




 本文概述了机器学习的基本任务,包括分类、回归、重写等,并详细介绍了主成分分析(PCA)这一常用降维方法。PCA通过将数据投影到包含最多信息量的新坐标系中,有效降低数据维度,减少计算量,提高对噪声的鲁棒性。
本文概述了机器学习的基本任务,包括分类、回归、重写等,并详细介绍了主成分分析(PCA)这一常用降维方法。PCA通过将数据投影到包含最多信息量的新坐标系中,有效降低数据维度,减少计算量,提高对噪声的鲁棒性。
机器学习的理论部分学习知识点比较乱且杂。我这里通过几篇文章,简单总结一下自己对机器学习理论的理解,以防遗忘。第一篇文章主要概述了机器学习的基本任务以及一个常用的降维方法,主成分分析。
机器学习的基本任务
机器学习能实现许多不同的任务,基本分为以下几类:
- 分类 : 算法需要判断输入属于哪一种类别。例如通过一张人像图片判断人的身份。
- 回归 : 算法需要将一个数值与输入联系起来。例如通过气象学的
参数判断24小时的温度。 - 重写 : 通过观察输入,将其重写为文字形式。例如通过一张谷歌街道的图片,识别街道的名称。
- 翻译 : 将一系列的符号文字转化为另一种语言的符号和文字。例如将英语翻译成中文,将Java代码翻译为对应的C++代码。
- 异常寻找: 判断输入是不是非典型的。例如检测是否有逆行的车辆。
- 合成 : 生成与样本数据类似的新的样本。例如合成另一个角度的风景图。
- 降噪 : 对样本数据进行降噪处理。
协方差矩阵
协方差矩阵用于描述各个维度之间的联系,其元素是各个向量元素之间的协方差。
例如如果我们我们有N个维度为n的向量数据xix_ixi,他们的协方差矩阵如下
Σ=1N∑i=1N(xi−μ)(xi−μ)T\Sigma = \frac{1}{N}\sum_{i=1}^{N}(x_i-\mu)(x_i-\mu)^TΣ=N1i=1∑N(xi−μ)(xi−μ)T
其中μ\muμ是数据xix_ixi的平均向量。协方差矩阵维度为n*n且对称。协方差矩阵中编码了数据各个维度之间的相互关系,以及各个维度的方差。例如在n=2,二维平面中,协方差矩阵可以表示为 :
Σ=(σxx σxyσyx σyy)
\Sigma =
\left(
\begin{matrix}
\sigma_{xx}\space\space \sigma_{xy}\\
\sigma_{yx}\space\space\sigma_{yy}
\end{matrix}
\right)
Σ=(σxx σxyσyx σyy)
主对角线描述了该维度上数据的方差,副对角线描述了各个维度之间的协方差,当各个维度处于相同数量级时可以一定程度上反应各个维度之间的相关性。
主成分分析
现实生活中的样本数据的分布可能与很多的潜在因素有关,因此使得我们的数据往往呈现出高维的形式。高维度的数据会对我们进行数据分析造成很多干扰,例如在我们进行分类分析时,随着样本容量的不断增大,维度越高,计算量将呈几何倍数的增长且难以避免的会有噪声的影响。因此如何降维也是数据预处理十分重要的步骤。其中,主成分分析可以有效地降低样本数据的维度,减少计算量的同时使得样本数据对噪音干扰更不敏感。
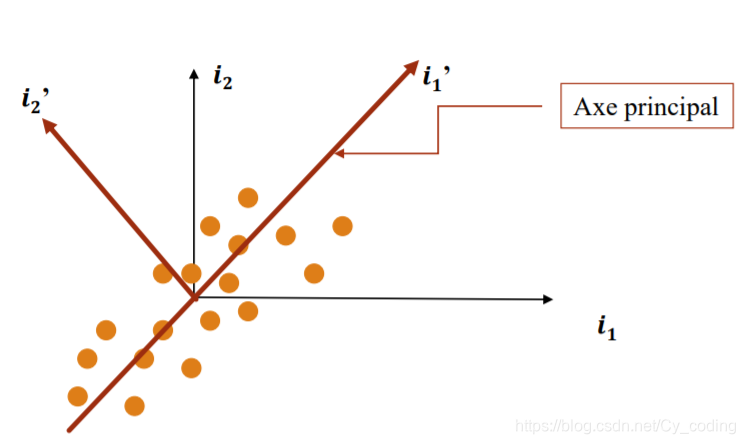
主成分分析 principal component analysis, 其中心思想是将高维度的数据,投影到低维度,以此来实现降维。例如下图中,将原本的二维空间(O,i1i_1i1,i2i_2i2)中的数据,投影到向量i1′i{_1}'i1′上。主成分分析的要点,即是将数据投影到新的坐标系中,其中坐标系的前几个基底向量应该包含样本数据最多的信息量。在进行主成分分析之间,要对数据进行预处理,中心化规格化数据,即对每个数据作减去平均值并除以标准差的操作。
主成分分析的数学表示如下:
对于每个在原始坐标系中的数据点xix_ixi,xi=xi1i1+xi2i1+...+xini1x_i = x_{i1}i_1 + x_{i2}i_1 +... +x_{in}i_1xi=xi1i1+xi2i1+...+xini1,其中xinx_{in}xin是xix_ixi在各个维度的分量。将数据投影到新的坐标轴i1′i{_1}'i1′后,新的坐标为xi1′=xiTi1′x{_{i1}}' = x{_i}^Ti{_1}'xi1′=xiTi1′。数据集沿着新的坐标轴i1′i{_1}'i1′的方差计算如下:
σ=1N∑i=1Nxi1′2=1N∑i=1Nxi1′Txi1′=1N∑i=1Ni1′TxixiTi1′\sigma = \frac{1}{N}\sum_{i=1}^{N}x{_{i1}}'^2 = \frac{1}{N}\sum_{i=1}^{N}x{_{i1}}'^Tx{_{i1}}' = \frac{1}{N}\sum_{i=1}^{N}i{_1}'^Tx_ix_{i}^Ti{_1}' σ=N1i=1∑Nxi1′2=N1i=1∑Nxi1′Txi1′=N1i=1∑Ni1′TxixiTi1′
=1Ni1′T(∑i=1NxixiT)i1′ = \frac{1}{N}i{_1}'^T (\sum_{i=1}^{N}x_ix_i^T)i{_1}'=N1i1′T(i=1∑NxixiT)i1′
σ=i1′TΣi1′\sigma = i{_1}'^T\Sigma i{_1}' σ=i1′TΣi1′
其中 Σ\SigmaΣ 是协方差矩阵 Σ=1N(∑i=1NxixiT)\Sigma = \frac{1}{N}(\sum_{i=1}^{N}x_ix_i^T)Σ=N1(i=1∑NxixiT)
在进行主成分分析时,我们假设某一维度所包含的信息量,与该维度数据的方差是呈正相关的,因此主成分分析问题就转化成了最大值问题,使用拉格朗日乘数法,找到使方差最大化的剩余维度:
L=i1′TΣi1−λ(i1′Ti1′−1)L = i{_1}'^T \Sigma i_1 - \lambda(i{_1}'^T i{_1}' - 1)L=i1′TΣi1−λ(i1′Ti1′−1)
∂L∂i1′=0即Σi1′=λi1′\frac{\partial L}{\partial i{_1}'} = 0 即 \Sigma i{_1}' = \lambda {i_1}'∂i1′∂L=0即Σi1′=λi1′
其中,i1′i{_1}'i1′ 和 λ\lambdaλ 分别是数据协方差矩阵的特征向量和对应的特征值。第一个投影维度对应协方差矩阵的第一个特征向量(特征值最大的特征向量)。第二个投影维度对应第二个特征向量以此类推,我们可以得到一组对应特征值递减的特征向量。通过选出协方差矩阵的前K个特征向量,我们就能选出包含信息量最大的主成分维度,实现对原始数据的降噪,排除掉高维度的干扰,使得后续的数据分析成果更稳定。
Tips : 协方差矩阵是对称构成的且至少是半正定矩阵,因此其所有的特征向量都是实数,所有的特征值都是正数或0,所有的特征向量互相垂直不相关。

















 52
52

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









