



在出海创业浪潮中,越来越多中国企业正在积极部署 AI 能力,从跨境电商推荐算法,到 AIGC 内容生成工具,再到面向全球用户的 LLM API 接口服务——GPU 云服务已经成为出海企业的基础设施刚需。
但随之而来的,是一个绕不开的问题:海外 GPU 云平台怎么选?
我们之前围绕“裸金属GPU服务器”,对比了 AWS、谷歌云、DigitalOcean、腾讯云、阿里云、华为云和Vast.ai几个比较知名的云平台。
本文将聚焦AI创业者群体中热门的两大GPU云服务平台——DigitalOcean和RunPod,深入对比它们在AI部署方面的表现。DigitalOcean代表了“通用云服务商的GPU解决方案”,而RunPod则侧重于“专注AI的弹性算力平台” ()。通过本文,我们将帮助你理解两者差异,为你的AI部署云平台选择提供决策依据。
一、产品定位与核心差异:RunPod与DigitalOcean的根本区别
在选择GPU云平台时,首先要明确其产品定位与核心运营模式,这将直接影响资源稳定性、性能表现及适用场景。
RunPod:弹性算力聚合平台,成本敏感者的选择
RunPod 它包含两种基础设施:社区云(Community Cloud)和安全云(Secure Cloud)。值得注意的是,RunPod 的“社区云”并非其自营数据中心,它主要依赖全球各地个人或第三方数据中心提供的闲置 GPU 资源。RunPod 在此扮演的是一个聚合和管理平台的角色。因此,社区云的价格便宜,但由于依赖闲置资源,价格和可用性都可能不稳定。
安全云也并非RunPod自己拥有和运营的数据中心。它更像是一个“平台即服务”(PaaS)或“基础设施聚合器”(Infrastructure Aggregator),通过聚合和包装其他供应商的底层计算资源来提供服务。这意味着RunPod的数据中心并非全部自主运营,其GPU服务器节点主要集中在美国西部、东部地区及欧洲。这种模式下,虽然资源调度灵活,但算力分布依赖第三方,可能会带来性能波动性。此外,RunPod的存储、网络等服务也可能依赖第三方供应商,导致速度和稳定性因供应而异。可以说RunPod唯一优点就是GPU资源比较便宜。RunPod模式更适合对成本敏感、能容忍一定资源不稳定性和性能波动、且对GPU架构有精细调优需求的个人用户或AI团队。
DigitalOcean:自营数据中心,企业级稳定运营首选
DigitalOcean则是一家拥有遍布全球的自营云数据中心的通用云服务商,其节点覆盖美国、新加坡、德国、英国、加拿大、印度等十余个地区 。DigitalOcean具备完善的虚拟机网络、对象存储、负载均衡、VPC等通用云平台服务。其
DigitalOcean GPU 服务器节点主要部署在美国和欧洲,以低延迟、性能稳定著称。
DigitalOcean的GPU资源均由平台自主提供,具备更高的可预测性和稳定性,特别适合企业级运营对资源锁定和独占的需求。例如,DigitalOcean提供的裸金属(Bare Metal)实例,具备独立显卡直通、CPU+内存资源独占、无虚拟化开销等优势。所有 GPU 服务器机型的配置在DigitalOcean官网都有明确说明,信息透明。DigitalOcean更适合对模型性能稳定性与SLA(服务水平协议)要求较高,或需要中文服务、本地结算与云主机配套资源支持的中国出海企业 。
二、GPU 型号丰富程度:谁更能满足AI多样化需求?
对于 AI 训练与推理任务而言,GPU 型号的选择至关重要。不同的显卡,其架构代际、显存大小、带宽与吞吐量差异,直接影响 LLM、Diffusion 或 RAG 系统的性能表现。
RunPod:型号选择多样,但需甄别资源来源
RunPod 平台上的 GPU 型号丰富,大约有 16 种 GPU 型号(2025年7月的官网数据),涵盖从消费级的 RTX 4090 到企业级的 A100、H100、L4,以及消费级的 4090。
然而,其“社区云”模式依赖全球各地个人或第三方数据中心闲置GPU资源,价格虽可能更低,但资源的稳定性和独占性可能存在不确定性,需要用户自行甄别。
DigitalOcean:主流型号聚焦,性能与性价比兼顾
DigitalOcean 当前主要提供 H200、H00、L40S、A100 和 MI300X 、MI325X 等 22 种 GPU 型号(2025 年 7 月的官网数据),覆盖范围相对聚焦但兼顾性能与性价比。其中 H200、 H100 等型号还提供裸金属服务器。Digitalocean 在 2024 年上线了 MI300X 裸金属实例,并在 2025 年 7 月上线了 MI325X 按需实例,为希望摆脱 NVIDIA 依赖、尝试 AMD 路线的企业提供了高性价比选择。
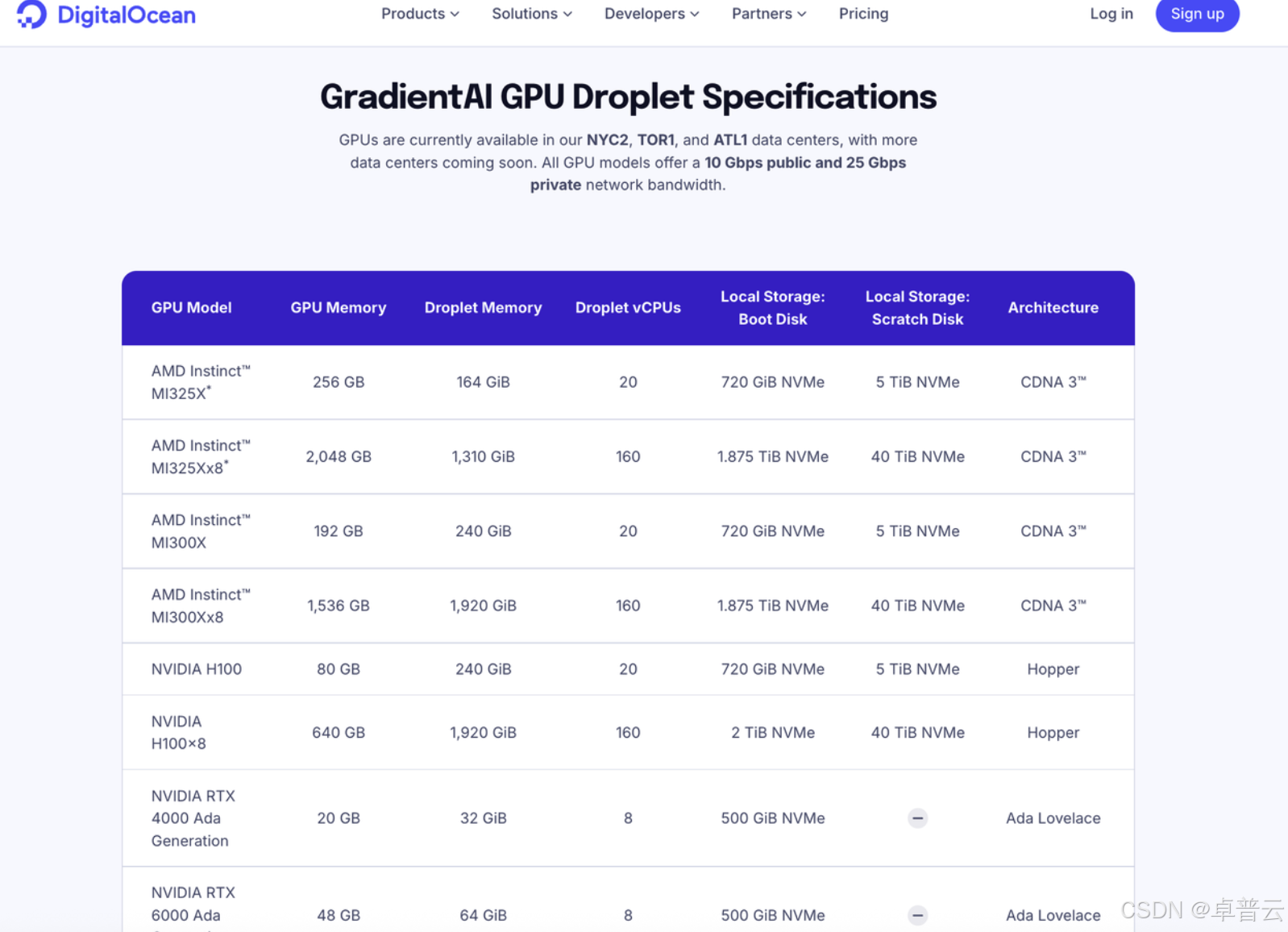
总结:按照 GPU 型号丰富程度来看,DigitalOcean 在目前所有云平台中处于第一梯队,甚至不逊于 AWS、谷歌云服务等老牌厂商。对于追求极致GPU型号自由度、对架构精细调优的AI团队或个人,RunPod提供更多消费级选择。但若你更侧重主流高性能GPU、关注长期稳定性和GPU服务器性价比,DigitalOcean无疑是更稳健的选择。DigitalOcean 更聚焦高性价比主流型号,有最前沿的 H200、MI325X ,也有 L40S、RTX 4000 Ada 这类适合推理任务的高性价比 GPU,适合大规模模型部署、中小量级的大语言模型部署或 AI 推理任务等。
三、数据中心节点范围:全球覆盖与访问优化谁更胜一筹?
出海企业往往需兼顾全球访问速度与部署合规性,尤其在东南亚、中东、欧美等主要业务区域,云服务节点分布显得尤为关键。不过由于目前美国对 GPU 的管控,使得绝大多数云平台的 GPU 服务器节点都集中在欧洲和美国地区。
DigitalOcean:原生全球云平台,一站式GPU服务更完善
DigitalOcean 拥有遍布全球的云数据中心,包括美国、新加坡、德国、英国、加拿大、印度等十余个地区,具备完善的虚拟机网络、对象存储、负载均衡、VPC 等通用云平台服务。DigitalOcean 的 GPU 服务器节点主要部署在美国和欧洲,虽然数量不多,但延时低、性能稳定。
RunPod:节点覆盖弹性强,但资源依赖第三方
RunPod 在文档中写明了在全有17个数据中心。RunPod 没有像 DigitalOcean 那样大规模自建和运营其所有计算基础设施(数据中心)。RunPod 有两种基础设施,一种叫社区云(Community Cloud),另一种叫安全云(Secure Cloud)。社区云不是 RunPod 自己的数据中心。它依赖的是全球各地个人或第三方数据中心提供的闲置 GPU 资源。RunPod 在这里扮演的是一个聚合和管理平台的角色。所以社区的价格更加便宜,但由于是闲置 GPU 资源,所以价格不稳定。安全云也不是 RunPod 自己拥有和运营的数据中心。它更像是一个“平台即服务”(PaaS)或“基础设施聚合器”(Infrastructure Aggregator),通过聚合和包装其他供应商(包括个人和专业数据中心)的底层计算资源来提供服务。RunPod 的 GPU 服务器节点主要集中在美国西部、东部地区,欧洲。在“社区提供”节点下,算力分布依赖第三方,性能波动性较大。
总结:DigitalOcean 具备更广泛的区域覆盖和平台化支持,适合全球部署与持续运维;RunPod 节点选择灵活,但可能需用户自行甄别节点稳定性。DigitalOcean 的存储、网络等服务均是平台自主提供的,性能和速度都很稳定,而RunPod则会依赖一些第三方供应商,所以速度和稳定性都因供应而异,这一点 RunPod 在其文档中也有明确说明。
四、GPU 服务器配置:裸金属能力
DigitalOcean:支持标准化裸金属 GPU 主机
DigitalOcean 裸金属(Bare Metal)实例,具备独立显卡直通、CPU + 内存资源独占、无虚拟化开销等优势。典型如 MI300X 实例(2,048 GiB 高带宽内存、192GB GPU 显存、61.44 TiB NVMe 存储),裸机 GPU 已在美国纽约和荷兰阿姆斯特丹推出,更多数据中心即将推出。除了 MI300X 裸金属服务器,DigitalOcean 还提供 H200、H100 GPU 裸金属服务器。所有裸金属机型的配置,在DigitalOcean官网都有明示,你可以自行查询,或直接咨询DigitalOcean中国区独家战略合作伙伴卓普云。
RunPod:支持裸金属机型
根据 RunPod 在 2025 年发布的博客显示,RunPod 可提供裸金属 GPU 主机,但是并未在博文或后台或其官网说明支持什么型号的GPU。其裸金属 GPU 主机的具体配置也是未知数。这种信息的不透明性,可能为需要精确配置的AI团队带来不便。
总结:如果你希望在裸金属环境中长期稳定运行大模型推理服务,DigitalOcean因其明确的裸金属机型配置和透明度,是比RunPod更适合的选择。
五、GPU 服务器:易用性对比
DigitalOcean:简单易用,功能服务丰富
DigitalOcean GPU Droplet 服务器的配置过程简单,用户可通过浏览器登录后台,简单点击用户界面即可完成配置,也可以通过命令行远程配置开启新的 GPU Droplet。
在配置 GPU Droplet 时,DigitalOcean 提供了 ML-in-a-Box功能,它提供了一个预装数据科学堆栈的即用型环境,让用户能够快速启动和运行机器学习项目,而无需手动配置复杂的软件和驱动。同时,DigitalOcean 与 HuggingFace 合作提供“一键模型部署(1-Click Model)”功能,可让用户在配置 GPU Droplet 时,快速部署最新版本的 LLama、DeepSeek、Gemma等开源大模型。
对于需要管理复杂、可扩展机器学习工作流的用户,DigitalOcean GPU Droplet 能够与 DigitalOcean Kubernetes (DOKS) 服务无缝集成。这意味着用户可以将 GPU Droplet 作为集群节点加入到 Kubernetes 环境中,利用 Kubernetes 强大的容器编排能力,轻松部署、扩展和管理基于 GPU 的机器学习应用。
RunPod:开启服务器流程简单
RunPod 提供了极具弹性的 GPU 云服务,其配置过程同样注重效率和自定义能力。在配置 GPU 实例时,RunPod 提供了一系列预构建的模板(Templates)。这些模板是预装了深度学习框架(如 PyTorch、TensorFlow)、驱动和 CUDA 环境的 Docker 镜像,用户可以直接选择使用,省去了繁琐的环境配置步骤,实现即时启动和运行机器学习项目。
总结:不论你是刚接触 AI与基础设施的初学者,还是资深的工程师,或更看重整体云平台的易用性和集成度,DigitalOcean 都是比 RunPod 更理想的选择 。DigitalOcean 的“ML-in-a-Box”和“1-Click模型部署”功能能帮助你快速上手,成熟的存储和Kubernetes服务则为未来扩展提供便利。DigitalOcean更像一个“全能型”云服务商。
六、价格与性价比:透明计费 vs 灵活按需
在定价方面,两个平台存在较多区别。
DigitalOcean GPU 服务器价格都是由 DigitalOcean 官方统一定价的。由于 DigitalOcean 本身有云主机业务,资金流稳定,所以 GPU 的价格稳定。而且在遇到“黑色星期五”,或有新 GPU 型号上线时,相对较旧型号的 GPU 会出现降价、优惠。DigitalOcean GPU Droplet 在套餐中会提供一定额度的免费出站带宽,如果超出该额度,区域内的数据传输不计算费用,跨区域的出站流量统一按照0.01美元/GB计算。
RunPod 提供了两种价格,一种是社区云价格(Community Cloud),另一种是安全云价格(Secure Cloud)。社区云依赖的是全球各地个人或第三方数据中心提供的闲置 GPU 资源。RunPod 在这里扮演的是一个聚合和管理平台的角色。所以社区的价格更加便宜,但由于是闲置 GPU 资源,所以价格不稳定。安全云也不是 RunPod 自己拥有和运营的数据中心,但价格相对于 RunPod 社区云来说会更稳定,GPU 价格也会稍高一些。
我们以 H100 为例,对比一下两个平台的价格和配置。
DigitalOcean H100 GPU Droplets 配置与价格
DigitalOcean 提供了单卡和8卡H100 服务器,有按需实例、预留实例和裸金属服务器三种类型。在这里我们仅对比按需实例与预留实例的价格。
DigitalOcean 1x NVIDIA H100 SXM 按需实例:
-
GPU: 1 x NVIDIA H100
-
GPU 显存: 80 GB HBM3
-
vCPU: 20 核
-
内存 (RAM): 240 GB
-
引导盘 (Boot Disk):720 GiB NVMe
-
暂存盘 (Scratch Disk): 5 TiB NVMe
-
数据传输 (Transfer): 15,000 GiB
-
价格: $3.39/GPU/hour
DigitalOcean 8x NVIDIA H100 SXM 实例
-
GPU: 8 x NVIDIA H100
-
GPU 显存: 640 GB (总显存,每卡 80 GB)
-
vCPU: 160 核
-
内存 (RAM): 1,920 GiB
-
引导盘 (Boot Disk): 2 TiB NVMe
-
暂存盘 (Scratch Disk): 40 TiB NVMe
-
数据传输 (Transfer): 60,000 GiB
-
按需实例价格: $2.99/GPU/hour
-
预留实例价格:$1.99/GPU/hour (至少一年的合约期)
RunPod H100 GPU 服务器配置与价格
RunPod 提供了更丰富的 H100 GPU 配置选择,包括 PCIe 和 SXM 型号,并且区分了 Community Cloud 和 Secure Cloud。需要注意的是,Community Cloud 的价格是动态的,以下是撰写时的近似最低价格,实际价格可能因供需而异。
RunPod 1x NVIDIA H100 NVL :
-
GPU: 1 x NVIDIA H100
-
GPU 显存: 94 GB
-
vCPU: 16 核
-
内存 (RAM): 94 GB
-
存储: 40GB
-
社区云价格: $2.59/小时 (价格浮动较大,撰写时观察到的最低价)
-
安全云价格:$2.79/小时
RunPod 1x NVIDIA H100 PCIe :
-
GPU: 1 x NVIDIA H100 PCIe
-
GPU 显存: 80 GB
-
vCPU: 16 核
-
内存 (RAM): 188 GB
-
存储: 40GB
-
社区云价格: 未知
-
安全云价格:$2.39/小时
1x NVIDIA H100 SXM :
-
GPU: 1 x NVIDIA H100 SXM
-
GPU 显存: 80 GB HBM3
-
vCPU: 20 核
-
内存 (RAM): 125 GB
-
存储: 40GB
-
社区云价格: $2.59/小时 (价格浮动较大,撰写时观察到的最低价)
-
安全云价格:$2.69/小时
可以明确看出,DigitalOcean 在价格上与RunPod 接近,甚至 DigitalOcean 的预留实例更能帮助用户节省成本。但是 RunPod 暂时没有提供 8 卡 H100 服务器。目前所有 RunPod 的 GPU 服务器都默认配置 40GB 的存储,如果用户需要更多存储资源需要在后台单独配置,额外的存储的价格是 0.07美元/GB。RunPod 的存储有三类:Container Volume(临时存储)、Network Volume(永久存储)、S3-Compatible Storage,其中 S3-Compatible Storage 属于外部存储,其价格与存取速度因第三方供应商而不同,价格会出现浮动,不利于用户控制成本。
要注意,如果不明确将数据写入 Network Volume,很容易将关键数据意外写入到 Container Volume,导致服务器停止或重启后数据丢失。这对于不熟悉 RunPod 存储模型的新用户是一个常见的“坑”。
DigitalOcean GPU Droplet 可提供灵活扩展的存储。当你的数据量增长,但不需要增加 GPU 计算能力时,可以独立扩展存储容量,而无需升级整个 GPU Droplet。更重要的是,DigitalOcean Volumes 块存储中的数据是持久的,即使 GPU Droplet 被删除,Volume 也可以保留或挂载到新的 GPU Droplet 上,确保数据安全。同时,DigitalOcean Droplet 内置内容分发网络(CDN),可以加速全球范围内的数据访问和内容分发,提升用户体验,尤其对面向全球用户的 AI 应用(如 LLM API 服务)至关重要。DigitalOcean 产品符合 HIPAA 和 SOC 2 标准,并提供企业级服务水平协议(SLA)保障,承诺 Droplet 和数据存储的正常运行时间达到 99.99%。同时,提供 24/7 全天候支持,确保服务的高可用性和稳定性。
总结:长期部署追求高性价比和价格稳定性的企业,DigitalOcean更具优势,特别是其预留实例能带来显著成本节约。对于短期测试或学生科研项目,RunPod的社区云模式可能提供更灵活的按需选择,但需警惕价格波动和存储配置的复杂性。
七、技术支持与本地化体验:出海友好度谁更高?
在 GPU 云平台使用过程中,技术支持和本地化服务质量对出海企业至关重要,尤其在关键节点出现故障或资源调度失败时。
DigitalOcean + 卓普云:提供中文工程师支持与合规能力
DigitalOcean 中国区官方战略合作伙伴卓普云,支持微信/钉钉直接联系、定制化架构建议等服务。同时具备中国大陆境内开票能力,支持企业通过人民币对公结算,解决海外云服务报销难问题。
同时,用户还可以通过 DigitalOcean 英文官网的社区、工单系统,获取英文的技术支持。而且,DigitalOcean 拥有丰富的文档与教程,可以进一步帮助用户。
RunPod:论坛社区为主,支持自助工单系统
RunPod 提供基础 FAQ 与英文工单系统,但缺乏专门的中文技术支持团队。本地化能力较弱,适合具备海外操作经验的技术团队。
总结:DigitalOcean + 卓普云模式显著降低了中国用户使用门槛,RunPod 更适合已有独立 DevOps 能力的 AI 团队。
如何为你的 AI 出海项目选对 GPU 云平台?
最终选择哪家平台,应结合项目阶段、预算约束、团队技术能力以及目标市场进行综合考量。以下是几个典型场景建议:
-
个人早期探索阶段:个人用户希望快速尝试多个模型与推理框架,建议选择 RunPod,启动快、灵活度高。
-
规模化部署阶段:对模型性能稳定性与 SLA 要求较高,建议选择 DigitalOcean,裸金属稳定,价格透明。
-
中国企业出海场景:需要中文服务、本地结算与云主机配套资源支持,DigitalOcean + 卓普云是更适合的组合方案。
选择 DigitalOcean GPU Droplet ,您的企业将能享受到以下显著优势和好处:
-
GPU资源丰富:DigitalOcean 的GPU Droplet 提供了市场上最前沿的旗舰款 GPU 型号,以及像 RTX 6000 Ada、RTX 4000 Ada 和 L40S 等高性价比 GPU。DigitalOcean GPU Droplet 提供按需实例、预留实例和裸金属机型供用户自由选择。
-
卓越的性价比: DigitalOcean 的 GPU Droplet 服务在提供高性能 GPU 的同时,提供了比 AWS、谷歌云服务、腾讯、阿里云、RunPod 等云服务商更实惠的价格,帮助中国企业有效控制出海成本。清晰透明的定价模式,也避免了意外开支。
-
企业级稳定性与可靠性: 作为拥有自营数据中心的通用云服务商,DigitalOcean 提供的 GPU 资源具有更高的可预测性和稳定性,特别是在裸金属实例方面,确保了 AI 模型的长期稳定运行。严格的 SLA 和 24/7 技术支持,为您的业务保驾护航。
-
部署与运维的便捷性: DigitalOcean GPU Droplet界面直观,配置简单,配合“ML-in-a-Box”和“一键模型部署”等功能,能大幅缩短 AI 项目从开发到部署的时间。与 DigitalOcean Kubernetes (DOKS) 等服务的无缝集成,也为复杂 AI 工作流的管理提供了便利。
-
强大的数据存储与管理: 除了高性能的本地 NVMe 存储,DigitalOcean 还提供可独立扩展的持久化块存储(Volumes)和高可用、带 CDN 的对象存储(Spaces)。这些存储服务均为平台自主提供,确保了数据传输的稳定性和安全性,并能有效帮助您管理和优化数据存储成本。
-
定制化的本地支持: 通过与卓普云的合作,DigitalOcean 为中国出海企业提供了定制化的本地支持服务,包括中文工程师、微信/钉钉沟通渠道、人民币对公结算和中国大陆境内开票能力,极大地简化了海外云服务的使用和财务流程,让中国企业能够更专注于 AI 业务创新,无后顾之忧。
如果你也在为出海部署 AI 系统而苦恼,不妨试试搭配一台 DigitalOcean 的 GPU Droplet 服务器。如需获取 DigitalOcean 中国区 GPU 免费试用资格或出海部署建议,可联系卓普云技术顾问获取专属资源支持。


















 775
775

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









