




 本文深入探讨了数据结构中的向量概念,包括Fibonacci查找、二分查找的改进与完美版本,以及插值查找的高效算法。同时,详细介绍了起泡排序的优化与完美实施,以及归并排序的递归实现,提供了丰富的代码实例。
本文深入探讨了数据结构中的向量概念,包括Fibonacci查找、二分查找的改进与完美版本,以及插值查找的高效算法。同时,详细介绍了起泡排序的优化与完美实施,以及归并排序的递归实现,提供了丰富的代码实例。
有序向量Fibonacci查找
在二分查找中,左右分支关键码比较次数不同,而递归深度却相同,所以考虑让右分支尽可能短,即右分支递归深度尽可能浅

设向量总长度为某个Fabonacci数减一 ,
n
=
f
i
b
(
k
)
−
1
n=fib(k)-1
n=fib(k)−1,则可取mi=fib(k-1)-1,此时前、后字向量的长度分别为fib(k-1)-1,fib(k-2)-1
template <typename T>
static Rank fibsearch(T* A,T const &e,Rank lo,Rank hi){
Fib fib(hi-lo);//创建不小于hi-lo的最小fib项
while(lo<hi){
while(hi-lo<fib.get()) fib.prev();//while后fib值为n+1,prev后fib值为前一个fib数
//通过前向查找,确定形如Fib(k)-1的轴点
Rank mi = lo+ fib.get()-1;
if(e<A[mi]) hi=mi;
else if(A[mi]<e) lo=mi+1;
else return mi;
}
}
return -1;
class Fib{
private:
int f,g;
public:
Fib(int n)//构造不小于n的最小项fib数
{f=1;g=0;while(g<n) next();}
int get(){return g;}
int next(){g=g+f;f=g-f;return g;}
int prev(){f=g-f;g=g-f;return g;}
}
Fabonacci查找最优证明:
对于A[0,b),总选取A[
λ
\lambda
λn]作为轴点
二分法对应
λ
=
0.5
\lambda=0.5
λ=0.5,Fib法对应
λ
=
0.618...
\lambda=0.618...
λ=0.618...
设平均查找长度为
α
(
λ
)
\alpha(\lambda)
α(λ)

有序向量二分查找(改进版)
将等于mi的情况并入右分支,使得左右两边平衡。在最好的情况下性能有损失,但是在最坏的情况下性能有进步
static rank binSearch(T *A,T const& e,Rank lo,Rank hi)
{
while(1<hi-lo){
Rank mi=(lo+hi)>>1;
(e<A[mi]) ? hi=mi:lo=mi;
}
return (e==A[lo])? lo:-1;
}
有序向量二分查找(完美版)
满足语义要求和向量的自身维护
不考虑mi,只考虑[lo,mi)和(mi,hi)两个区间
需要等到考察区间变为0,即lo=hi时算法结束,此时A[lo]必大于e,A[- -lo]为不大于e的最后一个元素

static rank binSearch(T *A,T const& e,Rank lo,Rank hi)
{
while(lo<hi){
Rank mi=(lo+hi)>>1;
(e<A[mi])? hi=mi:lo=mi+1
}
return --lo; //注意应返回--lo
}
有序向量插值查找
当有序向量元素均匀且独立分布,比如查英文字典查y开头的单次要大概从24/26开始查


平均情况:每经过一次比较,问题规模
n
n
n缩减至
n
\sqrt n
n,最后复杂度为O(loglogn)。因为对于n开根号相当于对于n的二进制的折半,即
n
=
=
1
/
2
l
o
g
2
n
\sqrt n == 1/2log_2n
n==1/2log2n,所以插值查找相当于对n的二进制位进行二分查找,而n的二进制位总位数为
l
o
g
n
logn
logn,所以最终复杂度为O(loglogn)
插值查找通常优势不大,除非查找宽度极大或者比较操作成本极高。
实际可行的操作为:先通过插值查找,将数据规模缩小到一定范围,在进行二分查找
对于有序向量,大规模:插值查找 中规模:折半查找 小规模:顺序查找
起泡排序(优化版)
起泡排序作逐趟扫描,每扫描一趟最末尾就多一个最大值
改进版本:考虑未完成扫描的部分可能也有序,不需要再进行扫描,即在扫描过程中加入sorted = false;
template <typename T> void Vector<T>::BubbleSort(Rank lo,Rank hi)
{while(!bubble(lo,hi--));}
template <typename T> bool Vector<T>::Bubble(Rank lo,Rank hi)
{
bool sorted = true;
while(++lo<hi)
if(_elem[lo-1]>_elem[lo])//只要有一对顺序不对,则需要交换
sorted = false;//若未排序部分不存在顺序错误,则可结束排序
swap(_elem[lo-1],_elem[lo]);
}
return sorted;
起泡排序(完美版)
记录上一趟扫描中交换的最后一个元素设为last,该元素之后的全为已排序好的,然后把hi移到last元素位置,则下一轮扫描从last开始
template <typename T> void Vector<T>::BubbleSort(Rank lo,Rank hi)
{while(lo<(hi = bubble(lo,hi));}
template <typename T> Rank Vector<T>::Bubble(Rank lo,Rank hi)
{
Rank last;
while(++lo<hi)
if(_elem[lo-1]>_elem[lo])//只要有一对顺序不对,则需要交换
sorted = false;//若未排序部分不存在顺序错误,则可结束排序
last=_elem[lo]
swap(_elem[lo-1],_elem[lo]);
}
return last;
复杂度:做好情况 O ( n ) O(n) O(n),最坏情况 O ( n 2 ) O(n^2) O(n2)
归并排序
将向量以中点为分界分为两个子序列,然后再对子序列继续划分,这种划分在程序中表现为递归调用,然后再将有序的各个子序列合并成一个序列
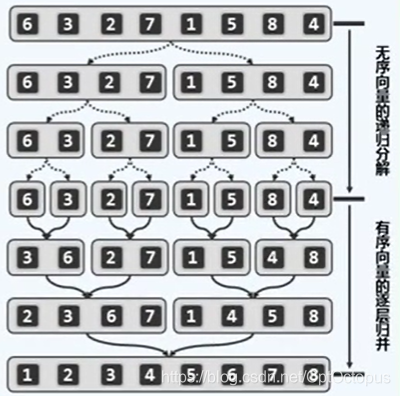
程序思路:使用递归,在mergsort排序函数中将向量一分为二,然后在merge子函数中将排序好的两个向量合并。
merge子函数:A为要排序的向量,另外构建B,C两个向量分别为A的前后半段,然后对B和C分别排序以后再合并

//归并过程:
template<typename T> viod Vector<T>::merge(Rank lo,Rank mi,Rank hi)
{
T *A= _elem +lo;
int lb= mi-lo; T* B=new T[lb];/开辟空间存放A的前半段在B
for(Rank i=0;i<lb;B[i]=A[i++]) ;//赋值B
int lc=hi-mi; T *C = _elem +mi;
for(Rank i=0,j=0,k=0;(j<lb)||(k<lc))){//(j<lb)||(k<lc)表示两边都处理完
if((j<lb)&&(k>lc||B[j]<=C[k])) A[i++]=B[j++];
if((j<lb)&&(j>lb||C[k]<B[J])) A[i++]=C[k++];
//j>lb表示B已越界,此时可以把C的元素直接都赋给A
}
delete B;
}
//归并排序函数递归实现
template<typename T> viod Vector<T>::mergesort(Rank lo,Rank hi){
if(hi-lo<2)return;
int mi=(hi+lo)>>1;
mergesort(lo,mi);
mergesort(mi,hi);
merge(lo,mi,hi);
//本算法为递归算法!!
}
复杂度:merge()中j+k=n,即最多n次循环,循环复杂度为O(n)
可以得到递推式:
T
(
n
)
=
2
∗
T
(
n
/
2
)
+
O
(
n
)
T(n)=2*T(n/2)+O(n)
T(n)=2∗T(n/2)+O(n),求得复杂度
T
(
n
)
=
O
(
n
l
o
g
n
)
T(n)=O(nlogn)
T(n)=O(nlogn)


















 831
831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









