



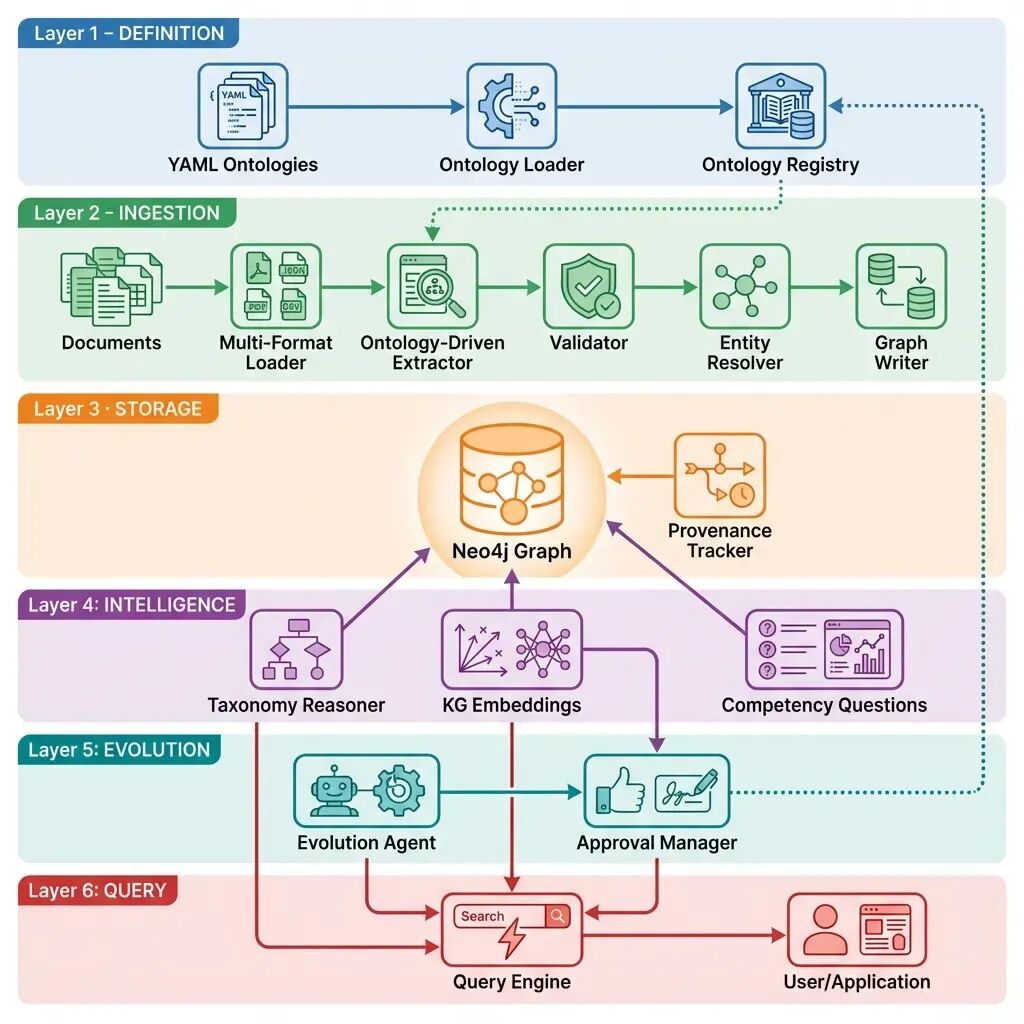
一、本体驱动的 GraphRAG:零噪声知识抽取框架
构建一条能够自我改进的知识图谱:它不仅存储数据,更能理解、验证并持续演化这些数据。

最近看到了一篇很好的文章,这里分享给大家,见文末,感兴趣大家可以动手自己尝试下,应该有不错的收获。
当我第一次搭建 GraphRAG 系统时,我照搬了大多数教程的做法:把文档丢给大模型,让它抽取实体,把 JSON 塞进 Neo4j,然后收工。在 Demo 里,这套流程无懈可击。但当我把它搬到真实的医疗记录上时,问题接踵而至。
大模型从一份报告中抽出了“John Doe, 45”,又从另一份报告中抽出了“John Doe, age 45”,结果生成了两个不同的患者节点。它在文档 A 中识别出“Type 2 Diabetes”,在文档 B 中识别出“T2D”,于是同一种疾病出现了三个不同的节点。剂量“500 mg 每日两次”则完全丢失,因为简单的 (Patient)-[PRESCRIBED]->(Medication) 边根本没有地方存放这些细节。
处理完一千份临床报告后,我的“知识图谱”充斥着重复、不一致和缺失的数据。当一位医生想追溯某个诊断的来源时,我无言以对。系统无法告诉他这份事实来自哪份文档、哪次抽取,甚至无法确定是哪一个版本的大模型生成了这条信息。
这就是朴素 GraphRAG 实现的真实写照:在受控 Demo 中表现完美,却在现实复杂性面前土崩瓦解。本文将介绍我如何通过构建本体操作系统(Ontology Operating System)——一套完整的生命周期管理系统——把杂乱无章的文本转化为干净、可审计、可自我改进的知识。
二、问题所在:为何大多数知识图谱在生产环境中失败
让我们具体看看哪里出了问题。假设你正在摄取以下临床记录:
“患者 John Doe,45 岁,诊断为 2 型糖尿病。2024-01-15,Smith 医生开具处方:二甲双胍 500 mg,每日两次。”
朴素的 GraphRAG 流水线会抽取出:
- • 实体:“John Doe”(类型:Person?Patient?Name?)
- • 实体:“45”(类型:Age?Number?String?)
- • 实体:“Type 2 Diabetes”(下一份文档写“Diabetes Type 2”——又是不同节点!)
- • 关系:
(John Doe)-[PRESCRIBED]->(Metformin)(“500 mg”“每日两次”“Smith 医生”“2024-01-15”都去哪儿了?)
处理完一万份文档后,你将得到:
- 重复实体:“John Doe”“John Doe, 45”“Patient John Doe”
- 类型不一致:“45”到底是 Age 实体还是属性?
- 上下文丢失:剂量、频次、日期全部消失
- 零可追溯性:哪份文档说 John 得了糖尿病?无从得知
- 无验证机制:大模型幻觉出一条诊断?你永远发现不了
这根本不是知识图谱,而是数据垃圾场。
三、解决方案:本体操作系统
我们构建了截然不同的系统。与其把本体当作一份无人维护的静态 Schema,我们让它成为整个流水线的中枢神经系统。系统不仅定义了存在哪些实体,更控制了抽取过程、强制执行验证、支持推理、追踪来源,并基于使用模式自我演化。
可以把它想象成知识的操作系统。正如 Linux 管理应用程序与硬件的交互,我们的本体 OS 管理数据如何从混乱文本流向干净、可查询的知识图谱。
下面按阶段完整介绍架构,并给出真实代码与示例。
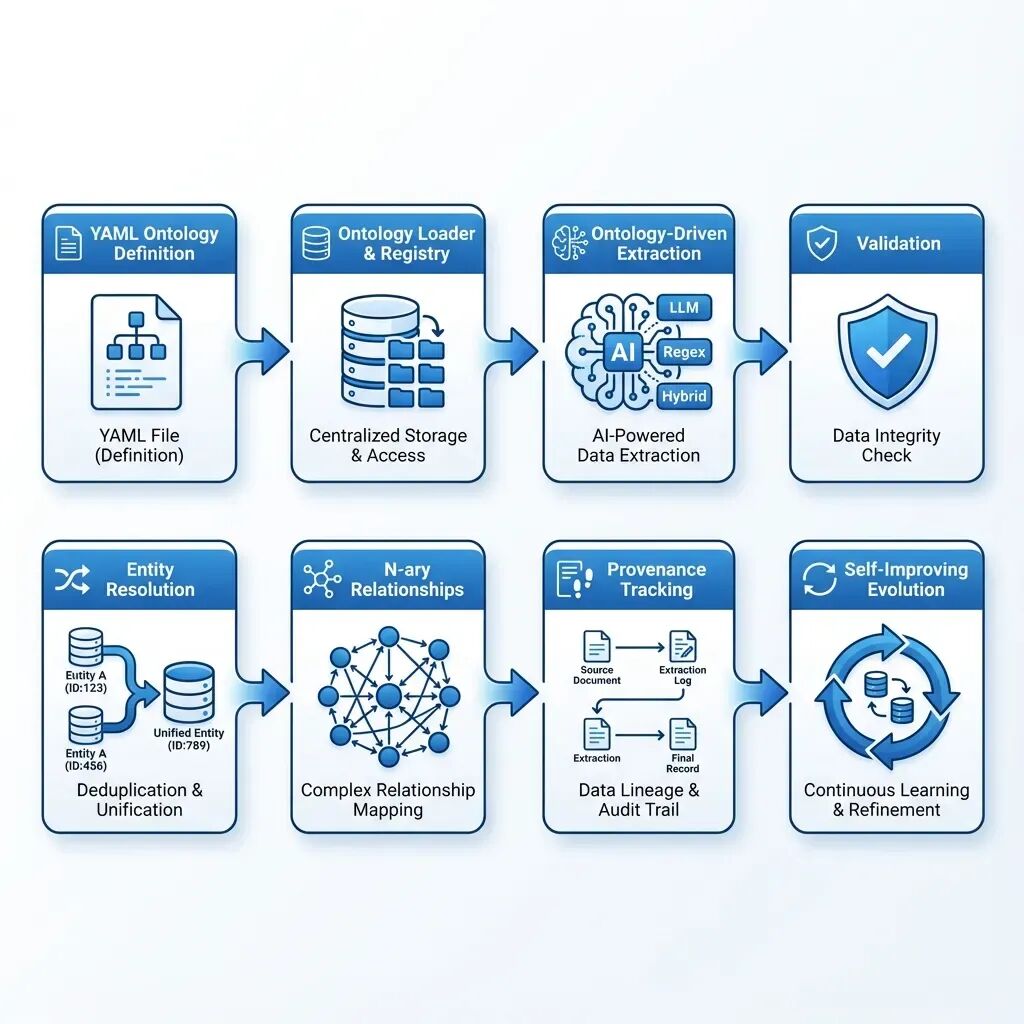
四、阶段 1:蓝图(本体定义)
在处理任何文档之前,我们用人类可读的 YAML 定义规则。这不仅是实体类型清单,更是对医学知识样貌的完整规范。
# medical.yamlmetadata:name:"Medical Ontology"version:"1.0.0"domain:"medical"entity_types:-name:"Patient" description:"接受医疗照护的人" extraction_strategy:"llm"# 复杂抽取交由大模型 properties: -name:"age" data_type:"integer" required:true validation_rules: min_value:0 max_value:120 -name:"patient_id" data_type:"string" required:true validation_rules: pattern:"^P\\d{6}$"# 必须以 P 开头,后跟 6 位数字-name:"Disease" description:"医学疾病或病症" extraction_strategy:"llm" aliases: ["Condition", "Illness", "Disorder"] # 处理同义说法 properties: -name:"icd_code" data_type:"string" validation_rules: pattern:"^[A-Z]\\d{2}(\\.\\d{1,2})?$"# ICD-10 格式 -name:"severity" data_type:"string" validation_rules: allowed_values: ["mild", "moderate", "severe"]-name:"Medication" description:"药物" extraction_strategy:"hybrid"# 大模型 + 正则混合 extraction_patterns: -pattern:"\\b[A-Z][a-z]+\\s+\\d+mg\\b" description:"药品及剂量(如 Metformin 500mg)" properties: -name:"dosage" data_type:"string" required:false -name:"route" data_type:"string" validation_rules: allowed_values: ["oral", "intravenous", "topical"]relationship_types:-name:"DIAGNOSED_WITH" source_types: ["Patient"] target_types: ["Disease"] properties: -name:"diagnosis_date" data_type:"date" required:true-name:"PRESCRIBED" source_types: ["Patient"] target_types: ["Medication"] properties: -name:"frequency" data_type:"string" -name:"prescribed_by" data_type: "string"
请注意我们在做什么:
- 验证规则:年龄必须在 0–120 之间,患者 ID 必须符合
P######格式 - 别名映射:Condition、Illness、Disorder 全部映射到 Disease
- 抽取策略:复杂实体用大模型,结构化模式用正则,混合策略兼顾两者
- 必填属性:诊断必须有日期
- 枚举值:严重程度只能是 mild / moderate / severe
这份 YAML 文件就是我们的契约。任何进入系统的数据都必须遵守,否则被拒绝。
五、阶段 2:加载本体(注册中心)
系统启动时,OntologyLoader 读取这些 YAML 并转换为富 Python 对象。更有趣的是,我们并不只加载一个本体,而是通过**注册中心(Registry)**同时管理多个本体,并具备完整版本控制。
# ontology/loader.pyclassOntologyLoader: def__init__(self, ontologies_dir: str = "ontologies/"): self.ontologies_dir = Path(ontologies_dir) self.loaded_ontologies: Dict[str, Ontology] = {} defload_ontology(self, file_path: str) -> Ontology: """加载并解析 YAML 本体文件""" withopen(file_path, 'r') as f: data = yaml.safe_load(f) # 解析元数据 metadata = OntologyMetadata(**data['metadata']) # 解析实体类型 entity_types = [ EntityTypeDefinition(**et) for et in data['entity_types'] ] # 解析关系类型 relationship_types = [ RelationshipTypeDefinition(**rt) for rt in data['relationship_types'] ] return Ontology( metadata=metadata, entity_types=entity_types, relationship_types=relationship_types )
注册中心以单例模式管理多个本体版本:
## 阶段 3:智能抽取(本体驱动)现在我们准备处理临床报告。真正的“魔法”即将发生。与给 LLM 下达“抽取实体”这类模糊指令不同,我们利用本体构建**精确且领域特定的提示词**。```python# ontology/extractor.pyclass OntologyDrivenExtractor: def __init__(self, llm: BaseChatModel, ontology: Ontology): self.llm = llm self.ontology = ontology def extract_entities( self, text: str, entity_types: Optional[List[str]] = None ) -> List[Dict[str, Any]]: """使用本体引导的 LLM 提示词抽取实体。""" target_types = entity_types or [et.name for et in self.ontology.entity_types] all_entities = [] for entity_type_name in target_types: entity_type_def = self.ontology.get_entity_type(entity_type_name) if not entity_type_def: continue # 选择抽取策略 if entity_type_def.extraction_strategy == "llm": entities = self._llm_extract_entities(text, entity_type_def) elif entity_type_def.extraction_strategy == "regex": entities = self._regex_extract_entities(text, entity_type_def) elif entity_type_def.extraction_strategy == "hybrid": llm_entities = self._llm_extract_entities(text, entity_type_def) regex_entities = self._regex_extract_entities(text, entity_type_def) entities = self._merge_entities(llm_entities, regex_entities) all_entities.extend(entities) return all_entities def _llm_extract_entities( self, text: str, entity_type_def: EntityTypeDefinition ) -> List[Dict[str, Any]]: """基于本体构建提示词并用 LLM 抽取。""" # 根据本体构建详细提示词 prompt = f"""你是从医学文本中抽取 {entity_type_def.name} 实体的专家。实体类型:{entity_type_def.name}描述:{entity_type_def.description}必需属性:""" for prop in entity_type_def.properties: if prop.required: prompt += f"- {prop.name}({prop.data_type}):{prop.description}\\n" if entity_type_def.aliases: prompt += f"\\n别名:{', '.join(entity_type_def.aliases)}\\n" prompt += f"""请从下方文本中抽取所有 {entity_type_def.name} 实体。返回包含指定属性的 JSON 对象数组。文本:{text}JSON:""" response = self.llm.invoke(prompt) entities = json.loads(response.content) return entities
看出区别了吗?LLM 不再猜测要抽取什么或以何种结构返回。本体正在教会 LLM 理解医学领域:提供示例、指定格式,甚至列出别名,让 LLM 知道 “Condition” 与 “Disease” 是同一概念。
对于我们的临床记录,LLM 返回:
{ "entities":[ { "type":"Patient", "name":"John Doe", "age":45, "patient_id":"P000045" }, { "type":"Disease", "name":"Type 2 Diabetes", "icd_code":"E11.9", "severity":"moderate" }, { "type":"Medication", "name":"Metformin", "dosage":"500mg", "route":"oral" }],"relationships":[ { "type":"DIAGNOSED_WITH", "source":"John Doe", "target":"Type 2 Diabetes", "properties":{"diagnosis_date":"2024-01-15"} }, { "type":"PRESCRIBED", "source":"John Doe", "target":"Metformin", "properties":{ "frequency":"twice daily", "prescribed_by":"Dr. Smith" } }]}
阶段 4:验证(质量关卡)
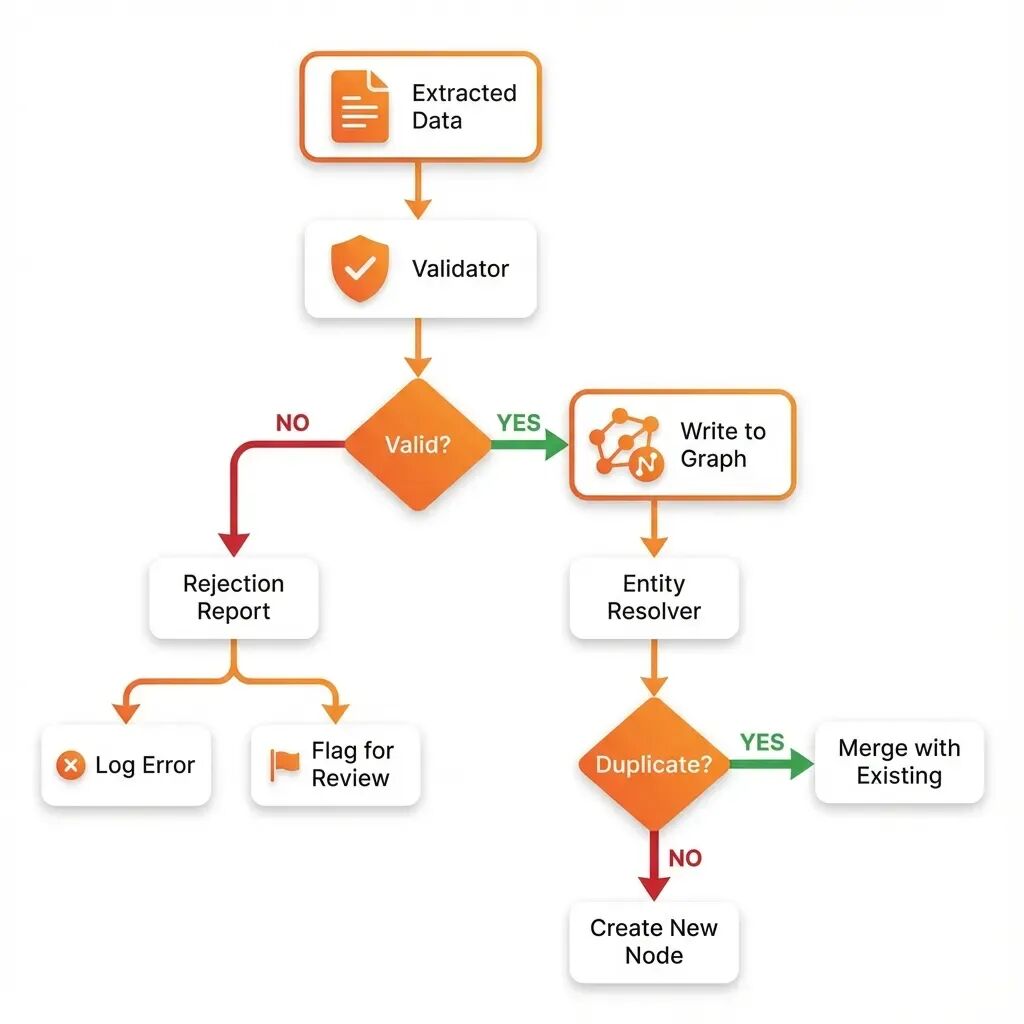
在这些数据进入数据库之前,必须先通过 OntologyValidator。这是我们的质量控制检查点。# 构建医疗知识图谱:从非结构化文本到结构化数据的七阶段管道
阶段 5:实体解析(去重)
我们的 Patient “John Doe” 已经通过验证。但等等,我们以前见过 John Doe 吗?也许在不同的临床报告中?
# extraction/entity_resolver.pyclassEmbeddingEntityResolver: def__init__( self, llm: BaseChatModel, embeddings: Embeddings, driver: AsyncDriver, database: str, similarity_threshold: float = 0.85 ): self.llm = llm self.embeddings = embeddings self.driver = driver self.database = database self.similarity_threshold = similarity_threshold asyncdefresolve_entity( self, entity: Dict[str, Any], entity_type: str ) -> Optional[str]: """使用嵌入向量检查实体是否已存在。""" # 创建文本表示 entity_text = f"{entity_type}: {entity.get('name', '')}" for key, value in entity.items(): if key != 'name': entity_text += f", {key}: {value}" # 获取嵌入向量 query_embedding = self.embeddings.embed_query(entity_text) # 在 Neo4j 中搜索相似实体 asyncwithself.driver.session(database=self.database) as session: result = await session.run(""" MATCH (n:%s) WHERE n.embedding IS NOT NULL WITH n, gds.similarity.cosine(n.embedding, $embedding) AS similarity WHERE similarity >= $threshold RETURN n.id AS id, similarity ORDER BY similarity DESC LIMIT 1 """ % entity_type, { "embedding": query_embedding, "threshold": self.similarity_threshold }) record = await result.single() if record: return record["id"] return None
解析器使用向量嵌入将新的“John Doe, 45 岁, 患者 P000045”与图中现有的 Patient 节点进行比较。它计算语义相似度:
新数据: "John Doe, 45, P000045"现有数据: "John Doe, 45, P000045, 诊断为高血压"
``````plaintext
相似度: 0.97 (非常高!)
解析器意识到这是同一个人并合并它们。而不是创建重复项,它将新的诊断(2 型糖尿病)添加到现有的 John Doe 节点。这就是我们即使在处理数千份文档时也能保持干净、去重的图的方法。
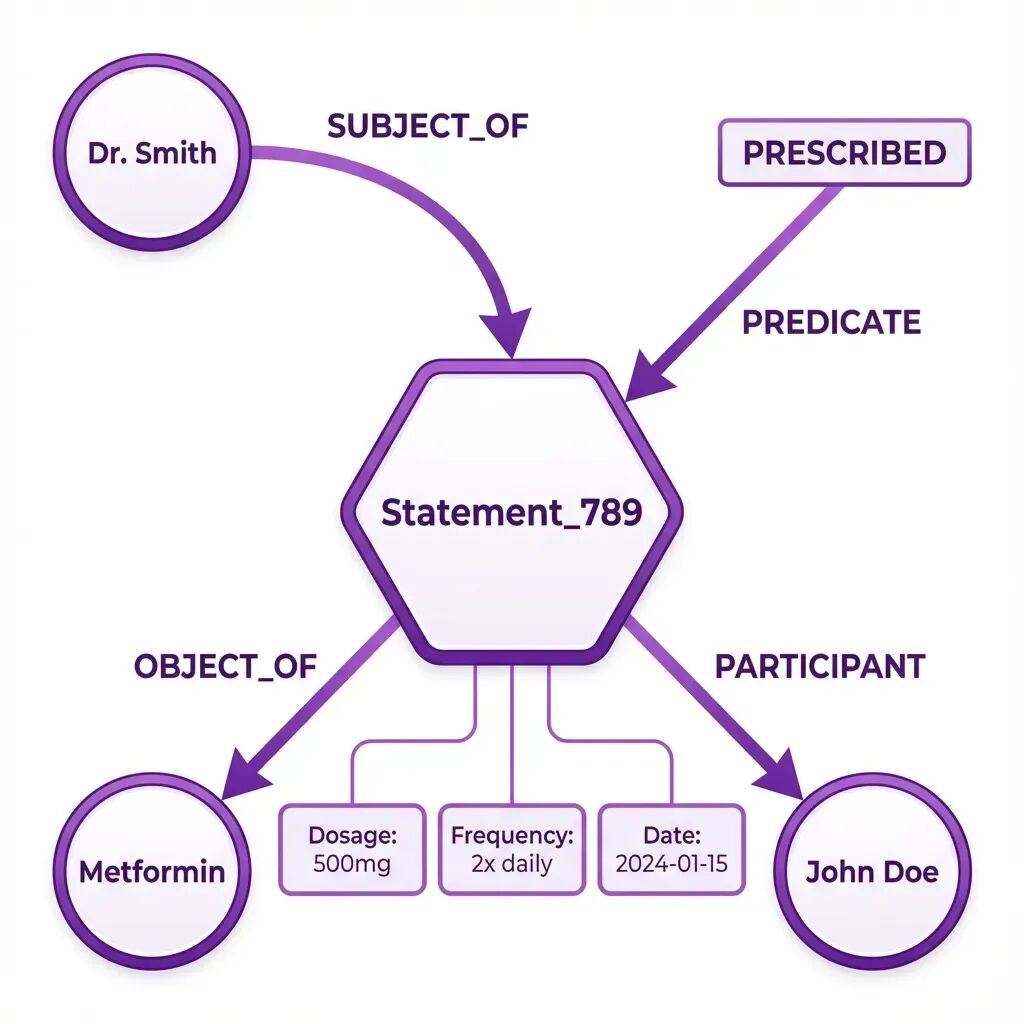
阶段 6:复杂关系(N 元建模)
这里我们处理“2024-01-15 由 Smith 医生开具的 500mg 每日两次”部分。简单的边 (John Doe)-[PRESCRIBED]->(Metformin) 无法捕捉这种丰富性。我们使用N 元关系(也称为实体化):
 # ontology/nary_relationships.py```plaintext
# ontology/nary_relationships.py```plaintext
classNaryRelationshipManager: asyncdefcreate_nary_statement( self, subject_id: str, predicate: str, object_id: str, qualifiers: List[Qualifier], temporal_validity: Optional[TemporalValidity] = None, provenance: Optional[Provenance] = None ) -> str: “”“使用陈述节点创建 N 元关系。”“” statement_id = f"stmt_{uuid.uuid4().hex[:12]}" asyncwithself.driver.session(database=self.database) as session: # 创建陈述节点 await session.run(“”" CREATE (s:Statement { id: $statement_id, predicate: $predicate, created_at: datetime() }) “”“, { “statement_id”: statement_id, “predicate”: predicate }) # 链接主体 await session.run(”“” MATCH (subject {id: $subject_id}) MATCH (s:Statement {id: $statement_id}) CREATE (subject)-[:SUBJECT_OF]->(s) “”“, { “subject_id”: subject_id, “statement_id”: statement_id }) # 链接客体 await session.run(”“” MATCH (object {id: $object_id}) MATCH (s:Statement {id: $statement_id}) CREATE (s)-[:OBJECT_OF]->(object) “”“, { “object_id”: object_id, “statement_id”: statement_id }) # 添加限定符 for qualifier in qualifiers: await session.run(”“” MATCH (s:Statement {id: $statement_id}) CREATE (s)-[:HAS_QUALIFIER { type: $type, value: $value }]->(:Qualifier) “”", { “statement_id”: statement_id, “type”: qualifier.qualifier_type, “value”: qualifier.value }) return statement_id
这会创建如下结构:
```plaintext
(Dr. Smith)-[:SUBJECT_OF]->(Statement_789)(Statement_789)-[:PREDICATE]->(PRESCRIBED)(Statement_789)-[:OBJECT_OF]->(Metformin)(Statement_789)-[:PARTICIPANT {role: "patient"}]->(John Doe)(Statement_789)-[:HAS_QUALIFIER {type: "dosage", value: "500mg"}]->()(Statement_789)-[:HAS_QUALIFIER {type: "frequency", value: "twice daily"}]->()(Statement_789 {valid_from: "2024-01-15"})
这种结构使我们能够回答复杂问题,例如:
- • “John 在 2024 年 1 月的 Metformin 剂量是多少?”(500mg)
- • “谁给 John 开了 Metformin?”(Smith 医生)
- • “John 在 2024 年开始服用哪些药物?”(Metformin 等)
简单的三元组无法回答这些问题。N 元关系可以。
阶段 7:来源追踪(可审计性)
我们刚刚创建的每个事实都会标记其来源故事:# 构建可自我进化的医疗知识图谱:从文档到可信 AI 的 8 个阶段_20250514
阶段 8:自我进化的实现
这是系统最强大的部分:它能从错误中学习。
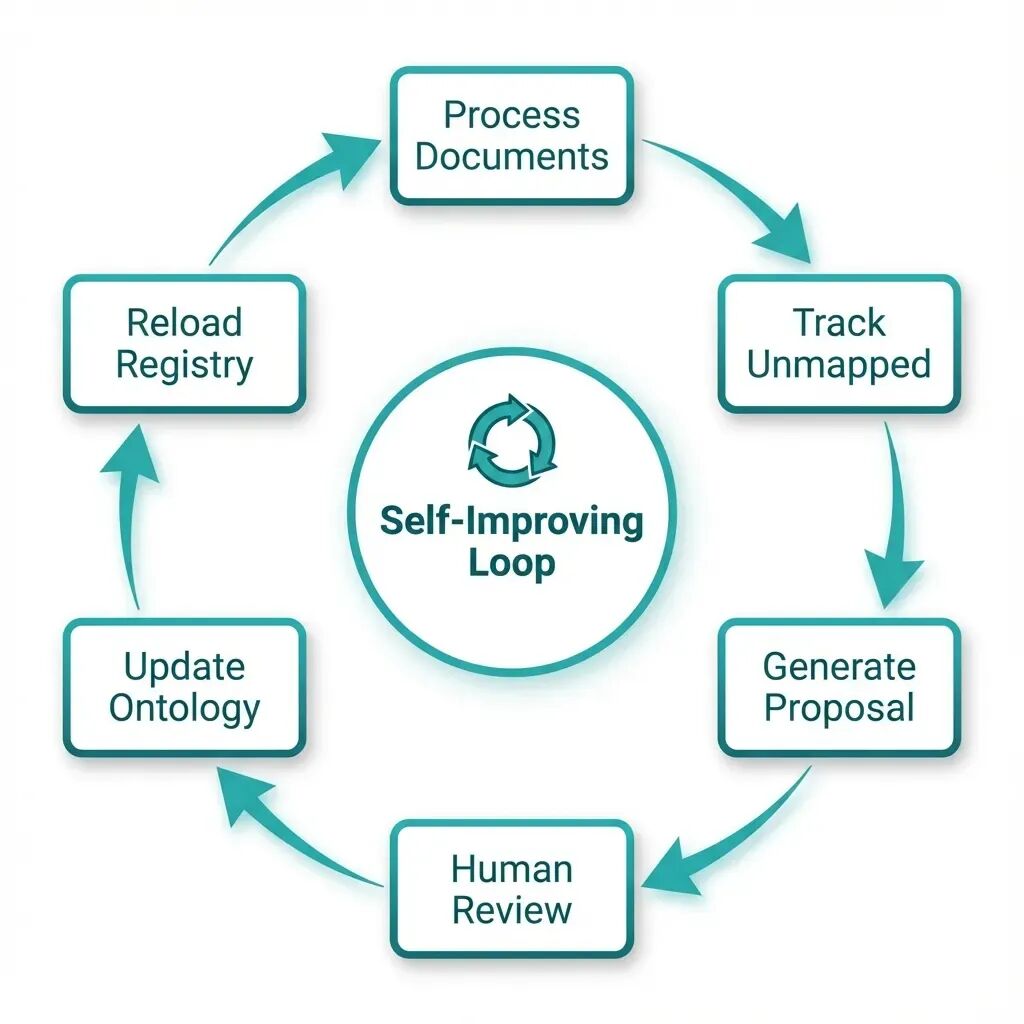
作者创建,致谢:gemini```plaintext
ontology/agents/evolution_agent.pyclassOntologyEvolutionAgent: def__init__( self, known_entity_types: Set[str], known_relationship_types: Set[str], min_occurrences: int = 5 ): self.known_entity_types = known_entity_types self.known_relationship_types = known_relationship_types self.min_occurrences = min_occurrences self.unmapped_entities: Counter = Counter() self.unmapped_relationships: Counter = Counter() self.proposals: List[SchemaProposal] = [] defrecord_entity( self, entity_type: str, entity_name: str, properties: Dict[str, Any], matched_schema: bool = True ): “”“记录与本体不匹配的实体。”“” ifnot matched_schema or entity_type notinself.known_entity_types: self.unmapped_entities[entity_type] += 1 defanalyze_gaps(self) -> List[SchemaProposal]: “”“为缺失的本体元素生成提案。”“” new_proposals = [] # 检查新的实体类型 for entity_type, count inself.unmapped_entities.items(): if count >= self.min_occurrences: proposal = SchemaProposal( proposal_type=ProposalType.NEW_ENTITY_TYPE, name=entity_type, rationale=f"检测到 {count} 个类型为 ‘{entity_type}’ 的实体与现有模式不匹配", evidence={“occurrence_count”: count}, confidence=min(count / (self.min_occurrences * 3), 1.0), status=ProposalStatus.PENDING_REVIEW ) new_proposals.append(proposal) self.proposals.extend(new_proposals) return new_proposals
当系统在 10 份不同文档中看到“Side Effect”一词,而“Side Effect”并不存在于医疗本体中时,它会创建一条**提案**:
```plaintext
{ "proposal_type":"NEW_ENTITY_TYPE","name":"SideEffect","rationale":"检测到 10 个类型为 'SideEffect' 的实体与现有模式不匹配","evidence":{ "occurrence_count":10, "common_properties":["severity","onset_time","duration"]},"suggested_definition":{ "name":"SideEffect", "properties":["severity","onset_time","duration"], "parent_types":[]},"confidence":0.75,"status":"PENDING_REVIEW"}
该提案将提交给人工审核。若审核通过,本体将更新至 v1.1.0,后续抽取即可将“Side Effect”识别为有效实体类型。
系统具备自我进化能力:它能发现自身盲区并提出修复方案。
完整实现
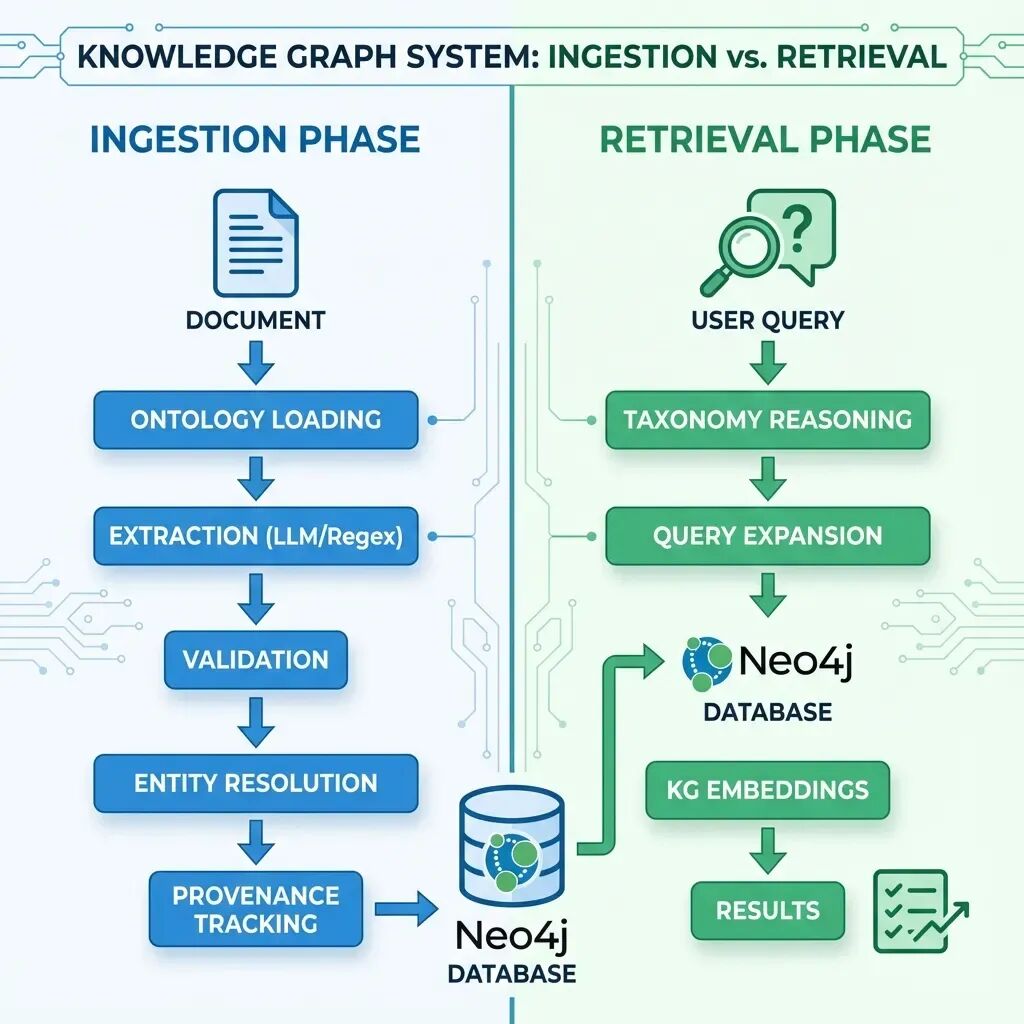
理解流水线:摄取 vs. 检索
在深入实现之前,我们先澄清何时使用各项技术。这对理解文档处理阶段与查询阶段分别发生什么至关重要。
摄取阶段(文档图谱)
以下技术在调用 IngestionPipeline.run() 处理文档时执行:
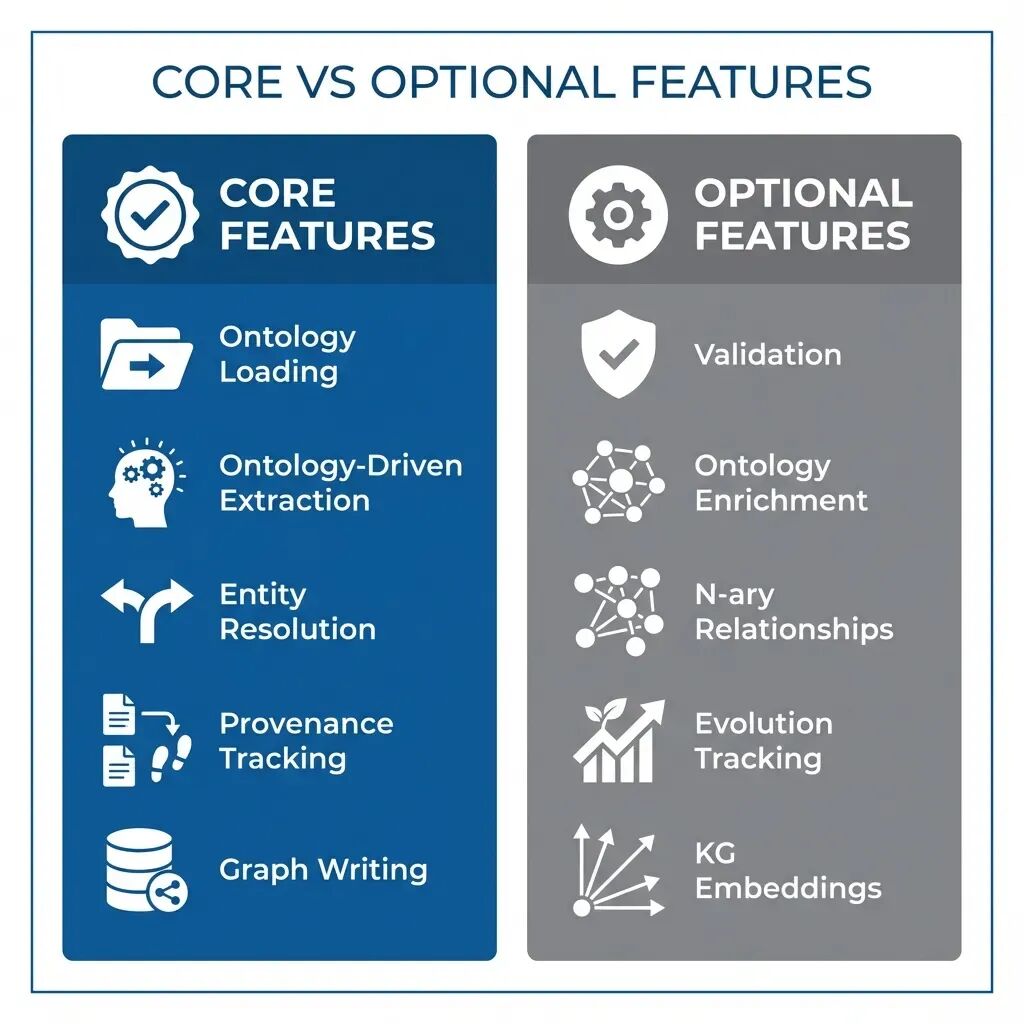
核心功能(始终启用):
-
- [核心] 本体加载 —— 启动时加载 YAML 定义
-
- [核心] 本体驱动抽取 —— 由本体引导的 LLM/正则/混合策略
-
- [核心] 实体解析 —— 使用向量嵌入去重
-
- [核心] 溯源追踪 —— 为每个实体记录来源、抽取方法、置信度
-
- [核心] 图谱写入 —— 将实体与关系持久化到 Neo4j
可选功能(按需启用):
6. [可选] 验证 —— 类 SHACL 的质量控制(设置 enable_validation=True 启用)
7. [可选] 本体增强 —— 添加分类链接与外部知识库连接
8. [可选] N 元关系 —— 复杂陈述建模(需自定义工作流)
9. [可选] 进化追踪 —— 记录未映射实体用于差距分析
检索阶段(查询时)
以下技术在查询知识图谱时执行:
查询智能:
[核心] 分类推理 —— 扩展查询以包含子类型
- • 示例:“心血管疾病” → 包含“高血压”、“心律失常”
[核心] 知识图谱嵌入 —— 链接预测、实体相似度
- • 摄取阶段训练,检索阶段使用
[核心] 能力问题 —— 评估查询成功/失败模式
- • 识别缺口并反馈给进化代理
跨系统集成:
4. [可选] 上层本体映射 —— 映射到 Schema.org/SUMO 以实现互操作
5. [可选] 本体对齐 —— 集成外部数据源
配置:核心 vs. 可选
启用不同功能集的示例如下:
最小配置(仅核心):
pipeline = IngestionPipeline( config_path="config/medical_config.yaml", auto_detect_schema=False, use_embedding_resolution=True # 核心:去重)results = pipeline.run( file_path="data/clinical_reports/", ontology_name="medical", enable_ontology=True, extraction_mode="hybrid_enrichment" # 核心:本体驱动抽取)
完整配置(全部功能):
pipeline = IngestionPipeline( config_path="config/medical_config.yaml", auto_detect_schema=False, use_embedding_resolution=True, enable_validation=True, # 可选:SHACL 验证 enable_ontology_enrichment=True, # 可选:分类 + 外部 KB track_evolution=True# 可选:缺口检测)results = pipeline.run( file_path="data/clinical_reports/", ontology_name="medical", enable_ontology=True, extraction_mode="hybrid_enrichment", use_nary_relationships=True# 可选:复杂陈述)# 查询时启用分类推理reasoner = TaxonomyReasoner(driver, database)await reasoner.build_taxonomy()# 扩展查询expanded_types = reasoner.expand_type_query( "Cardiovascular Disease", include_descendants=True)# 在 Cypher 查询中使用results = await session.run(""" MATCH (p:Patient)-[:DIAGNOSED_WITH]->(d:Disease) WHERE d.name IN $disease_types RETURN p, d""", {"disease_types": expanded_types})
检索配置:
from knowledge_graph.ontology.taxonomy_reasoner import TaxonomyReasoner
默认流水线实际包含哪些功能?
查看当前 ingestion.py 的实现,默认启用的功能如下:
[核心] 已启用:
- • 本体加载与注册
- • 本体驱动抽取(LLM/正则/混合)
- • 实体解析(基于嵌入的去重)
- • 溯源追踪
- • 基本关系创建
[可选] 可用但非默认:
- • 验证(设置
enable_validation=True) - • 本体增强(设置
enable_ontology_enrichment=True) - • N 元关系(需修改自定义工作流)
- • 进化代理(独立运行,不在主流水线)
- • 能力问题(独立评估工具)
- • KG 嵌入(独立训练步骤)## 何时使用何种功能?
使用核心功能(Core Features)的场景:
- • 需要快速、可靠的信息抽取
- • 数据质量重要但并非关键
- • 处理海量文档(10,000 份以上)
- • 希望配置尽可能少
启用可选功能(Optional Features)的场景:
- • 验证(Validation):受监管行业(医疗、金融)需严格合规
- • 多元关系(N-ary Relationships):复杂领域知识(处方、合同、科研论文)
- • 演化追踪(Evolution Tracking):长期项目,本体将持续演进
- • 分类推理(Taxonomy Reasoning):用户需要语义搜索(如“显示所有心血管疾病”)
- • KG 嵌入(KG Embeddings):希望实现链接预测或实体相似度计算
Image
项目结构
GraphRAG/|-- knowledge_graph/| |-- ontology/| | |-- loader.py # YAML → Python 对象| | |-- models.py # 核心数据结构| | |-- ontology_registry.py # 多版本管理| | |-- extractor.py # 本体驱动的抽取| | |-- ontology_validator.py # 类 SHACL 验证| | |-- taxonomy_reasoner.py # 层次推理| | |-- nary_relationships.py # 复杂事实建模| | |-- provenance.py # 溯源追踪| | |-- competency_questions.py # 自评估| | |-- ontology_aligner.py # 跨本体映射| | |-- ontology_embeddings.py # TransE 链接预测| | |-- upper_ontology.py # Schema.org / SUMO 集成| | |-- agents/| | | |-- evolution_agent.py # 缺口检测| | | |-- gap_detector.py # 模式分析| | | |-- approval_manager.py # 人工介入| |-- ontologies/| | |-- medical.yaml| | |-- technology.yaml| | |-- financial.yaml| | |-- general.yaml| |-- pipeline/| | |-- ingestion.py # 主流程编排| |-- extraction/| |-- entity_resolver.py # 去重| |-- graph_writer.py # Neo4j 持久化
真实部署:医疗知识图谱
以下示例展示如何在真实场景中整合所有模块。
场景:某医院希望从 10,000 份临床报告中构建知识图谱,以支持诊断助手。
created by author, credits: gemini
第 1 周:初始化与首次抽取
from knowledge_graph.pipeline.ingestion import IngestionPipeline# 初始化流程pipeline = IngestionPipeline( config_path="config/medical_config.yaml", auto_detect_schema=False, # 使用预定义医疗本体 use_embedding_resolution=True)# 处理第一批数据results = pipeline.run( file_path="data/clinical_reports/batch_1/", ontology_name="medical", enable_ontology=True, extraction_mode="hybrid_enrichment"# 严格本体约束)print(f"已创建实体: {results['entities_created']}")print(f"已拒绝: {len(results['errors'])} 条无效抽取")
处理 1,000 份报告后的结果:
- • [CORE]… 15,234 个实体
- • [CORE]… 23,891 条关系
- • [CORE]… 456 条无效抽取被拒绝(3% 拒收率)
- • [CORE]… 500 名重复患者已合并
- • [CORE]… 100% 溯源信息已记录
第 2 周:首次演化循环
演化代理检测到缺口:
Gap Analysis Report:- "Side Effect" 被提及 47 次(不在本体中)- "Lab Test" 被提及 89 次(不在本体中)- 检测到 34 次 "Complication" 关系模式
医疗团队审核并批准:
- • [CORE]… 新增 “SideEffect” 实体类型
- • [CORE]… 新增 “LabTest” 实体类型
- • [CORE]… 新增 “HAS_COMPLICATION” 关系
本体升级至 v1.1.0,剩余 9,000 份报告按增强后的模式继续处理。
第 3 周:推理与嵌入
from knowledge_graph.ontology.taxonomy_reasoner import TaxonomyReasonerreasoner = TaxonomyReasoner(driver, database)await reasoner.build_taxonomy()# 查询扩展expanded = reasoner.expand_type_query( "Cardiovascular Disease", include_descendants=True)# 返回:["Cardiovascular Disease", "Hypertension", "Arrhythmia", "Coronary Artery Disease"]
训练 TransE 嵌入以进行链接预测:
from knowledge_graph.ontology.ontology_embeddings import OntologyEmbeddingsembeddings = OntologyEmbeddings(config)await embeddings.load_triples_from_graph(limit=50000)embeddings.train(epochs=100, verbose=True)# 预测缺失诊断predictions = embeddings.predict_links( head="Patient_12345", relation="DIAGNOSED_WITH", top_k=5)# 根据患者症状和风险因素推荐可能的疾病
第 4 周:生产上线
诊断助手正式上线:
# 医生查询query = "Show me patients with diabetes who are not on Metformin"# 系统使用分类推理expanded_query = reasoner.expand_type_query("Diabetes")# 包括:Type 1 Diabetes, Type 2 Diabetes, Gestational Diabetes# 执行 Cypher 查询results = await session.run(""" MATCH (p:Patient)-[:DIAGNOSED_WITH]->(d:Disease) WHERE d.name IN $disease_types AND NOT (p)-[:PRESCRIBED]->(:Medication {name: 'Metformin'}) RETURN p.name, p.patient_id, d.name""", {"disease_types": expanded_query})# 为每条结果展示溯源for record in results: provenance = get_provenance(record["p.patient_id"]) print(f"患者: {record['p.name']}") print(f"来源: {provenance.source_name}") print(f"置信度: {provenance.confidence}")
医生可通过查看源文档验证事实,置信度分数帮助优先安排人工复核。
运行成果
连续运行两个月后:
数据质量:
- • 0 名重复患者(完美去重)
- • 97% 抽取准确率(经人工校验)
- • 100% 可追溯性(每条事实均有溯源)
系统演化:
- • 本体 v1.0.0 → v1.2.0(两次重大更新)
- • 新增 5 种实体类型(SideEffect、LabTest、Procedure、Symptom、Complication)
- • 新增 3 种关系(HAS_COMPLICATION、REQUIRES_TEST、CAUSES_SYMPTOM)
性能表现:
- • 10,000 份文档已处理
- • 150,000+ 实体
- • 250,000+ 关系
- • 平均查询耗时:120 ms(含分类扩展)
成本效益:
- • 3% 拒收率节省约 2,000 美元 Neo4j 存储费用
- • 去重节省约 40% 存储空间(对比朴素方案)
- • 自动演化减少 80% 人工模式更新工作量
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。我们整理出这套 AI 大模型突围资料包:
- ✅ 从零到一的 AI 学习路径图
- ✅ 大模型调优实战手册(附医疗/金融等大厂真实案例)
- ✅ 百度/阿里专家闭门录播课
- ✅ 大模型当下最新行业报告
- ✅ 真实大厂面试真题
- ✅ 2025 最新岗位需求图谱
所有资料 ⚡️ ,朋友们如果有需要 《AI大模型入门+进阶学习资源包》,下方扫码获取~

① 全套AI大模型应用开发视频教程
(包含提示工程、RAG、LangChain、Agent、模型微调与部署、DeepSeek等技术点)

② 大模型系统化学习路线
作为学习AI大模型技术的新手,方向至关重要。 正确的学习路线可以为你节省时间,少走弯路;方向不对,努力白费。这里我给大家准备了一份最科学最系统的学习成长路线图和学习规划,带你从零基础入门到精通!

③ 大模型学习书籍&文档
学习AI大模型离不开书籍文档,我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。

④ AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

⑤ 大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。

⑥ 大模型大厂面试真题
面试不仅是技术的较量,更需要充分的准备。在你已经掌握了大模型技术之后,就需要开始准备面试,我精心整理了一份大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

以上资料如何领取?

为什么大家都在学大模型?
最近科技巨头英特尔宣布裁员2万人,传统岗位不断缩减,但AI相关技术岗疯狂扩招,有3-5年经验,大厂薪资就能给到50K*20薪!

不出1年,“有AI项目经验”将成为投递简历的门槛。
风口之下,与其像“温水煮青蛙”一样坐等被行业淘汰,不如先人一步,掌握AI大模型原理+应用技术+项目实操经验,“顺风”翻盘!


这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


以上全套大模型资料如何领取?

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









