







1. 引言
DeepSeek-V3 由杭州深度求索人工智能基础技术研究有限公司发布的 LLM 模型,于2024年12月26日发布。DeepSeek-V3 为自研 MoE 模型,671B 参数,激活 37B,在 14.8T token 上进行了预训练。DeepSeek-V3 在推理速度上相较历史模型有了大幅提升。在目前大模型主流榜单中,DeepSeek-V3 在开源模型中位列榜首,与世界上最先进的闭源模型不分伯仲。
本文主要带领大家结合 DeepSeek-V3 技术报告一同查阅 DeepSeek-V3 核心架构的源码。建议事先下载好源码一同来学习学习,如果没有时间细看可以先收藏后查阅。
github:https://github.com/deepseek-ai/DeepSeek-V3
模型架构代码所在:inference/model.py
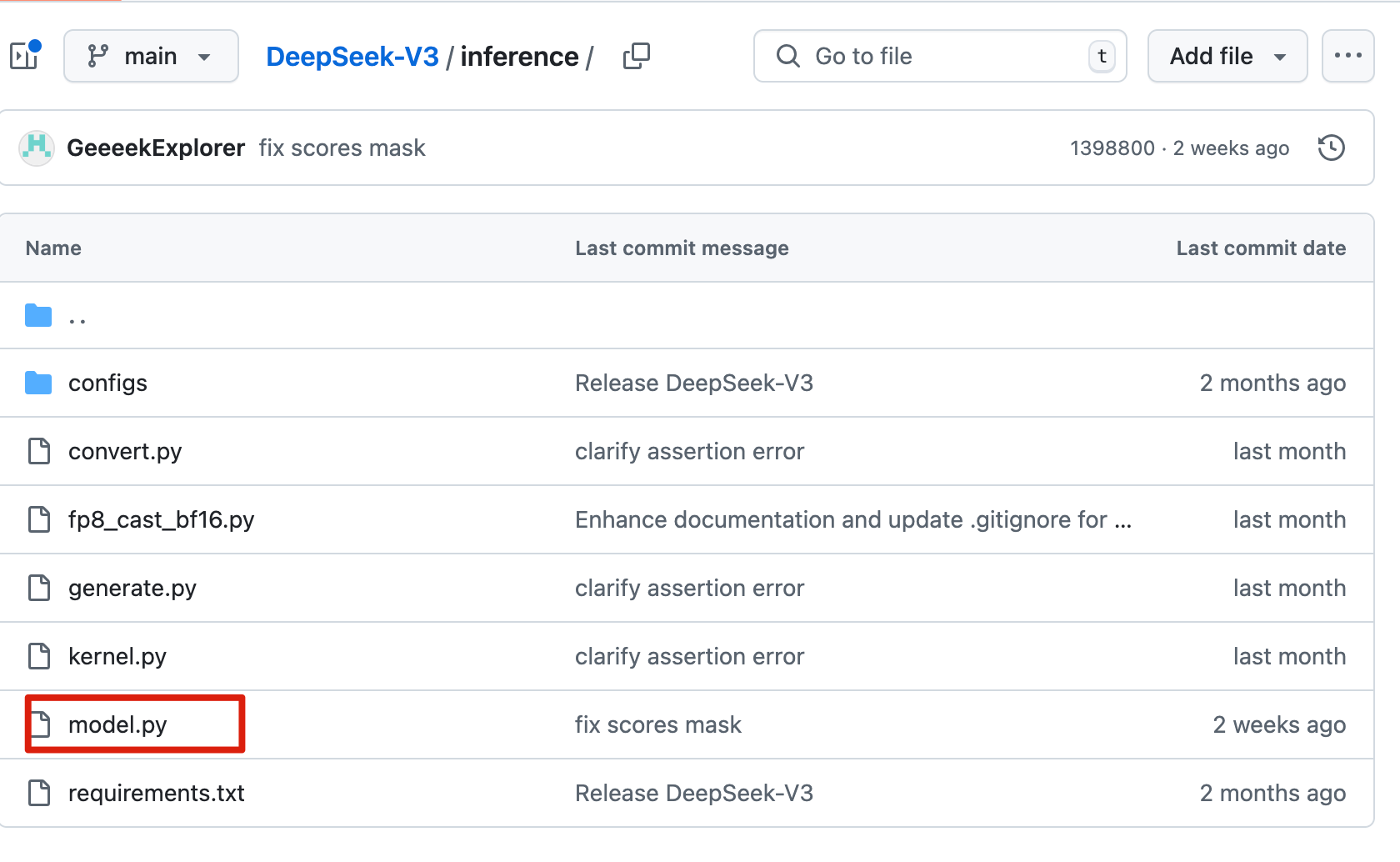
我们主要关注 model.py 文件中的代码即可。
2. 模型架构
我们先看一下官方展示的 DeepSeek-V3 模型架构图:

从上面这张图中,官方主要详细展示有两块内容,一是 MLA,二是 MOE,这些也是本文的主要内容所在。
对应来看下 model.py 定义的 class 有这些:
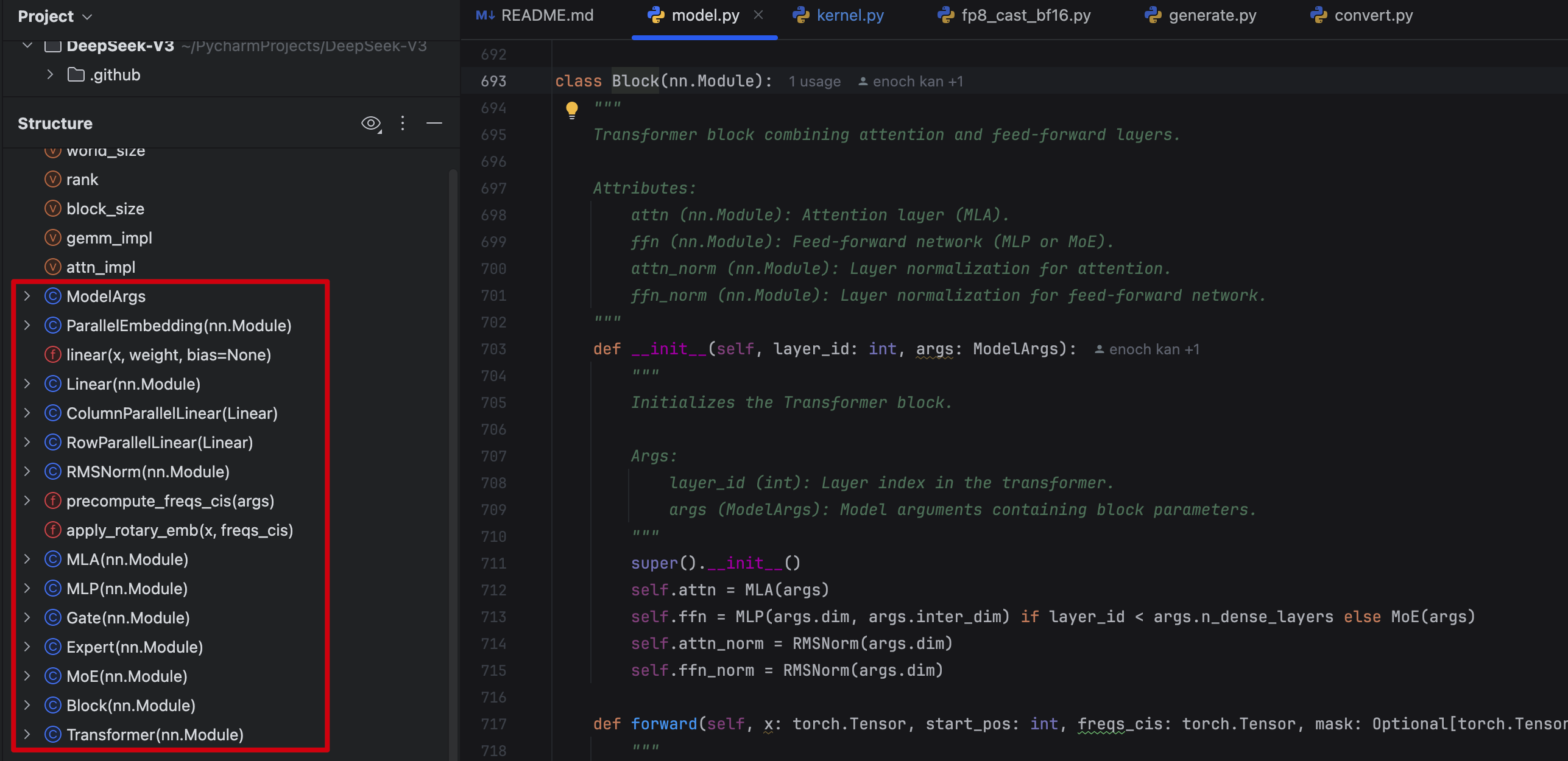
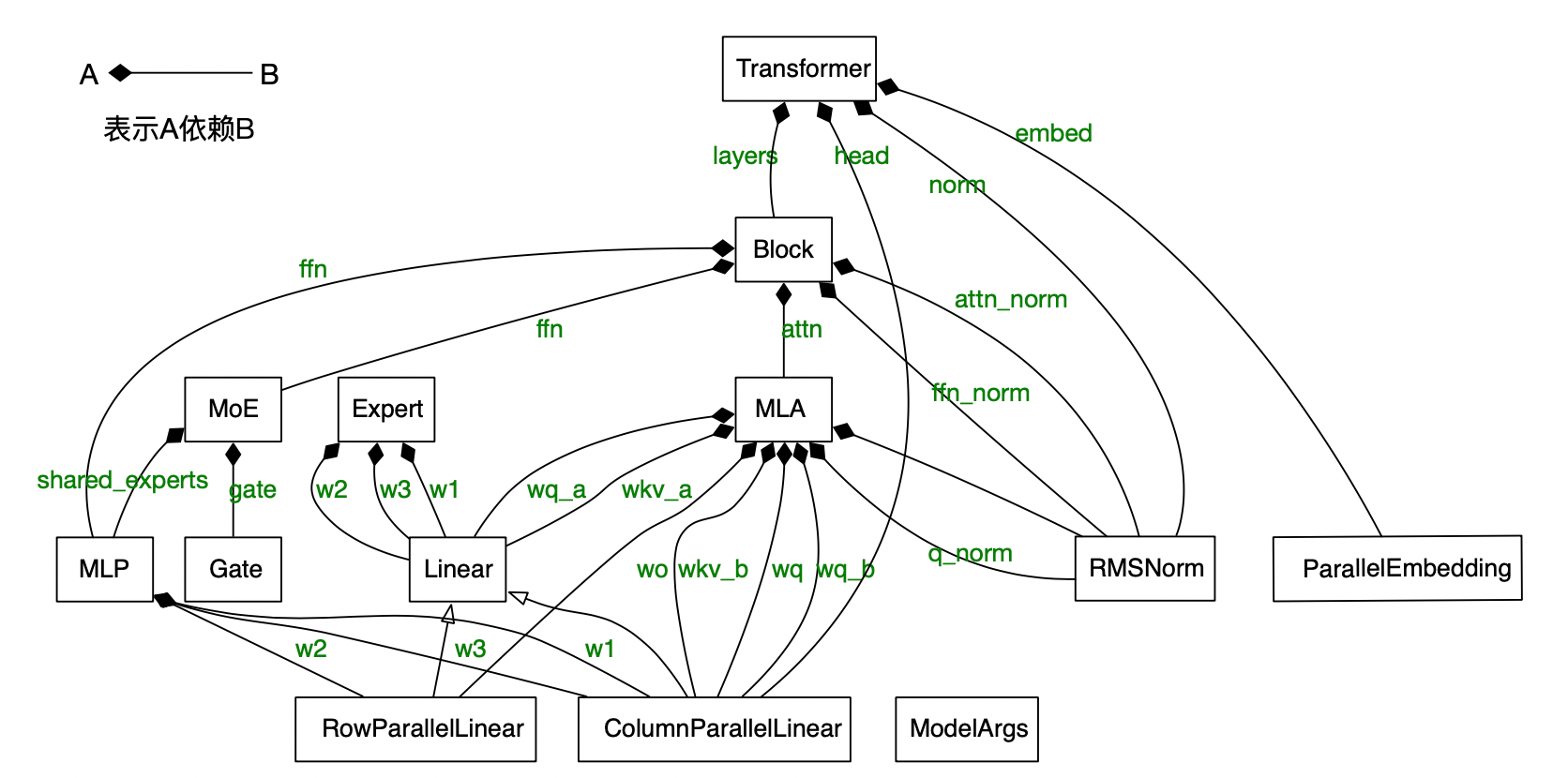
我们根据 model.py 定义的class 引用关系,可以绘制得出以下的关系:
3. 代码流程
3.1 初始化
Transformer 入口初始化:
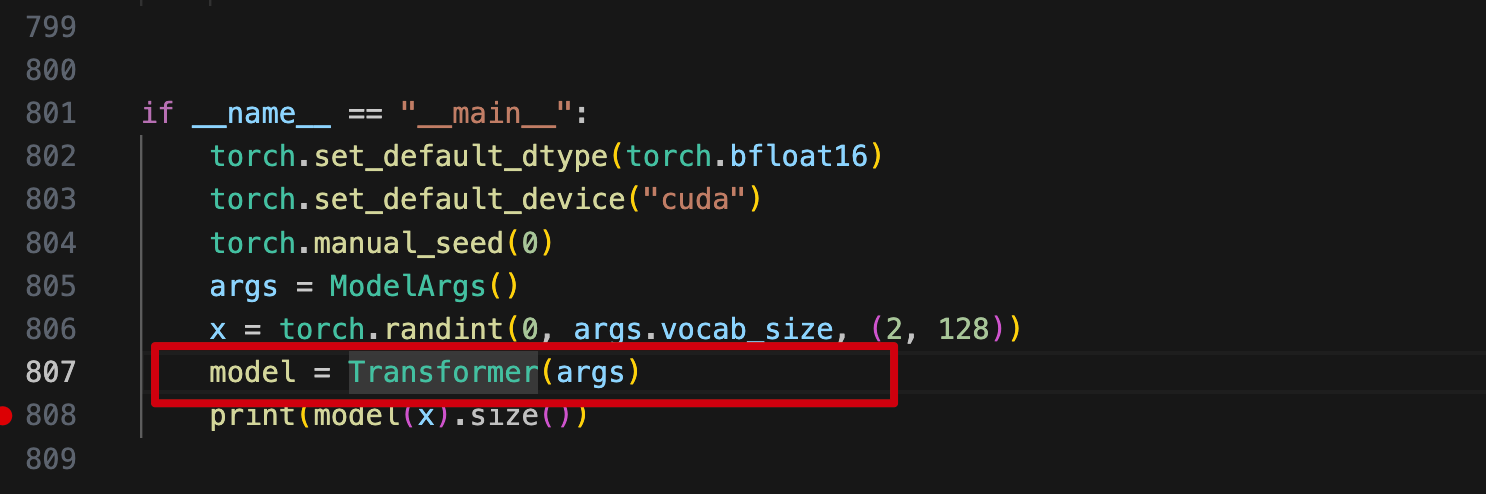
3.1.1 Transformer类
这里核心的初始化是模型层的初始化,每一层添加 Block 层:
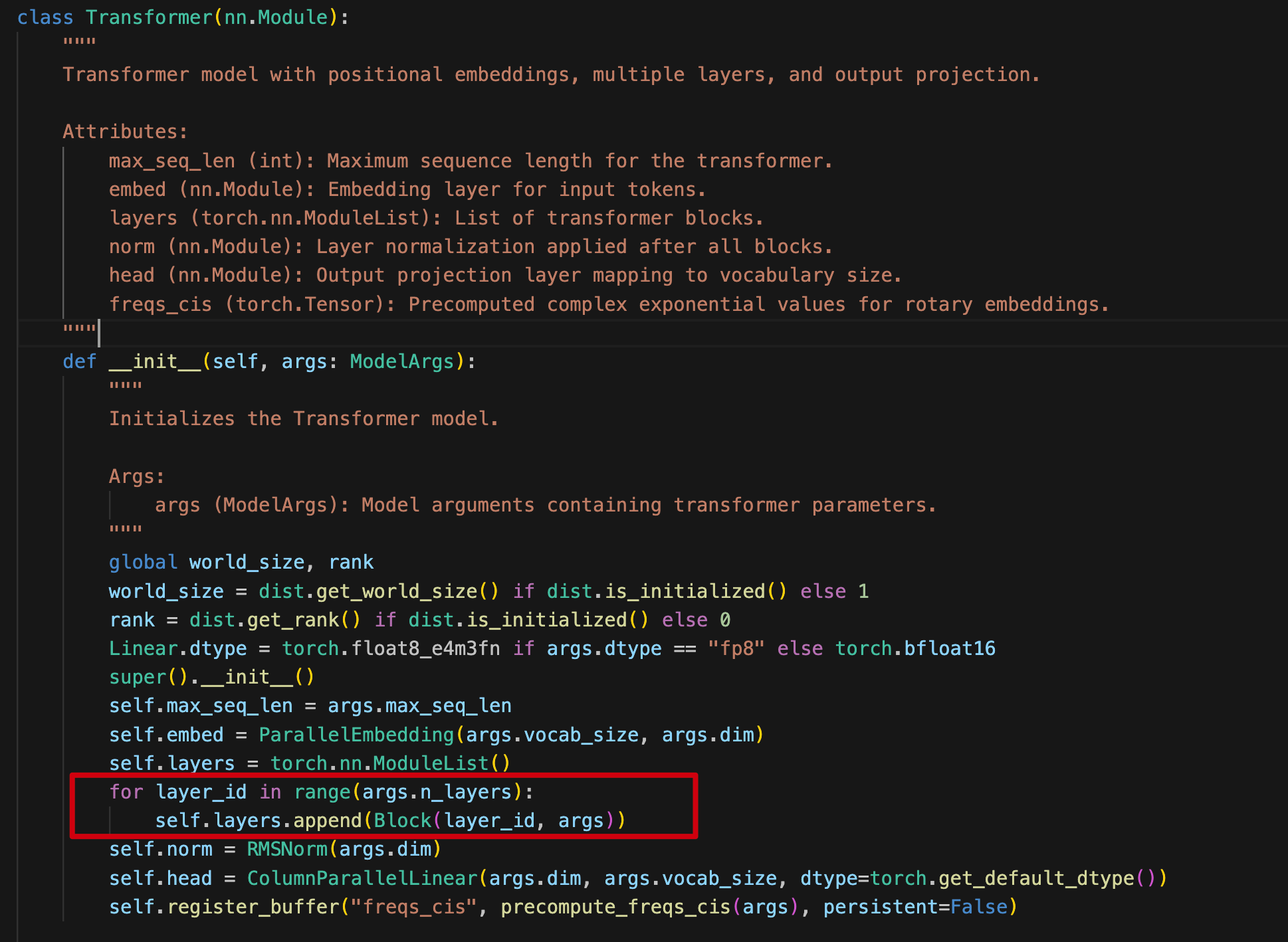
ps:代码中的 ParallelEmbedding、ColumnParallelLinear 主要用于分布式计算的,我们可以简化为 Embedding、Linear,即向量化、线性变换。
3.1.2 Block类
Block 层初始化主要关注 attn 和 ffn 层。
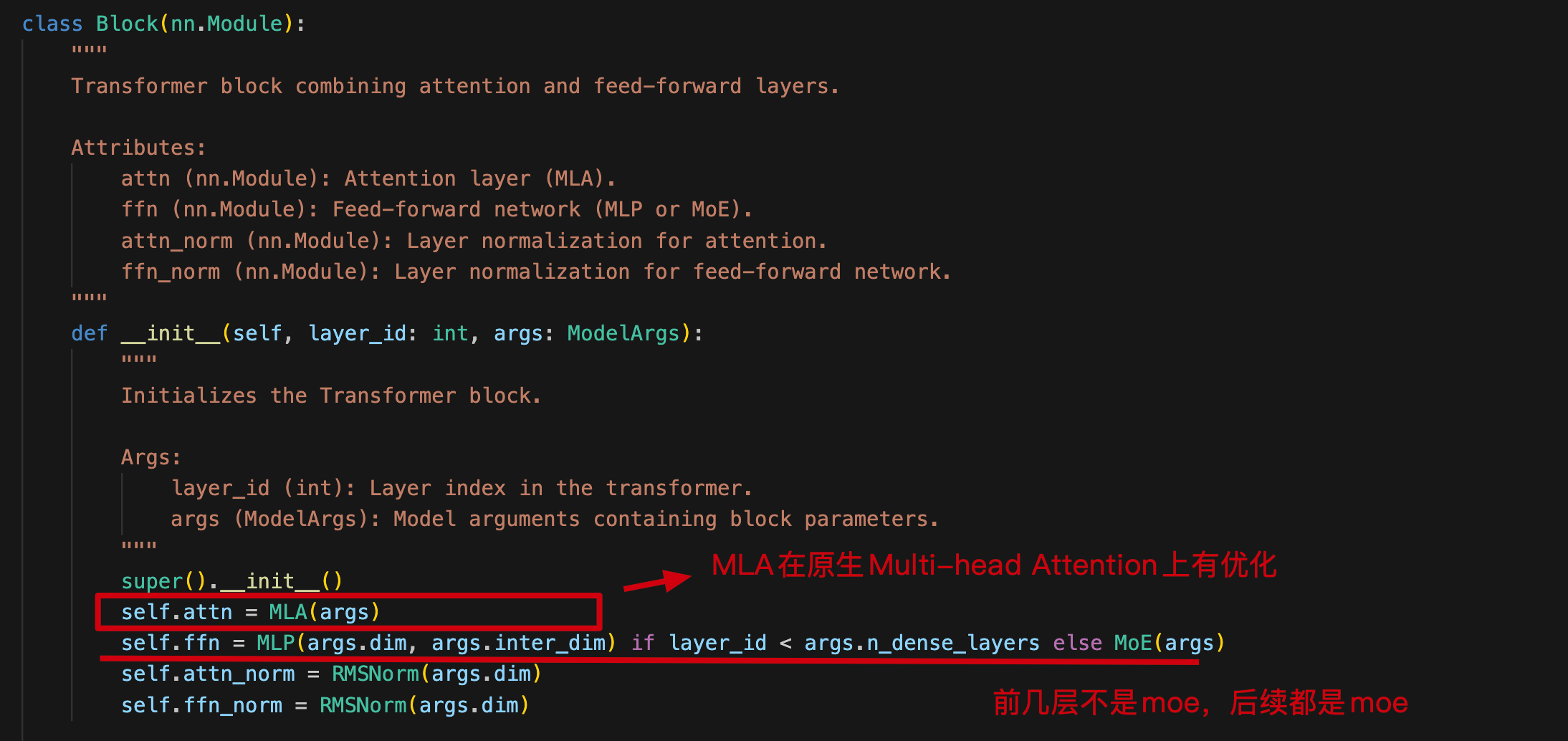
其中:
- attn 是 MLA(Multi-Head Latent Attention)替换了 Transformer 的 Multi-Head Attention
- ffn 也不完全是原始 Transformer 的 ffn,而是前几层是 MLP(多层感知机)、后面都是 MOE
Block 的多层叠加类似下图这样,前几层是 MLA + MLP,后面就是 MLA + MOE 了:
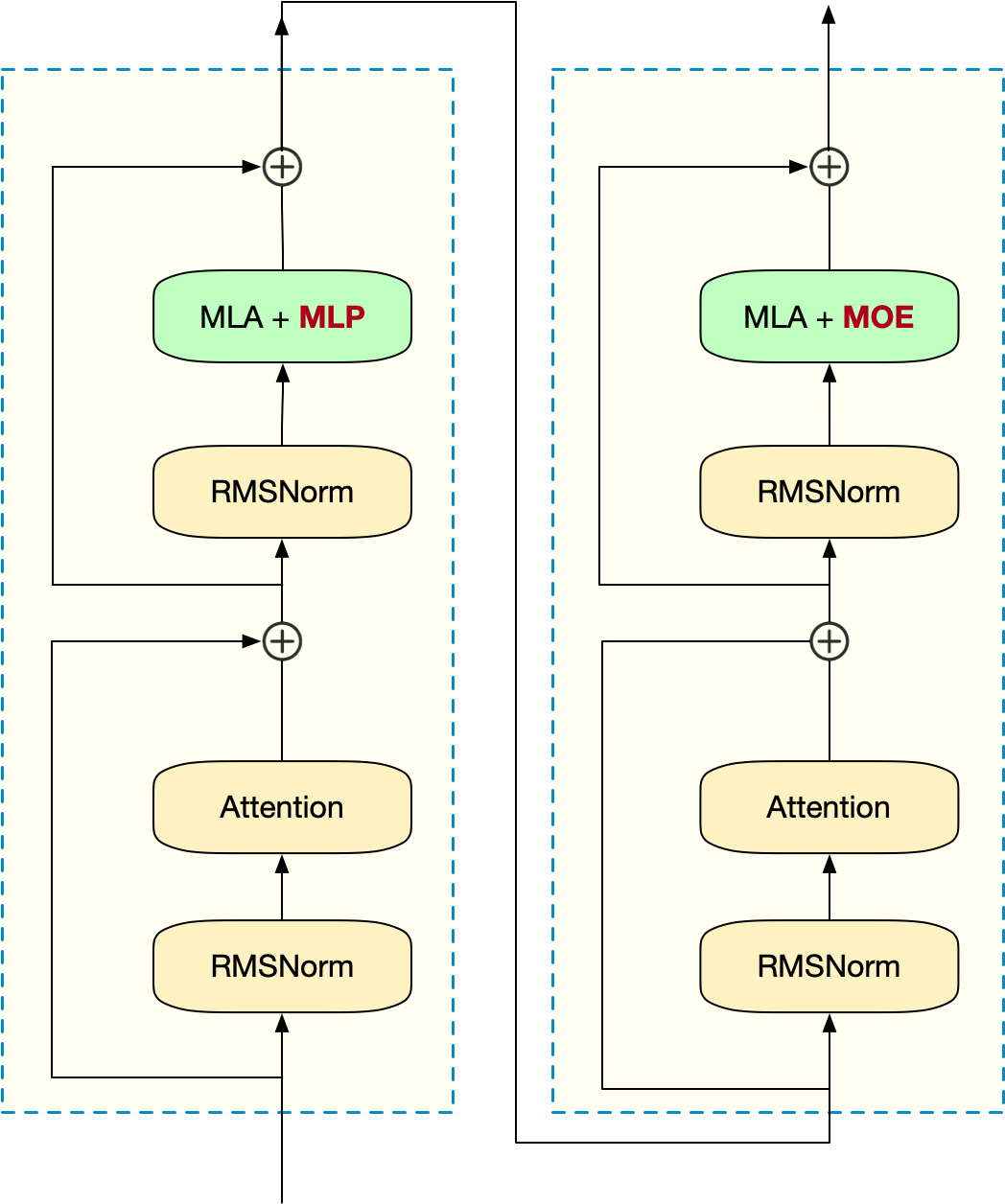
MLP(多层感知机)就不解释细节了,就是:线性变换 + 激活 的组合。
3.1.3 MLA类
MLA 是提出的新改进的注意力机制,旨在显著减少推理时的 KV 缓存(Key-Value Cache)占用,同时保持甚至超越传统多头注意力(MHA)的性能,在 DeepSeek-V2 报告中有阐述原理:https://arxiv.org/pdf/2405.04434v5
MLA 的架构:
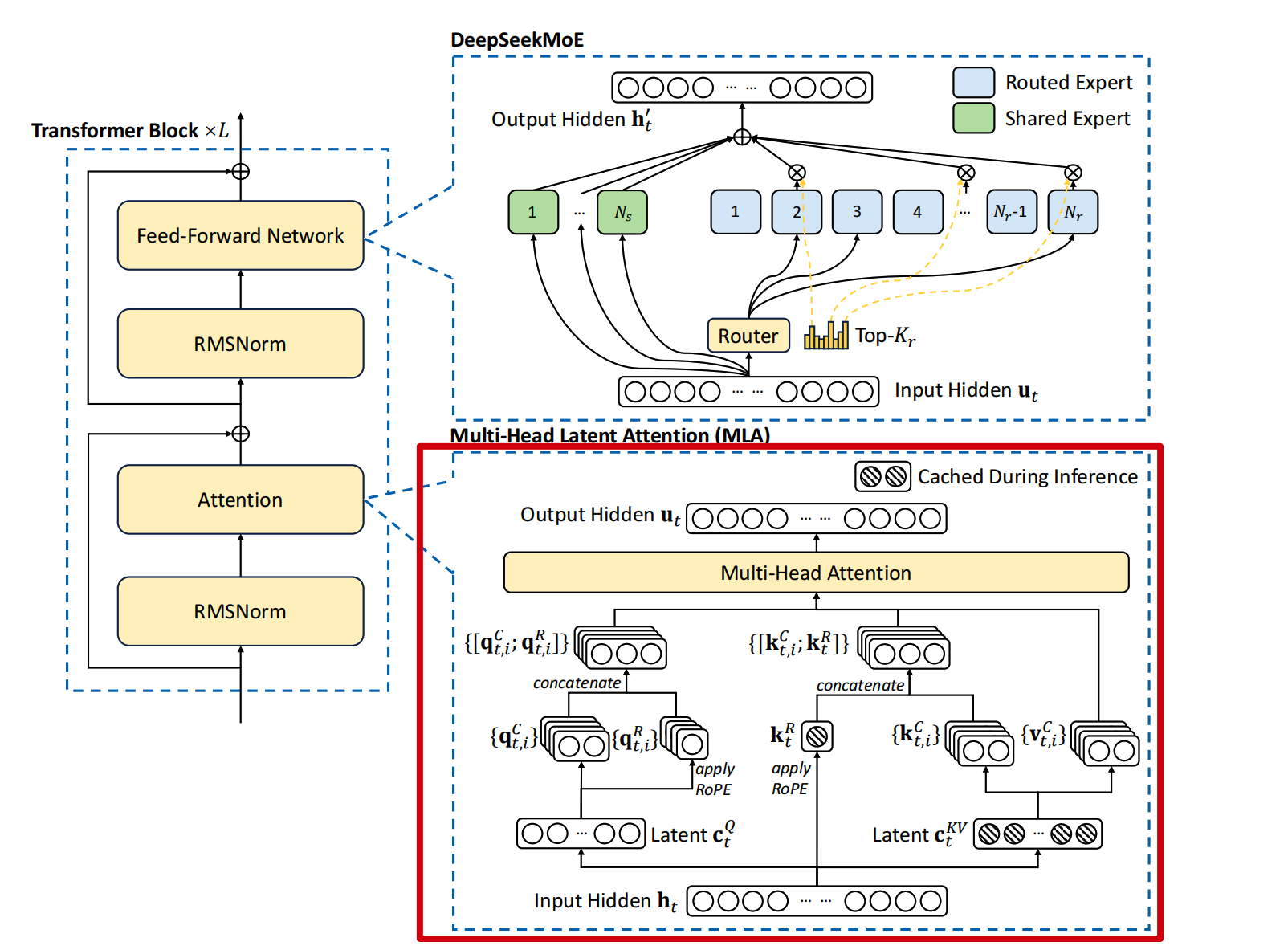
1. MLA 的核心机制
(1)低秩 Key-Value 联合压缩
- 问题背景:传统 MHA 对每个 token 需缓存所有的 Key 和 Value
KaTeX parse error: Unexpected character: '?' at position 33: …athbf{q}_{t} = ?̲?^Q\mathbf{h}_{…
这里需要缓存的就是 k t \mathbf{k}_t kt、 v t \mathbf{v}_t vt,缓存的总元素数为 2 n h d h l 2n_h d_h l 2nhdhl, n d n_d nd 表示头数, d h d_h dh 表示每头的维度, l l l 表示层数,这样导致长序列推理时内存占用激增。
如果你问为什么仅需要缓存 k t \mathbf{k}_t kt、 v t \mathbf{v}_t vt,而不需要缓存 q t \mathbf{q}_t qt,这涉及到 Transformer 的注意力机制的推理细节。Queries 通常是基于当前输入直接生成的,即它们是针对当前时间步或当前位置即时计算出来的,而 Keys 和 Values 是提前计算好的,并且可以在后续的时间步骤或层之间重复使用。不妨可以先关注后续文章再展开说明。
- 解决方案:MLA 通过低秩投影将 Key 和 Value 联合压缩到潜在空间,类似 LoRA 的思想:
c t K V = W D K V h t k t C = W U K c t K V v t C = W U V c t K V \begin{align} \mathbf{c}_{t}^{KV} = W^{DKV} \mathbf{h}_t \\ \mathbf{k}_{t}^{C} = W^{UK} \mathbf{c}_{t}^{KV} \\ \mathbf{v}_{t}^{C} = W^{UV} \mathbf{c}_{t}^{KV} \end{align} ctKV=WDKVhtk
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 337
337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











