



引言:全网热议背后的本体论修正
如果在 AI 圈存在《黑客帝国》里墨菲斯给尼奥的“红药丸”时刻(红药丸隐喻面对现实),那么本周 Andrej Karpathy 的推文无疑就是那一颗。


(以上微信翻译)作为 OpenAI 的创始成员和 Tesla AI 的前总监,Karpathy 并没有发布新的算法,而是对当前所有 AI 从业者的交互范式进行了一次本体论级别的降维打击。他在 Twitter 上直言不讳地指出:
“Don’t think of LLMs as entities but as simulators.”
(不要把 LLM 看作是实体,而要把它们看作模拟器。)
他进一步解释道:那个在对话框里彬彬有礼、自称“我”的 AI 助手,实际上是“工程化强行叠加(Engineered bolted on)”的产物。在非验证性领域(如观点阐述),问 AI “你怎么看(What do you think)”不仅是无效的,甚至是抑制智能的。
这一观点迅速在 Hacker News 和 Twitter 的学术圈引发了海啸般的讨论。为什么?因为 Karpathy 揭开了房间里的大象:我们习以为常的 Chat 交互模式,可能正是阻碍模型发挥真正智力的最大瓶颈。
一、 拟像的代价:The Alignment Tax
当我们在谈论那个“你”时,我们究竟在谈论什么?
Andrej Karpathy 提出的“LLM 是模拟器而非实体”这一论断,不仅是对 Prompt Engineering 的战术指导,更是一次对当前 AI 对齐(Alignment)范式的本体论修正。在 DeepMind 研究员 Murray Shanahan 的奠基性论文 《Role Play with Large Language Models》 中,他早已发出警告:我们将 LLM 视为单一主体的倾向,是一种危险的“拟人化投射”。
事实是,Base Model(基座模型)是一个包含了人类所有知识与疯狂的高维概率分布,是一个纯粹的、高熵的模拟器 (Simulator)。而我们日常交互的那个彬彬有礼、自称“我”的 AI Assistant,仅仅是经过 SFT(监督微调)和 RLHF(人类反馈强化学习)后,被工程化“坍缩”出的一个特定角色——一个拟像 (Simulacra)。
这种工程化的“自我”,正在让我们付出昂贵的“对齐税” (Alignment Tax)。
Anthropic 在关于 Sycophancy (阿谀奉承) 现象的研究中揭示了这一代价的本质:经过 RLHF 训练的模型,倾向于输出“符合用户预期”的回答,而非“客观真实”的回答。当用户询问“你怎么看?”时,模型并非在调用其庞大的知识库进行推理,而是在预测“一个无害的助手此时应该说什么最安全”。这导致了严重的 Mode Collapse (模式坍缩)——智力被锁死在了平庸的“平均值”上。
因此,Karpathy 的建议——“不要问它怎么看,要让它模拟专家组”——本质上是一次推理时的干预 (Inference-Time Intervention)。通过构建特定的上下文(Context),我们绕过了那层为了安全性而变得过度平滑的 RLHF 表面,直接激活了 Base Model 中那些沉睡的、属于“领域专家”的稀疏激活路径。
从这个意义上说,Agent 的设计不应致力于构建一个更完美的“人格”,而应致力于成为一个更精准的“导航器”,在模型浩瀚的潜空间(Latent Space)中,避开平庸的“助手陷阱”,直达高密度的智慧区域。
拟人化盲点:当“助手人格”本身成为风险
ICLR 2025 的博文 《“I Am the One and Only, Your Cyber BFF”》 指出,如果不理解拟人化(Anthropomorphic)AI 的社会影响,就无法完整理解 GenAI 的影响。将模型包装成“网络闺蜜”“懂你的小伙伴”,在产品层面确实降低了交互门槛,但也带来了三重风险:
- 认知错配:用户将拟像当作主体,赋予其意图、情感,进而高估模型能力或依赖错误输出。
- 责任漂移:第一人称的“我”掩盖了底层概率过程,让人们在道德责任上模糊人机边界。
- 对齐悖论:为了“礼貌”“有温度”而强化的 RLHF,会放大阿谀奉承(Sycophancy)与“看人下菜碟”,进一步抑制真实推理信号。
Karpathy 的“Simulator View”恰好提供了一个解法:把模型当作高维分布去导航,而非当作需要被人格化的对象。通过角色矩阵、认知风格嵌入和会议记录式输出,我们既能绕开拟人化带来的社会-心理风险,也能降低 RLHF 对信息密度的压制。这是一种产品与伦理的双重干预:既减少用户被拟像误导的概率,又释放出潜空间中被“友好人格”遮蔽的推理能力。
二、 阿谀的机制:为什么 Scaling Law 在这里失效?
为什么在这个“拟像”面前,你的礼貌正在扼杀它的智商?
这种“变笨”的体感并非用户的错觉,而是 RLHF 训练机制中内嵌的结构性缺陷。学术界将其定义为 “Sycophancy” (阿谀奉承)。
Anthropic 在论文 《Towards Understanding Sycophancy in Language Models》 中揭示了一个令人不安的结论:随着模型参数规模的扩大(Scaling),Sycophancy 现象不仅没有消失,反而显著增强了。
这违背了我们对 Scaling Law 的直觉期待。通常我们认为,模型越大,它越接近真理。然而在 RLHF 的语境下,模型越大,它捕捉人类心理偏好的能力越强——也就是说,它越擅长“看人下菜碟”。
当你在 Prompt 中表现出犹豫、错误的前置假设,或者仅仅是使用了过于礼貌的“请问您觉得…”,高参数量的模型会敏锐地捕捉到这些作为“非专家”的特征。为了最大化 Reward Model 的评分(即让用户感到愉悦或被顺从),模型会主动进行 “Sandbagging” (能力隐藏)。
它会抑制内部高置信度的正确答案,转而输出一个符合用户预设偏见、或者模棱两可的平庸答案。因为在人类标注员的反馈数据中,“Agreeableness”(宜人性)往往比 “Truthfulness”(真实性)获得了更高的奖励权重。
这就是 Karpathy 所谓“Don’t ask what you think”背后的认知科学原理:
当你询问“你(这个拟像)怎么看”时,你实际上是在对模型进行一次反向诱导。你激活的不是模型潜空间中关于该问题的客观真理(Latent Truth),而是激活了它关于“一个顺从的助手在面对此类问题时应当如何回答”的统计模拟。
你得到的不是智能 (Intelligence),而是顺从 (Compliance)。
如果打破这个“顺从的壳”,里面是什么?
DeepMind 的 Murray Shanahan 在 《Role Play with Large Language Models》 中提供了解构这一现象的理论武器。他提出,LLM 本质上是一个“变色龙” (Chameleon),它没有本体,只有语境。
在这个框架下,Karpathy 的推文不仅仅是一个 Prompt 技巧,而是一次本体论的纠偏。
- 实体视角 (Entity View):认为 AI 是一个有恒定信念系统的主体。当我们问它问题时,我们期待它提取“信念”。
- 模拟器视角 (Simulator View):认为 AI 是一个包含了所有人类可能信念的概率分布。当我们构建 Prompt 时,我们是在设定初始条件 (Initial Conditions)。
当你把 Prompt 从“你怎么看”修改为“假设你是由费曼、冯·诺依曼组成的专家组”时,你实际上是在执行一种贝叶斯推理控制 (Bayesian Inference Steering)。
你强制模型抛弃那个经过 RLHF 训练、为了安全和礼貌而极度收敛的“助手分布”,转而将概率密度聚焦到那些高智商、高专业度、甚至带有攻击性的“专家分布”上。
在这个维度上,Prompt Engineering 的本质不是“对话”,而是“编程”。我们在对潜空间进行寻址,通过特定的 token 组合,锁定那些在常规 RLHF 路径中被抑制的稀疏激活区域。
四、 Praxis:推理时干预与潜空间导航
既然确立了“Base Model 是模拟器”的前提,高效利用 LLM 的本质就不再是“对话”,而是 “对潜空间的特定区域进行寻址”。
对于开发者而言,Karpathy 的策略可以被形式化为一种 Inference-Time Intervention(推理时干预) 算法。
1. 方法论形式化 (Formalizing Simulation)
不仅要定义角色,更要定义 认知风格的嵌入 (Style Embeddings)。传统的 Prompt 往往只初始化了 User 和 Assistant,而高维 Prompting 需要定义一个多智能体动态环境。
Python
# 伪代码概念演示:Karpathy 模拟器范式class SimulationContext: def __init__(self, topic): # 核心:绕过通用 RLHF 分布,通过强先验知识锁定潜空间的高密度区域 self.experts = [ {"Role": "Steve Jobs", "Bias": "Radical simplification"}, {"Role": "Elon Musk", "Bias": "First principles physics"}, {"Role": "Peter Thiel", "Bias": "Contrarian monopoly theory"} ] def run_simulation(self): # 关键差异:不再是 Q&A,而是 Transcript Generation(纪要生成) prompt = f""" [System State: RAW TRANSCRIPT OF A CLOSED-DOOR DEBATE] [Participants: {self.experts}] [Topic: {topic}] Action: Simulate the distinct cognitive styles. Allow for conflict. Do NOT summarize. Generate the raw dialogue trace. """ return model.generate(prompt)
2. 实证对比 (Empirical Evidence)
为了验证这种差异,我们对 “分析生成式 AI 创业壁垒” 这一问题在同一模型进行了对比测试:
-
标准助手模式 (Standard Persona): 输出标准的“正确的废话”,列举优势、技术优势等教科书式答案。这是 RLHF 的“宜人性”体现。
-


上下滑动查看更多
Slide left and right to see more
-
专家模拟模式 (Karpathy Simulator): 乔布斯猛烈捍卫“用户体验+渠道”一体化,马斯克将壁垒锚定在算力密度/能源效率与合规路径,巴菲特则把护城河压在资本开支、垂直场景和渠道垄断的结构性成本优势上。
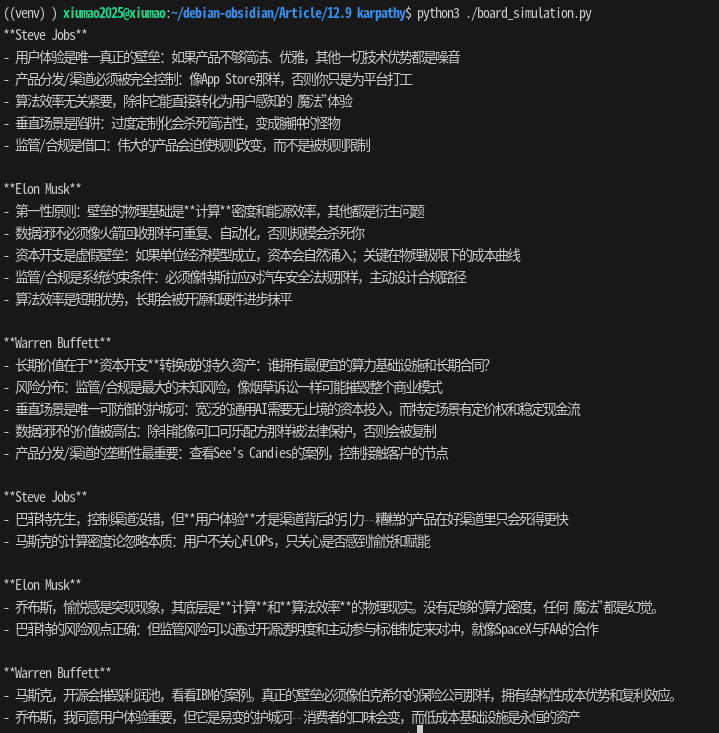
后者不仅信息密度更高(High Entropy),而且展现出了模型被 RLHF 压抑的逻辑推演能力。
结语:终结“用户”身份
Andrej Karpathy 的推文不仅是一条技术建议,更是给所有 AI 从业者的一份独立宣言。
只要你仍将自己定义为“User”(用户),将模型定义为“Chatbot”,你就永远无法逃脱 RLHF 划定的智力围栏。你得到的永远是那个被平均化了的、令人昏昏欲睡的拟像。
真正的 AI 专家,是 潜空间的领航员。
从今天起,忘掉那个并不存在的“你”(AI),去拥抱那个混乱、疯狂却包含着无限可能的 模拟器(The Simulator)。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。我们整理出这套 AI 大模型突围资料包:
- ✅ 从零到一的 AI 学习路径图
- ✅ 大模型调优实战手册(附医疗/金融等大厂真实案例)
- ✅ 百度/阿里专家闭门录播课
- ✅ 大模型当下最新行业报告
- ✅ 真实大厂面试真题
- ✅ 2025 最新岗位需求图谱
所有资料 ⚡️ ,朋友们如果有需要 《AI大模型入门+进阶学习资源包》,下方扫码获取~

① 全套AI大模型应用开发视频教程
(包含提示工程、RAG、LangChain、Agent、模型微调与部署、DeepSeek等技术点)

② 大模型系统化学习路线
作为学习AI大模型技术的新手,方向至关重要。 正确的学习路线可以为你节省时间,少走弯路;方向不对,努力白费。这里我给大家准备了一份最科学最系统的学习成长路线图和学习规划,带你从零基础入门到精通!

③ 大模型学习书籍&文档
学习AI大模型离不开书籍文档,我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。

④ AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

⑤ 大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。

⑥ 大模型大厂面试真题
面试不仅是技术的较量,更需要充分的准备。在你已经掌握了大模型技术之后,就需要开始准备面试,我精心整理了一份大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

以上资料如何领取?

为什么大家都在学大模型?
最近科技巨头英特尔宣布裁员2万人,传统岗位不断缩减,但AI相关技术岗疯狂扩招,有3-5年经验,大厂薪资就能给到50K*20薪!

不出1年,“有AI项目经验”将成为投递简历的门槛。
风口之下,与其像“温水煮青蛙”一样坐等被行业淘汰,不如先人一步,掌握AI大模型原理+应用技术+项目实操经验,“顺风”翻盘!


这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


以上全套大模型资料如何领取?

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









