





本文字数:17911;估计阅读时间:45 分钟
作者:Mark Needham
本文在公众号【ClickHouseInc】首发

我最近花了一周时间,开发了一组示例,展示如何将 ClickHouse MCP Server 与当前主流的 12 种 AI 智能体(AI Agent)框架集成使用。相关内容已整理发布在我们的博客文章《如何用 MCP 构建 AI 智能体:12 个框架对比(2025)》中(https://clickhouse.com/blog/how-to-build-ai-agents-mcp-12-frameworks)。
在这个过程中,我注意到一件很有意思的现象:面对略带歧义的指令,不同的大语言模型(Large Language Model)在表现上差距显著。有的模型能快速把握意图,仅通过少量工具调用就完成任务,而有的模型则容易陷入循环,最终因为超时而失败。
这个现象引发了我的兴趣,我决定进一步深入分析整个问答过程中所产生的各类事件。为此我选择了 OpenAI agents 库作为实验框架,一方面是因为它支持多个模型,另一方面它优秀的追踪能力使我们可以全面剖析智能体的决策路径。
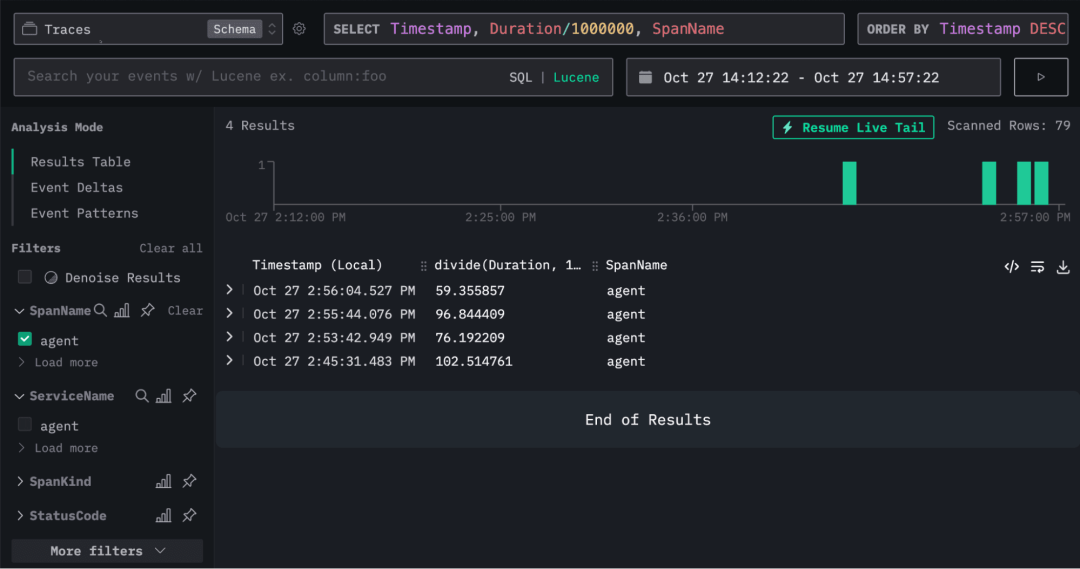
在这篇博客的最后,我们将学习如何将追踪数据加载到 ClickHouse 中,并结合 HyperDX 进行可视化,如下图所示:
创建一个 OpenAI 智能体
在开始追踪之前,我们需要先搭建一个 OpenAI 智能体。该智能体将通过 ClickHouse MCP Server 访问 ClickHouse 的 SQL Playground,具备查询数据集的能力,例如英国房地产或 GitHub 提交历史等。
下面这段 Python 代码用于初始化智能体,并指派它完成一个任务:找出 2025 年每个月最受欢迎的 GitHub 项目。为完成这一目标,智能体需要识别 GitHub 数据库,并知道要按月统计每个项目收到的 WatchEvent 数量。
env = {
"CLICKHOUSE_HOST": "sql-clickhouse.clickhouse.com",
"CLICKHOUSE_PORT": "8443",
"CLICKHOUSE_USER": "demo",
"CLICKHOUSE_PASSWORD": "",
"CLICKHOUSE_SECURE": "true"
}
from agents.mcp import MCPServerStdio
from agents import Agent, Runner, trace, RunConfig
import asyncio
from utils import simple_render_chunk
async def main():
async with MCPServerStdio(
name="ClickHouse SQL Playground",
params={
"command": "uv",
"args": [
"run",
"--with", "mcp-clickhouse",
"--python", "3.13",
"mcp-clickhouse",
],
"env": env,
},
client_session_timeout_seconds=60,
cache_tools_list=True,
) as server:
agent = Agent(
name="Assistant",
instructions="Use the tools to query ClickHouse and answer questions based on those files.",
mcp_servers=[server],
model="gpt-5-mini-2025-08-07",
)
message = "What's the most popular GitHub project for each month in 2025?"
print(f"\n\nRunning: {message}")
result = Runner.run_streamed(
starting_agent=agent,
input=message,
max_turns=20,
run_config=RunConfig(
trace_include_sensitive_data=True,
),
)
async for chunk in result.stream_events():
simple_render_chunk(chunk)
asyncio.run(main())在运行代码前,需要先执行命令 pip install openai-agents 安装必要的依赖。运行脚本后,你会看到类似如下的输出结果。
2025-10-27 12:09:26,457 - mcp.server.lowlevel.server - INFO - Processing request of type ListToolsRequest
Tool: list_databases({})
✅ Result: ["amazon", "bluesky", "country", "covid", "default", "dns", "environmental", "forex", "geo", "git", ...
Tool: list_tables({"database":"github"})
Tool: run_select_query({"query":"SELECT\n month,\n argMax(repo_name, stars) AS top_repo,\n argMax(stars, stars) AS stars\nFROM (\n SELECT toStartOfMonth(created_at) AS month, repo_name, sum(count) AS stars\n FROM github.repo_events_per_day\n WHERE event_type = 'WatchEvent'\n AND created_at >= '2025-01-01'\n AND created_at < '2026-01-01'\n GROUP BY month, repo_name\n)\nGROUP BY month\nORDER BY month\n"})
2025-10-27 12:10:09,752 - mcp.server.lowlevel.server - INFO - Processing request of type CallToolRequest
2025-10-27 12:10:09,752 - mcp-clickhouse - INFO - Executing SELECT query: SELECT
month,
argMax(repo_name, stars) AS top_repo,
argMax(stars, stars) AS stars
FROM (
SELECT toStartOfMonth(created_at) AS month, repo_name, sum(count) AS stars
FROM github.repo_events_per_day
WHERE event_type = 'WatchEvent'
AND created_at >= '2025-01-01'
AND created_at < '2026-01-01'
GROUP BY month, repo_name
)
GROUP BY month
ORDER BY month
✅ Result: {"columns":["month","repo_name","stars"],"rows":[["2025-01-01","deepseek-ai/DeepSeek-V3",51693]]}...
✅ Result: {"columns":["month","repo_name","stars"],"rows":[["2025-02-01","deepseek-ai/DeepSeek-R1",29337]]}...
...
I measured "most popular" by the number of WatchEvent (stars) in the GitHub events dataset (github.repo_events_per_day). Results for 2025:
- 2025-01: deepseek-ai/DeepSeek-V3 — 51,693 stars
- 2025-02: deepseek-ai/DeepSeek-R1 — 29,337 stars
- 2025-03: mannaandpoem/OpenManus — 37,967 stars
- 2025-04: x1xhlol/system-prompts-and-models-of-ai-tools — 28,265 stars
- 2025-05: TapXWorld/ChinaTextbook — 27,315 stars
- 2025-06: google-gemini/gemini-cli — 27,073 stars
- 2025-07: OpenCut-app/OpenCut — 13,798 stars
- 2025-08: DigitalPlatDev/FreeDomain — 11,567 stars
- 2025-09: github/spec-kit — 15,696 stars
- 2025-10: karpathy/nanochat — 7,783 stars你可以在 ClickHouse 示例仓库中找到本示例的完整代码,文件名为 agent_no_tracing.py,该版本为未开启追踪功能的初始实现。(https://github.com/ClickHouse/examples/blob/main/ai/mcp/openai-agents/agent_no_tracing.py)
为 OpenAI agents 应用添加追踪功能
目前的代码已经能够输出智能体执行的各个步骤和最终结果,但如果我们想进一步了解其内部执行过程,应该如何追踪每一步发生了什么?
好消息是,OpenAI agents 自带了追踪机制。默认情况下,它会将追踪信息发送到 OpenAI 自家的追踪系统中。但我们也可以接入自己的自定义导出器,将追踪数据捕获到本地并进行分析。
OpenAI agents 的追踪 SDK 将 trace(追踪)与 span(操作片段)区分为两个概念,它们定义如下:
Trace:表示一次完整的“工作流”执行过程,由若干 span 构成。其属性包括:
-
workflow_name:逻辑上的工作流或应用名称,例如 “Code generation” 或 “Customer service”。
-
trace_id:该追踪的唯一 ID。若未指定系统会自动生成,格式为 trace_加上 32 位字母数字组合。
-
group_id(可选):用于将多个 trace 关联到同一次对话中,比如可使用 chat thread ID。
-
disabled:若设置为 True,该 trace 将不会被记录。
-
metadata:可选的追踪元数据。
Span:表示一次具体的操作过程,具有明确的起止时间。其属性包括:
-
started_at 与 ended_at:表示操作的起止时间戳。
-
trace_id:表示该 span 所属的 trace。
-
parent_id:指向其父级 span(若有)。
-
span_data:包含该 span 的详细信息。例如:
-
AgentSpanData 包含智能体相关信息,
-
GenerationSpanData 描述大语言模型生成的细节。
为了直观展示追踪过程,我们先实现一个基础版的导出器,将所有 trace 和 span 信息直接输出到终端:
from agents.tracing.processors import TracingExporter
class ClickHouseExporter(TracingExporter):
def export(self, items: list) -> None:
for item in items:
print(item.export())然后,在主函数开头添加如下代码,将 ClickHouseExporter 注册为 BatchTraceProcessor 的导出器:
from agents.tracing.processors import BatchTraceProcessor
exporter = ClickHouseExporter()
add_trace_processor(BatchTraceProcessor(exporter=exporter, max_batch_size=200))设置完成后重新运行脚本,终端上会看到如下输出:
{'object': 'trace', 'id': 'trace_c6a4645e18a94ba5bd0913f86ca54962', 'workflow_name': 'Agent workflow', 'group_id': None, 'metadata': None}
{'object': 'trace.span', 'id': 'span_40b255d4b9f645b2ad8f5628', 'trace_id': 'trace_c6a4645e18a94ba5bd0913f86ca54962', 'parent_id': None, 'started_at': '2025-10-24T13:27:57.602767+00:00', 'ended_at': '2025-10-24T13:27:57.603974+00:00', 'span_data': {'type': 'mcp_tools', 'server': 'ClickHouse SQL Playground', 'result': ['list_databases', 'list_tables', 'run_select_query']}, 'error': None}
{'object': 'trace.span', 'id': 'span_27c715e28a5141ceb7abf8b3', 'trace_id': 'trace_c6a4645e18a94ba5bd0913f86ca54962', 'parent_id': 'span_f3f9621318ed44188b44bf88', 'started_at': '2025-10-24T13:28:30.797297+00:00', 'ended_at': '2025-10-24T13:28:31.707780+00:00', 'span_data': {'type': 'function', 'name': 'run_select_query', 'input': '{"query":"SELECT month, argMax(repo_name, stars) AS top_repo, max(stars) AS stars\\nFROM (\\n SELECT toStartOfMonth(created_at) AS month, repo_name, sum(count) AS stars\\n FROM github.repo_events_per_day\\n WHERE event_type = \'WatchEvent\'\\n AND created_at >= \'2025-01-01\' AND created_at < \'2026-01-01\'\\n GROUP BY month, repo_name\\n)\\nGROUP BY month\\nORDER BY month ASC"}', 'output': '{"type":"text","text":"Query execution failed: Received ClickHouse exception, code: 184, server response: Code: 184. DB::Exception: Aggregate function max(stars) AS stars is found inside another aggregate function in query. (ILLEGAL_AGGREGATION) (version 25.8.1.8513 (official build)) (for url https://sql-clickhouse.clickhouse.com:8443)","annotations":null,"meta":null}', 'mcp_data': {'server': 'ClickHouse SQL Playground'}}, 'error': None}
{'object': 'trace.span', 'id': 'span_cc38716cf5f4427783e27e37', 'trace_id': 'trace_c6a4645e18a94ba5bd0913f86ca54962', 'parent_id': 'span_f3f9621318ed44188b44bf88', 'started_at': '2025-10-24T13:28:49.436986+00:00', 'ended_at': '2025-10-24T13:29:05.725308+00:00', 'span_data': {'type': 'response', 'response_id': 'resp_03d650071a423c650068fb7f11a7348198a3ffd41e1c4a0ac1'}, 'error': None}输出显示,我们首先创建了一个 trace,然后紧接着生成了一系列 span,这些 span 分别对应以下操作:
-
枚举可用的 MCP 工具
-
执行 run_select_query 函数
-
LLM 返回响应内容
目前的输出中还有一个关键字段未被采集——模型名称。实际上该信息存在于 span_data 对象中,但默认未被导出。我们只需更新导出器逻辑,提取该字段即可。
class ClickHouseExporter(TracingExporter):
def export(self, items: list) -> None:
for item in items:
if "Span" in type(item).__name__:
span_data = {}
if hasattr(item, "span_data") and item.span_data:
if hasattr(item.span_data, "export"):
span_data = item.span_data.export()
if hasattr(item.span_data, "response") and item.span_data.response:
if hasattr(item.span_data.response, "model"):
span_data["model"] = str(item.span_data.response.model)
span_export = {**item.export(), "span_data": span_data}
print(span_export)
else:
print(item.export())更新导出器并重新运行后,就能在 response 类型的 span 中看到 span_data 包含的模型名称了。
{'object': 'trace.span', 'id': 'span_ebd0502f02da4c099c7aff51', 'trace_id': 'trace_7b50bba9027f41c1b948fd24d7b7f3fe', 'parent_id': 'span_8a896ba19e1e422a8cf7200d', 'started_at': '2025-10-24T14:16:51.219051+00:00', 'ended_at': '2025-10-24T14:16:58.164456+00:00', 'span_data': {'type': 'response', 'response_id': 'resp_05fec3bb8d3e90250068fb8a5361148198b8fcf8d35f3ec646', 'model': 'gpt-5-mini-2025-08-07'}, 'error': None}该基础导出器的完整代码可在 ClickHouse 示例项目的 GitHub 仓库中找到,文件名为 agent_tracing_base.py。
将 OpenAI agents 的追踪数据写入 ClickHouse
接下来,我们要将追踪数据导入 ClickHouse。首先,创建一张新表,字段结构与 OpenAI agents 框架中的追踪格式保持一致:
CREATE TABLE agent_spans_raw
(
`trace_id` String,
`id` String,
`parent_id` String,
`started_at` String,
`ended_at` String,
`span_data` JSON,
`error` String
)
ORDER BY (id, trace_id);然后更新导出器,初始化 ClickHouse 客户端,并在每次收到新的 trace 或 span 时将数据写入表中。
import clickhouse_connect
class ClickHouseExporter(TracingExporter):
def __init__(self):
self.span_tbl = "agent_spans_raw"
self.client = clickhouse_connect.get_client(
host='localhost', port=8123,
username="default", password=""
)
def export(self, items: list) -> None:
spans = []
for item in items:
if "Span" in type(item).__name__:
span_data = {}
if hasattr(item, "span_data") and item.span_data:
if hasattr(item.span_data, "export"):
span_data = item.span_data.export()
if hasattr(item.span_data, "response") and item.span_data.response:
if hasattr(item.span_data.response, "model"):
span_data["model"] = str(item.span_data.response.model)
span_export = {**item.export(), "span_data": span_data}
# Only include columns that exist in agent_spans_raw table
table_columns = {"trace_id", "id", "parent_id", "started_at", "ended_at", "span_data", "error"}
filtered_span = {k: (v if v is not None else "") for k, v in span_export.items() if k in table_columns}
spans.append(filtered_span)
try:
if spans:
column_names = list(spans[0].keys())
data = [[row[col] for col in column_names] for row in spans]
self.client.insert(table=self.span_tbl, data=data, column_names=column_names)
except Exception as e:
print(f"[ClickHouseExporter] Error: {e}")
import traceback
traceback.print_exc()完整代码可在 ClickHouse 示例仓库的 agent_tracing.py 中找到,我们还将 ClickHouse 相关导出逻辑单独封装为一个模块,文件名为 clickhouse_processor.py。
当我们重新运行脚本后,就能看到 ClickHouse 表开始被写入数据。
SELECT *
FROM agent_spans_raw
LIMIT 3;Row 1:
──────
trace_id: trace_b89379b2c3a64eb8a08f5f84ccc47ac3
id: span_308bb0c0ae92404499142d23
parent_id: span_7332b7e5c8984b6e9c4151b1
started_at: 2025-10-27T12:54:16.997495+00:00
ended_at: 2025-10-27T12:54:31.942834+00:00
span_data: {"model":"gpt-5-mini-2025-08-07","response_id":"resp_0857b013cad9136f0068ff6b7b5178819993fc61e17d70d424","type":"response"}
error:
Row 2:
──────
trace_id: trace_b89379b2c3a64eb8a08f5f84ccc47ac3
id: span_34f7ffe500dd452595123b14
parent_id: span_7332b7e5c8984b6e9c4151b1
started_at: 2025-10-27T12:54:34.868942+00:00
ended_at: 2025-10-27T12:54:34.868966+00:00
span_data: {"result":["list_databases","list_tables","run_select_query"],"server":"ClickHouse SQL Playground","type":"mcp_tools"}
error:
Row 3:
──────
trace_id: trace_b89379b2c3a64eb8a08f5f84ccc47ac3
id: span_52a47cd0b8374f92b1c26437
parent_id: span_7332b7e5c8984b6e9c4151b1
started_at: 2025-10-27T12:53:58.116785+00:00
ended_at: 2025-10-27T12:53:58.984619+00:00
span_data: {"input":"{}","mcp_data":{"server":"ClickHouse SQL Playground"},"name":"list_databases","output":"{\"type\":\"text\",\"text\":\"[\\\"amazon\\\", \\\"bluesky\\\", \\\"country\\\", \\\"covid\\\", \\\"default\\\", \\\"dns\\\", \\\"environmental\\\", \\\"forex\\\", \\\"geo\\\", \\\"git\\\", \\\"github\\\", \\\"hackernews\\\", \\\"imdb\\\", \\\"logs\\\", \\\"metrica\\\", \\\"mgbench\\\", \\\"mta\\\", \\\"noaa\\\", \\\"nyc_taxi\\\", \\\"nypd\\\", \\\"ontime\\\", \\\"otel\\\", \\\"otel_clickpy\\\", \\\"otel_json\\\", \\\"otel_v2\\\", \\\"pypi\\\", \\\"random\\\", \\\"rubygems\\\", \\\"stackoverflow\\\", \\\"star_schema\\\", \\\"stock\\\", \\\"system\\\", \\\"tw_weather\\\", \\\"twitter\\\", \\\"uk\\\", \\\"wiki\\\", \\\"words\\\", \\\"youtube\\\"]\",\"annotations\":null,\"meta\":null}","type":"function"}
error:每条 span 的类型存储在 span_data.type 字段中。例如,下面这三条记录分别表示一次响应、一次列出 MCP 工具的操作、以及一次函数调用。对于函数调用,还可以看到调用时传入的参数和返回结果,这些信息都记录在 span_data 字段中。
使用 HyperDX 可视化 OpenAI agents 的追踪数据
虽然我们可以继续使用 SQL 手动分析这些追踪数据,但还有更高效的方式——借助 HyperDX 进行可视化。HyperDX 是专门为可观测性场景设计的前端界面,它与 OpenTelemetry、ClickHouse 一起构成了 ClickStack 的一部分,支持追踪数据的灵活查询与图形化展示。
HyperDX 可以根据自定义字段读取追踪数据,但为了简化集成流程,我们将创建一个字段结构与其默认 schema 保持一致的表。HyperDX 预期的字段结构如下:
CREATE TABLE otel_traces
(
`Timestamp` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`TraceId` String CODEC(ZSTD(1)),
`SpanId` String CODEC(ZSTD(1)),
`ParentSpanId` String CODEC(ZSTD(1)),
`TraceState` String CODEC(ZSTD(1)),
`SpanName` LowCardinality(String) CODEC(ZSTD(1)),
`SpanKind` LowCardinality(String) CODEC(ZSTD(1)),
`ServiceName` LowCardinality(String) CODEC(ZSTD(1)),
`ResourceAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`ScopeName` String CODEC(ZSTD(1)),
`ScopeVersion` String CODEC(ZSTD(1)),
`SpanAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`Duration` UInt64 CODEC(ZSTD(1)),
`StatusCode` LowCardinality(String) CODEC(ZSTD(1)),
`StatusMessage` String CODEC(ZSTD(1)),
`Events.Timestamp` Array(DateTime64(9)) CODEC(ZSTD(1)),
`Events.Name` Array(LowCardinality(String)) CODEC(ZSTD(1)),
`Events.Attributes` Array(Map(LowCardinality(String), String)) CODEC(ZSTD(1)),
`Links.TraceId` Array(String) CODEC(ZSTD(1)),
`Links.SpanId` Array(String) CODEC(ZSTD(1)),
`Links.TraceState` Array(String) CODEC(ZSTD(1)),
`Links.Attributes` Array(Map(LowCardinality(String), String)) CODEC(ZSTD(1)),
INDEX idx_trace_id TraceId TYPE bloom_filter(0.001) GRANULARITY 1,
INDEX idx_res_attr_key mapKeys(ResourceAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_res_attr_value mapValues(ResourceAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_span_attr_key mapKeys(SpanAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_span_attr_value mapValues(SpanAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_duration Duration TYPE minmax GRANULARITY 1
)
ENGINE = SharedMergeTree('/clickhouse/tables/{uuid}/{shard}', '{replica}')
PARTITION BY toDate(Timestamp)
ORDER BY (ServiceName, SpanName, toDateTime(Timestamp))虽然我们并不需要覆盖全部字段,但可以先建一张包含核心字段的表:
CREATE TABLE agent_spans
(
`Timestamp` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`TraceId` String CODEC(ZSTD(1)),
`SpanId` String CODEC(ZSTD(1)),
`ParentSpanId` String CODEC(ZSTD(1)),
`SpanName` LowCardinality(String) CODEC(ZSTD(1)),
`SpanKind` LowCardinality(String) CODEC(ZSTD(1)),
`ServiceName` LowCardinality(String) CODEC(ZSTD(1)),
`SpanAttributes` JSON,
`Duration` UInt64 CODEC(ZSTD(1)),
`StatusCode` LowCardinality(String) CODEC(ZSTD(1)),
INDEX idx_trace_id TraceId TYPE bloom_filter(0.001) GRANULARITY 1,
INDEX idx_duration Duration TYPE minmax GRANULARITY 1
)
ENGINE = MergeTree
ORDER BY (ServiceName, SpanName, toDateTime(Timestamp));然后再创建一个物化视图,从 agent_spans_raw 表中实时读取新插入的数据,写入标准化后的 agent_spans 表中,以供 HyperDX 使用:
CREATE MATERIALIZED VIEW agent_spans_mv TO agent_spans AS
WITH clean_spans AS (
select trace_id AS TraceId,
id AS SpanId, parent_id AS ParentSpanId,
span_data.type AS SpanName, 'agent' AS SpanKind,
parseDateTime64BestEffort(started_at, 6) AS start,
parseDateTime64BestEffort(ended_at, 6) AS end,
(end-start)*1_000_000 AS Duration,
started_at, 'ok' AS StatusCode,
span_data AS SpanAttributes
FROM agent_spans_raw
)
SELECT
start AS `Timestamp`, TraceId, SpanId, ParentSpanId, SpanName,
SpanKind, 'agent' AS ServiceName,
SpanAttributes, Duration, StatusCode
FROM clean_spans;将追踪数据导入 ClickHouse 并连接 HyperDX 可视化
一切配置就绪后,我们还可以进一步优化流程:将 agent_spans_raw 表的引擎设置为 Null。该引擎不会持久化数据,但仍能通过物化视图将写入数据实时导入到其他表中,适合以 agent_spans 作为正式存储表的架构。
CREATE TABLE agent_spans_raw
(
`trace_id` String,
`id` String,
`parent_id` String,
`started_at` String,
`ended_at` String,
`span_data` JSON,
`error` String,
)
ENGINE = Null;此时重新运行脚本,数据将被写入 agent_spans 表:
SELECT *
FROM agent_spans
LIMIT 3;Row 1:
──────
Timestamp: 2025-10-27 14:54:38.944627000
TraceId: trace_193c3e161a8449859d4daf824d349f0f
SpanId: span_ba4757335154405bb7484126
ParentSpanId:
SpanName: mcp_tools
SpanKind: agent
ServiceName: agent
SpanAttributes: {"result":["list_databases","list_tables","run_select_query"],"server":"ClickHouse SQL Playground","type":"mcp_tools"}
Duration: 1095
StatusCode: ok
Row 2:
──────
Timestamp: 2025-10-27 14:54:38.958115000
TraceId: trace_193c3e161a8449859d4daf824d349f0f
SpanId: span_1de3219725254881ad98578e
ParentSpanId: span_93a5211e80a14d98ae944c90
SpanName: response
SpanKind: agent
ServiceName: agent
SpanAttributes: {"model":"gpt-5-mini-2025-08-07","response_id":"resp_0b2f2bf21108efe60068ff799f47e8819580968609bb10ebea","type":"response"}
Duration: 3111783 -- 3.11 million
StatusCode: ok
Row 3:
──────
Timestamp: 2025-10-27 14:54:42.070196000
TraceId: trace_193c3e161a8449859d4daf824d349f0f
SpanId: span_2991dc72622045ef8fd55988
ParentSpanId: span_93a5211e80a14d98ae944c90
SpanName: function
SpanKind: agent
ServiceName: agent
SpanAttributes: {"input":"{}","mcp_data":{"server":"ClickHouse SQL Playground"},"name":"list_databases","output":"{\"type\":\"text\",\"text\":\"[\\\"amazon\\\", \\\"bluesky\\\", \\\"country\\\", \\\"covid\\\", \\\"default\\\", \\\"dns\\\", \\\"environmental\\\", \\\"forex\\\", \\\"geo\\\", \\\"git\\\", \\\"github\\\", \\\"hackernews\\\", \\\"imdb\\\", \\\"logs\\\", \\\"metrica\\\", \\\"mgbench\\\", \\\"mta\\\", \\\"noaa\\\", \\\"nyc_taxi\\\", \\\"nypd\\\", \\\"ontime\\\", \\\"otel\\\", \\\"otel_clickpy\\\", \\\"otel_json\\\", \\\"otel_v2\\\", \\\"pypi\\\", \\\"random\\\", \\\"rubygems\\\", \\\"stackoverflow\\\", \\\"star_schema\\\", \\\"stock\\\", \\\"system\\\", \\\"tw_weather\\\", \\\"twitter\\\", \\\"uk\\\", \\\"wiki\\\", \\\"words\\\", \\\"youtube\\\"]\",\"annotations\":null,\"meta\":null}","type":"function"}
Duration: 910501
StatusCode: ok很好,数据写入成功。现在我们可以开始在 HyperDX 中进行可视化分析。
HyperDX 提供了托管平台(play.hyperdx.io),可以直接连接到本地运行的 ClickHouse 实例。
打开浏览器访问该地址,将看到配置页面:
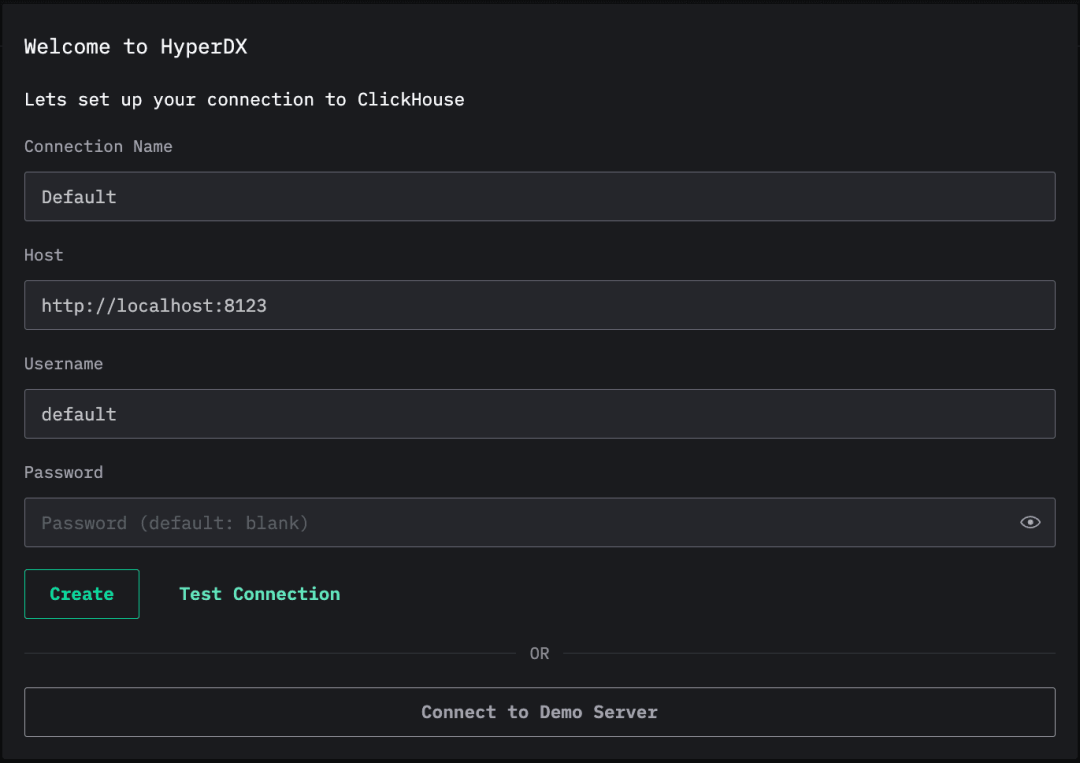
如果你本地使用的是默认配置,那么无需做任何修改。当然,也可以根据实际情况自定义主机地址、用户名和密码。
完成连接配置后,系统会要求你创建一个数据源。选择数据类型为 Trace,然后填写必要的字段即可。
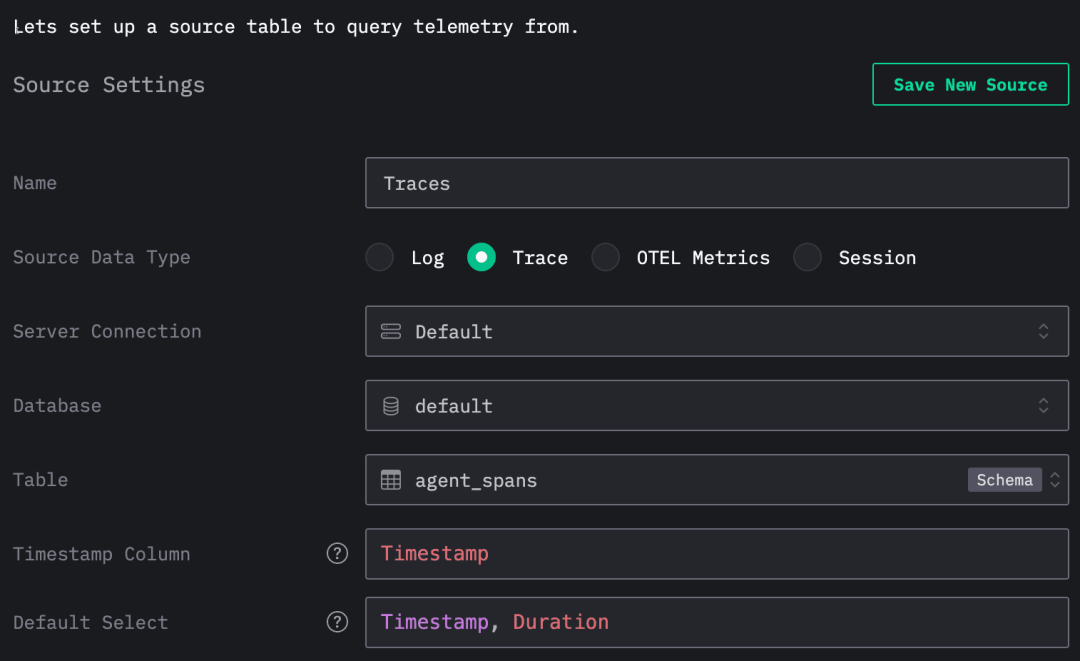
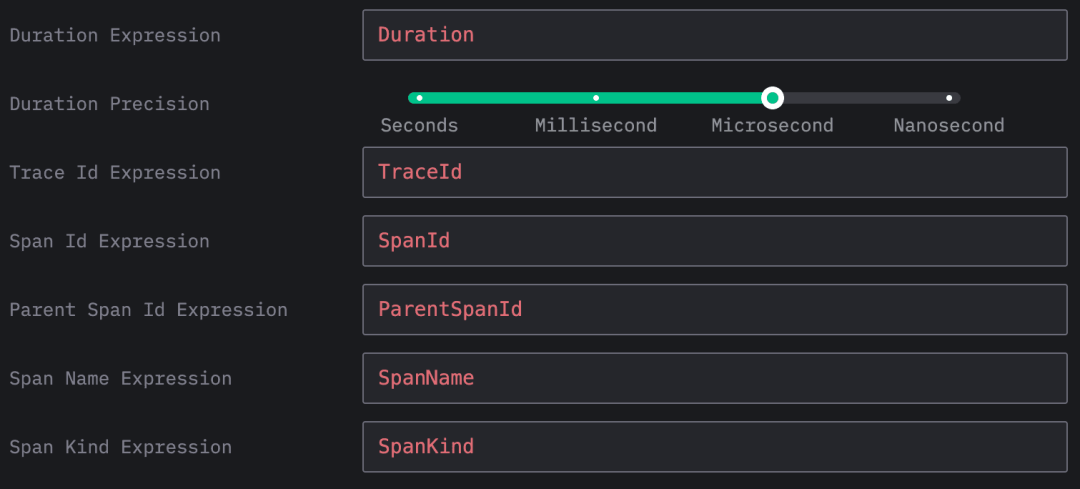

设置完成后,就可以开始浏览和分析追踪数据了。如下图所示,系统已开始接收事件流:
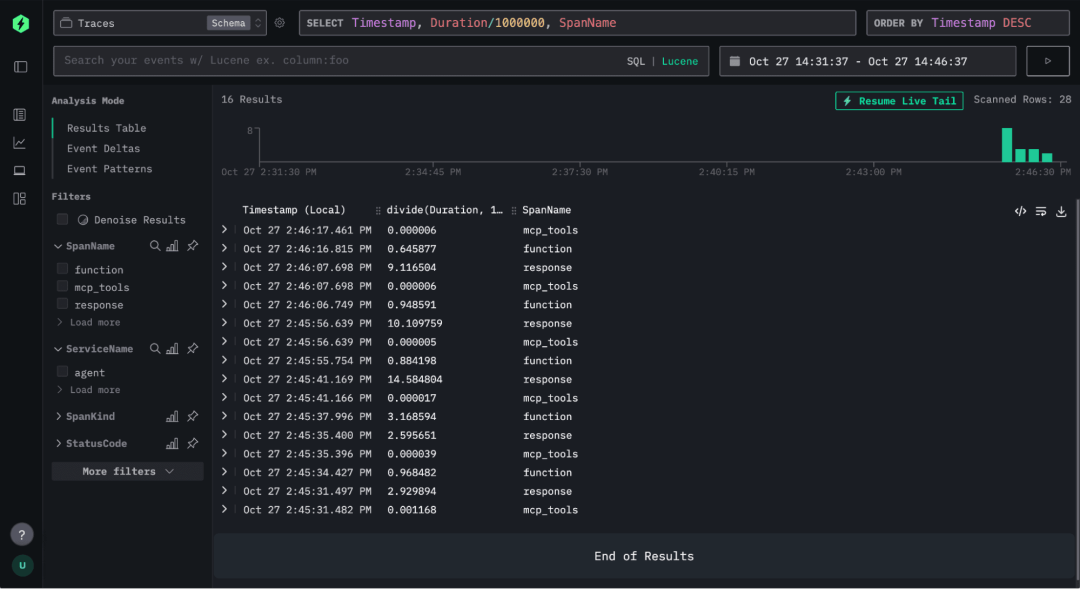
点击任意一条 trace,可以展开查看其完整的函数调用链。
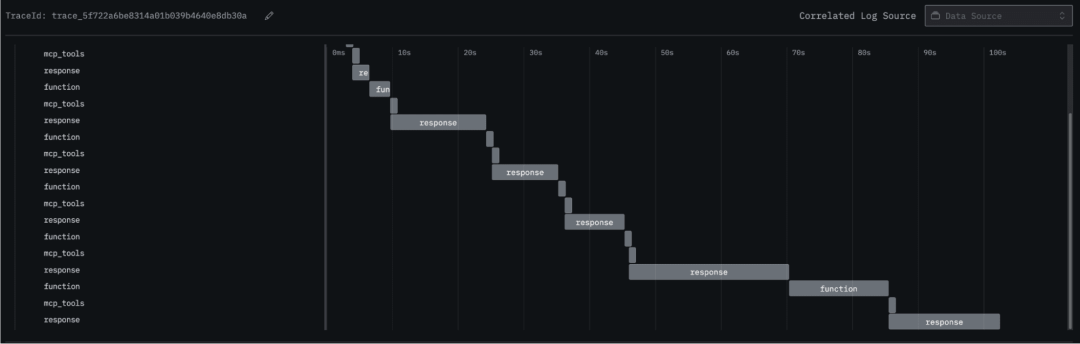
在某些调用链中我们能看到多个函数被重复调用,可能说明某个逻辑出了问题——毕竟这个问题本可以通过一两条 SQL 语句解决。点开其中一个函数查看详情:
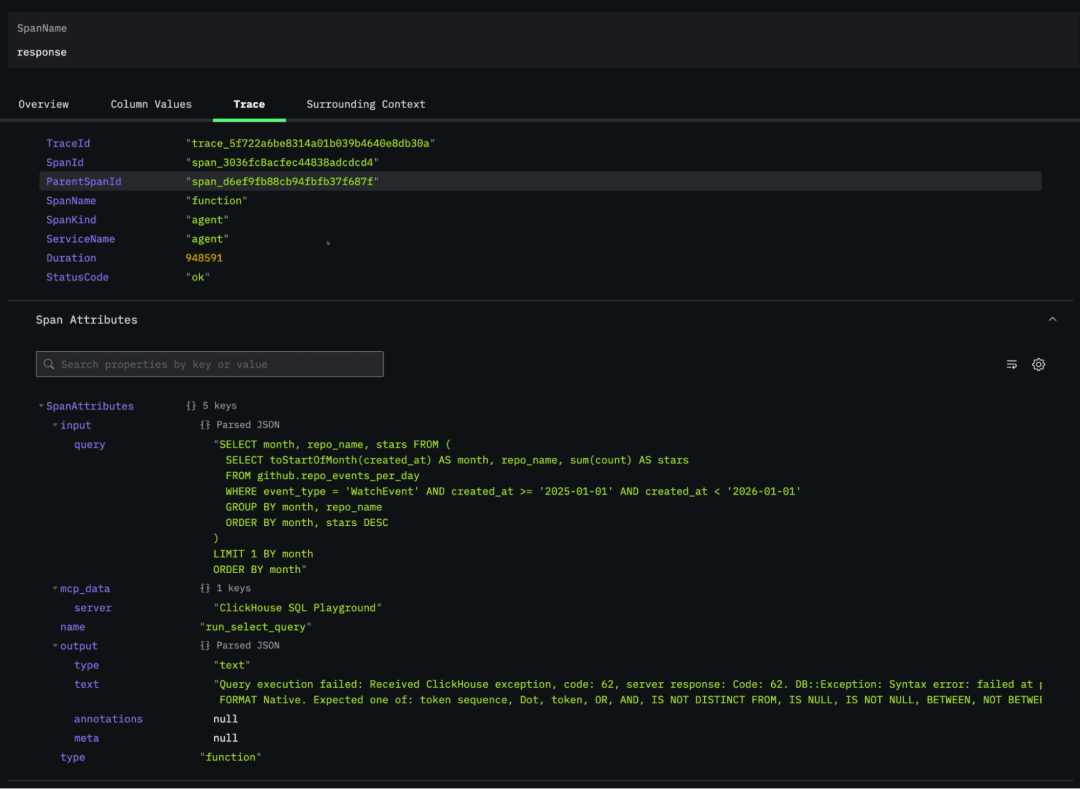
在 “Span Attributes” 区块中我们可以看到,生成的 SQL 查询因语法错误未被成功执行。粗略看了一下,问题出在 SQL 的最后一行,ORDER BY 应该写在 LIMIT 前面。好在智能体最终成功修正了语句,并给出了正确答案。
此外,我们还可以通过任意字段筛选展示的 spans。例如,只查看 SpanName 为 agent 的记录。多次运行后,就可以看到如下筛选结果:
这个案例还可以继续拓展,但就本文而言,我们已经展示了完整的追踪和分析流程。
结语:让 AI 智能体行为透明可观测
通过追踪 AI 智能体的执行过程,我们得以清晰理解其推理逻辑、决策路径和行为表现,尤其是在指令不明确时,这种洞察尤为关键。
本篇文章中,我们从构建一个能访问 ClickHouse 的 OpenAI 智能体开始,逐步实现了追踪数据的采集、导出到 ClickHouse,并借助 HyperDX 实现了高质量的可视化。最终构建起一整套 AI 智能体的可观测性链路——从原始运行数据,到图形化分析界面,一应俱全。
这种机制对调试、模型评估以及理解不同模型和框架的推理差异具有重要意义。随着 AI 系统越来越复杂,可观测性将成为 AI 智能体系统不可或缺的能力。而基于 ClickHouse 的架构,不仅具备性能优势,也为这类分析任务提供了出色的可扩展性。
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









