




 本文深入探讨了向量数据结构的实现原理,包括构造与析构过程,向量的加倍式扩容策略及其分摊成本分析,有序向量的唯一化算法及二分查找的复杂度分析。
本文深入探讨了向量数据结构的实现原理,包括构造与析构过程,向量的加倍式扩容策略及其分摊成本分析,有序向量的唯一化算法及二分查找的复杂度分析。
(a)接口与实现
//构造函数:
Vector(int c=DEFAULT_CAPACITY, int s = 0, T v=0)
{
_elem = new T[_capacity =c];//_capacity为实际物理容量,_size为当前大小
//复制构造函数,使用指针而并非引用
Vector(T const *A,Rank lo,Rank hi){copy_from(A,lo,hi);}
for(_size=0;_size<s;_elem[_size++]=v)}
//析构函数:
~Vector(){delete [] _elem;}
//copy_from函数的实现:
template <typename T>
void copy_from(T const *A,Rank lo,Rank hi){
_elem = new T[_capacity=2*(lo-hi)];//开辟两倍需要复制长度大小的内存空间
_size=0;
while(lo<hi)
_elem[_size++] = A[lo++];
}
(b)向量的加倍式扩容
向量的加倍式扩容的分摊成本为
O
(
1
)
O(1)
O(1)

注:图中每次只插入一个元素,连续插入2^m个元素
分摊分析:对数据结构实时连续的足够多次的操作,所需的成本分摊到单次操作
(c )有序向量
有序向量的唯一化
方法:从第i个元素开始,往后查找首个不相等元素第j,将第j个元素移动到i+1位,然后再从第i+1位开始往复,直到j=_size,此时向量长度为i+1,重复元素个数为j-i
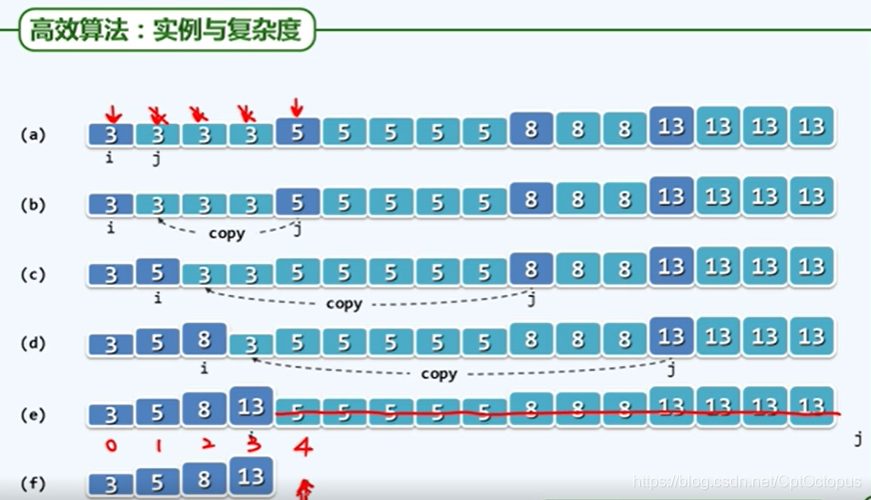
template <tupename T> int Vrctor<T>::uniquify(){
Rank i=0,j=0;
while(++j<_size)
if(_elem(i)!=_elem[j])//跳过雷同者
_elem[++i]=_elem[j];
_size=++i;shrunk();//剔除末尾的元素
return j-i
}
有序向量的二分查找
语义约定:有便于有序向量自身的维护:V.insert(1+V.search(e),e)
1)即便新元素查找失败,也应该给出新元素适当的插入位置
2)若允许重复元素,则每一组重复元素也需按照插入次序排序
约定:在有序向量V[lo,hi)中,确定不大于e的最后一个元素,取该元素的后一位作为插入位置
若e过小,则返回lo-1;若e过大,则返回hi-1

static rank binSearch(T *A,T const& e,Rank lo,Rank hi)
{
while(lo<hi){
Rank mi=(lo+hi)>>1;
if (e<A[mi]) hi=mi;
else if(A[mi]<e) lo=mi+1;
else return mi;
}
return -1;
}
复杂度分析:
先行递归
T
(
n
)
=
T
(
n
/
2
)
+
O
(
1
)
T(n)=T(n/2)+O(1)
T(n)=T(n/2)+O(1),
O
(
1
)
O(1)
O(1)表示每次只需要进行1到2次的常数次比较
递归跟踪:轴总取中点,各实例递归耗时O(1),总递归数量
l
o
g
n
logn
logn,所以递归深度
O
(
l
o
g
n
)
O(logn)
O(logn)
考察关键码的比较次数,即查找长度(search lenght):
查找成功和失败的两种情况平均查找长度大致为
O
(
1.5
l
o
g
n
)
O(1.5logn)
O(1.5logn)

往左的时候只需要一次对比,往右需要两次,因为程序中是先对比左边,若不满足再对比右边的。最底层(d)表示失败的情况

















 831
831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









