




 本文介绍了统计学基本原理,包括测量尺度、均值、中位数、众数及离散趋势的衡量。深入探讨了统计推断,如卡方检验、t检验和方差检验在假设检验中的应用,讲解了其重要性和应用场景。此外,还提到了抽样方法和数据分析的目的。
本文介绍了统计学基本原理,包括测量尺度、均值、中位数、众数及离散趋势的衡量。深入探讨了统计推断,如卡方检验、t检验和方差检验在假设检验中的应用,讲解了其重要性和应用场景。此外,还提到了抽样方法和数据分析的目的。
目录
数据分析的目的1:对历史数据的分析,分析历史数据为什么呈现这样的特征
2:用历史总结的经验来预测未来
可用的手段:1、描述性统计 2、推断性统计

人工智能3大领域:统计学、机器学习、深度学习
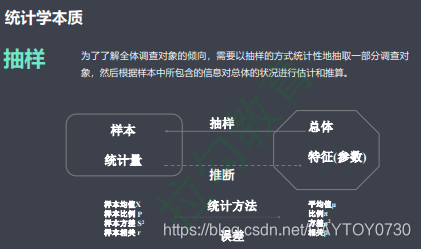
第一节 数据分析相关概念
一、测量尺度
1、定类(nominal)
功能:分类作用,比如性别
2、定序 (ordinal)
功能:分类、排序作用,比如喜欢的艺人、年级
3、定距(不止可以分类、排序,还可以加减,但是不能乘除)
功能:分类、排序、加减,比如温度
4、定比(scale)
功能:分类、排序、加减、乘除,比如年龄
定距和定比相比,一般没有绝对零点
定类与定序合成分类变量,定距与定比合成连续变量。
分类变量的描述统计方法只能用频次统计,连续变量的描述统计方法既可以用频次统计,也可以均值、标准查。

二、均值
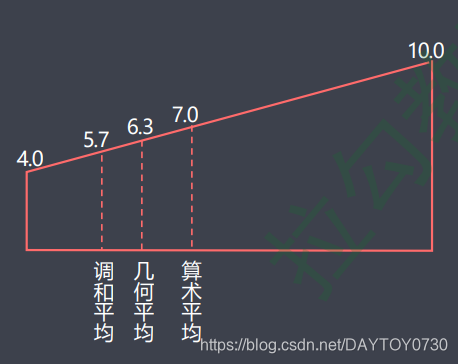
算术平均
几何平均,针对率或者比例这类数值要计算多个数值均值时,正常0-1之间,必须是正数。在计算多年的平均增长率时还会遇到一个指标,复增长率。
调和平均,可能用在数据中较多数值聚集在最小值附近(右偏:波峰在左边),原因可能是因为调和平均相对于算术平均、几何平均更小。
调整平均(或称trim平均),可以去除一定比例(通常是5%)的最大值和最小值的原因是:因为这些值很可能是异常值。
三、中位数、众数
1、中位数:当一组序列数据之间差异较大时,导致平均值代表性较弱,可通过中位数来表示数据的集中趋势。
2、平均值、中位数通常应用在连续变量中,既数值型变量;众数即可以应用在连续变量中也可以应用在分类变量中。
ps:波峰在右边就是左偏,波峰在左面就是右偏
四、极差和标准差
衡量离散趋势,数据离散趋势代表了数据中包含的信息量。

1、如果希望比较两组数据的离散趋势,不能直接比较两组数据的标准差,因为两组数据的数量和均值不同。通常选用离散系数来进行比较。
离散系数:标准差/均值,其实就是除以一个量纲,量纲就是均值。
2、标准差计算公式中有的除以n,有的除以n-1,但计算总体数据标准差时除以n,通过样本数据计算总体标准差时除以n-1,原因是人为增大标准差,以提高代表性。
第二节 统计推断/假设检验
1、大数定律、中心极限定理
大数定律:样本n越大,样本均值几乎必然等于均值
中心极限定理:当样本N逐渐趋于无穷大时,N个抽样样本的均值的频次逐渐趋于正态分布
标准差与标准误区别:
&nbs
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3520
3520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









