



总部位于巴黎的 Mistral AI 宣布推出其最新一代 开源权重模型家族,包括 Mistral Large 3 以及另外三款小型、稠密模型。所有模型均采用 Apache 2.0 许可证 发布,这意味着它们可以自由用于商业用途、自行托管以及微调。
Mistral 可以说是欧洲“小而精”的开源典范。其首款模型 Mistral 7B 以仅 70 亿参数即展现出媲美更大模型的推理能力;后续推出的稀疏混合专家模型 Mixtral 8×7B(约 12B 激活参数),在保持高效推理的同时显著提升性能,逼近 GPT-3.5 水平。尤为可贵的是,Mistral 坚持高质量开源路线,多次以 Apache 2.0 或 MIT 等宽松许可发布核心模型,极大推动了研究与工业落地。在主流大厂普遍闭源的背景下,Mistral 不仅代表了欧洲 AI 的创新高度,更成为社区对“高性能仍可开放共享”这一理念的关键寄托——正因如此,每当其新模型发布,业界无不密切关注。
本教程将介绍 Mistral 3 系列模型,并与现有开源大语言模型进行对比,概述各模型的潜在应用场景,说明硬件需求,并展示一个实际部署示例。
简要介绍 Mistral 模型
Mistral Large 3(675B)
该系列中规模最大、能力最强的模型是 Mistral Large 3 675B。该模型使用 3,000 张 NVIDIA H200 GPU 进行训练,采用 稀疏型专家混合(Mixture of Experts,MoE)架构,在总计 675B 参数中,每次仅激活 410 亿(41B)参数,其中包括一个 25 亿参数的视觉编码器。
在主流大语言模型基准测试中,其整体表现与 DeepSeek 3.1 670B 和 Kim-K2 1.2T 处于同一水平。该模型具备 图像分析能力,支持 256k 超长上下文窗口,并原生支持 函数调用(Function Calling) 与 JSON 格式输出。
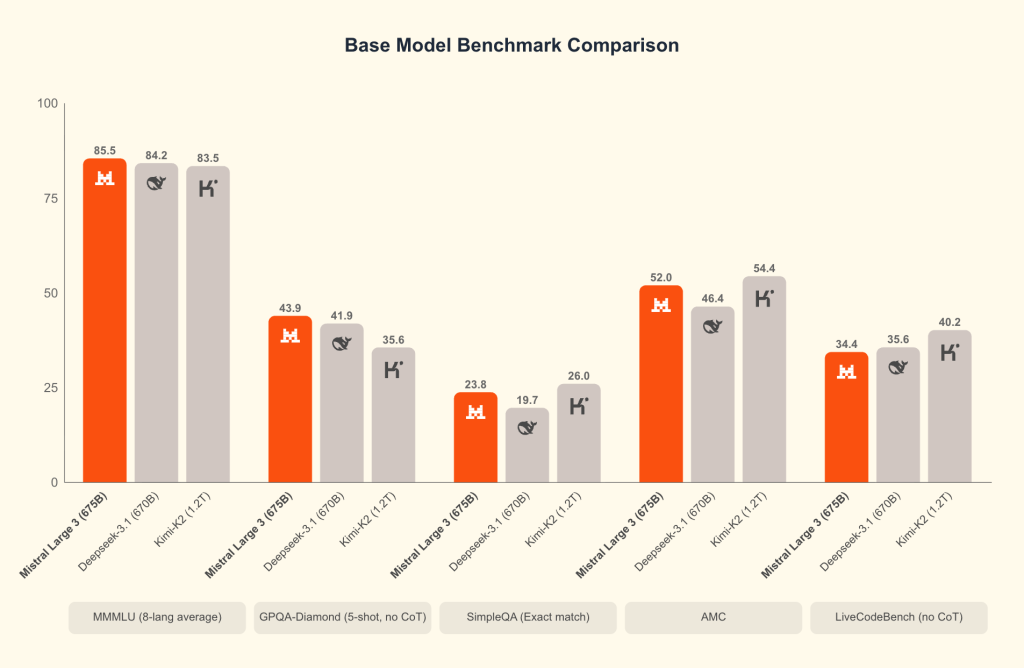
Mistral 官方推荐的适用场景包括:
- 长文档理解
- 高性能通用 AI 助手
- 带工具调用的 Agent 应用
- 企业级知识工作
- 通用代码辅助
它并不是一款专门的推理模型,也未针对视觉任务进行优化,因此在需要复杂推理,或对视觉能力要求较高的多模态应用场景中,可能并非最佳选择。此外,该模型体量较大,要想在规模化场景下实现高效部署,需要具备充足的硬件资源。
Mistral 另外发布的三款模型是被称为 “Mini-stral” 的小型语言模型,参数规模分别为 14B、8B 和 3B。这三款小模型同样具备视觉能力并支持 256k 上下文窗口,但在设计上更侧重于适配更广泛的硬件环境,包括笔记本电脑和边缘设备。每个小模型都提供了 Base、Instruct 和 Reasoning 三种版本,分别用于微调、推理服务以及以准确性为导向的应用场景。
在实际表现上,Mistral AI 的小模型非常擅长减少回复中不必要的输出 token 数量,这使用户能够在更低成本下获得更多有效输出。与其他开源权重模型相比,这三款小模型在性价比(性能/成本比)方面表现尤为出色。
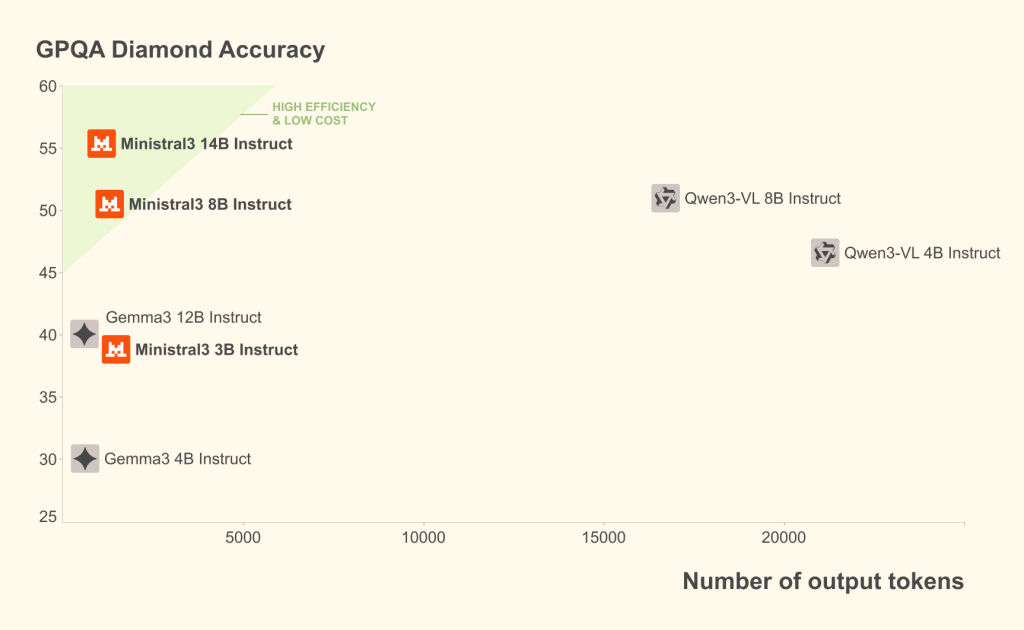
由于体量较小,这些 Ministral 模型非常适合用于离线推理能力优先或成本优先于精度与性能的系统架构中。同时,它们也适用于并行架构场景,通过多个小模型协同工作来完成更复杂、更大规模的任务。
部署示例(Deployment Example)
Mistral 建议将 Large 3 模型以 FP8(8 位浮点**)精度** 部署在由 H200 GPU 组成的节点上,或以 NVFP4 精度 部署在 A100 GPU 节点上。同时,他们推荐 3B、8B 和 14B 三款模型分别至少配备 8 GB**、12 GB 和 24 GB 的显存(VRAM,视频随机存取存储器)** 进行部署。
| 模型 | 精度 | 系统需求 |
|---|---|---|
| Large 3 (675B) | FP8 | 8 × H200 |
| Large 3 (675B) | NVFP4 | 8 × H100 |
| Ministral 3 14B | FP8 | 24 GB VRAM |
| Ministral 3 8B | FP8 | 12 GB VRAM |
| Ministral 3 3B | FP8 | 8 GB VRAM |
以下示例将演示如何在 NVIDIA GPU 上部署 Ministral 3 3B。
第一步:创建 GPU Droplet
首先,登录你的 DigitalOcean 账号并创建一个 GPU Droplet 服务器。如果还没有 DigitalOcean 云平台的账号,可以在 digitalocean.com 快速注册一个,只需要填写验证邮箱,绑定支付宝或信用卡即可使用。
之所以选择使用 DigitalOcean 的 GPU 服务器,是因为它相对于 AWS、GCP 等一线云平台的综合成本要便宜,而且支持从 H200 到 L40S 等不同性能的十余款 GPU,而且 DigitalOcean 的 GPU 型号比其它二线云平台都要丰富,并且易于使用。
在登录账号之后,进入后台,在镜像中选用 AI/ML-Ready(系统自动完成 AI 所需的软件配置),然后选择任意可用的 NVIDIA GPU。由于 Ministral 3 3B 可以运行在 NVIDIA RTX 4000 Ada 上,这里我们选择该配置。接着添加或选择一个 SSH Key,并创建 DigitalOcean Droplet 服务器。
第二步:连接 GPU Droplet
在 Droplet 创建完成后,通过 SSH 连接实例:
ssh root@your_server_ip
首次连接可能会提示:
The authenticity of host 'your_server_ip (...)' can't be established...
Are you sure you want to continue connecting (yes/no/[fingerprint])?
输入 yes 并回车即可。
第三步:安装 Python 与 vLLM
确保已进入 Linux 实例,然后安装 Python:
sudo apt install python3 python3-pip
若提示是否继续,输入 Y 并回车即可。 若出现“Daemons using outdated libraries”提示,可直接回车。
接着安装 vLLM:
pip install vllm
安装完成后即可开始部署模型。
第四步:启动 Mistral 模型服务
使用 Hugging Face 上的模型 ID,并设置必要参数(尤其是 max-model-len,以适配小显存 GPU):
vllm serve mistralai/Ministral-3-8B-Instruct-2512 \
--tokenizer_mode mistral \
--config_format mistral \
--load_format mistral \
--max-model-len 4096 \
--host 0.0.0.0 --port 8000
tokenizer_mode、config_format 和 load_format 这几个参数用于确保 Mistral 模型能够被正确加载。
当模型通过 vLLM 在你的实例上成功加载并对外提供服务后,你就可以在本地或从其他服务器使用 Python 向该端点发起推理请求。下面的示例展示了如何向模型发送请求。
模型启动后,可通过 Python 发送请求:
import requests
url = "http://your_server_ip:8000/v1/completions"
data = {
"model": "mistralai/Ministral-3-8B-Instruct-2512",
"prompt": "Suggest a short and easy recipe using potatoes and cheese.",
"max_tokens": 1000
}
response = requests.post(url, json=data)
response_message = response.json()['choices'][0]['text']
print(response_message)
稍候片刻你就会得到类似的输出:
Output
Here's a **easy and tasty 5-ingredient recipe** you can try:
### **Loaded Baked Potato Bar Muffins**
#### **Ingredients:**
- 4 large potatoes
- 2 cups shredded cheddar or mozzarella cheese
- 1 cup hot sauce (or sriracha for extra kick)
- ½ cup Greek yogurt or sour cream (optional for creaminess)
- 1 egg (optional, for binding)
- Toppings: Butter, garlic powder, bacon bits, scallions, etc.
#### **Directions:**
1. **Prep Potatoes**: Boil whole potatoes until fork-tender (~15 mins). Drain, halve lengthwise, and scoop flesh into a bowl.
2. **Mix Filling**: Cut potatoes and place in a bowl with cheese, hot sauce, yogurt, and egg (if using). Mash lightly until semi-blended but still chunky.
3. **Load Toppings**: Lightly butter an oven-safe muffin tin or use silicone molds. Drop spoonfuls of mix into each well, layering cheese on top.
4. **Bake**: Set oven to **375°F (190°C)** and bake **25–30 mins** until golden and bubbly (check with a toothpick).
5. **Serve Warm**: Top with extra cheese, butter, and hot sauce if desired! Perfect with a side salad or as a meal prep favorite.
---
**Bonus Tip:** Use starchy potatoes (Russet or Yukon Gold) for fluffier texture. For extra flavor, swap hot sauce for green onions, horseradish, or bacon bits. Enjoy!
常见问题(FAQ)
Q:3B 参数模型是否有实际用途? A:可以胜任基础任务,如食谱、常识问答、小学水平知识。但在格式一致性、指令遵循和确定性事实检索方面存在明显限制。
Q:Mistral 3 是否可用于商业用途? A:可以。所有 Mistral 3 模型均采用 Apache 2.0 许可证,允许商业使用、自托管和微调。
Q:14B / 8B 需要什么 GPU**?** A:取决于上下文长度与精度设置。建议至少满足最低 VRAM 要求并进行测试。部分小模型甚至可在 MacBook 上运行。
Q:是否适合视觉任务? A:具备基础视觉能力,但主要优化方向是文本分析,不适合重度视觉应用。
Q:如何选择 3B / 8B / 14B? A:取决于应用需求与可用 GPU。建议从小模型开始测试,逐步升级。
Q:是否适合推理任务? A:Large 3 不是专用推理模型,但 Ministral 提供专门的 Reasoning 版本。
写在最后
Mistral 3 模型家族为注重 数据隐私、可控性与成本效率 的应用提供了一套极具竞争力的开源方案。在保持高质量文本能力的同时,也引入了基础视觉支持。小模型可运行在多种硬件环境中,包括中低端 NVIDIA GPU。
下一步,你可以基于已部署的模型,以低成本方式开展推理任务,并完全掌控提示词和数据。若用于生产环境,请遵循安全最佳实践,例如创建非 root 用户、调整端口以避免公网暴露。
如果你还希望了解包括 RTX 4000 Ada,甚至即将上线的 NVIDIA B300 GPU 服务器的相关信息,或者希望预约测试更多不同 GPU 型号的按需实例,可直接联系 DigitalOcean 中国区独家战略合作伙伴卓普云 AI Droplet。


















 1447
1447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









