





本文字数:16238;估计阅读时间:41 分钟
作者:ClickHouse Team
本文在公众号【ClickHouseInc】首发

又到了月度发布的时间!
发布概要
ClickHouse 25.10 版本正式上线,本次更新带来了 20 项新功能 👻、30 项性能优化 🔮 以及 103 个 Bug 修复 🎃
此次版本新增了多项 JOIN 相关优化、新的数据类型以支持向量检索、次级索引的延迟物化等丰富功能,值得期待!
新的贡献者
欢迎新贡献者 热烈欢迎在 25.10 版本中首次贡献的开发者们!ClickHouse 社区的持续壮大令人振奋,我们始终感谢每一位让 ClickHouse 更加出色的贡献者。
以下是本版本的新贡献者名单:
0xgouda, Ahmed Gouda, Albert Chae, Austin Bonander, ChaiAndCode, David E. Wheeler, DeanNeaht, Dylan, Frank Rosner, GEFFARD Quentin, Giampaolo Capelli, Grant Holly, Guang, Guang Zhao, Isak Ellmer, Jan Rada, Kunal Gupta, Lonny Kapelushnik, Manuel Raimann, Michal Simon, Narasimha Pakeer, Neerav, Raphaël Thériault, Rui Zhang, Sadra Barikbin, copilot-swe-agent[bot], dollaransh17, flozdra, jitendra1411, neeravsalaria, pranav mehta, zlareb1, |2ustam, Андрей Курганский, Артем Юров
JOIN 中的懒惰列复制优化
贡献者:Pavel Kruglov
“JOIN 的性能优化什么时候才会结束?”
答案是:永远不会!
本次发布再次带来了 JOIN 性能方面的改进。
25.10 的第一个亮点是懒惰列复制(lazy columns replication)优化机制,这项新功能可以显著降低 JOIN 操作中 CPU 与内存的消耗,尤其是在结果中出现大量重复值的场景下。
在执行 JOIN 查询时(包括使用 arrayJoin 函数的查询),输入表中的某些列往往会在结果中被大量重复,特别是当某个键有多个匹配时。
举个例子,假设有一个名为 hits 的表,用于存储匿名化的网页访问分析数据,其中包含两列:ClientIP 和 URL:

当我们运行一个自连接时:
SELECT ...
FROM
hits AS t1 INNER JOIN hits AS t2
ON t1.ClientIP = t2.ClientIP;
查询结果中会重复大量来自左右两边的数据行:
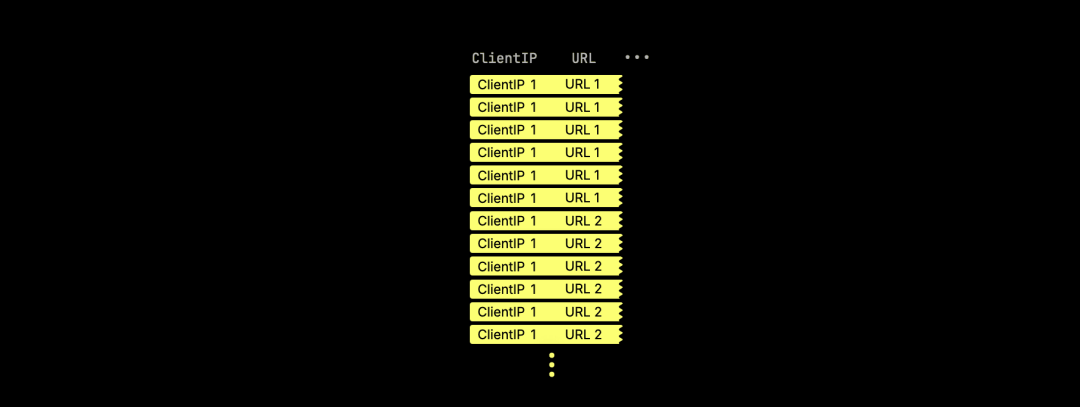
对于像 URL 这样体积较大的字段,这种重复会导致大量 CPU 和内存资源被浪费,因为相同的数据会在内存中被反复复制。
在 25.10 版本中,ClickHouse 针对这种情况进行了优化 —— 在 JOIN 操作中不再重复复制相同的值,从而降低了资源消耗。
我们引入了一种新的内部数据结构,专门用于处理像 URL 这样频繁被重复的列。
ClickHouse 不再在内存中复制数据,而是保留原始列,并引入一个紧凑的索引列,指向这些原始值:
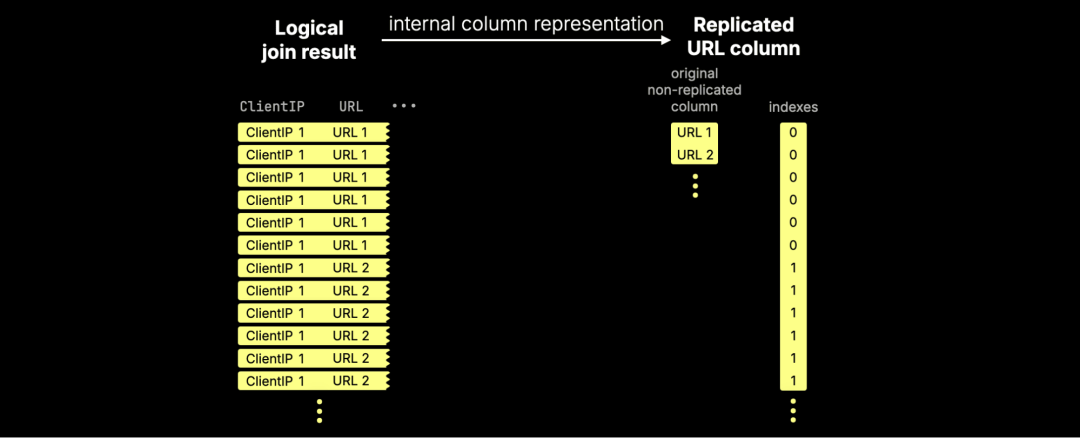
这项机制被称为“懒惰列复制(lazy columns replication)”,其核心思想是延迟对重复值的实际复制,只有在真正需要时才进行(而很多情况下,根本不需要复制)。
你可以通过以下两个设置项来启用该功能:
-
enable_lazy_columns_replication
-
allow_special_serialization_kinds_in_output_formats
实测效果
为了评估该功能的实际效果,我们在一台 AWS EC2 m6i.8xlarge 实例(32 核 vCPU,128 GiB 内存)上,对 hits 表进行了基准测试。
你也可以自行创建并加载这个表,步骤如下。
我们首先运行了一个未启用懒惰复制的自连接查询示例:
SELECT sum(cityHash64(URL))
FROM
hits AS t1 INNER JOIN hits AS t2
ON t1.ClientIP = t2.ClientIP
SETTINGS
enable_lazy_columns_replication = 0,
allow_special_serialization_kinds_in_output_formats = 0;
┌─sum(cityHash64(URL))─┐
│ 8580639250520379278 │
└──────────────────────┘
1 row in set. Elapsed: 83.396 sec. Processed 199.99 million rows, 10.64 GB (2.40 million rows/s., 127.57 MB/s.)
Peak memory usage: 4.88 GiB.
接着,在相同查询中启用了懒惰列复制功能:
SELECT sum(cityHash64(URL))
FROM
hits AS t1 INNER JOIN hits AS t2
ON t1.ClientIP = t2.ClientIP
SETTINGS
enable_lazy_columns_replication = 1,
allow_special_serialization_kinds_in_output_formats = 1;
┌─sum(cityHash64(URL))─┐
│ 8580639250520379278 │
└──────────────────────┘
1 row in set. Elapsed: 4.078 sec. Processed 199.99 million rows, 10.64 GB (49.04 million rows/s., 2.61 GB/s.)
Peak memory usage: 4.57 GiB.
结果显示:启用懒惰列复制后,该自连接查询的执行速度提升了 20 倍以上,同时也略微降低了内存峰值 —— 这归功于避免了对大型字符串的重复复制。
JOIN 引入 Bloom 过滤器优化
贡献者:Alexander Gololobov
接下来介绍的 JOIN 优化,是对 ClickHouse 中已有技术的扩展:在全排序归并连接(full sorting merge join)中,ClickHouse 已支持在实际执行 JOIN 前,通过连接键对左右两表进行预过滤。
在 25.10 版本中,这一优化也被引入到了 ClickHouse 最快的 JOIN 算法 —— 并行哈希连接(parallel hash join)中。
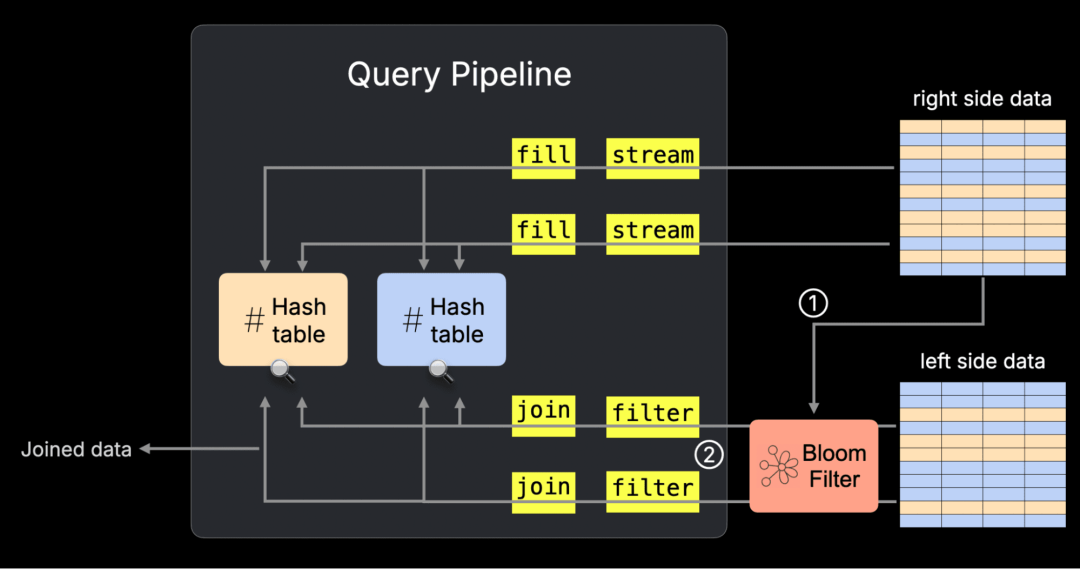
该优化机制如下:
① 在运行过程中,ClickHouse 会根据右表中的连接键构建一个 Bloom 过滤器;
② 然后,将这个过滤器应用到左表的扫描过程,从而提前过滤掉不相关的数据行。
下面的示意图展示了这一过程在并行哈希连接的物理查询计划(即“查询流水线”)中的位置。如需了解查询计划的更多内容,可参考相关文档。
此功能可通过设置 enable_join_runtime_filters 来启用。
我们在 AWS EC2 m6i.8xlarge 实例(32 核 vCPU,128 GiB 内存)上使用 TPC-H 数据集(规模因子为 100)进行了基准测试。接下来,我们将先分析该优化如何影响查询计划,然后评估其实际性能表现。
查看逻辑查询计划
观察 JOIN 查询内部逻辑的最简单方式,是通过 EXPLAIN plan 查看其逻辑执行计划。
我们首先运行一个基于 TPC-H 中 orders 表和 customer 表,以 custkey 为连接键的简单 JOIN 查询,同时关闭 Bloom 过滤器预过滤功能:
EXPLAIN plan
SELECT *
FROM orders, customer
WHERE o_custkey = c_custkey
SETTINGS enable_join_runtime_filters = 0;
其核心查询计划如下所示:
...
Join
...
ReadFromMergeTree (default.orders)
ReadFromMergeTree (default.customer)
这里我们省略其他部分,仅关注关键步骤。
从下往上阅读,可以看到 ClickHouse 计划从 orders 和 customer 两表中读取数据,并执行连接操作。
接下来我们再运行相同的 JOIN 查询,但这次启用运行时预过滤功能:
EXPLAIN plan
SELECT *
FROM orders, customer
WHERE o_custkey = c_custkey
SETTINGS enable_join_runtime_filters = 1;
其关键查询计划如下:
...
Join
...
Prewhere filter column: __filterContains(_runtime_filter_14211390369232515712_0, __table1.o_custkey)
...
BuildRuntimeFilter (Build runtime join filter on __table2.c_custkey (_runtime_filter_14211390369232515712_0))
...
同样从下往上阅读,可以看到 ClickHouse 首先 ① 从右表 customer 中的连接键构建 Bloom 过滤器。
接着,这个运行时过滤器会被 ② 应用为左表 orders 上的 PREWHERE 条件,从而在执行 JOIN 之前就能跳过不相关的数据行。
对比运行启用与未启用运行时过滤的查询
现在我们来运行一个稍微复杂一点的连接查询,这次将 orders、customer 和 nation 三个表连接起来,并统计来自法国客户的平均订单金额。
首先,我们在未启用运行时预过滤的情况下执行该查询:
SELECT avg(o_totalprice)
FROM orders, customer, nation
WHERE (c_custkey = o_custkey) AND (c_nationkey = n_nationkey) AND (n_name = 'FRANCE')
SETTINGS enable_join_runtime_filters = 0;
┌──avg(o_totalprice)─┐
│ 151149.41468432106 │
└────────────────────┘
1 row in set. Elapsed: 1.005 sec. Processed 165.00 million rows, 1.92 GB (164.25 million rows/s., 1.91 GB/s.)
Peak memory usage: 1.24 GiB.
接着,启用运行时预过滤后再次运行同一查询:
SELECT avg(o_totalprice)
FROM orders, customer, nation
WHERE (c_custkey = o_custkey) AND (c_nationkey = n_nationkey) AND (n_name = 'FRANCE')
SETTINGS enable_join_runtime_filters = 1;
┌──avg(o_totalprice)─┐
│ 151149.41468432106 │
└────────────────────┘
1 row in set. Elapsed: 0.471 sec. Processed 165.00 million rows, 1.92 GB (350.64 million rows/s., 4.08 GB/s.)
Peak memory usage: 185.18 MiB.
结果如下:
启用预过滤后,查询速度提升了 2.1 倍,内存使用减少近 7 倍。
借助 Bloom 过滤器提前过滤不相关的数据行,ClickHouse 能避免扫描和处理无效数据,从而加快 JOIN 执行并显著降低资源消耗。
JOIN 中复杂条件的下推优化
贡献者:Yarik Briukhovetskyi
ClickHouse 现已支持将 JOIN 查询中的复杂 OR 条件下推,使系统可以在执行 JOIN 之前就对各参与表进行预过滤。
该优化在以下情况下生效:OR 条件的每个分支中都分别包含了对连接中各表的过滤谓词。
例如:
(t1.k IN (1,2) AND t2.x = 100)
OR
(t1.k IN (3,4) AND t2.x = 200)
此处,JOIN 的两侧表(t1 和 t2)在每个分支中都各自包含了过滤条件。
因此,ClickHouse 可以将其拆分并下推为:
-
左表:t1.k IN (1,2,3,4)
-
右表:t2.x IN (100,200)
这样,两张表都可以在 JOIN 执行前完成预过滤,从而减少数据读取量,提升查询效率。
该功能可通过设置项 use_join_disjunctions_push_down 启用。
为了展示该优化在实际中的表现,我们使用 AWS EC2 m6i.8xlarge 实例(32 核 vCPU,128 GiB 内存)上的 TPC-H 数据集(scale factor 100)做了一个简单测试。
我们将以 c_nationkey 为连接键,连接 customer 与 nation 表,并使用一个包含两个 OR 分支的条件,每个分支都对两张表进行了过滤。
查看逻辑查询计划
我们先查看在未启用下推优化时的逻辑查询计划:
EXPLAIN plan
SELECT *
FROM customer AS c
INNER JOIN nation AS n
ON c.c_nationkey = n.n_nationkey
WHERE (c.c_name LIKE 'Customer#00000%' AND n.n_name = 'GERMANY')
OR (c.c_name LIKE 'Customer#00001%' AND n.n_name = 'FRANCE')
SETTINGS use_join_disjunctions_push_down = 0;
在这个计划中,ClickHouse 会直接从两张表中读取全部数据,并在 JOIN 阶段统一应用过滤条件:
Join
...
ReadFromMergeTree (default.customer)
ReadFromMergeTree (default.nation)
然后启用优化后再次查看查询计划:
EXPLAIN plan
SELECT *
FROM customer AS c
INNER JOIN nation AS n
ON c.c_nationkey = n.n_nationkey
WHERE (c.c_name LIKE 'Customer#00000%' AND n.n_name = 'GERMANY')
OR (c.c_name LIKE 'Customer#00001%' AND n.n_name = 'FRANCE')
SETTINGS use_join_disjunctions_push_down = 1;
此时,ClickHouse 能识别出两个分支分别包含对两张表的谓词,于是为每张表分别生成过滤条件并提前下推:
Join
...
Filter
ReadFromMergeTree (default.customer)
...
Filter
ReadFromMergeTree (default.nation)
性能对比测试
随后我们分别运行禁用与启用该优化的查询,比较性能差异:
未启用优化:
SELECT *
FROM customer AS c
INNER JOIN nation AS n
ON c.c_nationkey = n.n_nationkey
WHERE (c.c_name LIKE 'Customer#00000%' AND n.n_name = 'GERMANY')
OR (c.c_name LIKE 'Customer#00001%' AND n.n_name = 'FRANCE')
SETTINGS use_join_disjunctions_push_down = 0;
788 rows in set. Elapsed: 0.240 sec. Processed 15.00 million rows, 2.93 GB (62.56 million rows/s., 12.21 GB/s.)
Peak memory usage: 261.30 MiB.
启用优化:
SELECT *
FROM customer AS c
INNER JOIN nation AS n
ON c.c_nationkey = n.n_nationkey
WHERE (c.c_name LIKE 'Customer#00000%' AND n.n_name = 'GERMANY')
OR (c.c_name LIKE 'Customer#00001%' AND n.n_name = 'FRANCE')
SETTINGS use_join_disjunctions_push_down = 0;
788 rows in set. Elapsed: 0.010 sec. Processed 24.60 thousand rows, 4.81 MB (2.47 million rows/s., 482.53 MB/s.)
Peak memory usage: 4.30 MiB.
结果:
在启用下推后,查询速度提升了 24 倍,内存使用减少超过 60 倍。
通过将过滤逻辑下推到表扫描阶段,ClickHouse 能有效跳过数百万无关数据行,极大提升了查询效率。
MergeTree 表的列统计信息自动构建
贡献者:Anton Popov
这是本次版本中第四项 JOIN 相关的性能优化,虽然它是间接发挥作用的。
在上一版本中,ClickHouse 推出了自动的全局 JOIN 重排序功能,能高效地重新排列包含大量表的复杂 JOIN 结构。这项特性显著提升了性能,例如在某个 TPC-H 查询中,执行速度提高了 1,450 倍,内存占用减少了 25 倍。
全局 JOIN 重排序的效果依赖于连接键和过滤条件列的统计信息。此前,这些统计信息需要手动为每个列单独生成。
从 25.10 开始,ClickHouse 支持使用新表级设置 auto_statistics_types,自动为 MergeTree 表中所有适用的列生成统计信息。
通过该设置,你可以指定要生成的统计类型,例如 minmax、uniq 或 countmin:
CREATE TABLE tpch.orders (...) ORDER BY (o_orderkey)
SETTINGS auto_statistics_types = 'minmax, uniq, countmin';
启用后,系统会为整张表的列自动构建相应统计信息。
此外,你也可以在服务端配置中为所有 MergeTree 表全局启用该功能:
$ cat /etc/config.d/merge_tree.yaml
merge_tree:
auto_statistics_types: 'minmax, uniq, countmin'
借助这一自动机制,ClickHouse 能够始终保持列统计信息的最新状态,从而在 JOIN 和过滤决策中作出更优判断,进一步提升查询计划质量,减少资源消耗,无需人工干预。
这四项特性 —— 懒惰列复制、JOIN 中的 Bloom 过滤器、复杂条件的下推、自动列统计信息 —— 标志着 ClickHouse 在 JOIN 优化道路上的又一重要进展,并且这还只是开始。
QBit 数据类型
贡献者:Raufs Dunamalijevs
QBit 是一种用于向量嵌入的全新数据类型,支持在运行时灵活调节搜索精度。它采用按位切片的存储结构:每个数值在存储时按比特位拆分,查询时可以指定使用其中的高位比特数,从而控制精度与性能之间的权衡。
CREATE TABLE vectors (
id UInt64, name String, ...
vec QBit(BFloat16, 1536)
) ORDER BY ();
SELECT id, name FROM vectors
ORDER BY L2DistanceTransposed(vector, target, 10)
LIMIT 10;
Raufs Dunamalijevs 在博客文章《We built a vector search engine that lets you choose precision at query time》中对 QBit 数据类型的设计与应用进行了详细介绍。(https://clickhouse.com/blog/qbit-vector-search)
SQL 语法扩展
贡献者:Nihal Z. Miaji、Surya Kant Ranjan、Simon Michal
ClickHouse 25.10 对 SQL 支持进行了多项增强。
首先,<=> 运算符(即 IS NOT DISTINCT FROM)现已在所有 SQL 场景中可用,之前它仅限用于 JOIN ON 子句。该运算符可用于等值比较,并将 NULL 值视为相等。以下示例展示了其使用方式:
SELECT NULL <=> NULL, NULL = NULL;
┌─isNotDistinc⋯NULL, NULL)─┬─equals(NULL, NULL)─┐
│ 1 │ ᴺᵁᴸᴸ │
└──────────────────────────┴────────────────────┘
其次,ClickHouse 现在支持负数的 LIMIT 和 OFFSET 参数。这在查询中选取“最近若干条记录”但希望结果按时间升序返回时特别有用。我们通过英国房产价格数据集来说明这一功能。
假设我们要找出自 2024 年以来售价超过 1000 万英镑的房产,并按成交时间降序排列,可以使用如下 SQL:
SELECT date, price, county, district
FROM uk.uk_price_paid
WHERE date >= '2024-01-01' AND price > 10_000_000
ORDER BY date DESC LIMIT 10;
┌───────date─┬────price─┬─county────────────────────┬─district──────────────────┐
│ 2025-03-13 │ 12000000 │ CHESHIRE WEST AND CHESTER │ CHESHIRE WEST AND CHESTER │
│ 2025-03-06 │ 18375000 │ STOKE-ON-TRENT │ STOKE-ON-TRENT │
│ 2025-03-06 │ 10850000 │ HERTFORDSHIRE │ HERTSMERE │
│ 2025-03-04 │ 11000000 │ PORTSMOUTH │ PORTSMOUTH │
│ 2025-03-04 │ 18000000 │ GREATER LONDON │ HAMMERSMITH AND FULHAM │
│ 2025-03-03 │ 12500000 │ ESSEX │ BASILDON │
│ 2025-02-20 │ 16830000 │ GREATER LONDON │ CITY OF WESTMINSTER │
│ 2025-02-13 │ 13950000 │ GREATER LONDON │ KENSINGTON AND CHELSEA │
│ 2025-02-07 │ 81850000 │ ESSEX │ EPPING FOREST │
│ 2025-02-07 │ 24920000 │ GREATER LONDON │ HARINGEY │
└────────────┴──────────┴───────────────────────────┴───────────────────────────┘
但如果我们希望返回的这 10 条最新成交记录按日期升序展示,只需对 ORDER BY 和 LIMIT 语句稍作调整,使用负数 LIMIT 即可:
SELECT date, price, county, district
FROM uk.uk_price_paid
WHERE date >= '2024-01-01' AND price > 10_000_000
ORDER BY date LIMIT -10;
然后我们将看到以下结果:
┌───────date─┬────price─┬─county────────────────────┬─district──────────────────┐
│ 2025-02-07 │ 29240000 │ GREATER LONDON │ MERTON │
│ 2025-02-07 │ 75960000 │ WARRINGTON │ WARRINGTON │
│ 2025-02-13 │ 13950000 │ GREATER LONDON │ KENSINGTON AND CHELSEA │
│ 2025-02-20 │ 16830000 │ GREATER LONDON │ CITY OF WESTMINSTER │
│ 2025-03-03 │ 12500000 │ ESSEX │ BASILDON │
│ 2025-03-04 │ 11000000 │ PORTSMOUTH │ PORTSMOUTH │
│ 2025-03-04 │ 18000000 │ GREATER LONDON │ HAMMERSMITH AND FULHAM │
│ 2025-03-06 │ 18375000 │ STOKE-ON-TRENT │ STOKE-ON-TRENT │
│ 2025-03-06 │ 10850000 │ HERTFORDSHIRE │ HERTSMERE │
│ 2025-03-13 │ 12000000 │ CHESHIRE WEST AND CHESTER │ CHESHIRE WEST AND CHESTER │
└────────────┴──────────┴───────────────────────────┴───────────────────────────┘
这样便能获取相同数据集,但顺序相反的结果。
SELECT date, price, county, district
FROM uk.uk_price_paid
WHERE date >= '2024-01-01' AND price > 10_000_000
ORDER BY date LIMIT -10 OFFSET -10;
┌───────date─┬─────price─┬─county──────────┬─district────────────┐
│ 2025-01-21 │ 10650000 │ NOTTINGHAMSHIRE │ ASHFIELD │
│ 2025-01-21 │ 22722671 │ GREATER LONDON │ CITY OF WESTMINSTER │
│ 2025-01-22 │ 109500000 │ GREATER LONDON │ CITY OF LONDON │
│ 2025-01-24 │ 11700000 │ THURROCK │ THURROCK │
│ 2025-01-25 │ 75570000 │ GREATER LONDON │ CITY OF WESTMINSTER │
│ 2025-01-29 │ 12579711 │ SUFFOLK │ MID SUFFOLK │
│ 2025-01-31 │ 29307333 │ GREATER LONDON │ EALING │
│ 2025-02-07 │ 81850000 │ ESSEX │ EPPING FOREST │
│ 2025-02-07 │ 24920000 │ GREATER LONDON │ HARINGEY │
│ 2025-02-07 │ 151420000 │ GREATER LONDON │ MERTON │
└────────────┴───────────┴─────────────────┴─────────────────────┘
此外,LIMIT 和 OFFSET 都支持负数值,这使得我们可以更方便地以升序分页浏览。例如,若要获取接下来的 10 条记录,只需将 LIMIT -10 OFFSET -20。
最后,ClickHouse 现在支持 LIMIT BY ALL 语法。在某些查询中,我们希望限制结果中每种组合仅出现一次。例如,以下查询用于返回伦敦地区售价超过 1000 万英镑的住宅房产信息:
SELECT town, district, type
FROM uk.uk_price_paid
WHERE county = 'GREATER LONDON' AND price > 10_000_000 AND type <> 'other'
ORDER BY price DESC
LIMIT 10;
┌─town───┬─district───────────────┬─type─────┐
│ LONDON │ CITY OF WESTMINSTER │ flat │
│ LONDON │ CITY OF WESTMINSTER │ flat │
│ LONDON │ CITY OF WESTMINSTER │ flat │
│ LONDON │ CITY OF WESTMINSTER │ flat │
│ LONDON │ CITY OF WESTMINSTER │ flat │
│ LONDON │ CITY OF WESTMINSTER │ terraced │
│ LONDON │ CITY OF WESTMINSTER │ flat │
│ LONDON │ KENSINGTON AND CHELSEA │ terraced │
│ LONDON │ CITY OF WESTMINSTER │ terraced │
│ LONDON │ KENSINGTON AND CHELSEA │ flat │
└────────┴────────────────────────┴──────────┘
结果中 City of Westminster 出现次数较多,这是合理的,因为该区域房价本就较高。但如果我们希望每个(town, district, type)组合仅返回一条记录,可以使用:
SELECT town, district, type
FROM uk.uk_price_paid
WHERE county = 'GREATER LONDON' AND price > 10_000_000 AND type <> 'other'
ORDER BY price DESC
LIMIT 1 BY town, district, type
LIMIT 10;
┌─town───┬─district───────────────┬─type──────────┐
│ LONDON │ CITY OF WESTMINSTER │ flat │
│ LONDON │ CITY OF WESTMINSTER │ terraced │
│ LONDON │ KENSINGTON AND CHELSEA │ terraced │
│ LONDON │ KENSINGTON AND CHELSEA │ flat │
│ LONDON │ KENSINGTON AND CHELSEA │ detached │
│ LONDON │ SOUTHWARK │ flat │
│ LONDON │ KENSINGTON AND CHELSEA │ semi-detached │
│ LONDON │ CITY OF WESTMINSTER │ detached │
│ LONDON │ CAMDEN │ detached │
│ LONDON │ CITY OF LONDON │ detached │
└────────┴────────────────────────┴───────────────┘
如果不想手动列出字段名,使用 LIMIT BY ALL 语法即可达到同样效果:
SELECT town, district, type
FROM uk.uk_price_paid
WHERE county = 'GREATER LONDON' AND price > 10_000_000 AND type <> 'other'
ORDER BY price DESC
LIMIT 1 BY ALL
LIMIT 10;
查询结果将保持一致,但语法更简洁。
Arrow Flight 客户端与服务器互通支持
贡献者:zakr600、Vitaly Baranov
我们在 ClickHouse 25.8 中引入了对 Arrow Flight 协议的初步支持,使得 ClickHouse 可作为 Arrow Flight 的客户端或服务器使用。
经过持续改进,截至 25.10 版本,ClickHouse 已支持使用 Arrow Flight 客户端查询 ClickHouse 的 Arrow Flight 服务器。
你可以通过添加如下配置文件,在 ClickHouse Server 上启用 Arrow Flight 服务:
arrowflight_port: 6379
arrowflight:
enable_ssl: false
auth_required: false
服务将运行在 6379 端口。当前仅支持访问默认数据库,但我们可以通过使用 alias 表引擎来创建别名表,从而绕过该限制:
CREATE TABLE uk_price_paid
ENGINE = Alias(uk, uk_price_paid);
之后,即可通过 Arrow 客户端访问该别名表,完成数据查询:
SELECT max(price), count()
FROM arrowflight('localhost:6379', 'uk_price_paid', 'default', '');
┌─max(price)─┬──count()─┐
│ 900000000 │ 30452463 │
└────────────┴──────────┘
次级索引的延迟物化支持
贡献者:George Larionov
在 ClickHouse 25.10 中,引入了新的配置选项,可用于延迟次级索引的物化时机。对于包含构建成本较高索引的表(如近似向量检索所使用的索引(https://clickhouse.com/docs/engines/table-engines/mergetree-family/annindexes)),延迟物化可以有效提升写入性能。
我们以 DBpedia 向量嵌入数据为例来演示该功能。首先,将嵌入数据导入以下表结构中:
CREATE OR REPLACE TABLE dbpedia
(
id String,
title String,
text String,
vector Array(Float32) CODEC(NONE),
INDEX vector_idx vector TYPE vector_similarity('hnsw', 'L2Distance', 1536)
) ENGINE = MergeTree
ORDER BY (id);
接着,下载一个包含约 40,000 条嵌入向量的 Parquet 文件:
wget https://huggingface.co/api/datasets/Qdrant/dbpedia-entities-openai3-text-embedding-3-large-1536-1M/parquet/default/train/0.parquet
然后执行插入操作,将这些记录写入表中:
INSERT INTO dbpedia
SELECT `_id` AS id, title, text,
`text-embedding-3-large-1536-embedding` AS vector
FROM file('0.parquet');
0 rows in set. Elapsed: 6.161 sec. Processed 38.46 thousand rows, 367.26 MB (6.24 thousand rows/s., 59.61 MB/s.)
Peak memory usage: 932.41 MiB.
此操作在写入数据的同时还构建了 HNSW 索引,整体耗时约 6 秒。
接下来,我们创建该表的一个副本 dbpedia2:
create table dbpedia2 as dbpedia;
然后通过如下设置,选择在稍后阶段再进行索引物化:
SET exclude_materialize_skip_indexes_on_insert='vector_idx';
我们再次执行与之前相同的插入操作,但这次目标表为 dbpedia2:
INSERT INTO dbpedia2
SELECT `_id` AS id, title, text,
`text-embedding-3-large-1536-embedding` AS vector
FROM file('0.parquet');
可以看到写入速度显著提升:
0 rows in set. Elapsed: 0.522 sec. Processed 38.46 thousand rows, 367.26 MB (73.68 thousand rows/s., 703.59 MB/s.)
Peak memory usage: 931.08 MiB.
要确认索引是否已经被物化,可以通过以下 SQL 查询:
SELECT table, data_compressed_bytes, data_uncompressed_bytes, marks_bytes FROM system.data_skipping_indices
WHERE name = 'vector_idx';
┌─table────┬─data_compressed_bytes─┬─data_uncompressed_bytes─┬─marks_bytes─┐
│ dbpedia │ 124229003 │ 128770836 │ 50 │
│ dbpedia2 │ 0 │ 0 │ 0 │
└──────────┴───────────────────────┴─────────────────────────┴─────────────┘
在 dbpedia2 中,结果显示所占空间为 0 字节,说明索引尚未物化。这一操作会在后台的合并(merge)过程中自动进行。如需立即完成索引构建,可执行以下命令:
ALTER TABLE dbpedia2 MATERIALIZE INDEX vector_idx
SETTINGS mutations_sync = 2;
之后再次查询 data_skipping_indices 表,便可看到已更新的索引信息:
┌─table────┬─data_compressed_bytes─┬─data_uncompressed_bytes─┬─marks_bytes─┐
│ dbpedia │ 124229003 │ 128770836 │ 50 │
│ dbpedia2 │ 124237137 │ 128769912 │ 50 │
└──────────┴───────────────────────┴─────────────────────────┴─────────────┘
此外,也可通过查询 system.parts 表来检查指定分片中是否已生成索引:
SELECT name, table, secondary_indices_compressed_bytes, secondary_indices_uncompressed_bytes, secondary_indices_marks_bytes
FROM system.parts;
Row 1:
──────
name: all_1_1_0
table: dbpedia
secondary_indices_compressed_bytes: 124229003 -- 124.23 million
secondary_indices_uncompressed_bytes: 128770836 -- 128.77 million
secondary_indices_marks_bytes: 50
Row 2:
──────
name: all_1_1_0_2
table: dbpedia2
secondary_indices_compressed_bytes: 124237137 -- 124.24 million
secondary_indices_uncompressed_bytes: 128769912 -- 128.77 million
secondary_indices_marks_bytes: 50
如需完全禁用合并过程中索引的构建操作,可以启用以下设置:
CREATE TABLE t (...)
SETTINGS materialize_skip_indexes_on_merge = false;
同时,也可以选择排除某些计算开销较大的索引类型,以减轻写入压力:
CREATE TABLE t (...)
SETTINGS exclude_materialize_skip_indexes_on_merge = 'vector_idx';
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com


















 66
66

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









