和标准形式对比可以看到去掉了指数部分前面的尺度系数(不影响椭球几何);默认模型坐标中心在原点,方便旋转放缩,放入世界空间时再加上平移。那么对于初始化这个高斯椭球,目前就只有协方差矩阵这一个参数了。论文给出了初始化的方法如下表达
Σ
=
R
S
S
T
R
T
Σ = RSS^TR^T
Σ=RSSTRT
其中的S是放缩变换(沿着坐标轴的3D向量s);R是旋转变换(可以用四元数q来表达)。这是因为椭球是可以通过将圆球按轴向放缩再旋转。而在使用梯度下降对参数进行优化的时候,就是将梯度传递到s和q中进行优化的。
总结:从高斯1D到高斯3D的过程可以概括为扩展均值、扩展方差和使用多维高斯分布公式。该过程将高斯分布从一维扩展到三维,可以用于描述三维空间中的数据分布。
高斯3D的应用示例:3D点云处理: 高斯3D可以用于对3D点云进行滤波和降噪。3D图像重建: 高斯3D可以用于从2D图像中重建3D图像。3D形状识别: 高斯3D可以用于识别3D形状。
高斯3D是三维空间中数据分布的重要描述工具。理解从高斯1D到高斯3D的过程对于理解高斯3D的应用至关重要。
2.2 什么是光栅化?
one word: 光栅化就是把顶点数据转换为片元(片元指的是屏幕上的像素)的过程
光栅化过程中,片元指的是屏幕上的像素。光栅化将3D模型的顶点数据转换为屏幕上的像素,以便在显示器上显示图像。
具体来说,光栅化过程包括以下步骤:
三角形设置: 将3D模型中的所有几何图形分解为三角形。
三角形遍历: 遍历每个三角形。
插值: 计算每个三角形内部每个像素的颜色、深度和其他属性。
填充: 根据计算出的属性,将每个像素填充为相应的颜色。
**在插值步骤中,会使用顶点数据来计算每个像素的属性。**例如,对于颜色,可以使用顶点的颜色值进行线性插值。对于深度,可以使用顶点的深度值进行插值。
这里有一个工程实现就是完整的光栅化的过程与代码实现;见draw_depth_map.rar
因此,片元可以理解为光栅化过程中用于表示屏幕上单个像素**的数据结构。片元数据通常包括以下属性:
**颜色:**像素的颜色值。
**深度:**像素的深度值。
**纹理坐标:**用于纹理映射的纹理坐标。
**其他属性:**其他用于渲染的属性,例如法线、光照等。
**光栅化是3D图形渲染过程中的重要步骤。**它将3D模型的顶点数据转换为屏幕上的像素,以便在显示器上显示图像。
传统光栅化(rasterization)的主要内容之一是将三维三角形映射到投影平面并像素化(将图形或图像的矢量数据转换为像素数据,从而能够在计算机屏幕上显示的过程。通过将图形转换为像素级别,计算机可以更容易地处理和显示图形,同时确保图像在屏幕上以高速率绘制)。光栅化是实现计算机屏幕上图形显示和渲染的关键步骤,能够以非常高的速度生成图像,适用于实时渲染,例如视频游戏和模拟器。
光栅化就是把顶点数据转换为片元(片元指的是屏幕上的像素)的过程。片元中的每一个元素对应于帧缓冲区中的一个像素。光栅化其实是一种将几何图元变为二维图像的过程。该过程包含了两部分的工作。
第一部分工作:决定窗口坐标中的哪些整型栅格区域被基本图元占用;
第二部分工作:分配一个颜色值和一个深度值到各个区域。光栅化过程产生的是片元。
之所以是三角形是因为它在图形学中可以看做是几何体的基本形状。三角形在图形学中有很多很好的性质:
(1)三角形是最基本的多边形,并且任何其他的多边形都可以拆分为三角形。
(2)三个点可以保证他在一个平面如果是四边形四个点就不能保证。
(3)它可以很好地用叉积判断一个点是不是在三角形内部(三角形的内外定义特别清晰)。
2.3 什么是Splatting?
one word: 把椭球(3D高斯获得的表达)投影到投影平面后得到的2D图形称为Splatting
Splatting(抛雪球(splatting):是计算机图形学中用三维点进行渲染的方法,该方法将三维点视作雪球往图像平面上抛,雪球在图像平面上会留下扩散痕迹,这些点的扩散痕迹叠加在一起就构成了最后的图像,是一种针对点云的渲染方法)的方法进行渲染。
对于椭球(就是上面3D高斯获得的表达)的光栅化则需要开发者自己用GPU实现,其中把椭球投影到投影平面后得到的2D图形称为Splatting。Splatting算法与光线投射法不同,是反复对体素的投影叠加效果进行运算。它用一个称为足迹的函数计算每一体素投影的影响范围,用高斯函数定义点或者小区域像素的强度分布,从而计算出其对图像的总体贡献,并加以合成,形成最后的图像。由于这个方法模仿了雪球被抛到墙壁上所留下的一个扩散状痕迹的现象,因而取名为“抛雪球法”。所以,所谓的Splatting就是对高斯( 3D空间椭球)进行光栅化
对于3D高斯的分布函数,在模型空间原点用协方差
Σ
Σ
Σ 矩阵确定了形状与旋转,然后用椭球的中心
u
u
u 确定平移到世界空间。为了渲染到画布上需要先view变换(视角的变换)到相机空间,再project变换(透视投影模型?)将透视空间变得和像素对齐才能进行光栅化,这段完全是一个CG的内容,主要作用就是将透视坐标和投影坐标与模型坐标等体系坐标对齐到当前的相机坐标系。而所谓的栅格化可以理解伟将三维投射到平面并进行像素化。论文把这个过程用下面公式来表达
Σ
′
=
J
W
Σ
W
T
J
T
Σ' = JW Σ W^T J^T
Σ′=JWΣWTJT
其中,
W
W
W代表view变换(主要是旋转和平移,都是仿射变换);
J
J
J代表project变换,对其进行仿射近似,再取雅克比矩阵(Jacobian)。
上面的变换后的分布已经和画布像素对齐,沿着第三维积分则可得到椭球在某一像素上的着色。根据3D高斯的特点,沿着某一轴线积分的结果是一个2D高斯,所以这里可以直接用2D高斯替换积分过程,这里也是为什么这个方法比较快的原因。
2.4 什么是交叉优化?
one word: 在 3D 高斯 splatting 中,交叉优化是指一种用于提高渲染效率的技术。它通过减少 splat 的数量来实现,同时保持图像质量。
交叉优化的基本思想是将多个 splat 合并为一个更大的 splat。这可以通过以下两种方式实现:
空间合并: 将空间上相邻的 splat 合并为一个更大的 splat。
属性合并: 将具有相同属性的 splat 合并为一个更大的 splat。
空间合并可以减少 splat 的数量,同时保持图像质量。这是因为相邻的 splat 通常具有相似的颜色和深度值。
属性合并可以进一步减少 splat 的数量。这是因为具有相同属性的 splat 可以使用相同的渲染设置进行渲染。
**交叉优化可以显著提高 3D 高斯 splatting 的渲染效率。**它可以减少 splat 的数量,从而减少渲染所需的 GPU 内存和计算资源。
论文的核心是对 3D Gaussian 的优化,优化的目的是创建一组密集的 3D Gaussian 以精确地表示场景。优化的参数包括:三维位置 p、透明度 α 各向异性协方差 Σ 和球谐系数 SH (spherical harmonic coefficients) 。这些 ⌈参数的优化⌋ 和 ⌈自适应控制高斯模型⌋ 交替进行。
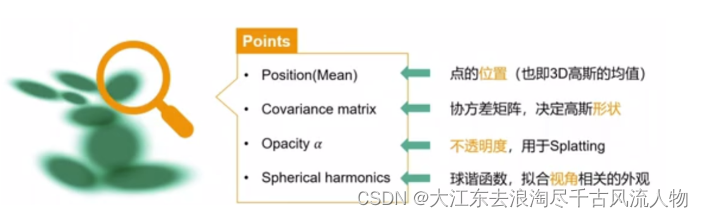
注意:图中的球谐系数 SH (spherical harmonic coefficients) 来表示每个高斯的颜色 ,不同视角颜色不同。
参数优化使用 SGD 连续迭代完成,每一轮迭代时都会渲染图像并将其与真实的训练视图做比较。α使用 Sigmoid 激活函数来限制 (0, 1) 的范围;Σ使用指数激活函数激活;p使用指数衰减调度技术 (exponential decay scheduling technique) 进行优化。模型的损失函数是 L1 与 D-SSIM 项的组合:
L
=
(
1
−
λ
)
L
1
+
λ
L
D
−
S
S
I
M
L = (1 - \lambda)L_1 + \lambda L_{D-SSIM}
L=(1−λ)L1+λLD−SSIM
2.5 什么是自适应控制?
在 3D 高斯 splatting 中, 自适应控制是指一种用于控制 splat 大小和位置的技术。它通过根据场景的复杂度调整 splat 的大小和位置来实现,以便在保持图像质量的同时提高渲染效率 。
自适应控制的基本思想是在场景复杂区域使用较小的 splat,在场景简单区域使用较大的 splat。这是因为复杂区域需要更多的 splat 来保持图像质量,而简单区域可以使用较少的 splat 来获得相同的图像质量。
在 3D Gaussian Splatting 中,场景表示是通过多个高斯模型叠加而成的。在早期迭代次数较少时,会出现重建不足 (under-reconstruction) 的问题,即高斯模型没有完全覆盖小规模的几何体,此时需要复制高斯模型进行覆盖;在后期迭代次数较多时,会出现重建过度 (over-reconstruction) 的问题,即高斯模型超出小规模几何体的范围,此时需要将该高斯模型一分为二。这就是自适应控制 Gaussians:
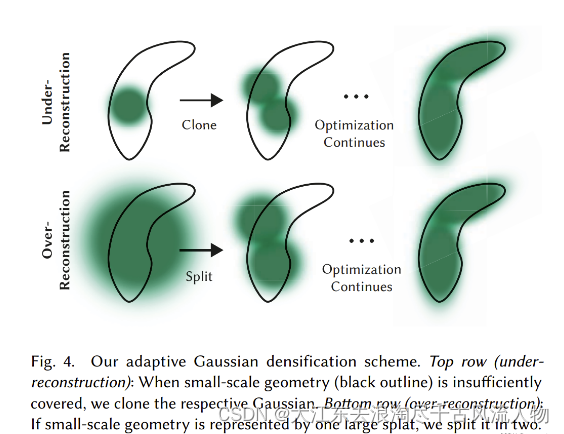
从初始化 Gaussians 为稀疏的 SfM 点云开始,通过自适应地控制高斯模型的数量和它们在单位体积上的密度,逐渐从稀疏的高斯模型集合过渡到更密集且能够更好地表示场景的集合。该过程主要关注 under-reconstruction 和 over-reconstruction 的区域,即具有较大的视图空间位置梯度的区域。直观理解来看,是因为这些区域尚未完全重建好,因此优化算法试图移动高斯函数以进行修正。under-reconstruction 和 over-reconstruction 的区别是 over-reconstruction 区域的 Gaussian 方差大,因为数据的变化幅度较大。对于视图空间的位置梯度大于阈值 𝜏pos 的区域,需要对该高斯模型进行稠密化 (densify) 操作:
under-reconstruction 区域:高斯模型没有完全覆盖小规模的几何体,此时需要复制高斯模型并将其沿位置梯度方向移动,以覆盖几何体。
over-reconstruction 区域:高斯模型超出小规模几何体的范围,此时需要将该拆分高斯模型只覆盖几何体。
自适应控制可以通过以下几种方式实现:
**基于距离:**根据 splat 与视点的距离来调整 splat 的大小。距离视点较近的 splat 使用较小的尺寸,距离视点较远的 splat 使用较大的尺寸。
**基于曲率:**根据场景曲率来调整 splat 的大小。曲率较大的区域使用较小的 splat,曲率较小的区域使用较大的 splat。
**基于纹理:**根据纹理细节来调整 splat 的大小。纹理细节较多的区域使用较小的 splat,纹理细节较少的区域使用较大的 splat。
**自适应控制可以显著提高 3D 高斯 splatting 的渲染效率。**它可以通过减少 splat 的数量来减少渲染所需的 GPU 内存和计算资源。
2.6 什么是快速可微光栅化?
在 3D 高斯 splatting 中,快速可微光栅化是指一种用于提高渲染效率的技术。它通过减少光栅化过程所需的时间和计算资源来实现,同时保持图像质量。
快速可微光栅化的基本思想是使用预计算的 splat 梯度来代替传统的逐像素插值(为啥可以快呢?答案就在这里)。这可以显著减少光栅化过程所需的时间和计算资源。
Gaussians 快速可微光栅化是为了快速实现整体渲染和排序,从而实现近似 α-混合(Alpha Blending)并且不再限制能够接收梯度的 splats 的数量。为了达到目的,对 Gaussian splats 进行分块 (tile) 处理,将该光栅化过程命名为 基于分块的光栅化 (tile-based rasterization)。
- 首先将 2D 屏幕分割成 16×16 个 tile,然后为每个 tile 筛选视锥体 (view frustum) 内的 3D Gaussian:每个视锥体内只保留置信度大于 99% 的高斯模型;设置一个保护带 (guard band) 剔除位于极端位置的高斯模型,如均值接近近平面或在视锥体之外;
- 根据每个 Gaussian 重叠的 tile 数量来实例化,为其分配 key 值(key 值结合了该 Gaussian 所在 tile 的 ID 和对应视域的深度);
- 使用 GPU Radix sort 根据 key 值对 Gaussians 进行排序(其实就是按高斯模型到图像平面的深度值);
- 将排好序的 Gaussians 从近到远向对应 tile 上做 Splatting。然后在每个 tile 上对高斯模型留下的 splat 做堆叠(类似 α-blending,累积 α 和 c),直到所有像素的不透明度都饱和(α=1);
优化参数时,按每个 tile 堆叠的 splat 对应的 Gaussians 的顺序反向传播;
系统的框图如下所示:系统首先对SfM产生的稀疏点云进行初始化,创建3D高斯模型,然后借助相机外参(就是pose了)将点投影到图像平面上(即Splatting),接着用可微光栅化,渲染得到图像。得到渲染图像Image后,将其与Ground Truth图像比较求loss,并沿蓝色箭头反向传播。蓝色箭头向上,更新3D高斯中的参数,向下送入自适应密度控制中,更新点云。这套流程下来感觉有点东西哈哈哈
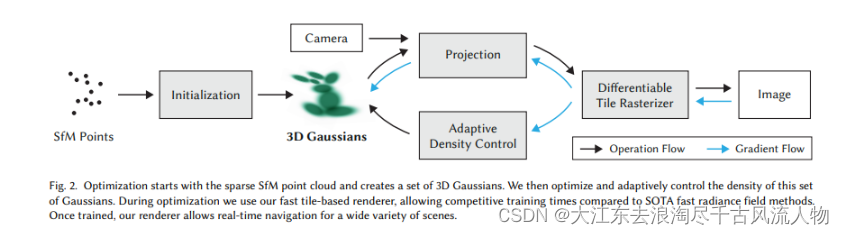
具体而言,即从已有点云模型出发,以每个点为中心,建立可学习的3D高斯表达,用Splatting的方法进行渲染,实现了高分辨率的实时渲染,其中包含三个关键步骤:
3D高斯场景表示:从相机校准过程中产生的稀疏点开始(初始化为sfm产生的稀疏点云),用3D高斯表示场景,3D高斯保留连续体积辐射场的理想属性以进行场景优化,同时避免了在空白空间中进行不必要的计算。
交错优化和密度控制:对3D高斯各种属性(如位置、不透明度、各向异性协方差和球面谐波系数)进行了交错优化/密度控制,特别优化了各向异性协方差(anisotropic covariance,指的是从各个方向上看过去,物体的外观表现都不同)以实现场景的准确表示。
快速可见性感知渲染算法:开发了一种快速可见性感知渲染算法(fast visibility-aware rendering algorithm),该算法支持各向异性抛雪球(anisotropic splatting),既能加速训练,又能保持高质量进行实时渲染。
小结:快速可微光栅化可以通过以下几种方式实现:
**预计算 splat 梯度:**在渲染之前,预计算所有 splat 的梯度。
**使用 splat 梯度进行插值:**在光栅化过程中,使用预计算的 splat 梯度来代替逐像素插值。
**快速可微光栅化可以显著提高 3D 高斯 splatting 的渲染效率。**它可以通过减少光栅化过程所需的时间和计算资源来实现。
快速可微光栅化的研究论文:
Fast Differentiable Rasterization for Splatting: https://arxiv.org/abs/2203.08337
Differentiable Splatting with Implicit Gradients: https://arxiv.org/abs/2008.06449
Mip-Mapped Gaussian Splats with Differentiable Rendering: https://arxiv.org/abs/1904.06286
2.8 什么是 α-混合(Alpha Blending)?
α-混合,也称为α合成,是计算机图形学中用于将多个图像或对象与不同透明度级别组合成单个最终图像的技术。它本质上控制了一张图像透过另一张图像的程度,在它们之间创建平滑过渡
工作原理:
带α通道的图像: 参与混合过程的每个图像通常有一个额外的通道,称为α通道(由符号α表示)。该通道为每个像素存储 0.0 到 1.0 之间的数值,其中:
0.0(完全透明): 像素完全不可见,允许底层图像完全显示。
1.0(完全不透明): 像素完全是实心的,完全阻塞了底层图像。
0.0 和 1.0 之间的数值(部分透明): 像素具有不同程度的透明度,允许底层图像部分显示。
混合公式: 使用数学公式根据两个图像的对应α值组合它们的颜色。常见公式为:
最终颜色 = (源颜色 * 源α) + (目标颜色 * (1 - 源α))
其中,
源颜色: 正在顶部混合的图像颜色(前景)
源α: 源图像中对应像素的α值
目标颜色: 正在底层混合的图像颜色(背景)
透明效果: 通过调整所涉及图像的α值,您可以实现各种透明效果,例如:
完全透明的物体允许背景显示。
淡入淡出物体。
具有混合外观的重叠半透明物体。
α-混合的应用:
创建逼真的玻璃、水、烟雾和其他半透明物体。
将文本、UI元素和其他2D图形叠加在3D场景之上。
组合多个纹理和效果层以创建复杂的视觉效果。
α-混合是计算机图形学中的一项基本技术,能够创建视觉丰富和分层的场景。
一些额外的细节:
α-混合通常与其他技术结合使用,例如深度排序和抗锯齿,以获得最佳效果。
不同的渲染API(例如OpenGL和DirectX)提供了不同的α-混合模式,允许您控制混合行为的细微差别。
除了颜色之外,α-混合也可以用于混合其他属性,例如深度和法线。



















 250
250

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











