




客户端模式
3FS 实现了两套客户端模式,FUSE Client和Native Client。前者更方便适配,性能相对较差。后者适合集成性能敏感的应用程序,适配成本较高。接下来做进一步分析。
Fuse Client
Fuse Client 模式的原理如下图所示。和传统 FUSE 应用类似,在 libfuse 中注册了 FUSE Daemon 实现的 fuse_lowlevel_ops,之后通过 FUSE 的所有的文件操作,都会通过 libfuse 回调到 FUSE Daemon 进行处理。同时在 libfuse 中实现了一个多线程模式来高效读取请求。这种模式对于业务逻辑影响较小,可以做到无感知。但是每次 I/O 单向需要经过两次“用户态-内核态”上下文切换,以及“用户空间-内核空间”之间数据拷贝。

Native Client (USRBIO)
介绍这个模式之前我们先了解一下 User Space Ring Based IO(简称 USRBIO)[1],它是一组构建在 3FS 上的高速 I/O 函数。用户应用程序能够通过 USRBIO API 直接提交 I/O 请求给 FUSE Daemon 进程中的 3FS I/O queue 来和 FUSE 进程通信,从而做到 kernel bypass。两者之间通过基于共享内存 ior/iov 的机制交换数据,这部分在后面章节介绍。Native Client 模式的原理如下图所示。使用这种模式能有效避免“用户态-内核态”上下文切换,同时做到零数据拷贝,全链路基本无锁化设计,性能上要比 Fuse Client 模式提升很多。(根据我们对 3FS 开源的 fio ioengine hf3fs_usrbio 压测结果看,在不进行参数调优的情况下,USRBIO 比 **Fuse Client **模式顺序写性能提升 20%-40%,其他场景性能还在进一步验证中)
3FS 使用 Pybind 定义 Python 扩展模块 hf3fs_py_usrbio,这也方便 Python 能够访问 hf3fs 的功能。以此推测 USRBIO 模式适合在大模型训练和推理等对性能有极致需求的场景中使用。
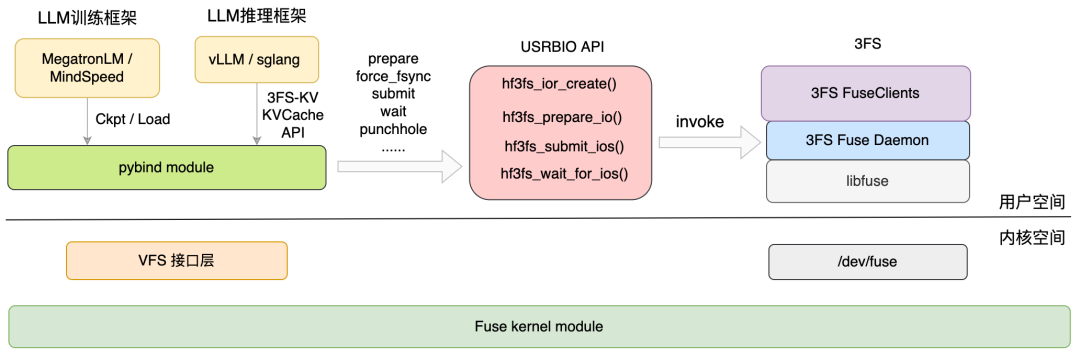
另外,从上面分析我们注意到 Fuse Daemon 在两种客户端模式下都起到核心作用的重要组件。在 Fuse Client 模式中,它通过 fuseMainLoop 创建 FuseClients,注册 fuse 相关 op 的 hook,并根据配置拉起单线程(或多线程) fuse session loop 处理 fuse op。在 USRBIO 模式中,与 I/O 读写链路相关的 USRBIO API 通过共享内存和 Fuse Daemon 通信,部分与 I/O 无关的控制路径请求例如 hardlink,punchhole 等,USRBIO API 则还是通过 ioctl 直接走了内核 FUSE 路径。这可能是一个 tradeoff 的设计,后面会做讨论。
基础组件
ServerLauncher
Fuse Daemon 也就是 FuseApplication, 通过 core::ServerLauncher 拉起。同样的还有 MgmtdServer,MetaServer,StorageServer 都是类似的 Daemon。Fuse Daemon 拉起之后就创建一个 FuseClients 进行核心功能操作。
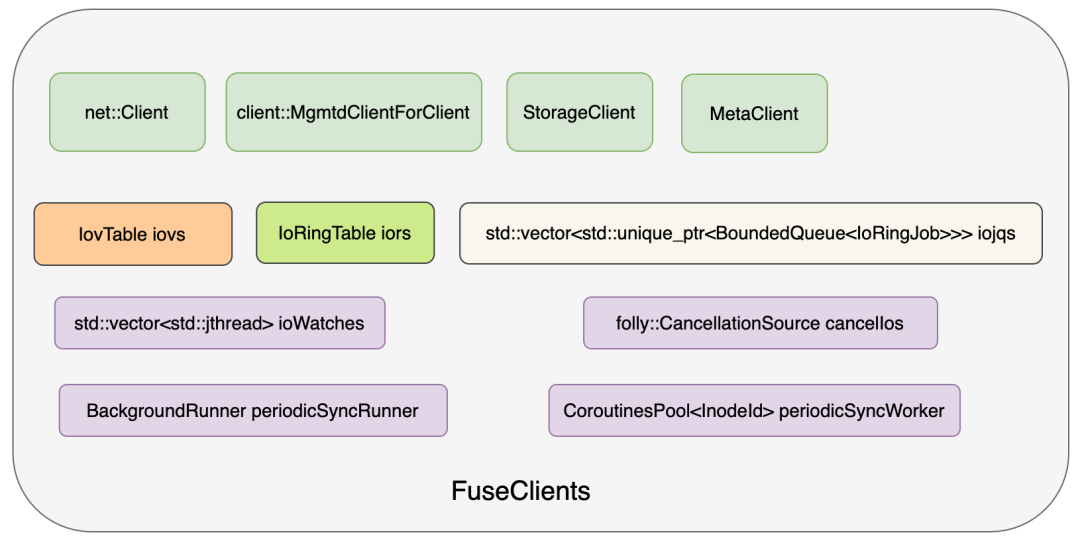
FuseClients
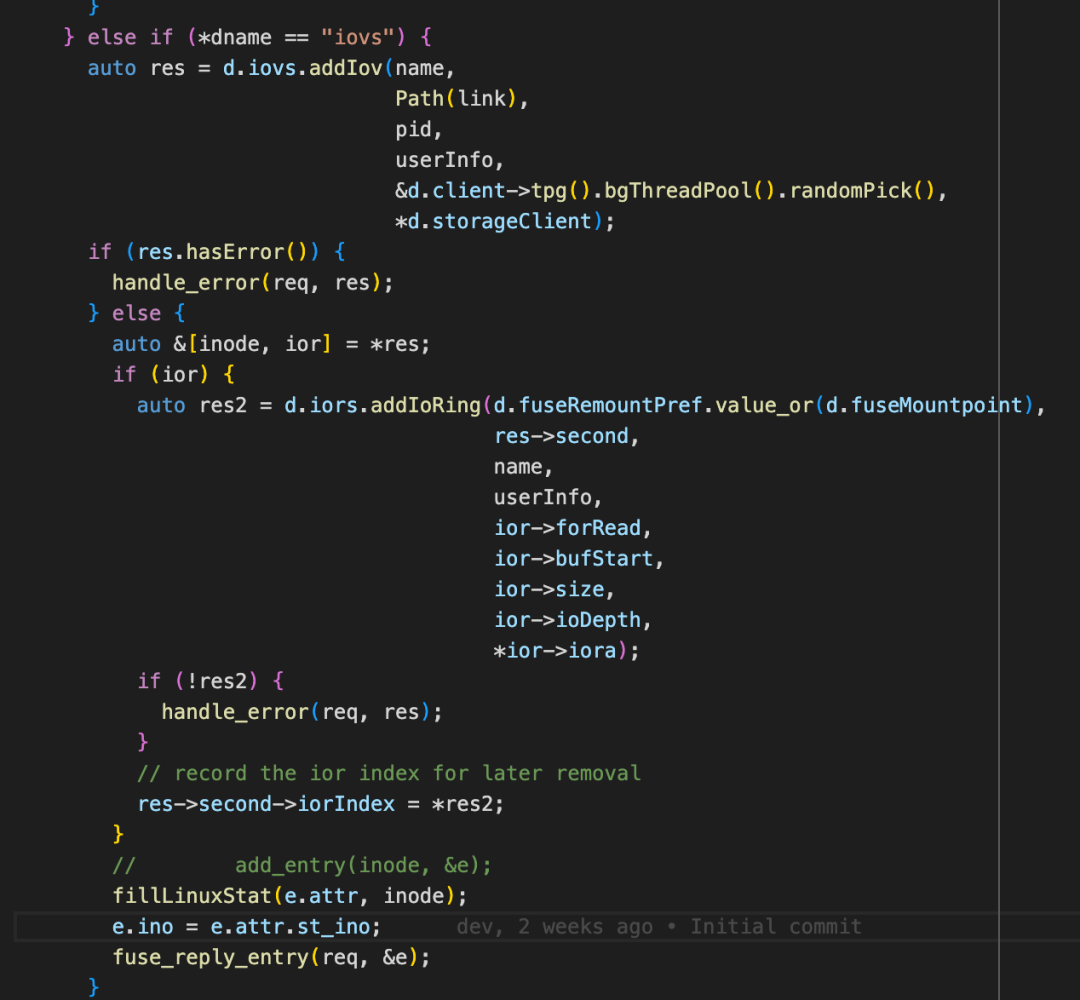
一个 FuseApplication 包含 一个 FuseClients,一个 FuseClients 和一个挂载点对应。FuseClients 主要包括下图所示组件,其中包含与其他组件(meta,mgmtd,storage)打交道的 "client for client"。FuseClients 在启动时也会初始化 mgmtdClient,创建 StorageClient,metaClient,启动周期性 Sync Runner(用来更新文件长度等元数据),创建 notifyInvalExec 线程池等。同时还为每一个 FuseClients 创建一组 IOV 和 IOR。FuseClients 最重要的部分还是在和 USRBIO 协同设计。下面我们着重分析这部分。
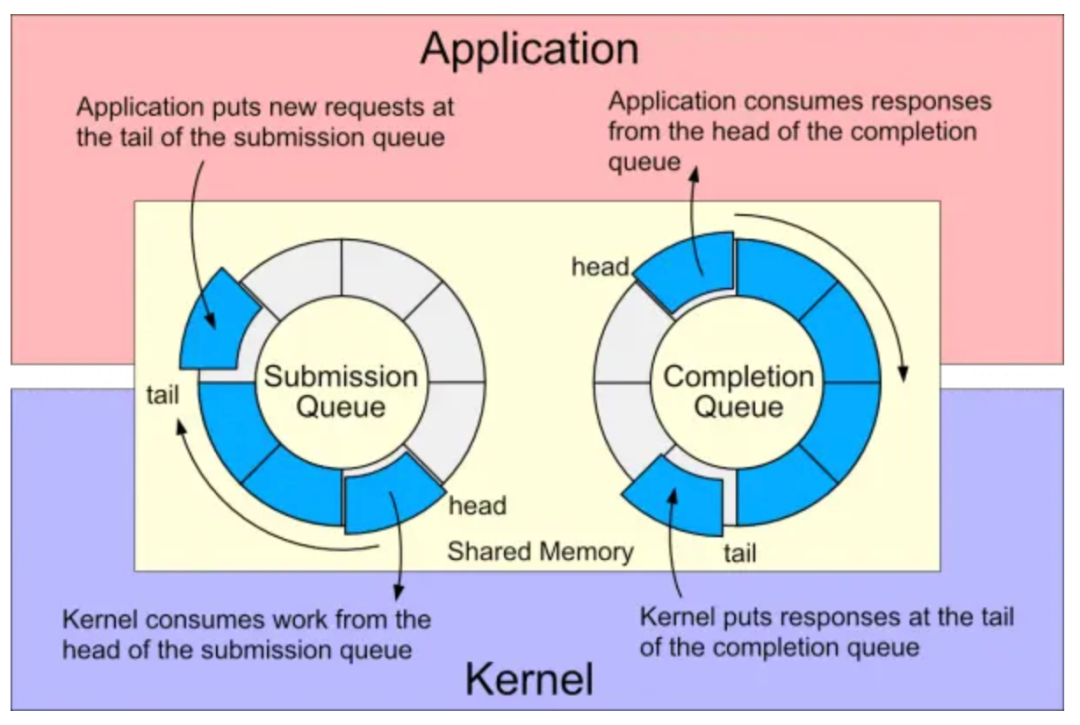
USRBIO 的设计和思考
3FS USRBIO 设计思想借鉴了 io_uring 以及 SPDK NVMe 协议栈的设计。原生 io_uring [2] 由一组 Submission Queue 和 Completion Queue 组成,每个 queue 是一个 ring buffer。用户进程提交请求到 SQ,内核选择 polling 模式或事件驱动模式处理 SQ 中的请求,完成之后内核向 CQ 队尾 put 完成 entry,应用程序根据 polling 模式或者事件驱动模式处理 CQ 队首的请求。整个过程无锁,共享内存无内存拷贝。在 polling 模式下,io_uring 接近纯用户态 SPDK polling mode 性能,但是 io_uring 需要通过额外的 CPU cost 达到这个效果。
3FS USRBIO 的核心设计围绕 ior 和 iov 来开展。 ior 是一个用于用户进程与 FUSE 进程之间通信的小型共享内存环。用户进程将读/写请求入队,而 FUSE 进程从队列中取出这些请求并完成执行。ior 记录的是读写操作的元数据,并不包含用户数据,其对应的用户数据 buffer 指向一个叫做 iov 的共享内存文件。这个 iov 映射到用户进程和 FUSE 进程共享的一段内存,其中 InfiniBand 内存注册由 FUSE 进程管理。在 USRBIO 中,所有的读取数据都会被读取到 iov,而所有的写入数据应由用户先写入 iov。
ior 用来管理 op 操作任务,和 io_uring 不同的是这个 queue 中既包括提交 I/O 请求(sqe)又接收完成 I/O 结果(cqe),而且不通过 kernel,纯用户态操作。ior 中包含的 sqeSection 和 cqeSection 的地址范围由创建 ring 的时候计算出来的 entries 个数确定,用来查询 sqe 和 cqe 在 ring 中的 位置。ior 中还包含一个 ringSection,这个 section 用来帮助 sqe 定位 iov id 的索引和位置。
如下图所示,sqe 里包含 idx 是 IOArgs* ringSection 这个数组的下标,索引后才是真正的 io 参数。例如:seq -> ringSection[idx] -> IovId -> Iov。
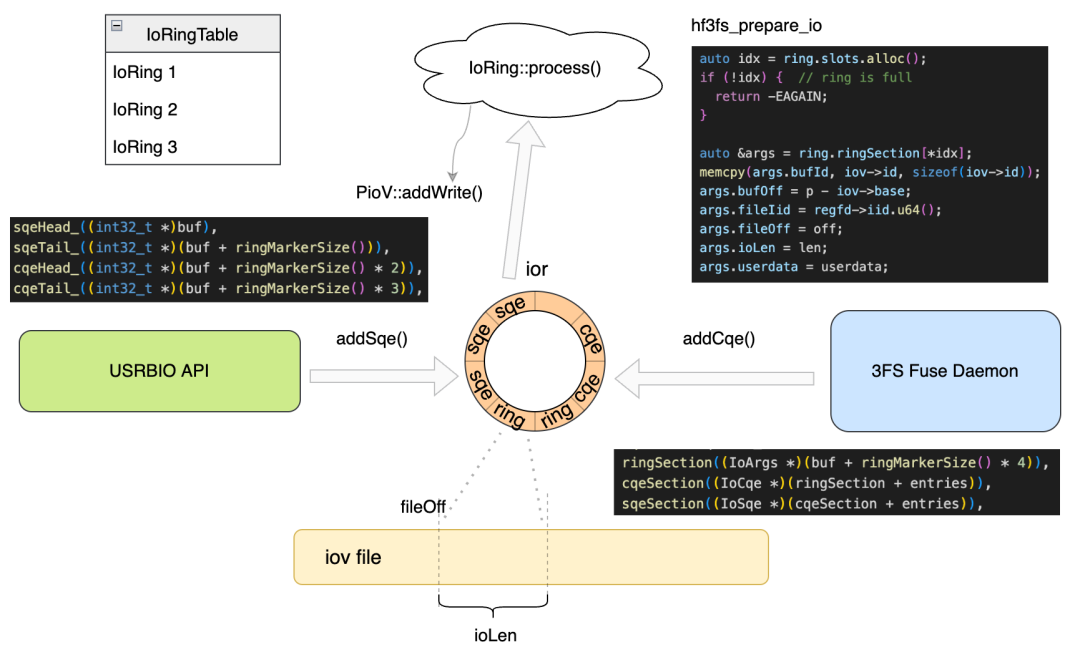
USRBIO 中提供了一个 API hf3fs_iorwrap 用来创建和管理 ior,其中 Hf3fsIorHandle 用来管理 ior。之后 hf3fs_iorwrap 会通过 cqeSem 解析 submit-ios 信号量的路径,并通过 sem_open 打开关联信号量,用于 I/O 任务同步。这里的信号量根据优先级被放置在不同目录中。之后在提交 IO 过程中,会 post 信号量通知 cqe section 中 available 的 slots。
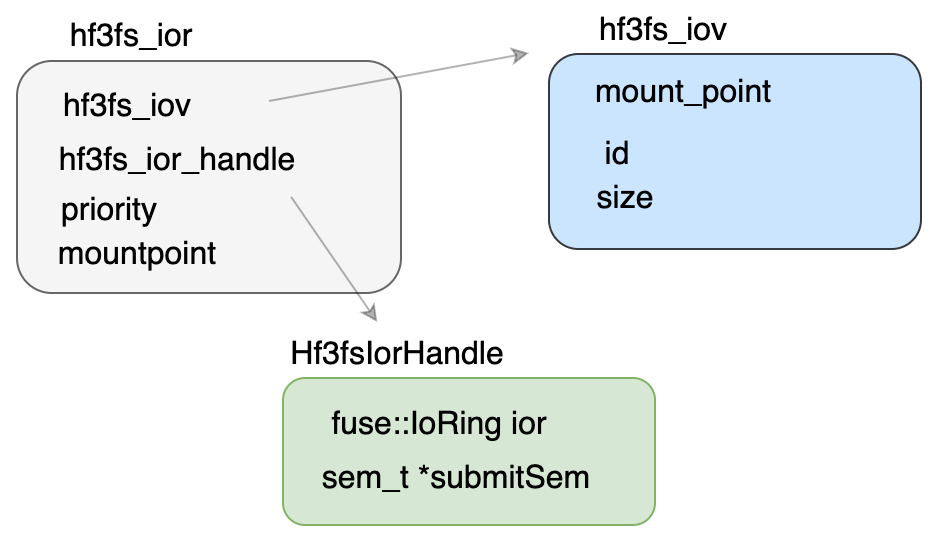
在 ior 中,通过 IoRingJob 分配工作,任务被拆分成 IoRingJob,每个任务会处理一定数量的 I/O 请求做批处理。和 io_uring 一样,采用 shared memory 减少用户态与内核态切换。
-
1. IoRing 初始化资源
-
2. 提交 I/O 请求 addSqe
-
3. 获取待处理的 I/O 任务 IoRing::jobsToProc
-
4. 处理 I/O 任务 IoRing::process,如上图所示。
IoRing::process() -->ioExec.addWrite() --> ioExec.executeWrite()
--> ioExec.finishIo()
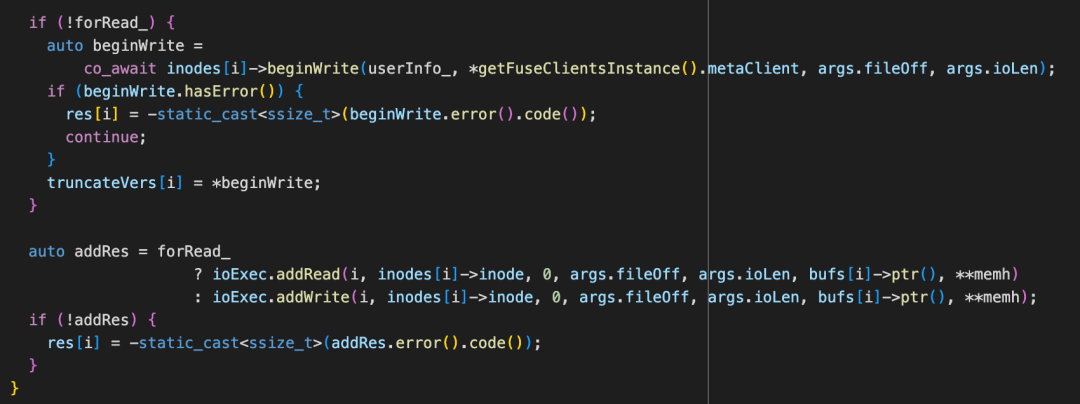
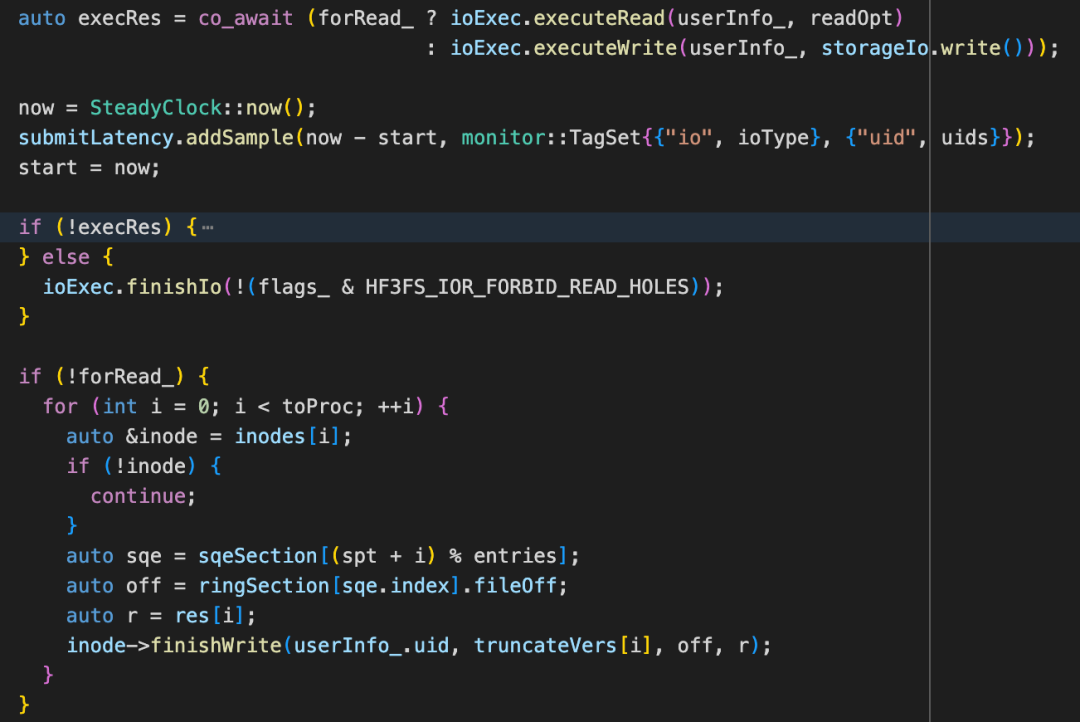
IoRing 中的 ioExec 就是 PioV。PioV::executeWrite() 执行写操作中根据是否需要 truncate chunk,选择将 truncate WriteIO 包到一个 std::vectorstorage::client::WriteIO wios2中,或者直接传输std::vectorstorage::client::WriteIO wios_,最后通过 StorageClient::batchWrite() 将 Write IO 通过发送 RPC 写请求到 Storage 端。其中,写请求 WriteReq 包括 payload,tag,retryCount,userInfo,featureFlags 等字段。
FuseClients 中最核心的逻辑之一在 ioRingWorker 中。它负责从 FuseClients 的 ior job queue 中拿到一个 ior,并调用 process 处理它。在处理过程中考虑了取消任务的设计,这里使用了一个 co_withCancellation 来封装,它能够在异步操作中优雅地处理任务取消,避免不必要的计算或资源占用,并且支持嵌套任务的取消感知。有关 co_cancellation 的原理可以参考 [3]:

另外,还支持可配置的对任务 job 分优先级,优先级高的 job 优先处理。这些优化都能在复杂的场景下让性能得到极致提升。值得提到的一点是,所有的 iovs 共享内存文件在挂载点 3fs-virt/iovs/ 目录下均建有 symlink,指向 /dev/shm 下的对应文件。
USRBIO 代码逻辑错综复杂,偏差之处在所难免,在这里抛砖引玉一些阅读代码的思路和头绪,如有错误也请不吝批评指正。
关于USRBIO的思考
USRBIO 在共享内存设计上使用了映射到物理内存的一个文件上,而不是使用匿名映射到物理内存。这可能是因为用户进程和 FUSE Daemon 进程不是父子进程关系。实现非派生关系进程间的内存共享,只能使用基于文件的映射或 POSIX 共享内存对象。
USRBIO 没有采用直接以 SDK 形式,放弃 Fuse Daemon,直接和元数据服务器与 Chunk Server 来通信的方式设计客户端,而采用了关键 I/O 路径使用纯用户态共享内存,非关键路径上依旧复用 libfuse 这种方式。这可能是简化控制链路设计,追求 FUSE 上的复用性,追求关键路径性能考虑。另外在 IoRing 的设计上并没有使用类似 io_uring 中的可配置的 polling 模式,而是采用信号量进行同步,这里暂时还没有理解背后的原因是什么。
USRBIO 使用共享内存还是不可避免会带来一些开销和性能损耗,如此设计的本质原因还是所有核心逻辑都做在了 FUSE Daemon 进程中。如果提供重客户端 SDK,所有逻辑都实现在 SDK 中,以动态连接库形式发布给客户端,可能就不需要进行这样的 IoRing 设计,或者只需要保留 io_uring 这样的无锁设计,不再需要共享内存设计。这样的好处和坏处都很鲜明:好处是 SDK 的实现能避免跨进程的通信开销,性能能达到理想的极限;坏处是如果需要保留 FUSE 功能的话需要实现两套代码,逻辑还很雷同,带来较大的开发和维护成本。而且 SDK 的升级比较重,对客户端造成的影响相对较大。当然从工程角度上可以由 FUSE 抽象出公共函数库让 Native Client 直接调用也可以避免重复开发。
目前这么做猜测可能是先做的 FUSE,后面再提供的 Native Client,这样采用现有方案是个比较水到渠成的过程,整体投入产出比可控。 这同时也是 USRBIO 方案的好处,它的客户端这一侧 API 相对较薄,逻辑也相对稳定,没有太多升级的压力,另外 Fuse 进程承担了和元数据以及 Storage 的通信,这样对上层推理或者训练业务的影响也就会较小。总体来说,USRBIO 方案是在易用性(FUSE 升级相对容易)、研发效率(简单化管控面)和性能(只针对 I/O 路径)这三个方面上做的一个权衡。
在大模型训练和推理技术蓬勃发展的今天,存储越来越贴近计算是一个必然的发展趋势。特别是在训练侧的 checkpoint,尽可能地让数据更快地从 GPU 写入到远端存储,能大大提升整体性能。目前在 3FS USRBIO 路径上没有看到 GPU Direct Storage / GPU Direct RDMA / GPU Direct Async 被使用,考虑到一个可能原因是 folly 协程库在 nvcc 下编译有问题。协程虽然在计算密集型业务中带来的性能提升不明显,但对于 I/O 密集型业务由于避免了线程切换的开销能带来较大提升,这个点上相信 DeepSeek 做过较深入的对比和考量。
另外,我们也从 DeepSeek 开源的 DeepEP 上看到在跨 NVLink 域 和 RDMA 域高性能通信的可能性,是否在存储框架上也能实现与上层训练和推理框架更紧密地结合,畅想一下 3FS 和大模型存储业界未来可能打造出诸如 User Space GPU Based IO(USGBIO)这样的存储组件来。
StorageClient
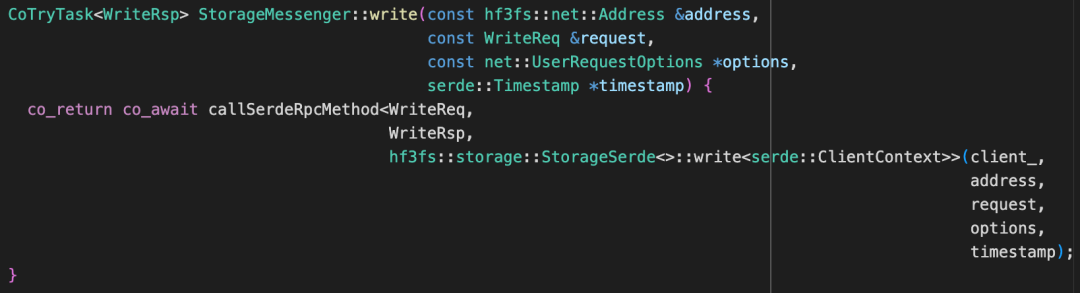
StorageClient 是客户端和 Storage 进行 RPC 通信的重要组件。StorageClientImpl 是其中实际工作的模块,它在启动的时候会拉起来若干组件:包括一个存储用的 StorageMessenger,一个Update用的 StorageMessenger,初始化MgmtdClient。
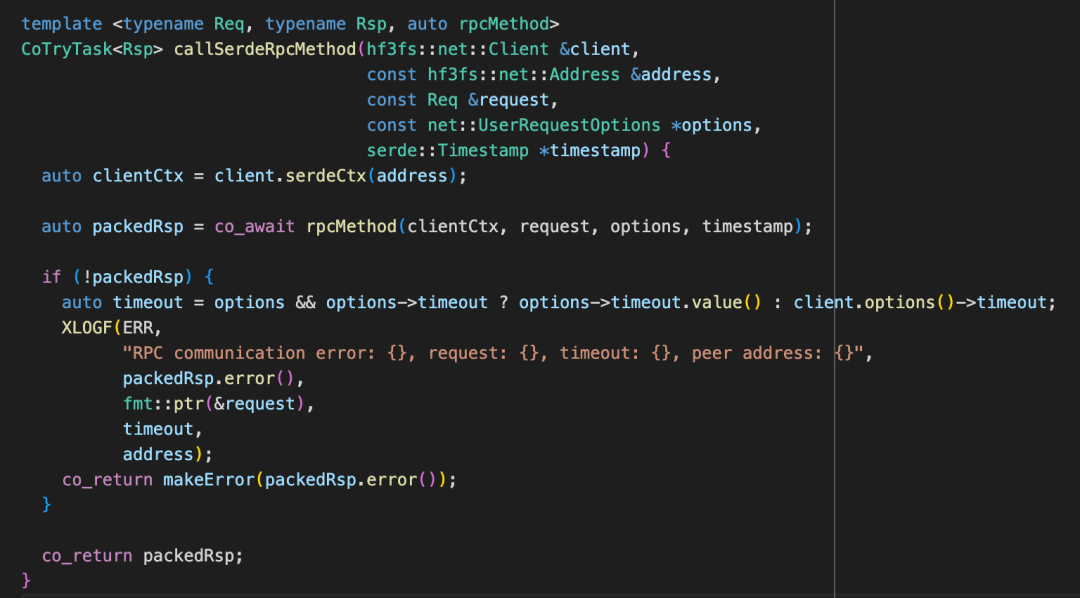
StorageClientImpl::selectRoutingTargetForOps() 中会选择 servingTargets。同时 StorageClient 中有一个 StorageMessenger,通过调用 callSerdeRpcMethod 发送请求到 Storage。
Targets 选择
在 batchRead,batchWrite,queryLastChunk,removeChunks,truncateChunks 操作中都涉及到选择 routing targets。
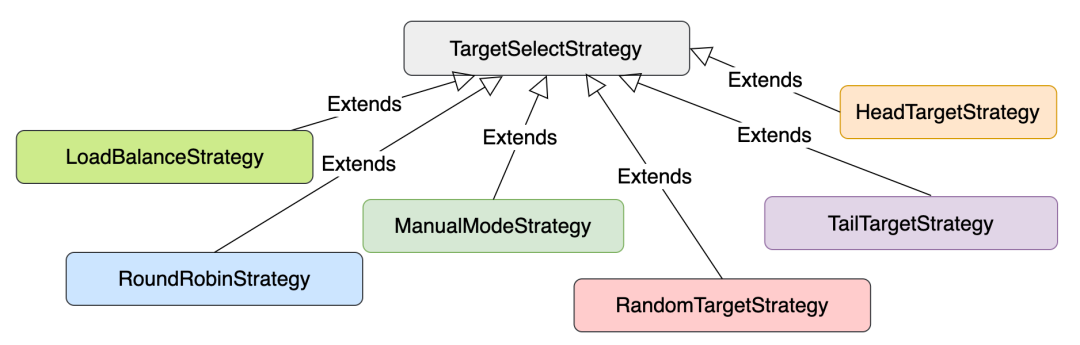
selectRoutingTargetForOps-->TargetSelectionStrategy::create(options) --> targetSelectionStrategy->selectAnyTarget()
客户端选择 Target 策略 有若干种类型可供配置选择:
Batch 和 Parallel
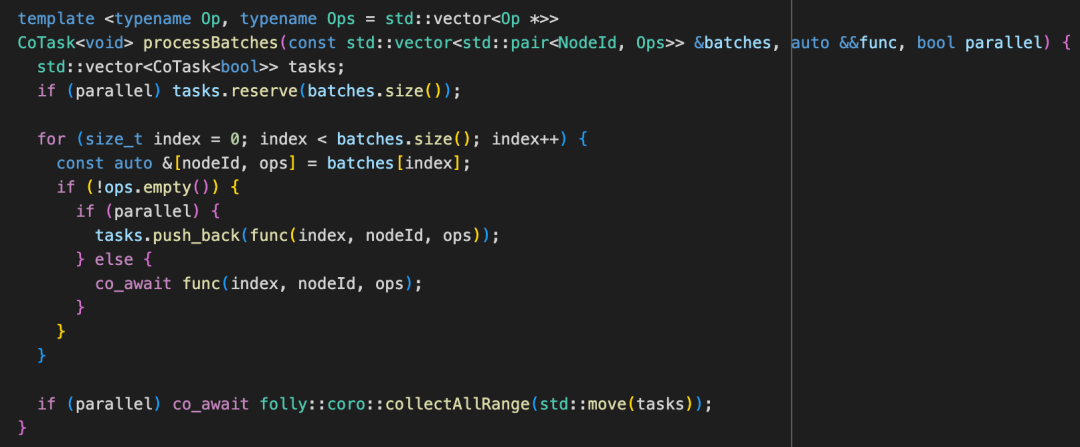
在 batchRead,batchWrite,queryLastChunk,removeChunks,truncateChunks 操作中均涉及到 batch 操作。这部分逻辑使用 groupOpsByNodeId 将输入的请求根据不同 NodeId 做 group 聚合,生成了一个根据 NodeId 组成的 Op* 数组的这样一个 pair 的数组,最后通过 processBatches 把它们发送出去。在 processBatches 中巧妙利用 folly::coro::Task 和 collectAllRange 来实现了并行执行操作。
参考材料
[1] 3FS USRBIO 官方参考文档
https://github.com/deepseek-ai/3FS/blob/main/src/lib/api/UsrbIo.md
[2] Why you should use io_uring for network I/O | Red Hat Developer
[3] DeepSeek SF-ZHOU 关于 folly coro cancellation 的技术博客
https://sf-zhou.github.io/coroutine/folly_coro_cancellation.htm

















 2778
2778

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









