





本文字数:17454;估计阅读时间:44 分钟
作者:Intel 上海的性能优化工程师:Jiebin Sun、Zhiguo Zhou、Wangyang Guo 和 Tianyou Li。
本文在公众号【ClickHouseInc】首发

Intel 最新一代处理器将服务器的核心数推向了前所未有的新高:Granite Rapids 每个插槽配备多达 128 个 P 核心(P-core),Sierra Forest 则集成了高达 288 个 E 核心(E-core),未来路线图还计划突破每插槽 200 核心。对于多插槽系统而言,这一数字将进一步倍增,整体核心数轻松超过 400。由于物理瓶颈的限制,单核性能提升变得愈发困难,“增加核心数而非提高主频”逐渐成为主流。自 2000 年代中期 Dennard 缩放失效以来,功耗密度问题持续制约着单线程性能的提升。
对于 ClickHouse 这类分析型数据库而言,超高核心数既意味着巨大的性能潜力,也带来了复杂的工程挑战。理论上,更多的核心意味着更强的并发处理能力,但实际中,多数数据库并未能充分发挥这些硬件资源。随着核心数的上升,锁争用、缓存一致性、NUMA 布局、内存带宽瓶颈以及线程协作开销等问题也会随之加剧。
如何优化 ClickHouse 以适应超高核心数
过去三年,我一直专注于提升 ClickHouse 在 Intel Xeon 超高核心数处理器上的可扩展性。通过使用 perf、emon、Intel VTune 等一系列性能分析工具,我们系统性地分析了全部 43 条 ClickBench 查询在超高核心服务器上的执行情况,识别瓶颈,并逐一对 ClickHouse 进行针对性优化。
优化成效显著:部分查询的性能提升可达数倍,最高甚至接近 10 倍;所有 43 条 ClickBench 查询在每项优化下的几何平均性能提升普遍在 2% 至 10% 之间。实践证明,ClickHouse 完全可以在超高核心数平台上实现良好的扩展性。
扩展核心数所面临的主要挑战
为了在多核环境下实现高性能,不仅要关注单线程速度,还需解决以下关键问题:
-
缓存一致性:频繁的缓存行转移会导致 CPU 周期浪费。
-
锁争用:即便只有 1% 的串行代码,Amdahl 定律也可能显著拉低整体并发性能。
-
内存带宽:对数据密集型系统而言,如何高效利用内存带宽一直是核心难点,良好的内存复用和缓存机制至关重要。
-
线程协同:线程间同步的代价会随着线程数量提升而呈超线性增长。
-
NUMA 架构差异:多插槽架构下,访问本地与远程内存的延迟与带宽差异明显。
这篇文章总结了我们在超高核心数服务器上优化 ClickHouse 的核心方法。这些优化均已合并至 ClickHouse 主线代码,现已在全球范围内的实际部署中带来性能提升。
硬件配置方面:本次实验基于 Intel 最新平台,包括:
-
2 × 80 vCPU 的 Ice Lake(ICX)
-
2 × 128 vCPU 的 Sapphire Rapids(SPR)
-
1 × 288 vCPU 的 Sierra Forest(SRF)
-
2 × 240 vCPU 的 Granite Rapids(GNR)
其中除 SRF 外,其余平台均启用了 SMT(超线程)和高内存带宽配置。
软件方面,我们使用了 perf、Intel VTune、流水线可视化工具及多种自研性能分析工具进行深入剖析。
五大优化方向
在对 ClickHouse 在超高核心数系统上的运行表现进行系统性剖析后,我识别出五个最具潜力的优化方向。这些方向涵盖可扩展性的不同方面,共同构成了一套系统的性能提升路径,能够最大限度地释放硬件潜力。
而整个优化工作的起点,就是最基本却又最致命的问题:锁争用。
瓶颈 1:锁争用
根据排队理论,当 N 个线程同时竞争一个锁时,等待时间会以 N² 的速度增长。例如从 8 核扩展到 80 核,锁等待时间理论上会提升 100 倍。同时,mutex 本身会产生大量缓存一致性流量,线程上下文切换的开销也会成倍增加。在这种高并发场景中,任意一个 mutex 都可能成为可扩展性的瓶颈,哪怕是再微小的同步代码,也可能拖垮整个系统。
关键点在于,解决锁争用问题并不仅仅是“去掉锁”这么简单,更重要的是彻底重新设计线程之间的协作方式和状态共享机制。这通常需要多管齐下的策略,包括:
-
缩短关键路径的执行时长(critical section)
-
将粗粒度的互斥锁(mutex)替换为更细粒度的同步机制
-
在可能的场景中,彻底取消共享状态(stateless design)
优化 1.1:查询条件缓存优化(PR #80247)
在优化 jemalloc 页错误(详见后文)后,我们在 native_queued_spin_lock_slowpath 函数中发现了新的性能热点:该函数占据了整整 76% 的 CPU 时间,调用源自 QueryConditionCache::write,在 2×240 vCPU 的系统中尤为严重。
那么,什么是查询条件缓存(Query Condition Cache)?
它是 ClickHouse 中用于缓存 WHERE 子句过滤条件结果的组件,目的是在查询时跳过无效数据。每次执行 SELECT 查询时,多个线程会根据以下条件判断是否需要更新缓存条目:
-
过滤条件的哈希值(作为缓存 key)
-
本次读取的 mark 范围
-
当前读取的分片是否包含 final mark
这个组件的读写比非常不均衡——主要以读取为主。但原始实现却对所有操作都使用独占锁(write lock),导致严重争用:
优化读密集型工作负载中的关键路径
该优化展示了在读密集型代码中减少锁持有时间(尤其是写锁)的重要性。
在单个查询中启用 240 个线程时,原始实现会导致严重的性能瓶颈:
-
所有线程即使仅仅是读取缓存,也要获取写锁
-
更新操作在写锁中执行,导致临界区时间很长
-
多个线程可能重复更新同一个缓存条目
为了优化这一点,我们引入了带有原子操作的“双重检查锁定(double-checked locking)”策略:
1. 快速路径(fast path):通过原子读取或共享锁检查是否需要更新,如果不需要,直接返回,无需加锁。
2. 慢速路径(slow path):如果需要更新,则获取写锁,再次确认是否仍需要更新——因为其他线程可能已经完成了相同的更新。
实现
该优化已通过 PR #80247 合并至主线。它有效绕过了不必要的写锁开销,尤其适用于这种以读为主的缓存访问模式,在 240 线程场景下大幅提升了吞吐能力。
/// Original code
void updateCache(mark_ranges, has_final_mark)
{
acquire_exclusive_lock(cache_mutex); /// 240 threads wait here!
/// Always update marks, even if already in desired state
for (const auto & range : mark_ranges)
set_marks_to_false(range.begin, range.end);
if (has_final_mark):
set_final_mark_to_false();
release_lock(cache_mutex);
}
/// Optimized code
void updateCache(mark_ranges, has_final_mark)
{
/// Fast path: Check if update is needed with a cheap shared lock
acquire_shared_lock(cache_mutex); /// Multiple threads can read simultaneously
need_update = false;
for (const auto & range : mark_ranges)
{
if (any_marks_are_true(range.begin, range.end))
{
need_update = true;
break;
}
}
if (has_final_mark && final_mark_is_true())
need_update = true;
release_shared_lock(cache_mutex);
if (!need_update)
return; /// Early out - no expensive lock needed!
/// Slow path: Actually need to update, acquire exclusive lock
acquire_exclusive_lock(cache_mutex);
/// Double-check: verify update is still needed after acquiring lock
need_update = false;
for (const auto & range : mark_ranges)
{
if (any_marks_are_true(range.begin, range.end))
{
need_update = true;
break;
}
}
if (has_final_mark && final_mark_is_true())
need_update = true;
if (need_update)
{
// Perform the actual updates only if still needed
for (const auto & range : mark_ranges)
set_marks_to_false(range.begin, range.end);
if (has_final_mark)
set_final_mark_to_false();
}
release_lock(cache_mutex);
}性能提升概览
这一优化在真实负载下带来了非常显著的性能收益:
-
native_queued_spin_lock_slowpath 的 CPU 消耗从 76% 降至仅 1%
-
ClickBench 查询 Q10 与 Q11 的每秒查询数(QPS)分别提升了 85% 和 89%
-
全部 ClickBench 查询的几何平均性能提升达 8.1%
优化 1.2:线程本地定时器 ID(Thread-Local Timer ID,PR #48778)
我们发现 ClickHouse 的查询分析器在执行过程中频繁创建和销毁一个全局变量 timer_id,引发了显著的锁争用问题,尤其在核心数极高的系统中尤为明显。
查询分析器中的定时器问题
ClickHouse 查询分析器基于 POSIX 定时器机制,对线程堆栈进行周期性采样,从而收集运行时数据进行性能剖析。原始实现中存在两个关键问题:
-
在每次分析过程中都会创建并销毁 timer_id,操作频繁
-
所有与定时器相关的操作(读/写)都需要通过全局锁进行同步
由于依赖共享数据结构,这导致了分析过程中的严重性能瓶颈。
通过 Thread-Local Storage 消除锁争用
我们通过引入线程本地存储(Thread-Local Storage, TLS)来彻底消除这一瓶颈。现在,每个线程都会维护属于自己的 `timer_id`,完全避免了共享状态,也无需再使用互斥锁来同步访问。
这样一来,定时器的更新过程不再需要加锁,同时也提升了系统整体的可扩展性。
技术方案
/// Original code
class QueryProfiler
{
static global_mutex timer_management_lock
void startProfiling()
{
timer_id = create_new_timer(); /// Expensive system call
acquire_exclusive_lock(timer_management_lock); /// Global lock!
update_shared_timer_state(timer_id); /// Modify shared state
release_lock(timer_management_lock);
}
void stopProfiling()
{
acquire_exclusive_lock(timer_management_lock);
cleanup_shared_timer_state(timer_id);
release_lock(timer_management_lock);
delete_timer(timer_id);
}
}/// Optimized code
class QueryProfiler
{
static thread_local timer_id per_thread_timer;
static thread_local boolean timer_initialized;
void startProfiling()
{
if (!timer_initialized)
{
per_thread_timer = create_new_timer(); /// Once per thread
timer_initialized = true;
}
/// Reuse existing timer - no locks, no system calls!
enable_timer(per_thread_timer);
}
void stopProfiling()
{
/// Just disable timer - no deletion, no locks!
disable_timer(per_thread_timer);
}
}技术实现与效果总结
优化后的实现带来了以下几点提升:
-
彻底消除了分析器中与定时器相关的锁争用热点,性能剖析更加高效
-
通过重用定时器对象,大幅减少了系统调用次数,降低了资源开销
-
显著提升了在超高核心数服务器上的分析器扩展能力
这一优化再次验证了线程本地存储的价值:当每个线程维护自己的状态时,全局同步便不再必要,系统的并发性能也随之大幅提升。
瓶颈 2:内存管理与分配优化
在超高核心数系统中,内存优化面临的挑战远超传统单线程环境。内存分配器本身就可能成为性能瓶颈,内存带宽也需在更多核心间共享;此外,许多在小规模系统中表现良好的内存使用模式,放大后可能引发级联的性能问题。因此,我们必须密切关注每一次内存分配的方式与行为。
这一类优化主要聚焦于:内存分配器的内部机制、如何降低对内存带宽的压力,甚至在某些场景中要彻底重构算法逻辑,以避免内存密集型操作。
优化 2.1:Jemalloc 内存重用优化([PR #80245])
PR #80245(https://github.com/ClickHouse/ClickHouse/pull/80245)
这个优化来源于我们在高核数系统上执行某些聚合查询时,观察到的页面错误频繁发生,以及常驻内存(VmRSS)使用异常升高的问题。
ClickHouse 聚合中二级哈希表结构
ClickHouse 在执行聚合查询时,会根据数据类型、数据量与分布特征,使用不同的哈希表。对于大规模聚合操作,使用的是如下的两层结构:
-
第一层是固定的 256 个静态桶,每个桶指向第二层的一个独立哈希表
-
每个二级哈希表可以根据需要独立扩展,不受其他桶影响
问题出在释放后的内存复用效率
聚合查询结束后,这些哈希表会被释放,并将内存合并为大块空闲区域。但我们发现:即使这些大块内存已释放,jemalloc 却很难有效将其重新用于未来的小规模分配操作。
问题的根源在于 jemalloc 的默认行为:它只能重用大小不超过目标分配 64 倍的空闲块。而 ClickHouse 的哈希表结构导致小块和大块分配交替频繁,这种策略大大限制了内存的复用能力。
通过调研 [jemalloc issue
#2842](https://github.com/jemalloc/jemalloc/issues/2842),我们识别出了影响内存重用的几个关键机制问题:
-
内存块追踪能力弱:大块释放后,jemalloc 无法高效管理这些空间
-
大小类别(size class)碎片化严重:空闲内存被限制在特定分类中,难以跨类别复用
-
元数据结构占用过多空间:阻碍了有效的内存块合并
-
页面错误放大效应:新分配触发了频繁的 page fault,而不是重用已有的内存页
深入分析后,我们锁定配置参数 lg_extent_max_active_fit 为核心限制因素,其默认值对 ClickHouse 的分配模式明显不适用。
我们将修复提交至 jemalloc(见 PR
#2842),但由于其稳定版本更新周期较慢,最终我们通过在 ClickHouse 内部构建时修改 jemalloc 配置参数,成功绕开了这一问题(详见 [PR
#80245](https://github.com/ClickHouse/ClickHouse/pull/80245))。
/// Original jemalloc configuration
JEMALLOC_CONFIG_MALLOC_CONF = "oversize_threshold:0,muzzy_decay_ms:0,dirty_decay_ms:5000"
/// lg_extent_max_active_fit defaults to 6, meaning memory can be reused from extents up to 64x larger than the requested allocation size/// Optimized jemalloc configuration
JEMALLOC_CONFIG_MALLOC_CONF = "oversize_threshold:0,muzzy_decay_ms:0,dirty_decay_ms:5000,lg_extent_max_active_fit:8"
/// lg_extent_max_active_fit is set to 8.
/// This allows memory reuse from extents up to 256x larger
/// than the requested allocation size (2^8 = 256x vs default 2^6 = 64x).
/// The 256x limit matches ClickHouse's two-level hash table structure (256 buckets).
/// This enables efficient reuse of merged hash table memory blocks.优化效果
该项优化带来了显著改善:
-
ClickBench 查询 Q35 性能提升 96.1%
-
同一查询的常驻内存使用(VmRSS)降低了 45.4%,页面错误数减少了 71%
这项工作说明,在超高核心数平台上,内存分配器的行为会直接决定系统性能表现,且对查询性能和系统稳定性有深远影响。
优化 2.2:通过 AST 查询改写降低内存使用(PR #57853)
PR #57853(https://github.com/ClickHouse/ClickHouse/pull/57853)
ClickBench 查询 Q29 的瓶颈在于重复计算 sum(column + literal) 表达式,导致了大量临时列与聚合操作,严重消耗内存带宽。
分析内存瓶颈
ClickBench 查询 Q29 中包含多个带有字面值的 sum 表达式:
SELECT SUM(ResolutionWidth), SUM(ResolutionWidth + 1), SUM(ResolutionWidth + 2),
SUM(ResolutionWidth + 3), SUM(ResolutionWidth + 4), SUM(ResolutionWidth + 5),
SUM(ResolutionWidth + 6), SUM(ResolutionWidth + 7), SUM(ResolutionWidth + 8),
SUM(ResolutionWidth + 9), SUM(ResolutionWidth + 10), SUM(ResolutionWidth + 11),
SUM(ResolutionWidth + 12), SUM(ResolutionWidth + 13), SUM(ResolutionWidth + 14),
SUM(ResolutionWidth + 15), SUM(ResolutionWidth + 16), SUM(ResolutionWidth + 17),
SUM(ResolutionWidth + 18), SUM(ResolutionWidth + 19), SUM(ResolutionWidth + 20),
-- ... continues up to SUM(ResolutionWidth + 89)
FROM hits;原始查询的执行过程包括:
-
从磁盘加载一次原始列(例如 ResolutionWidth)
-
对该列进行 90 次计算,每次加一个常量,生成 90 个临时列
-
分别对这 90 个临时列执行 90 次独立的 `sum()` 聚合
这显然引入了极大的内存开销与重复计算负担。
优化策略:使用代数重写规则,消除冗余计算
我们通过改写语法树(AST),将 `sum(column + literal)` 转换为更高效的:
sum(column + literal) → sum(column) + count(column) * literal
该表达式改写可大幅减少内存分配和中间数据结构,从源头上解决问题。
性能提升:
-
查询 Q29 的执行速度在 2×80 vCPU 系统上提升了 11.5 倍
-
所有 ClickBench 查询的平均性能提升 5.3%
这说明:比起执行优化,更智能的查询改写能更有效避免不必要的计算,避免工作总比优化工作本身更划算。
瓶颈 3:提升并行能力以解决聚合合并瓶颈
在分析型数据库中,聚合是最核心的操作之一。但很多时候,聚合计算虽然并行完成,结果合并阶段却成为了性能瓶颈。
ClickHouse 的聚合过程分两步:
1. 每个线程对自己的数据子集进行并行聚合,产生“局部结果”
2. 所有局部结果最终合并为全局结果
第二阶段若未能并行化,将拖累整体性能。而线程越多,局部结果越多,串行合并反而更慢。
要解决这一问题,需要精心设计算法、合理选择数据结构,并深入理解哈希表在不同负载模式下的表现。目标是彻底消除串行合并阶段,使最复杂的聚合查询也能实现线性扩展。
优化 3.1:哈希表并行转换(PR #50748)
PR #50748(https://github.com/ClickHouse/ClickHouse/pull/50748)
我们在分析 ClickBench 查询 Q5 时,发现当线程数从 80 增加到 112 时,性能反而下降。
根因:哈希表类型转换过程是串行的
ClickHouse 聚合时使用两种哈希表:
-
单层哈希表:结构简单,适用于数据量小、线程处理量大的场景
-
二级哈希表:包含 256 个桶,适用于大数据量,支持桶级并行
默认策略是:当单层哈希表在聚合过程中超出某个阈值,会自动转换为二级结构。
问题出现在哪?
当部分线程产生的是单层哈希表,部分是二级哈希表时,系统必须先将所有单层表转换为二级,然后再进行并行合并。而原始实现中,这一步是串行执行的。
更糟的是:线程数越多(比如 112),每个线程处理的数据就越少,结果更多线程“卡”在单层表,最终导致合并阶段成倍变慢。
诊断方法:流水线可视化
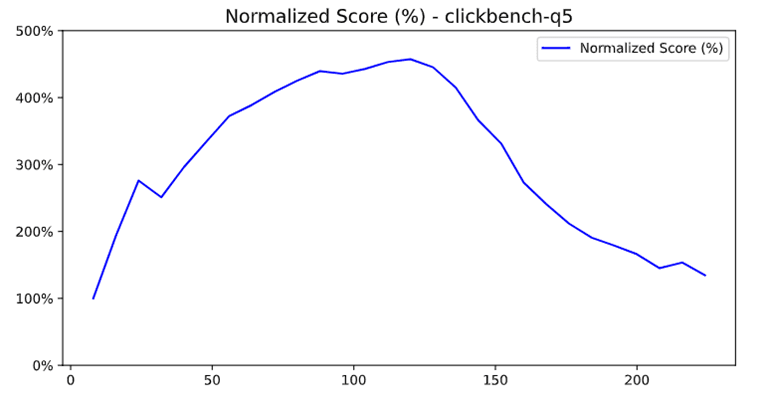
我们通过执行计划可视化工具发现:

在 max_threads = 80 时,合并阶段耗时正常

在 max_threads = 112 时,合并阶段耗时竟然增加了 3.2 倍
这就是串行瓶颈的信号。
优化策略:将哈希表转换过程并行化
我们优化了这一阶段逻辑:
-
不再串行转换哈希表
-
而是将每个线程的哈希表独立转换为二级结构
-
然后执行并行桶级合并
这样做完全消除了串行处理依赖,使得整个聚合过程恢复线性扩展能力。
/// Original code
void mergeHashTable(left_table, right_table)
{
if (left_table.is_single_level() && right_table.is_two_level())
left_table.convert_to_two_level(); /// Serial conversion blocks threads
/// Now merge
merge_sets(left_table, right_table);
}/// Optimized code
void mergeHashTableParallel(all_tables)
{
/// Phase 1: Parallel conversion
parallel_tasks = [];
for (const auto & table : all_tables)
{
if (table.is_single_level())
{
/// Parallel conversion!
task = create_parallel_task(table.convert_to_two_level());
parallel_tasks.add(task);
}
}
/// Wait for all conversions to complete
wait_for_all_tasks(parallel_tasks);
/// Phase 2: Now all sets are two-level, merge efficiently.
for (const auto & pair : all_tables)
merge_sets(pair.left_table, pair.right_table);
}并行合并的性能突破:从优化 Q5 到全面扩展聚合能力
我们原本的目标是优化 ClickBench 查询 Q5,结果发现这项优化为所有以聚合为主的查询带来了结构性突破 —— 聚合查询首次在超高核心数系统上实现了真正的线性扩展。
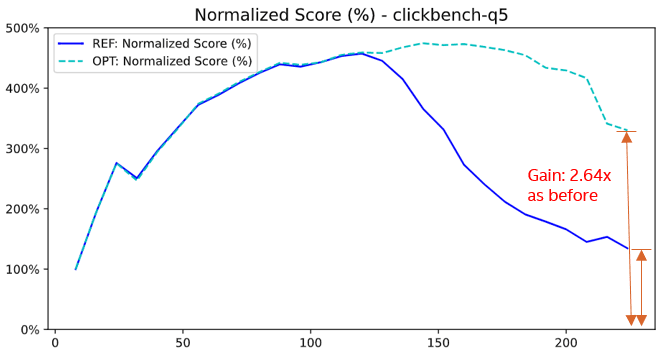
完成并行化改造后,性能有显著提升 —— Q5 查询性能提高了 264%。
整体性能表现:
-
查询 Q5 在 2×112 vCPU 系统上性能提升 264%
-
共计 24 条查询的性能提升超过 5%
-
所有 ClickBench 查询的几何平均性能提升 7.4%
这项工作也让我们意识到:可扩展性不只是“增加并行线程”那么简单,更关键的是消除那些随着并行度提升而加剧的串行逻辑。想要实现真正的横向扩展,有时候就需要从底层重构整个算法结构,而不仅仅是堆线程。
优化 3.2:单层哈希表也要并行合并(PR #52973)
PR #52973(https://github.com/ClickHouse/ClickHouse/pull/52973)
我们最初的并行优化只处理“混合类型”哈希表(即单层与二级共存)。但测试中发现,即使所有线程都使用单层哈希表,在数据量较大时性能依然受限,原因就在于合并阶段仍是串行的。
核心挑战:并不是所有情况都值得并行处理。
-
数据量小:并行带来的调度开销可能反而降低性能
-
数据量大:并行合并能显著缩短合并耗时
我们通过 PR #52973(https://github.com/ClickHouse/ClickHouse/pull/52973/files)引入了智能并行合并机制 —— 只要判断当前数据量超过阈值,系统就会在单层哈希表中启用并行合并路径。
/// Before: Only parallelize mixed-level merges
void parallelizeMergePrepare(hash_tables)
{
single_level_count = 0;
for (const auto & hash_table : hash_tables)
if hash_table.is_single_level():
single_level_count++;
/// Only convert if mixed levels (some single, some two-level)
if single_level_count > 0 and single_level_count < hash_tables.size():
convert_to_two_level_parallel(hash_tables);
}/// Optimized code
void parallelizeMergePrepare(hash_tables):
{
single_level_count = 0;
all_single_hash_size = 0;
for (const auto & hash_table : hash_tables)
if (hash_table.is_single_level())
single_level_count++
/// Calculate total size if all hash tables are single-level
if (single_level_count == hash_tables.size())
for (const auto & hash_table : hash_tables)
all_single_hash_size += hash_table.size();
/// Convert if mixed levels OR if all single-level with average size > THRESHOLD
if (single_level_count > 0 and single_level_count < hash_tables.size())
||
(all_single_hash_size / hash_tables.size() > THRESHOLD)
convert_to_two_level_parallel(hash_tables);
}优化效果:
-
大数据场景下,单层哈希表合并性能提升达 235%
-
通过大量实测数据找到了触发并行的最优阈值
-
小数据集上无任何性能回退风险,完全安全落地
优化 3.3:并行支持带键的哈希合并(PR #68441)
PR #68441(https://github.com/ClickHouse/ClickHouse/pull/68441)
前两个优化专注于不含键的哈希结构,比如 COUNT(DISTINCT) 或其它无键聚合操作。而在真实分析场景中,最常见的仍然是带键的 GROUP BY 查询。
我们继续推动并行能力向更复杂的聚合结构扩展:即哈希表中不仅存储 key,还包含需要进一步聚合合并的值。
这种场景原先完全串行,合并阶段常常成为瓶颈。我们在 PR #68441 中引入了带键并行合并机制,确保值的合并计算也能分发到多个线程处理。
性能效果:
-
查询 Q8 提升 10.3%,Q9 提升 7.6%
-
无任何回退或兼容性问题
-
合并阶段的 CPU 利用率明显提升,计算资源充分释放
需要注意的是,带键的并行合并要求我们在引擎中特别关注错误处理与中止逻辑的正确性,但最终结果表明:即便是最复杂的聚合模式,也可以通过正确策略实现高效并行。
并行合并不再只是优化技巧,而是 ClickHouse 在超高核心系统中真正实现横向扩展的基石。
瓶颈 4:算法优化 —— 利用 SIMD 重构字符串搜索逻辑
在数据库系统中充分发挥 SIMD 指令集的性能潜力是一项长期难题。主流编译器对自动向量化非常谨慎,而数据库中的复杂控制流也常常阻碍向量化策略的应用。
要真正发挥 SIMD 的价值,我们需要跳出传统的“每次处理更多数据”思维,转而关注:如何利用 SIMD 的并行比较能力,让算法更“聪明”、更早剪枝,从而整体减少计算负担。
这种策略在字符串操作中尤其有效 —— 字符串操作在分析查询中非常常见,同时又是性能开销最大的部分之一。
优化 4.1:双字符 SIMD 字符串搜索(PR #46289)
PR #46289(https://github.com/ClickHouse/ClickHouse/pull/46289)
我们观察到,许多查询在执行 LIKE 或 substring 匹配时性能瓶颈严重,典型代表是 ClickBench 查询 Q20,该查询需要对数百万条 URL 进行模式匹配。
原始问题:误判过多导致性能浪费
之前的实现中,ClickHouse 虽已使用 SIMD 进行加速,但只使用了模式字符串的第一个字符进行初筛。这种策略虽然快速,但误判率高 —— 即便只匹配首字符也会触发后续完整匹配逻辑,造成严重浪费。
SELECT COUNT(*) FROM hits WHERE URL LIKE '%google%'解决方案:加入第二个字符判断
我们通过 PR #46289 引入了更智能的 双字符过滤策略:在 SIMD 指令中同时判断搜索模式的前两个字符。虽然只增加了极少量指令,但由于筛选条件更加严格,误判大幅减少,从而:
-
减少后续不必要的精确匹配操作
-
降低内存访问次数
-
提升 CPU 缓存命中率
-
改善分支预测行为
/// Original code
class StringSearcher
{
first_needle_character = needle[0];
first_needle_character_vec = broadcast_to_simd_vector(first_needle_character);
void search()
{
for (position in haystack; step by 16 bytes)
{
haystack_chunk = load_16_bytes(haystack + position);
first_matches = simd_compare_equal(haystack_chunk, first_needle_character_vec);
match_mask = extract_match_positions(first_matches);
for (const auto & match : match_mask)
/// High false positive rate - many expensive verifications
if (full_string_match(haystack + match_pos, needle))
return match_pos;
}
}
}// Optimized code
class StringSearcher
{
first_needle_character = needle[0];
second_needle_character = needle[1]; /// Second character
first_needle_character_vec = broadcast_to_simd_vector(first_needle_character);
second_needle_character_vec = broadcast_to_simd_vector(second_needle_character);
void search()
{
for (position : haystack, step by 16 bytes)
{
haystack_chunk1 = load_16_bytes(haystack + position);
haystack_chunk2 = load_16_bytes(haystack + position + 1);
/// Compare both characters simultaneously
first_matches = simd_compare_equal(haystack_chunk1, first_needle_character_vec);
second_matches = simd_compare_equal(haystack_chunk2, second_needle_character_vec);
combined_matches = simd_and(first_matches, second_matches);
match_mask = extract_match_positions(combined_matches);
for (const auto & match : match_mask)
// Dramatically fewer false positives - fewer expensive verifications
if full_string_match(haystack + match_pos, needle):
return match_pos;
}
}
}性能表现:
-
查询 Q20 性能提升 35%
-
其他涉及子串搜索的查询整体提升约 10%
-
所有 ClickBench 查询的平均性能提升 4.1%
这项优化再次印证了一个观点:高效的 SIMD 使用不只是每条指令处理更多数据,而是用并行比较的方式,让整个算法更早“做减法”。
通过仅仅增加第二个字符的判断,就显著减少了误判和无效计算 —— 是一个典型“低成本、高回报”的数据库底层优化策略。
瓶颈 5:伪共享 —— 小变量,大灾难
在超高核心数系统中,缓存行的争用常常被低估。而“伪共享(False Sharing)”就是其中最隐蔽、也最致命的问题之一。
伪共享指的是:多个线程虽然访问的是不同变量,但这些变量恰好处于同一个缓存行内,由于 CPU 缓存一致性协议以“缓存行为单位”处理同步操作,任意线程对该缓存行的写操作,都会导致其他线程的缓存副本失效。这将触发昂贵的核心间同步,拖垮整个系统的吞吐能力。
举个例子:在一个拥有 2×240 个 vCPU 的系统上,一个简单的计数器自增操作,就可能因为伪共享而演变成全系统范围的性能灾难。
优化 5.1:ProfileEvents 计数器缓存行对齐(PR #82697)
PR #82697(https://github.com/ClickHouse/ClickHouse/pull/82697)
我们在分析 ClickBench 查询 Q3 时发现,其 36.6% 的 CPU 时间都消耗在 ProfileEvents::increment 函数上。通过使用 perf 工具进行深入分析,我们定位到:根因是严重的缓存行争用。
背景:ProfileEvents 是什么?
这是 ClickHouse 用于内部事件统计的系统,追踪查询执行、内存分配、线程状态等核心指标。在高并发的分析型查询中,这些计数器被高频更新 —— 往往是每个线程每秒数百万次。
而问题就在于:这些计数器原本被紧密地打包在连续内存中,没有考虑缓存行边界。
为什么会出问题?
-
现代处理器的缓存行大小为 64 字节。如果同一缓存行内的任意字节被写入,其它核心的缓存副本必须失效。
-
当有 240 个线程同时更新这些计数器时,每次操作都触发缓存行无效化,导致原本应并行的操作被串行化处理。
-
核心数越多,争用越严重,问题呈指数级恶化。
定位工具:perf + c2c
我们使用了 `perf` 的 c2c(cache-to-cache)模块,进一步追踪缓存行粒度的争用情况,最终发现有 8 个不同计数器共用一个缓存行 —— 这是严重的设计问题。
我们还联合社区改进了 perf 的工具能力,方便后续开发者识别类似的缓存争用模式。

解决方案:对齐缓存行
在 PR #82697 中,我们为每个计数器添加了结构体对齐,使其独占一个 64 字节的缓存行。结果非常显著:
-
ProfileEvents::increment 的 CPU 时间从 36.6% 降到 8.5%
-
查询 Q3 性能提升 27.4%,并且随着核心数增长收益更大
// Before: Counters packed without alignment
struct ProfileEvents:
atomic_value counters[NUM_EVENTS] // Multiple counters per cache line
// 8 counters sharing single 64-byte cache lines
// After: Cache line aligned counters
struct ProfileEvents:
struct alignas(64) AlignedCounter:
atomic_value value
// Padding automatically added to reach 64 bytes
AlignedCounter counters[NUM_EVENTS] // Each counter gets own cache line
// Now each counter has exclusive cache line ownership小结:缓存对齐不仅提升性能,更改变可扩展性曲线
伪共享是一个看不见却非常致命的性能陷阱。在 8 核系统中几乎不会被察觉的细节,在 240 核系统中可能引发整个查询性能雪崩。
这项优化告诉我们:在构建能“上得去”的并行系统时,内存布局和缓存对齐与算法优化一样重要。

优化后:ProfileEvents::increment 的耗时比例从 36.6% 降至 8.5%。
它不仅消除了一个瓶颈,更是改变了 ClickHouse 的可扩展性斜率 —— 让它在面向未来的超高并发环境下,跑得更快、更稳、更远。
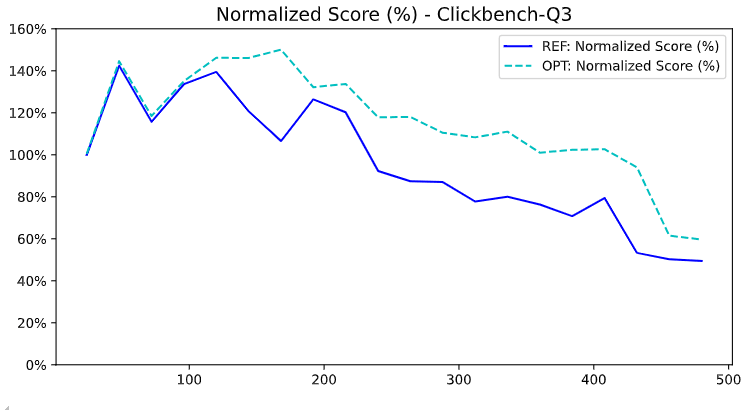
ClickBench Q3:性能提升 27.4%,在高核数系统上提升幅度更大。
构建一套面向未来的可扩展基础
本文围绕 ClickHouse 在超高核心数系统上的五大性能瓶颈,逐一提出了针对性的优化方案:
-
锁争用:线程越多,锁的协调成本指数级上升。我们通过消除不必要的独占锁、缩短临界区和改用原子操作等方式显著降低了锁开销。
-
内存带宽与管理:随着核心数上升,每个核心的可用内存带宽下降,而传统分配策略在大规模并发场景下容易造成碎片、page fault 等严重问题。我们通过调整 jemalloc 配置、改写内存密集算法、避免内存浪费等手段,显著降低了内存占用和页面错误率。
-
并行阶段串行化:线程数越多,结果合并阶段成为瓶颈。我们通过引入并行哈希表转换与合并逻辑,将原本线性增长的合并耗时,优化为接近常数级的并行处理。
-
SIMD 优化:传统 SIMD 使用往往停留在“多处理一条数据”,我们提出更高阶的利用方式,例如双字符 SIMD 筛选,大幅减少误判和不必要计算,提升了分支预测和缓存命中率。
-
伪共享:随着核心数上升,缓存行争用问题愈发严重。我们通过缓存行对齐与结构填充,将高度并发的数据结构隔离至不同缓存行,彻底解决了 false sharing 带来的吞吐瓶颈。
这些优化远不仅仅服务于 ClickHouse 本身,它们代表了整个数据库系统在未来高并发架构中应对硬件发展趋势的核心设计思路。未来,随着 Intel 和其他硬件厂商将处理器推向“千核”甚至“万核”时代,这类技术将不再是“优化”,而是基础建设。
在本文优化的支撑下,ClickHouse 实现了接近线性扩展的性能曲线,为其在未来数据密集型、并发压力巨大的分析场景中继续保持领先打下了坚实基础。

参考链接与资源
-
源码仓库:所有优化已合并至 ClickHouse 主分支
-
演讲资料:2025 年上海开发者 Meetup 分享幻灯片
-
Pull Requests:文中所有优化均附带具体 PR 链接与性能分析报告
-
Intel 指令内联指南:[Intel® Intrinsics Guide](https://www.intel.com/content/www/us/en/docs/intrinsics-guide/) —— 用于理解底层 SIMD 指令的语义与组合策略
致谢
衷心感谢 ClickHouse 社区在优化过程中的代码审查与性能回归测试支持。这些成果来自 Intel 和 ClickHouse 两个团队跨组织、跨角色的深入协作,共同推动了分析型数据库在超高并发架构下的性能极限。
如果你想深入了解某个优化细节、或尝试复现实验数据,请查阅文中相关 PR 讨论页,我们在社区中也乐于继续探讨更多底层优化话题。
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com


















 818
818

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









