






近日,OpenAI前研究科学家william对外正式开源了一个号称面向未来的提示工程库,名为 ell,它将提示视为函数,并提供了一系列强大的工具来优化和管理提示。
在这个库中有一些核心设计理念值得大家学习借鉴。

一、提示是程序,而不是字符串
在传统的提示工程中,我们通常将提示视为简单的字符串。然而,ell 颠覆了这一观念,将提示视为程序。通过这种方式,我们可以将提示封装成独立的子程序,称为语言模型程序(Language Model Program, LMP)。这些 LMP 是完全封装的函数,可以生成字符串提示或消息列表,发送到各种多模态语言模型。
让我们从一个传统的 API 调用示例开始,看看如何使用 ell 实现相同的功能。以下是使用 OpenAI Chat Completion API 的简单示例:
import openai
openai.api_key = "your-api-key-here"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Say hello to Sam Altman!"}
]
response = openai.ChatCompletion.create(
model="gpt-4o",
messages=messages
)
print(response['choices'][0]['message']['content'])
现在,让我们看看如何使用 ell 实现相同的结果:
import ell
@ell.simple(model="gpt-4o")
def hello(name: str):
"""You are a helpful assistant.""" # 系统提示
return f"Say hello to {name}!" # 用户提示
greeting = hello("Sam Altman")
print(greeting)
ell 通过鼓励你将提示定义为功能单元来简化提示。在这个示例中,hello 函数通过文档字符串定义系统提示,通过返回字符串定义用户提示。提示的用户只需调用定义的函数,而不需要手动构建消息。在此基础上,我们可以进一步地改进提示。
import ell
import random
def get_random_adjective():
adjectives = ["enthusiastic", "cheerful", "warm", "friendly"]
return random.choice(adjectives)
@ell.simple(model="gpt-4o")
def hello(name: str):
"""You are a helpful assistant."""
adjective = get_random_adjective()
return f"Say a {adjective} hello to {name}!"
greeting = hello("Sam Altman")
print(greeting)
在这个示例中,我们的 hello LMP 依赖于 get_random_adjective 函数。每次调用 hello 时,它都会生成一个不同的形容词,创建动态、多样的提示。显然,ell 可使提示更具可读性、可维护性和可重用性。
二、提示工程是一个优化过程
提示工程的过程类似于机器学习中的优化过程,需要多次迭代。由于 LMP 只是函数,ell 提供了丰富的工具来支持这一过程。
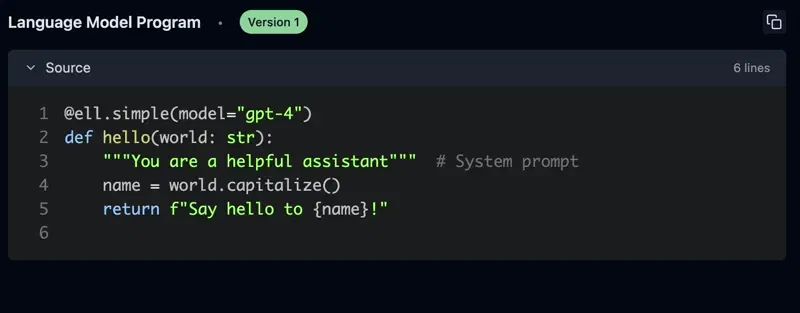
ell 通过静态和动态分析,提供了提示的自动版本控制和序列化,并生成自动提交消息到本地存储。这一过程类似于机器学习训练中的检查点,但不需要特殊的 IDE 或编辑器——只需使用常规的 Python 代码即可。
import ell
ell.init(store='./logdir') # 版本控制你的 LMP 和它们的调用
# 定义你的 LMP
hello("strawberry") # LMP 的源代码和调用被保存到存储中
同时,ell 提供了一个名为 Ell Studio 的本地开源工具,可用于提示版本控制、监控和可视化。通过 Ell Studio,你可以将提示优化过程科学化,并在问题出现之前捕捉到回归。
三、优雅实现测试时计算
从演示到实际应用,通常需要多次调用语言模型。这不仅仅是简单的字符串拼接,而是一个复杂的编程过程。通过强制功能分解问题,ell 使得在可读和模块化的方式中实现测试时计算变得容易。
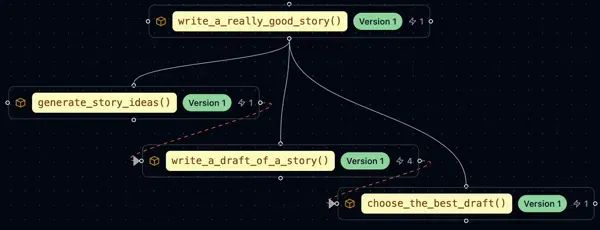
import ell
@ell.simple(model="gpt-4o-mini", temperature=1.0, n=10)
def write_ten_drafts(idea: str):
"""You are an adept story writer. The story should only be 3 paragraphs"""
return f"Write a story about {idea}."
@ell.simple(model="gpt-4o", temperature=0.1)
def choose_the_best_draft(drafts: List[str]):
"""You are an expert fiction editor."""
return f"Choose the best draft from the following list: {'\\n'.join(drafts)}."
drafts = write_ten_drafts(idea)
best_draft = choose_the_best_draft(drafts) # 从10个草稿中选择最佳草稿
测试时计算(Test-Time Computation)是机器学习和深度学习中的一个概念,指的是在模型推理阶段(也就是测试时)进行额外的计算或处理,以提高模型的性能或适应性。这种方法通常用于解决训练数据和测试数据之间存在差异的问题,或者在不重新训练模型的情况下提高模型的泛化能力。其核心思路是不重新训练模型,而是在模型实际使用时进行额外的处理,以提高模型的表现。类似于人类在应用所学知识时会根据具体情况做出适当灵活变通处理,而不是僵化执行。
每次调用语言模型都很重要
每次调用语言模型都非常宝贵,值得跟踪分析。在实践中,LLM 调用用于微调、蒸馏、k-shot 提示、从人类反馈中进行强化学习等。一个好的提示工程系统应该将这些作为一等公民概念捕捉。
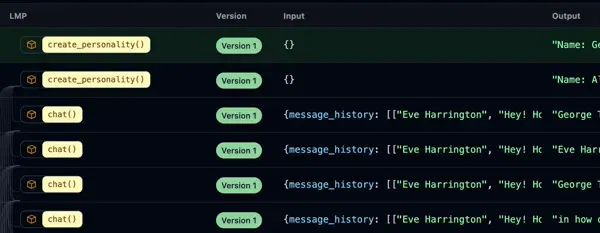
除了存储每个 LMP 的源代码外,ell 还可以选择性地本地保存每次调用语言模型的记录。这使你能够生成调用数据集,比较不同版本的 LMP 输出,并充分利用提示工程的所有工件。
四、需要时复杂,不需要时简单
使用语言模型通常只是传递字符串,但有时需要更复杂的输出。ell 提供了 @ell.simple 和 @ell.complex 装饰器,分别用于生成简单字符串输出和复杂的消息对象响应。
import ell
@ell.tool()
def scrape_website(url: str):
return requests.get(url).text
@ell.complex(model="gpt-5-omni", tools=[scrape_website])
def get_news_story(topic: str):
return [
ell.system("""Use the web to find a news story about the topic"""),
ell.user(f"Find a news story about {topic}.")
]
message_response = get_news_story("stock market")
if message_response.tool_calls:
for tool_call in message_response.tool_calls:
# 处理工具调用
pass
if message_response.text:
print(message_response.text)
if message_response.audio:
# message_response.play_audio() 支持多模态输出
pass
五、多模态是一等公民
LLM 可以处理和生成各种类型的内容,包括文本、图像、音频和视频。使用这些数据类型进行提示工程应该像处理文本一样简单。
from PIL import Image
import ell
@ell.simple(model="gpt-4o", temperature=0.1)
def describe_activity(image: Image.Image):
return [
ell.system("You are VisionGPT. Answer <5 words all lower case."),
ell.user(["Describe what the person in the image is doing:", image])
]
# 从摄像头捕捉图像
describe_activity(capture_webcam_image()) # 输出: "they are holding a book"
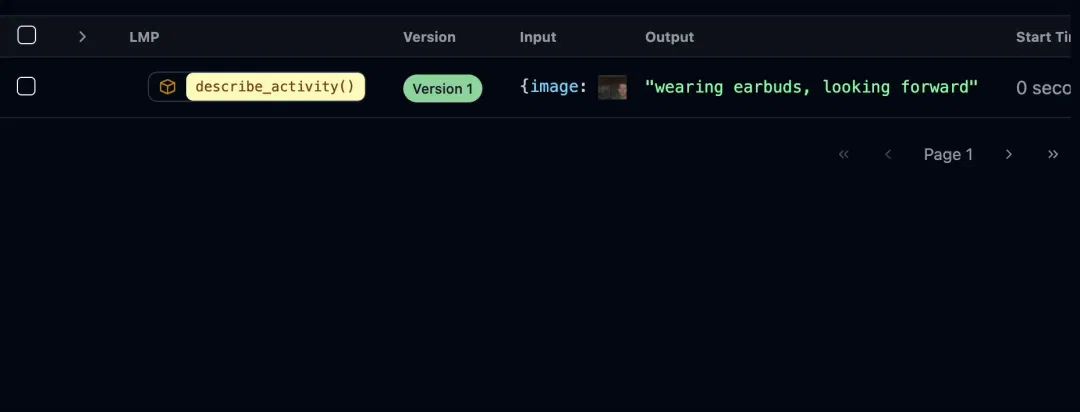
ell 支持多模态输入和输出的丰富类型转换。你可以在 LMP 返回的 Message 对象中内联使用 PIL 图像、音频和其他多模态输入。
六、提示工程库不干扰你的工作流程
ell 设计为一个轻量级且不干扰的库。它不要求你改变编码风格或使用特殊的编辑器。
你可以继续在你的 IDE 中使用常规的 Python 代码来定义和修改提示,同时利用 ell 的功能来可视化和分析你的提示。你可以逐步从 langchain 迁移到 ell,一次一个函数。
七、结语
ell 通过将提示视为函数,并提供一系列强大的工具,重新定义了提示工程。它不仅简化了提示的创建和管理过程,还使得提示优化变得科学化和系统化。无论你是提示工程的新手还是经验丰富的专家,ell 都能为你提供有价值的支持。
如何学习大模型?
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

5. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方优快云官方认证二维码,免费领取【
保证100%免费】

如有侵权,请联系删除

















 1703
1703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









