





本文字数:12066;估计阅读时间:31 分钟
作者:Misha Shiryaev
本文在公众号【ClickHouseInc】首发

问题背景
我们的 CI 系统在捕捉 Bug 方面表现优秀,尤其擅长在 AST Fuzzing、Stress(压力)测试和功能测试阶段捕获崩溃日志。但这些崩溃报告往往高度相似,导致我们难以区分哪些是全新的问题,哪些是重复的、已知的错误。
正如论文《TraceSim: A Method for Calculating Stack Trace Similarity》中所指出:
许多现代软件系统都配备了自动崩溃报告子系统。然而,同一个 Bug 常常会生成略有差异的报告。
该论文的方法论基于以下假设:结构相似的堆栈跟踪往往来源于相同的 Bug。作者提出了一种用于计算堆栈信息相似度的方法,可将相似的崩溃日志聚类归组。
我们最早的堆栈聚类系统由基础设施工程师 Michael Stetsyuk 构建,用于分析来自 ClickHouse Cloud 的崩溃日志。该系统通过堆栈信息对崩溃报告进行聚类,并在 issue 跟踪系统中进行统一管理。
基于上述经验,我们希望在 ClickHouse 之上构建一套用于分析 CI 崩溃日志的堆栈相似度系统,具备以下核心功能:
-
解析崩溃日志,提取堆栈帧;
-
计算堆栈信息之间的相似度;
-
自动将新日志与已知堆栈进行聚类归组;
-
在 GitHub 上创建或更新 issue,以便进行 Bug 追踪。
下面我将逐步介绍系统的实现过程,供你根据自身需求搭建类似的解决方案。
实现方式
系统的整体架构如下所示:
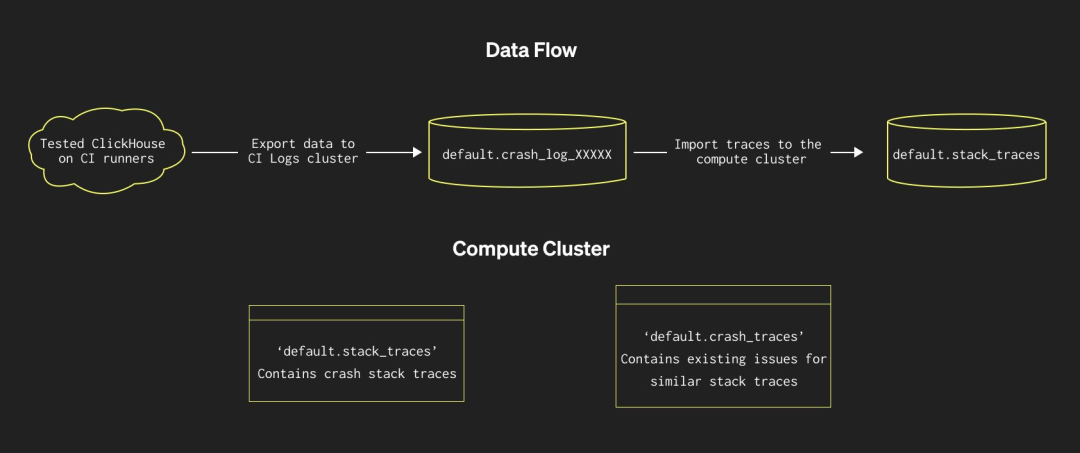
准备阶段:采集崩溃日志并初始化表结构
首先,需要从 CI 系统中收集崩溃报告。幸运的是,这一系统已稳定运行多年,具备良好的数据基础。
系统通过创建物化视图,将新日志自动写入远程 ClickHouse 集群中的目标表。目标表名根据当前表结构及附加列动态生成,使我们能够在表结构不完全一致的情况下,保留完整的历史数据,并实现跨 CI 任务共享同一张逻辑表。相关管理脚本位于项目的 ci 目录下。
数据主要来源于 system.crash_log 表,以下是当前 CI Logs 集群中部分表结构:
SHOW TABLES LIKE 'crash_log_%';
┌─name───────────────────────────┐
1. │ crash_log_12587237819650651296 │
2. │ crash_log_12670418084883306529 │
3. │ crash_log_1527066305010279420 │
4. │ crash_log_15355897847728332522 │
5. │ crash_log_15557244372725679386 │
6. │ crash_log_18405985218782237968 │
7. │ crash_log_2288102012038531617 │
8. │ crash_log_3310266143589491008 │
9. │ crash_log_6802555697904881735 │
10. │ crash_log_9016585404038675675 │
11. │ crash_log_9097266775814416937 │
12. │ crash_log_9243005856023138905 │
13. │ crash_log_9768092148702997133 │
14. │ crash_logs │
└────────────────────────────────┘
SHOW CREATE TABLE crash_logs;
CREATE TABLE default.crash_logs
(
`repo` String,
`pull_request_number` UInt32,
`commit_sha` String,
`check_start_time` DateTime,
`check_name` String,
`instance_type` String,
`instance_id` String,
`hostname` LowCardinality(String),
`event_date` Date,
`event_time` DateTime,
`timestamp_ns` UInt64,
`signal` Int32,
`thread_id` UInt64,
`query_id` String,
`trace` Array(UInt64),
`trace_full` Array(String),
`version` String,
`revision` UInt32,
`build_id` String
)
ENGINE = Merge('default', '^crash_log_')
示例:存储于该表中的原始崩溃数据:
SELECT *
FROM crash_logs
WHERE event_date = today()
LIMIT 1
Row 1:
──────
repo: ClickHouse/ClickHouse
pull_request_number: 85843
commit_sha: 41215391373ad2e277230939e887c834edeb16ce
check_start_time: 2025-08-19 10:07:50
check_name: Stateless tests (arm_binary, parallel)
instance_type: c8g.8xlarge
instance_id: i-0b53d7dc362ab4cd8
hostname: 16ffef362c03
event_date: 2025-08-19
event_time: 2025-08-19 10:09:04
timestamp_ns: 1755598144624168055
signal: 6
thread_id: 6359
query_id: 5ce98be8-f4cb-4950-82a8-cc2720669cad
trace: [280796479681009,280796479399548,280796479320368,188029769003464,188029769005984,188029769006680,188029679339096,188029679337384,188029679380404,188029836833040,188029837238400,188029837230992,188029837232044,188029915248680,188029915247868,188029915340828,188029915297288,188029915294080,188029915293160,…]
trace_full: ['3. ? @ 0x000000000007f1f1','4. ? @ 0x000000000003a67c','5. ? @ 0x0000000000027130','6. ./ci/tmp/build/./src/Common/Exception.cpp:51: DB::abortOnFailedAssertion(String const&, void* const*, unsigned long, unsigned long) @ 0x000000000e33b1c8','7. ./ci/tmp/build/./src/Common/Exception.cpp:84: DB::handle_error_code(String const&, std::basic_string_view>, int, bool, std::vector> const&) @ 0x000000000e33bba0','8. ./ci/tmp/build/./src/Common/Exception.cpp:135: DB::Exception::Exception(DB::Exception::MessageMasked&&, int, bool) @ 0x000000000e33be58','9. DB::Exception::Exception(String&&, int, String, bool) @ 0x0000000008db8658','10. DB::Exception::Exception(PreformattedMessage&&, int) @ 0x0000000008db7fa8','11. DB::Exception::Exception<>(int, FormatStringHelperImpl<>) @ 0x0000000008dc27b4','12. ./ci/tmp/build/./src/Storages/ObjectStorage/StorageObjectStorageConfiguration.cpp:212: DB::StorageObjectStorageConfiguration::addDeleteTransformers(std::shared_ptr, DB::QueryPipelineBuilder&, std::optional const&, std::shared_ptr) const @ 0x00000000123eb110','13. ./ci/tmp/build/./src/Storages/ObjectStorage/StorageObjectStorageSource.cpp:555: DB::StorageObjectStorageSource::createReader(unsigned long, std::shared_ptr const&, std::shared_ptr const&, std::shared_ptr const&, DB::ReadFromFormatInfo&, std::optional const&, std::shared_ptr const&, DB::SchemaCache*, std::shared_ptr const&, unsigned long, std::shared_ptr, std::shared_ptr, bool) @ 0x000000001244e080','14.0. inlined from ./ci/tmp/build/./src/Storages/ObjectStorage/StorageObjectStorageSource.cpp:412: DB::StorageObjectStorageSource::createReader()','14. ./ci/tmp/build/./src/Storages/ObjectStorage/StorageObjectStorageSource.cpp:265: DB::StorageObjectStorageSource::lazyInitialize() @ 0x000000001244c390','15. ./ci/tmp/build/./src/Storages/ObjectStorage/StorageObjectStorageSource.cpp:274: DB::StorageObjectStorageSource::generate() @ 0x000000001244c7ac','16. ./ci/tmp/build/./src/Processors/ISource.cpp:144: DB::ISource::tryGenerate() @ 0x0000000016eb3828','17. ./ci/tmp/build/./src/Processors/ISource.cpp:110: DB::ISource::work() @ 0x0000000016eb34fc','18.0. inlined from ./ci/tmp/build/./src/Processors/Executors/ExecutionThreadContext.cpp:53: DB::executeJob(DB::ExecutingGraph::Node*, DB::ReadProgressCallback*)','18. ./ci/tmp/build/./src/Processors/Executors/ExecutionThreadContext.cpp:102: DB::ExecutionThreadContext::executeTask() @ 0x0000000016eca01c','19. ./ci/tmp/build/./src/Processors/Executors/PipelineExecutor.cpp:350: DB::PipelineExecutor::executeStepImpl(unsigned long, DB::IAcquiredSlot*, std::atomic*) @ 0x0000000016ebf608',…]
version: ClickHouse 25.8.1.1
revision: 54501
build_id: 88351121A8340C83AB8A60BA97765ADC4B9B7786
至此,我们已成功获取可用于分析的原始堆栈日志。
采集与分析分离:构建分析专用集群与表结构
为避免影响 CI 系统本身的运行性能,我们将日志分析任务部署于一个独立的 ClickHouse 集群中。通过定义相关表结构及物化视图,实现从 CI Logs 集群定时同步数据至本地分析集群。
-- Create a table to store the raw stack traces with details about where and when they were appeared
CREATE TABLE default.stack_traces
(
`repo` LowCardinality(String),
`pull_request_number` UInt32,
`commit_sha` String,
`check_name` String,
`check_start_time` DateTime('UTC'),
`event_time` DateTime,
`timestamp_ns` UInt64,
`trace_full` Array(String),
`Version` UInt32 DEFAULT now()
)
ENGINE = ReplacingMergeTree(Version)
PARTITION BY toYYYYMM(event_time)
ORDER BY (event_time, timestamp_ns, repo, check_start_time)
SETTINGS index_granularity = 8192;
-- create a refresheable materialized view to collect the data from the crash_logs table for the last 100 days
-- https://clickhouse.com/docs/materialized-view/refreshable-materialized-view
CREATE MATERIALIZED VIEW default._stack_traces_mv
REFRESH EVERY 30 MINUTE TO default.stack_traces
AS SELECT
repo,
pull_request_number,
commit_sha,
check_name,
check_start_time,
event_time,
timestamp_ns,
trace_full,
now() AS Version
FROM remoteSecure('[HOST]', 'default', 'crash_logs', 'username', 'password')
WHERE event_date >= today() - INTERVAL 100 DAY;
-- Create a table to store the info about the GitHub issues created for the stack traces
CREATE TABLE default.crash_issues
(
`created_at` DateTime,
`updated_at` DateTime,
`closed_at` DateTime,
`repo` String,
`number` UInt32,
`state` Enum8('open' = 1, 'closed' = 2),
`stack_traces_full` Array(Array(String)),
`stack_traces_hash` Array(UInt64)
)
ENGINE = ReplacingMergeTree(updated_at)
PARTITION BY toYYYYMM(created_at)
ORDER BY (repo, number)
SETTINGS index_granularity = 8192;
从这一步开始,所有分析工作均基于分析集群进行。数据每隔 30 分钟刷新一次,确保我们始终处理的是最新的崩溃事件。
步骤一:清洗堆栈日志
原始堆栈日志通常包含大量无关信息,这些“噪声”会干扰堆栈相似度的准确计算,常见来源包括:
-
编译器版本差异;
-
构建类型差异(Debug 与 Release);
-
操作系统或硬件平台差异;
-
堆栈中的文件路径与源码行号信息。
为此,我们定义了两个用户自定义函数(UDF):
CREATE FUNCTION cleanStackFrame AS frame -> replaceRegexpOne(
replaceRegexpAll(
splitByString(
-- second, strip the file name and line number, keep the function name
': ', splitByString(
-- first, strip the frame address, keep the frame number, file name, line number, and function name
' @ ', frame, 2
)[1], 2
)[2],
-- third, replace all ABI specific information with a placeholder
'\\[abi:[^]]+\\]', '[$ABI]'),
-- finally, delete all LLVM specific information
'(\\s+[(])*[.]llvm[.].+', ''
);
CREATE FUNCTION cleanStackTrace AS trace -> arrayFilter(
frame -> (
-- second, keep only meaningful frames
frame NOT IN ('', '?')), arrayMap(
-- first, clean each frame of the stack trace
fr -> cleanStackFrame(fr), trace
)
);
-
cleanStackFrame:清洗单个堆栈帧,剔除无关上下文;
-
cleanStackTrace:对整个堆栈进行标准化处理,调用前者作用于每一帧。
这些函数在执行相似度计算前以“按需清洗”的方式动态调用,而不是将清洗结果事先写入数据库。该策略为后续迭代优化提供了更大灵活性,使我们能够在不重新处理所有历史数据的前提下,动态调整清洗逻辑与权重计算规则。
步骤二:堆栈分组与重要性判定
在完成堆栈清洗后,即可开始分析处理。系统会将已处理的堆栈信息存储在 crash_issues 表中,用于比对和识别现有的 issue。
WITH known_hashes AS
(
SELECT
repo,
-- Avoid default value of 'open' for state
toString(state) AS state,
updated_at,
closed_at,
arrayFlatten(groupArrayDistinct(stack_traces_hash)) AS known_hashes
FROM default.crash_issues FINAL
GROUP BY ALL
)
SELECT
repo,
groupArrayDistinct((pull_request_number, commit_sha, check_name)) AS checks,
cleanStackTrace(trace_full) AS trace_full,
sipHash64(trace_full) AS trace_hash,
length(groupArrayDistinct(pull_request_number) AS PRs) AS trace_count,
has(PRs, 0) AS is_in_master
FROM default.stack_traces AS st
LEFT JOIN known_hashes AS kh ON (st.repo = kh.repo AND has(kh.known_hashes, trace_hash))
WHERE (st.event_time >= (now() - toIntervalDay(30)))
AND (length(trace_full) > 5)
GROUP BY
repo,
trace_full
HAVING
groupArrayDistinct(kh.state) = [''] -- new trace, no issues
OR (groupArrayDistinct(kh.state) = ['closed'] AND max(st.check_start_time) > max(kh.closed_at)) -- new event after the issue is closed
ORDER BY max(st.event_time)
查询脚本会基于清洗后的堆栈内容进行分组,并为每条堆栈计算哈希值,然后与 crash_issues 表比对,判断该堆栈是否已存在。如果发现该堆栈对应的 issue 处于打开状态,或该堆栈生成时间早于已有 issue 被关闭的时间,则将其视为已知堆栈。
此外,查询还会统计包含该堆栈的唯一 Pull Request 数量,并检查该堆栈是否出现于 master 分支(Pull Request 编号 0)。若某堆栈仅出现在少于三个 Pull Request 中,且未出现在 master/release 分支中,则被视为不重要。此类堆栈不会触发新 issue 的创建,但若其与已知堆栈相似度足够高,则会附加到已有 issue 中。
步骤三:堆栈相似度计算
第二步得到的新堆栈列表,需要逐一与已知堆栈(已关联 GitHub issue)进行相似度比对。
以下查询实现了 TraceSim 论文中的相似度计算方法。ClickHouse 自 25.4 版本起提供了 arraySimilarity 函数,并可在查询时动态计算权重,其中 new_trace 表示第二步中的某条新堆栈。
WITH
1.97 AS alpha,
2.0 AS beta,
3.7 AS gamma,
0.68 AS threshold,
stack_frame_weights AS (
WITH
(
SELECT count()
FROM default.stack_traces
FINAL
) AS total
SELECT
arrayJoin(cleanStackTrace(trace_full)) AS frame,
countDistinct(trace_full) AS count,
log(total / count) AS IDF,
sigmoid(beta * (IDF - gamma)) AS weight
FROM default.stack_traces
FINAL
GROUP BY frame
),
(SELECT groupArray(weight) AS w, groupArray(frame) AS f FROM stack_frame_weights) AS weights,
(trace -> arrayMap((_frame, pos) -> (pow(pos, -alpha) * arrayFirst(w, f -> (f = _frame), weights.w, weights.f)), trace, arrayEnumerate(trace))) AS get_trace_weights,
-- one of the new traces from step two
['DB::abortOnFailedAssertion(String const&, void* const*, unsigned long, unsigned long)','DB::handle_error_code(String const&, std::basic_string_view>, int, bool, std::vector> const&)','DB::Exception::Exception(DB::Exception::MessageMasked&&, int, bool)','DB::Exception::Exception(int, FormatStringHelperImpl::type, std::type_identity::type, std::type_identity::type>, String const&, String&&, String const&)','DB::paranoidCheckForCoveredPartsInZooKeeper(std::shared_ptr const&, String const&, StrongTypedef, String const&, DB::StorageReplicatedMergeTree const&)','DB::StorageReplicatedMergeTree::executeDropRange(DB::ReplicatedMergeTreeLogEntry const&)','DB::StorageReplicatedMergeTree::executeLogEntry(DB::ReplicatedMergeTreeLogEntry&)','operator()','decltype(std::declval)::$_1&>()(std::declval&>())) std::__invoke[$ABI])::$_1&, std::shared_ptr&>(DB::StorageReplicatedMergeTree::processQueueEntry(std::shared_ptr)::$_1&, std::shared_ptr&)','bool std::__invoke_void_return_wrapper::__call[$ABI])::$_1&, std::shared_ptr&>(DB::StorageReplicatedMergeTree::processQueueEntry(std::shared_ptr)::$_1&, std::shared_ptr&)','DB::ReplicatedMergeTreeQueue::processEntry(std::function ()>, std::shared_ptr&, std::function&)>)','DB::StorageReplicatedMergeTree::processQueueEntry(std::shared_ptr)','DB::ExecutableLambdaAdapter::executeStep()','DB::MergeTreeBackgroundExecutor::routine(std::shared_ptr)','DB::MergeTreeBackgroundExecutor::threadFunction()'] AS new_trace,
get_trace_weights(new_trace) AS new_trace_weights
SELECT
arraySimilarity(
new_trace,
arrayJoin(stack_traces_full) AS trace_full,
new_trace_weights,
get_trace_weights(trace_full)
) AS similarity,
repo,
number,
created_at,
closed_at,
stack_traces_full,
stack_traces_hash
FROM default.crash_issues FINAL
WHERE repo = 'ClickHouse/ClickHouse'
AND state = 'open'
AND threshold <= similarity
系统会按小时收集并处理重要堆栈,以便及时分析。如果某条新的重要堆栈未匹配到相似堆栈,将在 GitHub 仓库中自动创建新的 issue,并将该堆栈写入 crash_issues 表。
每天系统还会统一处理所有堆栈(包括不重要堆栈),以判断其是否与已知的重要堆栈相似。当某条堆栈与重要堆栈的相似度超过阈值时,会自动将其添加到对应的 issue。
我们还利用大语言模型(LLM)辅助生成 issue 标题,并基于堆栈内容推测可能的崩溃原因。
最终结果
所有自动创建的 issue 都集中在 GitHub 仓库中带有 crash-ci 标签的列表内。如果你发现可修复的问题,欢迎直接在仓库中贡献修复方案。
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com



















 1186
1186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









