 Structure-CLIP:增强多模态结构化表示
Structure-CLIP:增强多模态结构化表示




摘要
大规模视觉-语言预训练在多模态理解和生成任务中取得了显著的性能提升。 然而,现有方法在需要结构化表示的图像-文本匹配任务上的表现往往较差,即对对象、属性和关系的表示。 As illustrated in Fig. 1 (a), the models cannot make a distinction between “An astronaut rides a horse” and “A horse rides an astronaut”. 这是因为它们在多模态场景中学习表示时未能充分利用结构化知识。 在本文中,我们提出了一种端到端的框架Structure-CLIP,它集成了_场景图知识_(SGK)来增强多模态结构化表示。 首先,我们使用场景图来指导构建_语义否定_示例,这使得学习结构化表示更加突出。 此外,提出了一种_知识增强编码器_(KEE) ,利用SGK作为输入来进一步增强结构化表示。 为了验证所提出框架的有效性,我们使用上述方法预训练我们的模型,并在下游任务上进行了实验。 实验结果表明,Structure-CLIP在VG-Attribution和VG-Relation数据集上取得了_最先进的_(SOTA)性能,分别比多模态SOTA模型高出12.5%和4.1%。 同时,MSCOCO上的结果表明,Structure-CLIP在保持一般表示能力的同时,显著增强了结构化表示。 我们的代码可在https://github.com/zjukg/Structure-CLIP获取。
一、引言

图1: 图像与匹配/不匹配标题之间的CLIP得分(在两个结果之间归一化后)。 结果表明,CLIP模型无法区分具有结构化语义差异的句子。
视觉语言模型(VLMs)在各种多模态理解和生成任务中展现出显著的性能(Radford等人,2021;Li等人,2022;Singh等人,2022;Li等人,2019)。 尽管多模态模型在各种任务中表现出色,但这些模型能否有效地捕捉结构化知识(即理解对象属性和对象之间关系的能力)的问题仍然悬而未决。
例如,如图11所示,图像与正确匹配的标题(“一名宇航员骑着一匹马”)之间的CLIP得分(即语义相似度)与图像与不匹配标题(“一匹马骑着一名宇航员”)之间的得分相比,值较低。 随后,图1 (b)说明了交换两个对象之间的属性也会对模型准确区分造成挑战。 它们的语义。 这些发现表明,CLIP模型产生的通用表示无法区分包含相同单词但在结构化知识方面存在差异的文本片段。 换句话说,CLIP模型表现出类似于词袋方法的倾向,这种方法不理解句子中的细粒度语义(Lin等人,2023)。
Winoground(Thrush等人,2022) 是第一个关注 这个问题并进行了广泛研究的工作。 他们故意创建了一个包含400个实例的数据集,其中每个实例包含两个单词组成相同但语义不同的句子。 他们评估了各种性能良好的VLM(例如,VinVL(Zhang等人,2021),UNITER(Chen等人,2020),ViLBERT(Lu等人,2019)和CLIP(Radford等人,2021)),旨在评估与对象、属性和关系相关的结构化表示。 不幸的是,他们的研究结果表明,尽管这些模型在其他任务中表现出与人类水平相当的能力,但其结果与随机选择相当。 这些任务的结果表明,一般的表示不足以 进行语义理解。 因此可以推断,应该更加重视结构化表示。
NegCLIP (Yüksekgönül et al. 2022) 通过整合特定任务的负样本增强结构化表示,这些负样本是通过随机交换句子中任意两个单词生成的。 因此,虽然通用表示在正样本和负样本中保持一致性,但结构化表示则表现出差异。 通过采用对比学习方法,它迫使模型获取结构化表示而不是通用表示。 此外,NegCLIP 还提供了一个大规模的测试平台,用于评估视觉语言模型 (VLMs) 在结构化表示方面的能力。 然而,NegCLIP 存在一个缺点,即在负样本构建过程中缺乏对语义知识的理解和建模,这导致负样本质量显著下降。 例如,当在原始标题“黑白奶牛”中互换“白色”和“黑色”属性时,句子的底层语义含义保持不变。 这种低质量的负样本进一步导致性能下降。
在本文中,我们提出了一种新方法 Structure-CLIP,它利用_场景图知识_(SGK) 来增强多模态结构化表示。 首先,与 NegCLIP 中的随机交换方法相反,我们利用 SGK 来构建更符合底层意图的单词交换。 其次,我们提出了一种_知识增强编码器_(KEE),利用 SGK 来提取重要的结构信息。 通过在输入层整合结构化知识,提出的 KEE 可以进一步增强结构化表示的能力。 在 Visual Genome Relation 和 Visual Genome Attribution 上的结果显示了 Structure-CLIP 的_最先进_(SOTA)性能及其组件的有效性。 此外,我们在 MSCOCO 上进行了跨模态检索评估,结果表明 Structure-CLIP 仍然保留了足够的通用表示能力。
总体而言,我们的贡献有三方面:
-
据我们所知,Structure-CLIP 是第一个通过构建_语义负_样本增强详细结构化表示的方法。
-
Structure-CLIP 中引入了一个_知识增强编码器_,利用结构化知识作为输入来增强结构化表示。
-
我们进行了全面的实验,证明Structure-CLIP能够在结构化表示的下游任务上取得最先进的性能,并在结构化表示上取得显著改进。
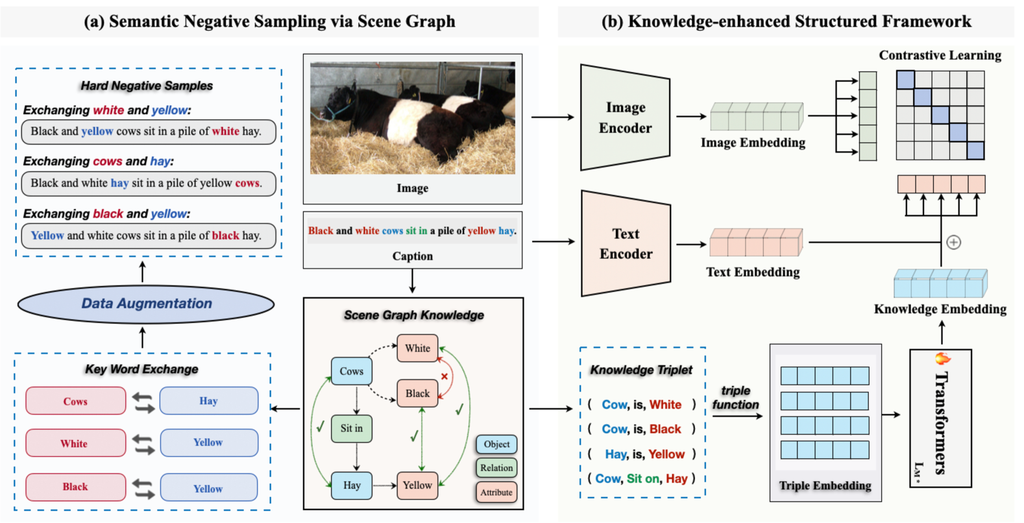
图2: Structure-CLIP概述。 (a) 基于场景图的语义负采样:我们从标题中提取场景图,以帮助构建高质量的负样本(左部分)。 (b)知识增强编码器:知识嵌入模块和多个Transformer层用于在输入级别建模结构化知识(右部分)。
二、相关工作
2.1视觉语言预训练
视觉语言模型 (VLMs)旨在学习通用的跨模态表示,这有利于在下游多模态任务中取得良好的性能。 根据多模态下游任务的不同,已经开发出不同的模型架构,包括双编码器架构(Radford et al. 2021; Jia et al. 2021)、融合编码器架构(Tan and Bansal 2019; Li et al. 2021a)、编码器-解码器架构(Cho et al. 2021; Wang et al. 2022c; Chen et al. 2022a),以及最近的统一Transformer架构(Li et al. 2022; Wang et al. 2022a)。
预训练任务对VLMs可以从数据中学到什么有很大的影响。 主要有4种类型的任务: (i)跨模态掩码语言建模 (MLM) (Kim, Son, and Kim 2021; Lin et al. 2020; Li et al. 2021a; Yu et al. 2022); (ii)跨模态掩码区域预测 (MRP) (Lu et al. 2019; Chen et al. 2020; Huang et al. 2021); (iii)图像文本匹配 (ITM) (Li et al. 2020; Lu et al. 2019; Chen et al. 2020; Huang et al. 2021); (iv)跨模态对比学习 (CMCL) (Radford et al. 2021; Jia et al. 2021; Li et al. 2021a; Huo et al. 2021; Li et al. 2021b)。
最近的研究主要集中在CMCL的研究上。 以CLIP模型(Radford et al. 2021)为例,该模型通过将正样本与数据集中所有其他样本的负样本进行比较,学习到了足够的通用表示。
2.2结构化表示学习
结构化表示指的是匹配具有相同词组成的图像和文本的能力。Winoground(Thrush等人,2022) 首次提出了一项用于评估视觉语言模型 (VLMs)能力的新任务和数据集。 该数据集主要包含400个手工制作的实例,其中每个实例包括两句词语构成相似但语义不同的句子,以及相应的图像。Winoground 的评估结果通过一系列相关任务(即探测任务、图像检索任务)的实验确定了数据集的主要挑战,表明视觉方面的主要挑战-语言模型可能在于融合视觉和文本表示,而不是理解组合语言。
由于Winoground测试数据的数量有限,因此很难得出关于结构表示能力的可靠实验结果。 最近,NegCLIP (Yüksekgönül等人,2022)提供了一个大型测试平台来评估VLMs的结构化表示。 此外,NegCLIP还提出了一种负采样方法来增强结构化表示。
2.3场景图生成
一个场景图是一种结构化知识,它通过对对象、对象的属性以及对象和主体之间关系的建模,描述了多模态样本的最重要部分。 通常,_场景图生成 (SGG)_模型包含三个主要模块:用于定位对象边界框的候选区域生成、用于标记检测到的对象的物体分类以及用于预测成对对象之间关系的关系预测。 一些现有的工作(Xu等人,2017; Yang等人,2018; Zellers等人,2018)应用RNNs和GCNs来传播图像上下文,以便更好地利用上下文进行对象和关系预测。VCTree(Tang等人,2019)通过利用动态树结构捕获局部和全局视觉上下文。 Gu等人 (2019)和Chen等人 (2019)将外部知识整合到SGG模型中,以解决噪声标注的偏差。
作为描述图像和标题详细语义的有益先验知识,场景图已帮助在多个视觉语言任务中取得了优异的性能。 例如图像字幕(Yang等人,2019)、图像检索(Wu等人,2019a)、视觉问答(Zhang, Chao和Xuan,2019; Wang等人,2022b)、多模态情感分类(Huang等人,2022)、图像生成(Johnson, Gupta和Fei-Fei,2018)和视觉语言预训练(Yu等人,2021)。
三、方法
Structure-CLIP 的概述如图2所示。 首先,我们的方法利用场景图通过生成具有相同词语构成但语义细节不同的语义负样本(图2的左侧部分)来增强细粒度结构化表示。 其次,我们提出了一种知识增强编码器,它利用场景图作为输入,将结构化知识集成到结构化表示中(图2的右侧部分)。 我们将在3.1节介绍通过场景图进行语义负采样,并在3.2节介绍知识增强编码器。
3.1通过场景图进行语义负采样
Faghri等人 (2018)提出了一种负采样方法,该方法涉及构建负样本以通过将它们与正样本进行比较来增强表示。 我们的目标是构建具有相似一般表示但语义细节不同的样本,从而鼓励模型专注于学习结构化表示。
场景图生成。
包括对象、对象的属性以及对象之间关系在内的详细语义对于理解视觉场景至关重要。 它们对于旨在增强视觉和语言联合表示的跨模态学习至关重要。 在我们的框架中,采用(Wu等人 2019b)提供的场景图解析器将文本解析为场景图。 给定文本句子𝐰,我们将其解析为场景图(Johnson等人 2015),表示为G(𝐰)=<O(𝐰),E(𝐰),K(𝐰)>,其中O(𝐰)是𝐰中提到的对象的集合,R(𝐰) 是关系节点的集合,而E(𝐰)⊆O(𝐰)×R(𝐰)×O(𝐰)是表示对象之间实际关系的超边的集合。 K(𝐰)⊆O(𝐰)×A(𝐰)是属性对的集合,其中A(𝐰)是与对象关联的属性节点的集合。
如图2所示,我们基于原始标题生成场景图。 以图2中“黑白奶牛坐在一堆黄色的干草上”的标题为例,在生成的场景图中, 对象,例如“奶牛”和“干草”,是基本元素。 相关的属性,例如“白色”和“黄色”,描述了物体的颜色或其他属性。 诸如“坐在”之类的关系表示物体之间的空间连接。
语义负样本的选择。
对比学习旨在通过将语义上接近的邻居拉近,并将非邻居推开,来学习有效的表示。 我们的目标是构建具有相似构成但语义细节不同的语义负样本。 因此,负样本的质量在结构化表示学习中起着至关重要的作用。
一个多模态数据集通常由N个图像-文本对组成,其中图像和文本分别用带下标的I和W表示。 给定一个图像-文本对(I_i,W_i)和一个由W_i生成的相关的场景图G(W_i),一个高质量的语义负样本W_i−通过
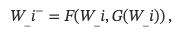
其中F是提出的采样函数,W_i−表示高质量的语义负样本。 具体来说,对于场景图中的三元组(object,relation,subject),W_i−通过
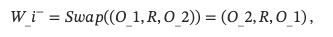
其中Swap是交换句子中宾语和主语的函数,O_1,R,O_2表示宾语、关系和主语。 对于属性对 (A1,O1) 和(A2,O2) 在场景图中,W_i−通过
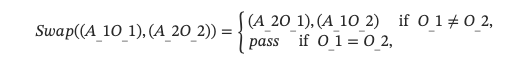
总体而言,我们利用场景图指导来构建高质量的语义负样本,而不是随机交换词语位置。 我们的语义负样本保持相同的句子构成,同时改变细节语义。 因此,我们的模型能够更有效地学习详细语义的结构化表示。
对比学习目标。
我们的对比学习目标是通过将图像I_i和原始标题W_i拉近,并将图像I_i和负样本W_i−推远来学习足够的表示。 具体来说,我们引入了一个具有损失函数的多模态对比学习模块:
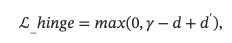
其中γ是边际超参数,d表示图像I_i和原始标题W_i之间的距离,而d′表示图像I_i和原始标题W_i−之间的距离。 引入对比学习目标是为了提高结构化表示的性能。 同时,为了保持模型的一般表示能力,我们将原始的小批量图像-文本对比学习损失和提出的损失结合起来进行联合训练。
原始的图像-文本对比学习损失ℒ_ITCL包含图像到文本的对比损失ℒ_i2t和文本到图像的对比损失ℒ_t2i,它们
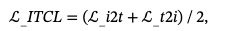
图像到文本的对比损失ℒ_i2t的公式为
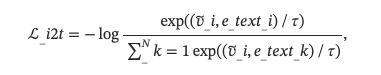
其中τ是温度超参数。 类似地,文本到图像的对比损失ℒ_t2i为
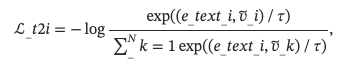
因此,最终的损失,它结合了铰链损失和InfoNCE损失,为
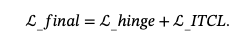
表1:结果(%)在VG-Relation、VG-Attribution和MSCOCO数据集上比较我们的方法和其他基线。 匹配分数分别通过多模态模型中图像嵌入和文本嵌入之间的语义相似性以及大型语言模型中的最大似然概率获得。
| Domains | Models | Params | Visual Gnome | MSCOCO | ||
| Attribute | Relation | IR-R@1 | TR-R@1 | |||
| - | Random Chance | - | 50.00 | 50.0 | 0.02 | 0.1 |
| Multi-modal Models | VILT (VIT-B/32) | 87 M | 20.3 | 39.5 | 37.3 | 53.4 |
| FLAVA | 241 M | 58.1 | 28.0 | 38.5 | 43.5 | |
| CLIP-Base (ViT-B/32) | 151 M | 60.1 | 59.8 | 30.4 | 50.1 | |
| CLIP-Large (ViT-L/14) | 427M | 61.1 | 61.5 | 36.5 | 56.3 | |
| Neg-CLIP | 151 M | 71.0 | 81.0 | 41.0 | 56.0 | |
| Large Language Models | BART | 300 M | 73.6 | 81.1 | - | - |
| FLAN-T5 | 11 B | 76.5 | 84.4 | - | - | |
| OPT | 175 B | 79.8 | 84.7 | - | - | |
| Ours | Sturcture-CLIP-Base | 220 M | 82.3 | 84.7 | 41.2 | 55.6 |
| Structure-CLIP-Large | 496 M | 83.5 | 85.1 | 48.9 | 58.2 | |
3.2知识增强编码器
在本节中,我们提出了一种知识增强编码器,它利用场景图作为文本输入来增强结构化表示。 首先,我们使用以下函数对图像I_i和文本W_i进行编码:

其中CLIP_vis和CLIP_text分别表示CLIP模型的视觉编码器和文本编码器。
然而,CLIP模型以词袋的方式处理文本输入,忽略了文本的详细语义。 相反,结合场景图可以捕捉句子中关键的结构信息,从而使模型能够更深入地理解文本的细粒度语义。
因此,该知识增强编码器显式地将详细的知识建模为模型输入,即对象、对象的属性以及成对对象之间的关系。 具体来说,我们对两种结构化知识:对和三元组,制定了统一的输入规范。 我们将关系连词“is”添加到该对中以统一表示。 例如,以这种方式,对 (white,cow) 将被视为三元组 (cow,is,white)。 这样就得到了一组三元组𝒯_in={(h_i,r_i,t_i)|i∈[1,k]}, 其中(h_i,r_i,t_i)分别表示头实体、关系实体和尾实体。 对于 𝒯_in 中的每个三元组 (h_i,r_i,t_i),我们使用 BERT (Devlin 等人 2019) 中的 Tokenizer 和 Word Vocabulary Embeddings 来获取每个实体嵌入w_h,w_r,w_t:

为了获得每个实体嵌入的三重嵌入,我们使用以下编码函数:
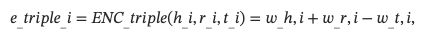
其中ENC_triple(.) 是三重编码函数。 有了这个三重编码器,我们的方法可以更好地解决头尾实体顺序颠倒的问题,详细分析在第2节中进行了说明。4.4.3.
通过这种方式,K个三元组可以被处理成K个语义嵌入。 然后我们将e_triple输入到多个Transformer层以获得最终表示。
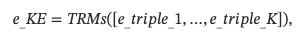
知识增强编码器使我们能够从所有输入的三元组中提取足够的结构化知识,这可以作为有效的结构化知识来提高结构化表示的性能。
因此,知识增强编码器可以用来获得文本知识嵌入s。 然而,仅仅依赖结构化知识可能会导致丢失一般语义的表示。 因此,我们整合了文本嵌入s和结构化知识嵌入s:
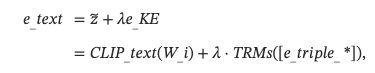
其中λ是一个超参数,z~和e_KE分别表示原始文本嵌入和结构化知识嵌入。
我们的文本表示包含整个句子携带的单词信息以及句子中详细语义组成的结构化知识。 同样,我们在训练过程中使用了公式5中所示的相同损失策略。
表2: VG-Relation和VG-Attribution数据集上消融研究的结果(%),用于分析不同的组件。 结果表明,每个组件都极大地提高了结构化表示的能力。
| Methods | Finetune | Negatives | KEE | VG-Attribution | VG-Relation |
| CLIP | ✗ | ✗ | ✗ | 60.1 | 59.8 |
| CLIP (fine-tune) | MSCOCO (ours) | ✗ | ✗ | 64.0 | 66.5 |
| Neg-CLIP | MSCOCO (full) | Random | ✗ | 71.0 | 81.0 |
| w/ {Random Change} | MSCOCO (ours) | Random | ✗ | 73.9 | 77.7 |
| w/ {Semantic Negative} | MSCOCO (ours) | Semantic | ✗ | 77.8 | 79.0 |
| w/ {Transformer} | MSCOCO (ours) | ✗ | ✓ | 65.7 | 68.8 |
| Structure-CLIP (Ours) | MSCOCO (ours) | Semantic | ✓ | 82.3 (↑11.3) | 84.7 (↑3.7) |
表3: 不同超参数和嵌入方法的消融研究。
| Types | KEE Layers | Fusion Weight (λ) | Embedding Fusion (ENC_triple) | VG-Attribution | VG-Relation |
| Layers | 1 layer | 0.2 | head + relation - tail | 82.1 | 82.9 |
| 2 layers | 0.2 | head + relation - tail | 82.2 | 83.3 | |
| 6 layers | 0.2 | head + relation - tail | 82.3 | 84.7 | |
| 12 layers | 0.2 | head + relation - tail | 81.9 | 83.2 | |
| Weight | 6 layers | 0.0 | head + relation - tail | 77.8 | 79.0 |
| 6 layers | 0.01 | head + relation - tail | 82.7 | 83.5 | |
| 6 layers | 0.2 | head + relation - tail | 82.3 | 84.7 | |
| 6 layers | 1.0 | head + relation - tail | 82.3 | 83.8 | |
| Embedding | 6 layers | 0.2 | Concat | 81.1 | 83.3 |
| 6 layers | 0.2 | head + relation + tail | 81.9 | 83.3 | |
| 6 layers | 0.2 | head + relation - tail | 82.3 | 84.7 | |
四、实验
4.1数据集
预训练数据集。
高质量的图像-文本对齐数据是训练模型的关键方面。 我们采用了广泛使用的跨模态文本-图像检索数据集 MSCOCO(Lin et al. 2014)。 与之前的工作(Li et al. 2022)一致,我们使用 Karpathy (Karpathy and Fei-Fei 2017) 分割进行训练和评估。 在我们的实验中,预训练是通过过滤大约 10 万个包含多个对象、属性和关系的图像-文本对来进行的。 随后,对模型在包含 5000 张图像的测试集上进行评估。 我们报告了图像到文本检索(IR)和文本到图像检索(TR)上的 Recall@1,以衡量通用表示的能力。
下游数据集。
两个新的数据集(Yüksekgönül et al. 2022)用于评估不同模型的结构化表示性能,其中每个测试用例都包含一张图像及其匹配的标题和交换后的不匹配标题。 模型的任务是根据相应的图像区分对齐和未对齐的标题。
-
Visual Genome 关系 (VG-Relation)。 给定一张图像和一个包含关系三元组的标题,我们评估模型选择与图像关系对齐的标题的能力。 具体来说,我们希望模型能够区分特定图像的“X关系Y”和“Y关系X”(例如,“一名宇航员正在骑着一匹马”v.s.“一匹马正在骑着一匹马宇航员”与图1
-
Visual Genome 属性 (VG-Attribution)。 给定形式“A_1O_1和A_2O_2”和“A_2O_1和A_1O_2”,我们评估模型准确地对对象属性进行归属的能力。 如图1(b)所示,我们期望模型根据图像区分标题“红色连衣裙和蓝色书籍”和标题“蓝色连衣裙和正确的书籍”。
4.2实验设置
所有实验均在单块 NVIDIA A100 GPU 上使用 Pytorch 框架进行。 我们利用预训练的场景图生成器(Wu et al. 2019b)提取场景图知识。
结构化的知识增强编码器使用具有6层 Transformer 架构的 BERT-base (Devlin et al. 2019)进行初始化实现。
在训练阶段,我们使用预训练的 CLIP 模型初始化模型,并在我们的数据集上使用 128 的批量大小训练 10 个 epoch。 我们使用带 0.1 权重衰减的 mini-batch AdamW 优化器。 学习率初始化为 2e-6。 知识权重λ为 0.2。
4.3总体结果
结构化表示任务。
我们将我们的方法与_8_种具有代表性或最先进的方法进行比较,包括多模态模型和大型语言模型。 如表1所示,我们注意到我们的 Structure-CLIP 在 VG-Relation 和 VG-Attribute 数据集上取得了优于所有基线的最佳性能。
首先,很明显,NegCLIP 在结构化表示方面优于 CLIP 模型,这表明上述负样本采样方法可以显著增强结构化表示。 此外,通过利用场景图知识的指导来提高构建负样本的质量,Structure-CLIP 实现了对结构化表示的进一步增强。 结果,Structure-CLIP 在 VG-Attribution 上优于现有的多模态 SOTA 模型 (NegCLIP) 12.5%,在 VG-Relation 上优于 4.1%。
我们还将 Structure-CLIP 与现有的使用最大似然概率对图像和文本进行匹配评分的大型语言模型 (LLM) 进行了比较。 我们的结果表明,随着大语言模型(LLM)模型参数的显著增加,其结构化表示也相应得到改善。 然而,即使Structure-CLIP的参数不到OPT模型的1%,它仍然分别比OPT模型高出3.7%和0.4%。 我们的结果表明,增加模型参数以改进结构化表示是资源密集型的,并且性能欠佳,因为模型在训练阶段主要学习的是通用表示而不是结构化表示。 相反,我们提出的Structure-CLIP方法只需少量增加模型参数和少量训练即可显著增强结构化表示。
通用表示任务。
我们评估了Structure-CLIP在通用表示任务上的性能。 在基础模型模式下,Structure-CLIP在MSCOCO数据集上取得了与NegCLIP相当的性能。 换句话说,在很大程度上提高了结构化表示的性能的同时,Structure-CLIP保留了通用表示的能力。 此外,我们的结果表明,使用Structure-CLIP可以同时获得足够的通用表示和结构化表示,而之前的模型生成的结构化表示不足。 在大型模型设置下,我们提出的领域微调方法与域外模型相比,显著增强了结构化表示和通用表示。
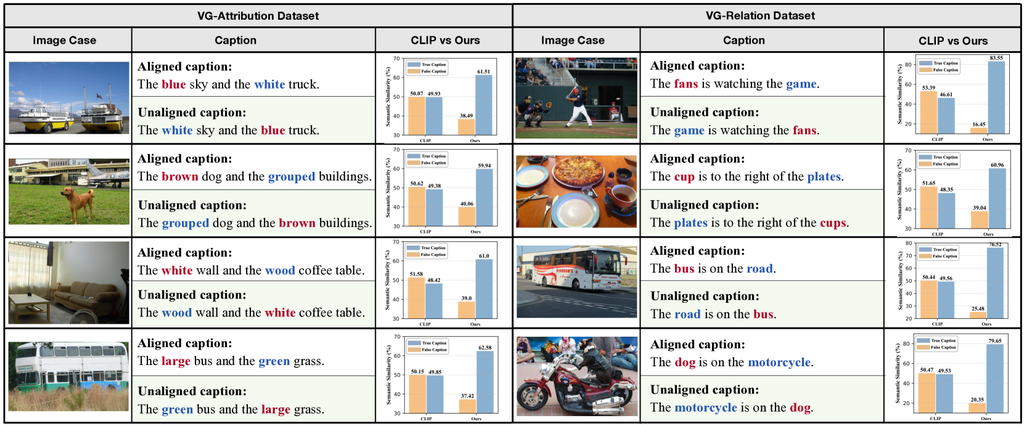
图3: 不同方法的预测结果。 红色和蓝色的单词是两个交换的单词。 我们将我们的Structure-CLIP与CLIP进行比较,以计算图像和标题之间的CLIP分数(即语义相似度)。
4.4消融研究
成分分析。
我们对VG-Relation和VG-Attribution数据集上的CLIP-base模型的多个增强版本进行了消融研究。 各个变体的结果如表2所示。
首先,我们的实验结果表明,应用_语义负例_而不是_随机负例_采样策略时,性能得到了显著提升(第4行与第5行)。VG-Attribution和VG-Relation数据集上的性能分别提高了3.9%和1.3%,这表明该方法生成了更高质量的负例,从而产生了更优的结构化表示。
通过提出的知识增强编码器将结构化知识作为输入,仅产生了轻微的改进(第2行与第6行)。 这些发现意味着,为了获得足够的结构化表示,必须结合负例采样。 因此,知识增强编码器在与语义负采样结合后实现了显著的增强(第5行与第7行)。
超参数分析。
基于表3中所示的Structure-CLIP的实验结果,我们可以得出以下结论:(i) 随着知识Transformer层数的增加,模型表示多模态结构化表示的能力得到提高。 然而,重要的是要注意,超过某个阈值后,可用数据可能不足以支持模型增加的容量,从而可能导致过拟合。 (ii) 实验结果表明,在没有结构化知识集成的情况下,模型的性能不令人满意(第5行)。 相反,当集成结构化知识时,不同权重下的性能差异最小,这表明我们的方法在增强结构表示方面的有效性和直观性。
三元组嵌入。
我们探索了三种不同的用于集成三元组的三元组嵌入方式。 _拼接_方法考虑了输入三元组元素的顺序,但没有考虑头部实体、关系实体和尾部实体的组合。 _头部+关系+尾部_方法结合了三元组之间的组合关系。 然而,它们缺乏区分三元组顺序的能力。 例如,两个三元组的最终嵌入,(cow,is,white)和(white,is,cow)是相同的,这无法帮助模型进行区分。 与这些方法相比,我们的三元组嵌入方法同时考虑了位置和组合信息。 通过这种方式,我们的Structure-CLIP模型能够更好地利用句子中的结构化知识来捕捉细粒度的语义信息,并增强多模态结构化表示。
4.5案例研究
VG-Relation和VG-Attribution中案例的预测结果如3所示,这清楚地表明Structure-CLIP能够成功区分对齐的和未对齐的标题,前提是给定一张图像,且具有非常大的边距。 然而,CLIP模型在准确确定这些标题与给定图像之间的语义相似性方面面临挑战。 特别是,当交换两个属性或对象时,CLIP模型表现出近乎一致的语义相似性,这表明它缺乏捕捉结构化语义的能力。 与CLIP模型相比,Structure-CLIP对细粒度语义的修改表现出敏感性,表明其在表示结构化知识方面的能力。 例如,标题“蓝色的天空和白色的卡车”用于评估Structure-CLIP区分对齐的和未对齐的标题的能力,其中交换了两个属性(即蓝色和白色)。 结果表明,Structure-CLIP能够以25.16%的边距区分区分对齐的和未对齐的标题,这进一步验证了该方法在增强多模态结构化表示方面的有效性。
五、结论
在本文中,我们提出了Structure-CLIP,旨在集成场景图知识以增强多模态结构化表示。 首先,我们使用场景图来指导构建语义负例。 此外,我们引入了一个知识增强编码器,它利用场景图知识作为输入,从而进一步增强结构化表示。 我们提出的Structure-CLIP在预训练任务和下游任务上都优于所有最新的方法,这说明Structure-CLIP能够有效且鲁棒地理解多模态场景中的详细语义。
六、如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方优快云官方认证二维码,免费领取【保证100%免费】


















 764
764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









