



文章通过巴黎旅行比喻,解释多模态学习原理。多模态AI像人类一样通过多种感官同时收集信息,让不同感官信息"对话"关联,将体验编码为可比较格式,确保信息一致性,最后通过智能加权投票系统融合信息,得出准确判断。这一过程包含六个关键步骤:感官收集、感官协调、信息编码、信息对齐、综合判断和完整表达,使AI能够像人类一样全面理解世界。
想象你第一次来到巴黎街头,想要完全理解这座城市的魅力。你不会只依赖一种方式——你用眼睛欣赏埃菲尔铁塔的壮美和香榭丽舍大街的繁华,用耳朵聆听塞纳河的波浪声和咖啡馆里的法语交谈,同时努力理解路标和菜单上优美的法文。只有将这些不同感官的信息融合在一起,你才能真正"读懂"巴黎的浪漫。
多模态学习就是这样——让AI拥有像人类一样的"多重感官",同时理解图像、文字、声音,并融合成完整的智慧!
这张流程图就是AI"巴黎之旅"的完整攻略,让我们看看机器如何像游客一样用"全感官"体验世界!
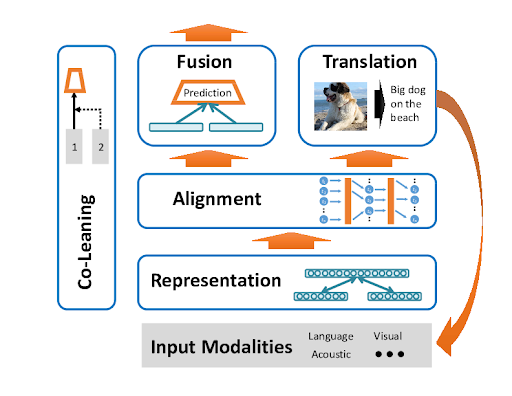
一、感官收集(Input Modalities)
步骤1:初到巴黎:多重感官同时启动
就像游客一到巴黎就被各种信息包围
你刚走出地铁站,巴黎瞬间"轰炸"你的感官:
(1)眼睛看到的画面:“哇!面前是一座宏伟的石制建筑,有着优雅的拱门和复杂的雕刻细节,阳光透过梧桐叶洒在鹅卵石路面上,穿着时尚的巴黎人悠闲地走过…”
(2)大脑处理的文字:“路牌写着’Avenue des Champs-Élysées’,咖啡馆门口的黑板菜单用法语写着今日推荐,我的旅游手册说这里是’世界上最美的街道’…”
(3)耳朵捕捉的声音:“远处传来街头艺人的手风琴音乐,咖啡馆里传出轻松的法语对话声,还有汽车轻柔的引擎声和高跟鞋踩在石板路上的节奏…”
这就是多模态输入的真实场景:
传统AI:只能处理一种信息
"我只能看图片" 或者 "我只能读文字"
多模态AI:同时处理多种信息
"我既能看图片,又能读文字,还能听声音!"
二、感官协调(Co-Learning)
**步骤2:感官开始"对话":学会关联不同信息
就像你的眼睛、耳朵、大脑开始互相"聊天"
想象你的感官在内心进行这样的对话:
(1)眼睛说:“我看到一个优雅的女士走向咖啡馆,她穿着米色风衣,手里拿着一个小包…”
(2)耳朵说:“等等!我刚听到她说’Bonjour’,声音很温和,还有高跟鞋的声音证实了她正在走路!”
(3)大脑说:“有意思!我刚读到旅游书里写’巴黎女人以优雅著称’,现在眼睛和耳朵的信息完全吻合了!”
这种"感官对话"让理解更准确:
单独的眼睛:只知道"有个女人在走"
单独的耳朵:只知道"有人在说法语"
单独的大脑:只知道"书上说巴黎女人优雅"
三者合作:完整理解"一位优雅的巴黎女士正走向咖啡馆准备打招呼"
**三、信息编码(Representation)
步骤3:建立"巴黎记忆档案":把体验转化成可比较的信息
就像在大脑里建立一个"巴黎文化数据库"
你需要把复杂的感官体验转换成大脑能处理的"记忆格式":
(1)视觉体验 → 记忆编码:
看到的场景:优雅建筑 + 时尚行人 + 温暖阳光
↓ 大脑翻译成记忆代码 ↓
[建筑优雅度: 0.9, 人群时尚度: 0.8, 环境温馨度: 0.7, 历史感: 0.9]
(2)文字理解 → 记忆编码:
读到的信息:"香榭丽舍大街,巴黎最著名的购物街"
↓ 大脑翻译成记忆代码 ↓
[知名度: 0.95, 商业繁华度: 0.8, 文化重要性: 0.9, 浪漫程度: 0.7]
(3)听觉体验 → 记忆编码:
听到的声音:手风琴音乐 + 法语对话 + 轻柔环境音
↓ 大脑翻译成记忆代码 ↓
[音乐浪漫度: 0.8, 语言优雅度: 0.9, 环境舒适度: 0.8, 文化氛围: 0.9]
**四、信息对齐(Alignment)
步骤4:确认信息一致性:避免"张冠李戴"
就像检查你看到的、听到的、想到的是否在说同一件事
你需要确认不同感官描述的确实是同一个场景:
错位的感官信息:
看到:一个安静的公园
听到:热闹的市场叫卖声
想到:这里应该是商业区
信息不匹配!需要重新确认位置
对齐后的感官信息:
看到:香榭丽舍大街的咖啡馆
听到:咖啡馆里的法语交谈声
想到:这确实是著名的巴黎商业街
三种信息完美匹配!
五、综合判断(Fusion + Prediction)
步骤5:投票决策:综合所有感官得出最终判断
就像让你的眼睛、耳朵、大脑一起"投票"决定这里到底怎么样
每个"感官专家"根据自己的信息给出判断:
(1)视觉专家的投票:“根据我看到的建筑风格、人群穿着、环境布置,我85%确定这是一个高端、优雅、充满艺术气息的地方!”
(2)听觉专家的投票:“根据我听到的音乐类型、语言节奏、环境音调,我90%确定这是一个浪漫、悠闲、文化氛围浓厚的区域!”
(3)知识专家的投票:“根据我了解的历史背景、地理位置、文化意义,我95%确定这是巴黎最具代表性的时尚文化区!”
智能加权投票系统:
最终判断 = 权重分配×各专家意见
视觉印象 × 30% = 0.85 × 0.3 = 0.255
听觉感受 × 30% = 0.90 × 0.3 = 0.270
知识背景 × 40% = 0.95 × 0.4 = 0.380
综合得分 = 0.905 (90.5%的确信度)
投票结果:香榭丽舍大街 = 优雅艺术区 + 浪漫文化区 + 时尚购物区
**六、完整表达(Translation)
步骤6:完美表达:把深度理解转化成准确描述**
就像回国后向朋友生动描述你的巴黎印象
基于多感官融合理解,现在你可以给出准确而丰富的描述:
单一感官的片面描述:
只用眼睛: "那里有很多建筑"
只用耳朵: "那里有音乐声"
只用知识: "那是个著名地方"
多感官融合的完整表达:
香榭丽舍大街是巴黎最迷人的文化街区,
优雅的奥斯曼建筑在阳光下散发着历史韵味,
街头艺人的手风琴为时尚的巴黎人创造了浪漫的购物氛围,
每一个细节都诠释着这座城市独特的艺术魅力。
这就是多模态深度学习的完整工作原理——就像一个敏感的旅行者在巴黎的完整体验。六个关键步骤:(1)感官收集 - 同时启动视觉、听觉、语言理解,(2)感官协调 - 让不同信息源互相"对话"验证,(3)信息编码 - 将复杂体验转换为可比较的"记忆格式",(4)信息同步 - 确保所有信息描述的是同一个场景,(5)综合判断 - 智能融合所有信息得出最佳结论,(6)完美表达 - 将深度理解转化为准确丰富的输出。**
如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 大模型行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方优快云官方认证二维码,免费领取【保证100%免费】

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









