 CTF题目:抄错字符的解码求解
CTF题目:抄错字符的解码求解





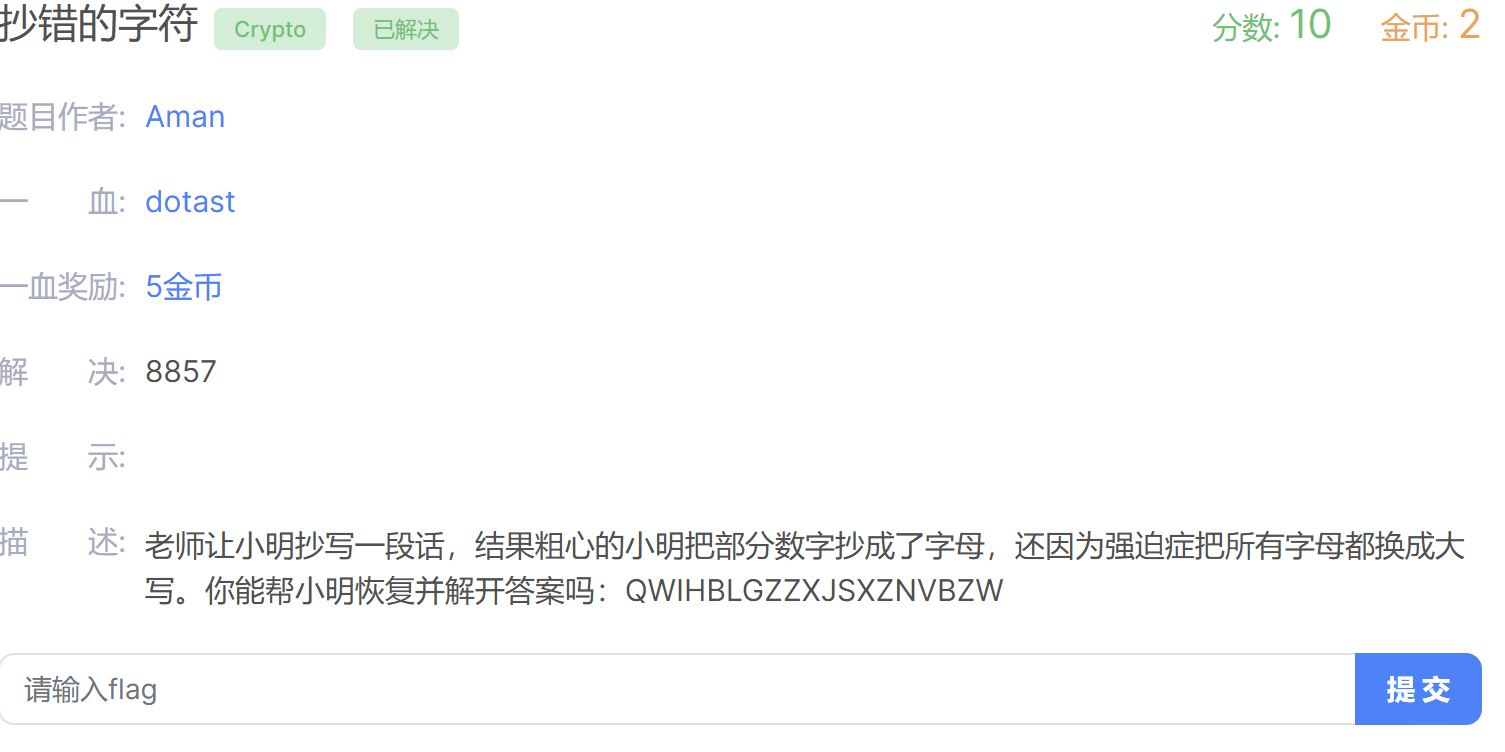
QWIHBLGZZXJSXZNVBZW
题目如上
整体思路:
用随波逐流解码,base64是最接近的,有数字有大小写字母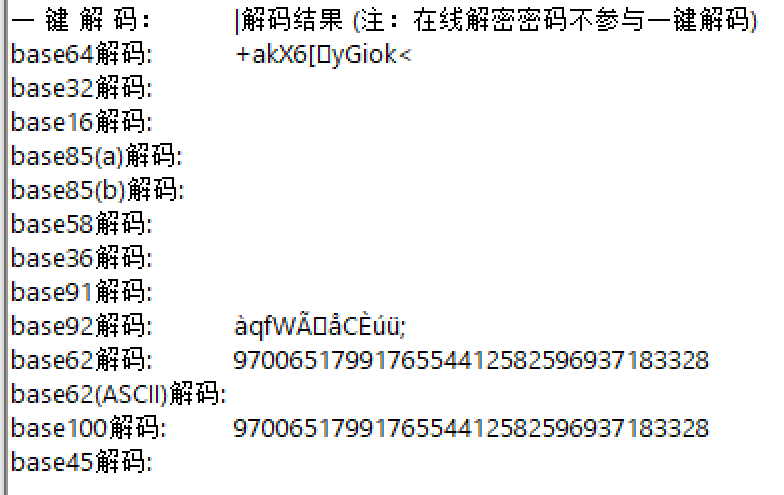
每个字符找到可能的小写、长得像的数字,然后全部重新排列组和,再用base64解码(原字符串为19位,补个=)。解码后判断该字符串是否为有意义的英文单词。
将以上思路告诉deepseek,形成python代码。
第一步:初步解码
将base64解码后的结果导出为文件(后面修改代码就不需要重新跑生成过程了)
import itertools
import base64
cipher = 'QWIHBLGZZXJSXZNVBZW='
dic = {
'Q': ['Q', 'q', '9'],
'W': ['w', 'W'],
'I': ['I', 'i', '1'],
'H': ['H', 'h'],
'B': ['B', 'b', '8'],
'L': ['L', 'l', '1'],
'G': ['G', 'g', '9'],
'Z': ['Z', 'z', '2'],
'X': ['X', 'x'],
'J': ['J', 'j'],
'S': ['S', 's', '5'],
'N': ['N', 'n'],
'V': ['V', 'v'],
'=': ['=']
}
combine = []
file_path = "./output.txt"
# 打开文件(追加模式),确保文件关闭由 with 管理
with open(file_path, 'a', encoding='utf-8') as f:
# 遍历所有可能的组合
for possible in itertools.product(*[dic[char] for char in cipher]):
possible_str = ''.join(possible) # 组合成字符串
try:
# 尝试 Base64 解码
decoded_bytes = base64.b64decode(possible_str)
decoded_str = decoded_bytes.decode('utf-8') # 转换成字符串
# 存入 combine
combine.append(decoded_str)
print("存入" + decoded_str)
# 立即追加写入文件
f.write(decoded_str + '\n') # 每个字符串后加换行符
f.flush() # 确保立即写入磁盘(可选)
except (base64.binascii.Error, UnicodeDecodeError):
# 如果解码失败(非法 Base64 或非 UTF-8 编码),跳过
continue
第二步:识别有意义的英文单词
import enchant
import re
def filter_lines_with_english_words(input_file, output_file):
# 初始化英文词典
d = enchant.Dict("en_US")
# 统计变量
total_count = 0
valid_count = 0
# 打开输入文件和输出文件
with open(input_file, 'r', encoding='utf-8') as infile, \
open(output_file, 'w', encoding='utf-8') as outfile:
for line in infile:
total_count += 1
line = line.strip()
# 跳过空行
if not line:
continue
# 检查行中是否包含有效英文单词
contains_valid = False
# 使用正则表达式分割出可能的单词
for word in re.findall(r"[a-zA-Z']+", line):
if len(word) > 1 and d.check(word): # 忽略单字母"单词"
contains_valid = True
break
if contains_valid:
outfile.write(line + '\n')
valid_count += 1
print(f"'{line}': 包含有效英文单词 → 已写入{output_file}")
else:
print(f"'{line}': 不包含有效英文单词")
# 输出统计信息
print(f"\n处理完成!共检查 {total_count} 行,其中 {valid_count} 行包含有效英文单词")
print(f"结果已保存到: {output_file}")
# 使用示例
input_file = "output.txt" # 输入文件路径
output_file = "vaild.txt" # 输出文件路径
filter_lines_with_english_words(input_file, output_file)
第三步:根据结构找共同点,用正则表达式定位
可能存在有意义单词的字符串长这样,得到25000+的数据
可以看到还不太正常,这时候需要进一步整理,筛选只由字母和下划线构成的字符串
import re
def is_all_alpha_substrings(line):
"""检查一行是否满足:被下划线分隔的所有子串都是纯字母"""
line = line.strip()
if not line: # 跳过空行
return False
# 使用下划线作为分隔符
substrings = re.split(r'_+', line) # 匹配一个或多个连续下划线
# 检查每个子串是否都是纯字母(长度至少1)
return all(sub.isalpha() and len(sub) >= 1 for sub in substrings if sub)
def filter_lines(input_file, output_file):
"""过滤文件内容,将符合条件的行写入新文件"""
with open(input_file, 'r', encoding='utf-8', errors='replace') as infile, \
open(output_file, 'w', encoding='utf-8') as outfile:
total = passed = 0
for line in infile:
total += 1
if is_all_alpha_substrings(line):
outfile.write(line)
passed += 1
print(f"保留: {line.strip()!r}") # !r显示原始格式
else:
print(f"过滤: {line.strip()!r}")
print(f"\n处理完成!共处理 {total} 行,保留 {passed} 行")
print(f"结果已保存到: {output_file}")
# 使用示例
filter_lines("vaild.txt", "words.txt")
最终得到240条有效数据

合理推断,可能是 xx_very_cool 的组合,用notepad++正则表达式匹配并复制高亮文本,得到结果
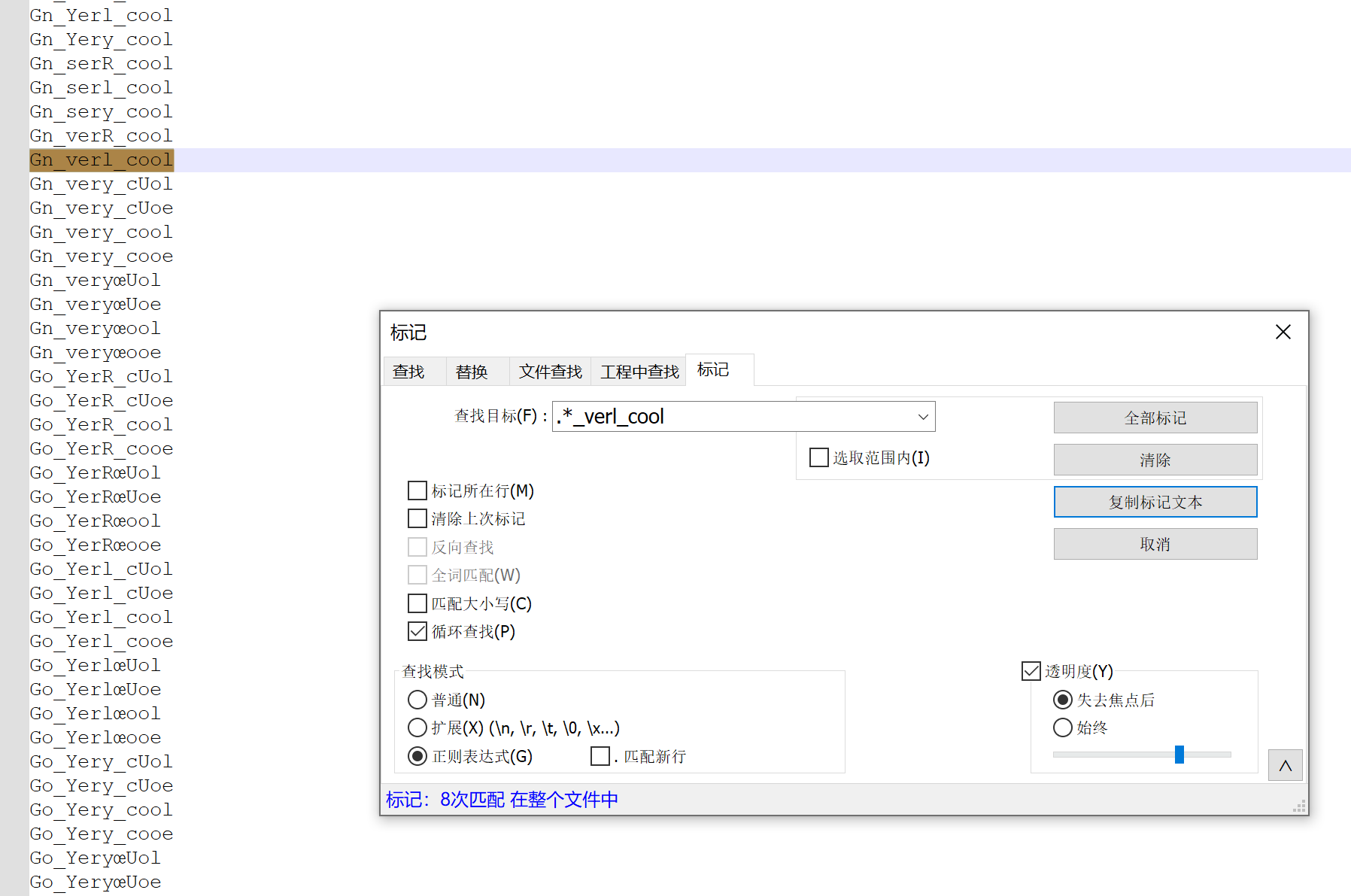
最终得到8条有效数据,挨个提交
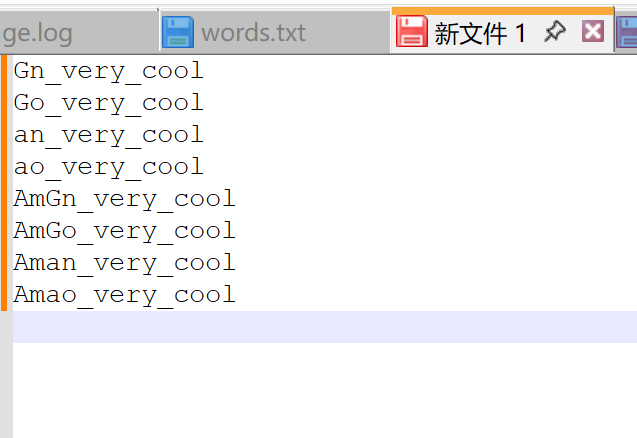
最终答案
flag{Aman_very_cool}

















 5189
5189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









