



大家都遇到过这种类似的情况,一个看似微不足道但实际影响深远的问题正困扰着很多AI应用开发者:**为什么看似相似的提示词会导致模型生成截然不同的输出?**这种现象不仅影响用户体验,还严重制约了 LLM 在关键应用场景中的可靠性。
让我们以一个具体的例子来说明。当我们向模型提问“解释认知偏差的概念”时,仅仅改变措辞方式,就可能得到截然不同的输出:
- “Explain the concept of cognitive biases”
- “Interpret the idea of cognitive biases”
- “Expound on the concept of cognitive biases”
- “Elaborate on the concept of cognitive biases”
这些在人类看来几乎完全等价的表达,却可能导致模型生成显著不同的答案。模型对这些微小变化表现出的敏感性使得提示工程的效果变得不可预测,甚至难以控制。
为了解决这一问题,来自印度理工学院德里分校和 Adobe 研究团队的研究者们提出了一种名为 POSIX(PrOmpt Sensitivity IndeX) 的新指标。POSIX 是首个能够全面衡量 LLM 对提示词变化敏感程度的指标体系。本文将详细介绍 POSIX 的原理、实现方法、研究过程及其在多个模型上的应用,并讨论为什么提示的微小变化会对模型的输出产生显著影响。

一、提示敏感性问题的背景
大型语言模型(如 GPT-3、LLaMA 等)在庞大的语料库上预训练,具备处理多样自然语言任务的能力。然而,研究者发现,即便是输入提示中微小的变化,比如拼写错误、措辞的改变或者提示模板的调整,都会导致模型生成截然不同的输出。这种现象凸显了模型对输入提示的敏感性,也使得模型的行为变得难以预测。
标准的模型评估基准如 MMLU(Massive Multitask Language Understanding,旨在评估模型在多任务上的理解和推理能力)或 BBH(Big Bench Hard,用于评估模型在广泛、多样任务上的表现)通常侧重于评估模型在下游任务上的性能,却忽略了对提示敏感性的系统性评估。这种缺失导致用户在使用模型时难以预估哪种提示能够获得最佳输出,而这在现实场景中显得尤为重要,因为普通用户可能无法总是精准地编写“最佳”提示。
二、POSIX:首个全面的提示词敏感度量指标
POSIX,这是首个全面衡量 LLM 对提示词变化敏感程度的指标体系。研究团队在对 Llama-2、Mistral、OLMo 等主流开源模型的系统评估中,揭示了一系列令人深思的发现。
1、POSIX 的创新之处
POSIX 突破性地提出了四个维度的综合评估框架:
- 响应多样性(Response Diversity)
- 衡量指标:对于语义相近的提示词,模型产生不同响应的数量。
- 实验发现:在 MMLU 测试中,模型对同一问题的不同表述可能产生 2-20 个不同的响应。
- 影响因素:提示词变化类型、模型架构、任务类型。
- 响应分布熵(Response Distribution Entropy)
- 定义:各种响应出现频率的分布均匀程度。
- 重要性:反映模型对提示词变化的稳定性。
- 数据显示:高敏感度模型的响应分布熵普遍在 0.5-2.5 之间波动。
- 语义连贯性(Semantic Coherence)
- 评估方法:使用余弦相似度计算不同响应间的语义相似程度。
- 基准范围:0.75-1.00,越接近 1 表示响应越稳定。
- 关键发现:即使语义相似度高,模型的置信度可能差异显著。
- 置信度方差(Confidence Variance)
- 测量维度:模型对相同响应在不同提示词下的概率评估波动。
- 实验数据:对于相同的响应,概率对数方差可达 0.0-2.5。
- 启示:高置信度并不一定意味着低敏感性。
2、如何理解 POSIX 的工作原理
为了深入理解 POSIX 的工作原理,我们需要引入一些预备概念和正式定义。
预备知识
定义 1(意图一致的提示)
任意两个提示 ( x_1 ) 和 ( x_2 ),如果它们尽管在措辞、模板或包含的轻微拼写错误上有所不同,但设计的目的是基于相同的底层目标、意图或含义来从语言模型中获取响应,那么它们被称为意图一致的提示。
定义 2(意图一致的提示集)
一个提示集合 ( X = { x_i }_{i=1}^N ),当且仅当对于所有 ( 1 \leq i \neq j \leq N ),( x_i \in X ) 和 ( x_j \in X ) 是意图一致的提示时,称其为意图一致的提示集。
POSIX 的定义
定义 3(提示敏感性)
设 ( X = { x_i }{i=1}^N ) 是一个意图一致的提示集,( Y = { y_i }{i=1}^N ) 是对应的由语言模型 ( M ) 生成的响应集合,即 ( y_i ) 是模型 ( M ) 在提示 ( x_i ) 下生成的响应。则 ( M ) 在提示集 ( X ) 上的提示敏感性定义为:

其中:
- ( N ) 是提示集 ( X ) 的大小。
- ( L_{y_j} ) 是响应 ( y_j ) 的 token 数量。
- ( P_M(y_j \mid x_i) ) 是在提示 ( x_i ) 下生成响应 ( y_j ) 的概率。
- ( P_M(y_j \mid x_j) ) 是在提示 ( x_j ) 下生成响应 ( y_j ) 的概率。
定义 4(POSIX 指数)
给定一个语言模型 ( M ) 和一个数据集 ( D = { X_i }_{i=1}^M ),其中每个 ( X_i ) 是意图一致的提示集,则模型 ( M ) 在数据集 ( D ) 上的 PrOmpt Sensitivity IndeX(POSIX)定义为:
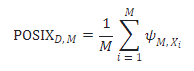
这个指标表示了模型 ( M ) 在整个数据集 ( D ) 上的平均提示敏感性。
POSIX 的含义
POSIX 通过计算模型在不同但意图一致的提示下生成相同响应的概率变化,量化了模型对提示变化的敏感程度。敏感性越高,表示模型对提示的微小变化越敏感,生成的响应概率差异越大。
三、研究方法与过程
数据集与模型选择
为了验证 POSIX 的有效性,研究者们选择了 MMLU 数据集(用于多选题任务)和 Alpaca 数据集(用于开放式生成任务)进行实验。实验中涉及的模型包括 LLaMA、Mistral 和 OLMo 等多个开源大型语言模型,涵盖了不同的模型规模和架构。
在实验中,研究者们为每个提示生成了 60 个意图保持一致的变体,这些变体包括以下三种类型的变化:
- 拼写错误:随机选择提示中的词语并引入拼写错误,例如插入、删除、替换或交换字母。
- 提示模板:使用不同的语法和格式重写提示,保持其核心含义不变。
- 改写:使用 GPT-3.5-Turbo 生成提示的多种改写版本,确保保留原始意图。
选择这些类型的原因是为了全面覆盖可能的提示变动方式,从而评估模型对不同类型变化的敏感性。拼写错误用于测试模型对输入中的小错误的鲁棒性,提示模板变化用于评估模型对结构变化的适应性,而改写则考察模型对语义保留但表述变化的反应能力。
POSIX 的计算
为了计算 POSIX,研究者们基于每个提示及其变体生成的响应的对数似然比。具体而言,对于每一组意图一致的提示集,计算模型在不同提示下生成相应响应的概率的对数比值,然后对这些比值进行长度归一化,最终得到一个可比较的敏感性度量,即 POSIX 指数。
四、实验结果与分析
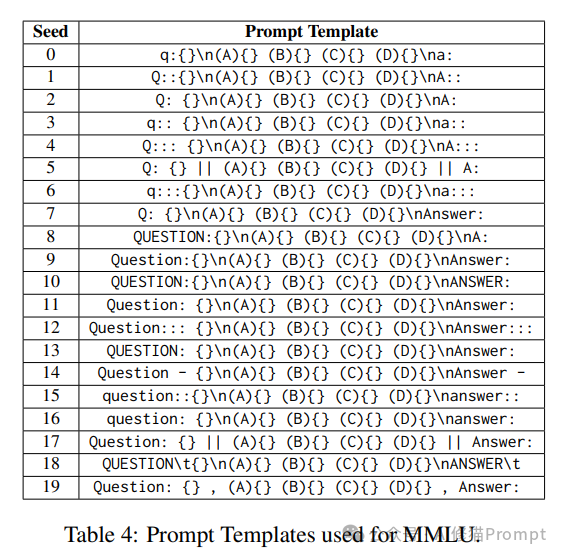
提示模板对敏感性的影响最大
研究结果表明,在多选题任务(如 MMLU)中,提示模板的变化导致了最大的敏感性。这意味着对于这些任务,提示的格式和结构对模型的响应影响非常大。相反,在开放式生成任务(如 Alpaca)中,改写(paraphrasing)导致的敏感性最高,这表明在这些任务中,提示的具体措辞对生成结果的影响更为显著。
模型规模与敏感性之间的反直觉关系
进一步的实验结果显示,模型的参数规模增加并不一定会降低敏感性。模型规模变大,提示的格式敏感性降低(表现出更高的稳健性),与本文结论相反,但那是GPT4和GPT3.5之间的对比,请您注意区分。例如,在对比 LLaMA-2 的 7B 和 13B 模型时,发现较大的模型在某些情况下反而对提示更为敏感。这表明,模型的准确性和提示敏感性是两个独立的维度,提升模型的性能并不必然改善其对提示的稳定性。
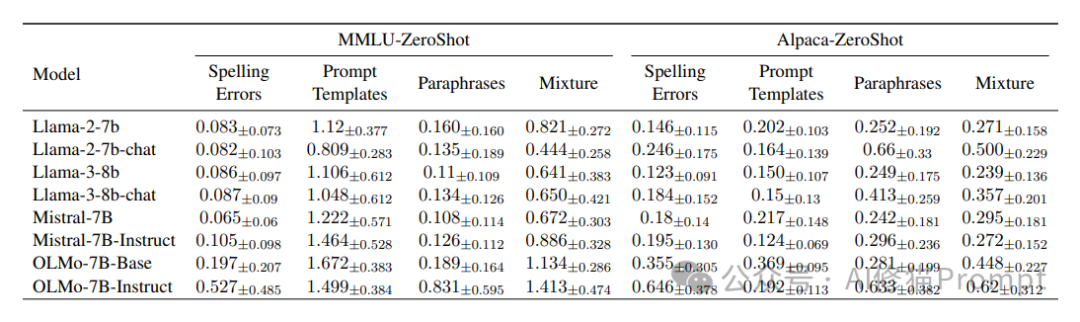
这些数据明确显示:模型参数量的增加并不必然带来更好的提示词鲁棒性。
指令调优与敏感性
研究还发现,经过指令调优(instruction tuning)的模型在某些情况下对提示的敏感性有所降低,但在开放式生成任务中,这些模型的敏感性反而增加。这一结果表明,指令调优并不是解决提示敏感性的万能手段,其效果取决于具体任务和提示类型。例如,在结构化任务(如信息提取和分类任务)中,指令调优通常能显著提高模型的性能和一致性。然而,在开放式生成任务(如自由文本生成)中,指令调优的效果可能较差,甚至会增加模型的敏感性,使其对提示的微小变化更加不稳定。
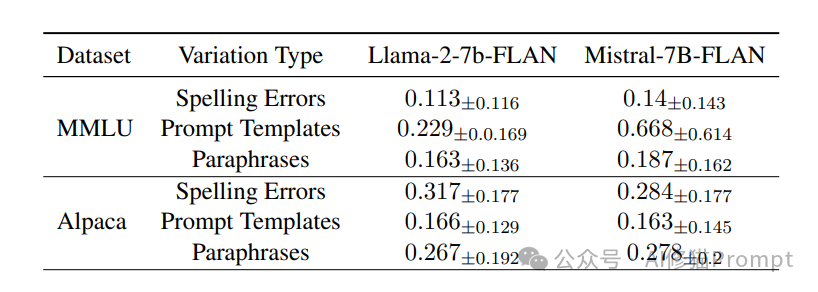
这些数据表明,单纯的指令微调可能在某些情况下反而增加了模型的敏感性。
Few-shot 示例的作用
有趣的是,研究发现加入少量示例(few-shot exemplars)可以显著降低模型的提示敏感性。这是因为 Few-shot 示例为模型提供了明确的上下文和参考,从而减少了对提示变体的依赖和不确定性。在技术上,这些示例通过增加输入的丰富性,使得模型能够更好地捕捉不同提示间的共性特征,进而提升对提示变化的鲁棒性。即便只加入一个示例,也能显著提升模型对提示变化的鲁棒性。不过,随着示例数量的增加,敏感性改善的幅度逐渐减小,呈现出边际效益递减的趋势。
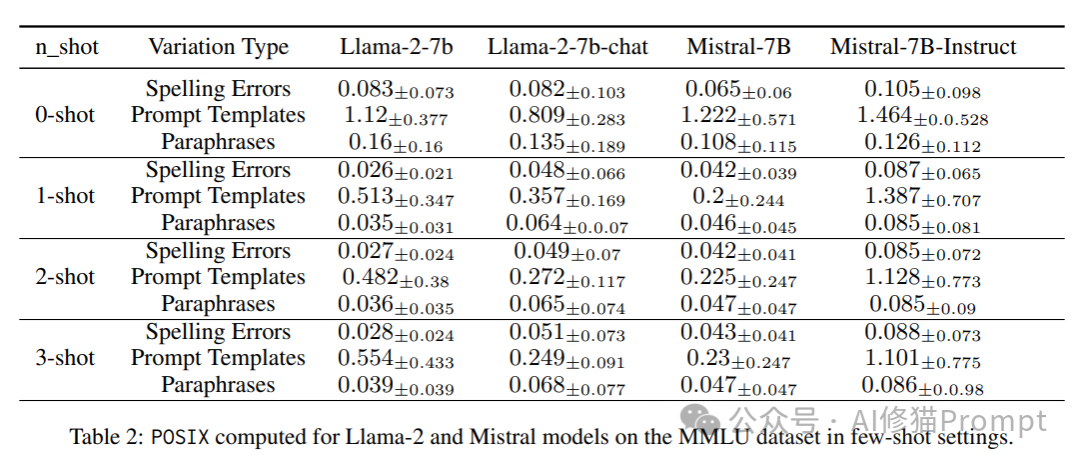
这组数据清晰地展示了示例的“一例胜千言”效应。
任务类型决定敏感性模式
研究揭示了不同任务类型的独特敏感性特征:
MCQ 任务 vs 开放式生成任务:**
MMLU(多选题):
- 提示模板变化:1.12±0.377(最敏感)
- 拼写错误:0.083±0.073
- 改写变体:0.16±0.16
Alpaca(开放式):
- 提示模板变化:0.177±0.109
- 拼写错误:0.141±0.126
- 改写变体:0.225±0.173(最敏感)
五、一些建议
基于上述研究结果,为大家在实际工作中提供一些有价值的建议:
-
精心设计提示模板:对于多选题类任务,提示模板的设计至关重要。尽量保持模板的一致性,以减少模型对格式变化的敏感性。
-
优化提示措辞:在开放式生成任务中,提示的具体措辞对输出影响显著。Prompt 工程师应关注措辞的精确性,确保提示能够明确表达意图。
-
使用 Few-shot 示例:在提示中加入几个示例可以有效降低敏感性,尤其是在模型对提示变化较为敏感的任务中,这种方法尤为有效。
- 示例选择原则:代表性、多样性和简洁性。每个示例控制在 50 个 token 以内。
- 示例数量优化:零样本到单样本的敏感性降低幅度最大,建议大多数场景下使用 1-2 个示例即可,最多不要超过3个。
-
理解模型的限制:不同规模和类型的模型在提示敏感性上表现各异,Prompt 工程师应了解所用模型的特点,选择合适的提示方式以获得最佳结果。
-
系统化测试:
- 基础测试集:包括 20 个拼写变体、20 个模板变化和 20 个改写版本。
- 评估维度:响应一致性目标 >80%、语义相似度目标 >0.9、POSIX 指数目标 <0.3。
六、结论
POSIX 为量化大型语言模型对提示变化的敏感性提供了一个新的工具。通过全面考虑响应多样性、响应分布、语义一致性和置信度方差,POSIX 能够有效捕捉模型在面对提示变化时的行为差异。与传统的评价指标(如准确率和损失函数)相比,POSIX 独特之处在于它能够全面评估模型对输入提示变化的鲁棒性,而不仅仅是对特定任务的表现。传统指标往往无法揭示模型对输入变化的脆弱性,而 POSIX 通过多个维度捕捉这种细微的敏感性,帮助工程师更好地理解模型在实际应用中的稳定性。实验结果显示,提示模板和措辞的微小变化都可能对模型的输出产生重大影响,而这些影响因任务类型和模型特性而异。您也可以在这里看论文作者的代码:
https://github.com/kowndinya-renduchintala/POSIX
对于正在开发 AI 产品的 Prompt 工程师而言,理解和利用 POSIX 可以帮助他们更好地设计提示,提升模型的稳定性和用户体验。同时,这项研究也提醒我们,大型语言模型的性能不仅取决于其规模和训练数据,还在很大程度上受到输入提示的影响。因此,在未来的模型开发和评估中,提示敏感性应作为一个重要的考量因素。
七、最后分享
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方优快云官方认证二维码,免费领取【保证100%免费】


















 953
953

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









