





本文字数:10085;估计阅读时间:26 分钟
作者:ClickHouse Team
本文在公众号【ClickHouseInc】首发

时间来到新的一月,我们迎来了 ClickHouse 的全新版本!
发布概要
ClickHouse 25.9 版本共带来了 25 项新功能 🍎、 22 项性能优化 🍁、 以及 83 个bug修复 🌿。
本次版本更新引入了自动全局 Join 重排序、二级索引的流式处理、新的文本索引等多项重磅改进!
新贡献者
热烈欢迎在 25.9 版本中首次贡献代码的开发者!ClickHouse 社区的不断壮大令人振奋,正是因为有了众多贡献者的支持,ClickHouse 才能成为今天这样备受欢迎的项目。
以下是所有新加入的贡献者名单:
Aly Kafoury, Christian Endres, Dmitry Prokofyev, Kaviraj, Max Justus Spransy, Mikhail Kuzmin, Sergio de Cristofaro, Shruti Jain, c-end, dakang, jskong1124, polako, rajatmohan22, restrry, shruti-jain11, somrat.dutta, travis, yanglongwei
Join 重排序
由 Vladimir Cherkasov 贡献
许多用户期盼已久的功能终于在本版本实现:自动全局 Join 重排序。
ClickHouse 现在能够自动优化包含数十张表的复杂连接结构,支持包括 Inner、Left/Right Outer、Cross、Semi 和 Anti 等主流 Join 类型。之所以能够实现这一优化,是因为多个表之间的连接操作具备结合性(associativity)。
Join 顺序为什么重要
以三个表为例,数据库可能会先将 A 和 B Join,再将结果与 C 连接:
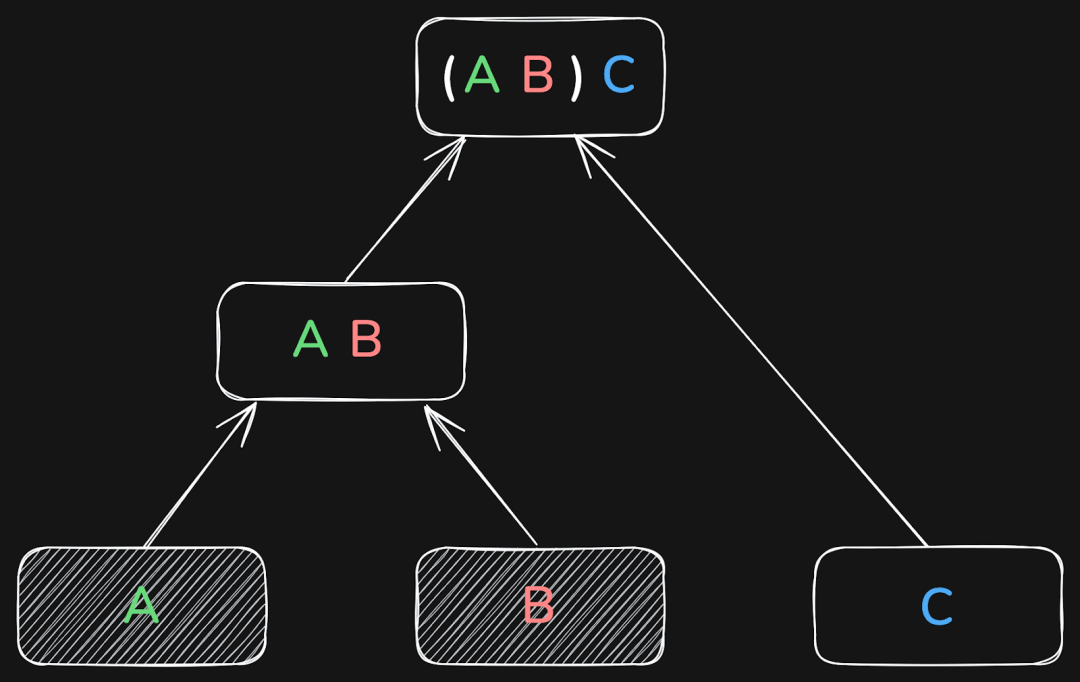
也可以先将 B 和 C Join,再将结果与 A 连接:
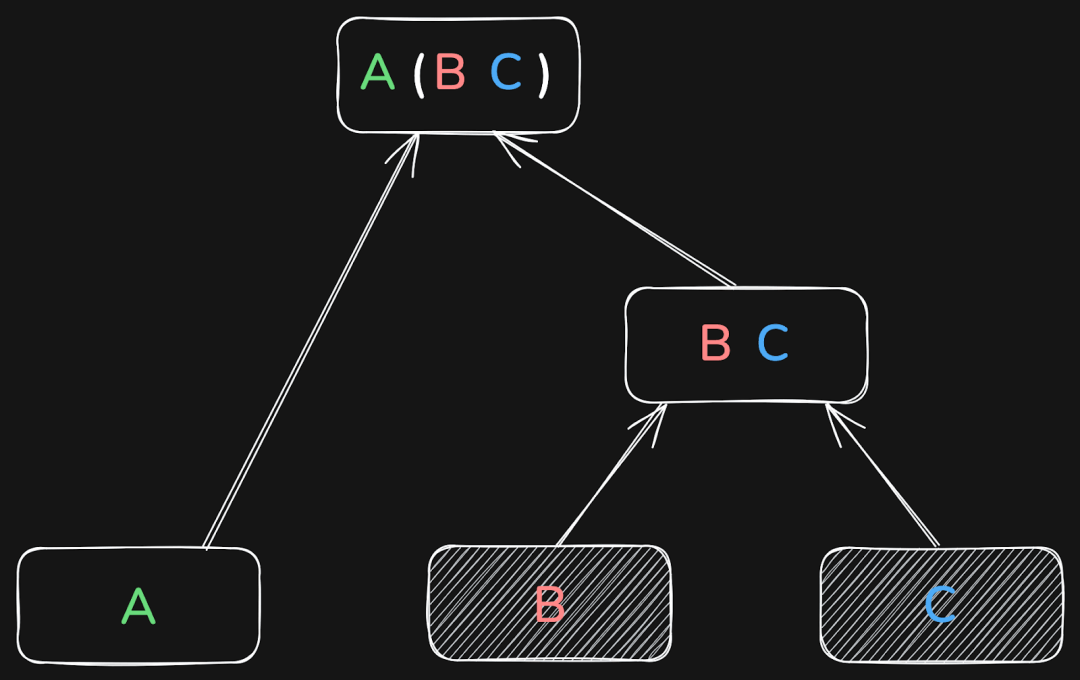
或者是先将 A 和 C Join,再将结果与 B 连接:
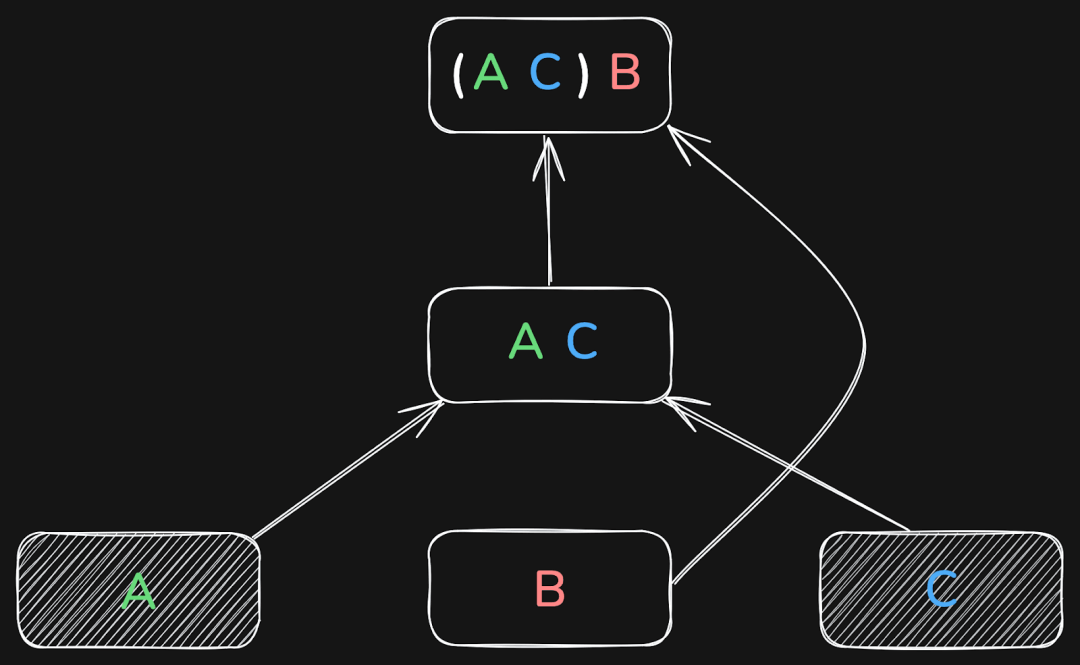
这三种方式最终都会得到相同的结果。
但随着 Join 表数量的增加,全局 Join 顺序的影响也会越来越大。
在某些场景下,合理与不合理的 Join 顺序,其查询性能可能相差几个数量级!
那么 Join 顺序为何会如此重要?我们先来简单回顾一下 ClickHouse 的 Join 执行方式。
ClickHouse 的 Join 执行机制
简要回顾一下:ClickHouse 当前最快的 Join 算法是默认启用的并行哈希连接(parallel hash join),其执行过程分为两个阶段:
-
构建阶段(Build phase):将右侧的表加载进内存哈希表中。
-
探测阶段(Probe phase):对左侧表进行流式扫描,并查找哈希表中的匹配项。
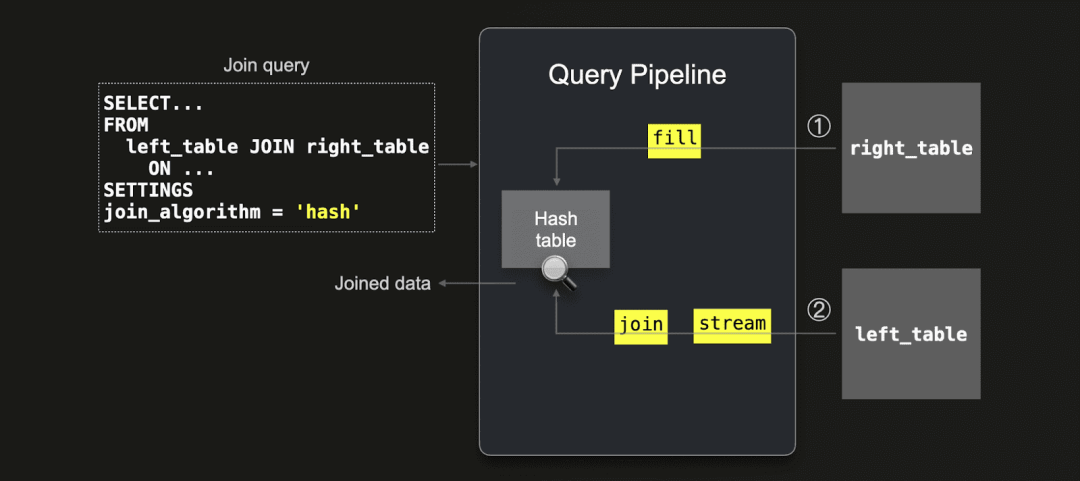
图 3: 25.9 版本中的 Join 执行流程示意图
由于右侧表会预加载进内存,因此在大多数情况下,将较小的表放在右侧能显著提升执行效率。
其他 Join 算法,如使用外部排序的部分合并 Join(partial merge join),也遵循类似的构建与探测机制。在这些算法中,同样推荐将小表放在构建端,以加快查询速度。
局部 Join 重排序功能
ClickHouse 在 24.12 版本首次引入了针对两个表的自动局部 Join 重排序功能。该优化会自动将两个表中较小的那个放置在右侧,即哈希表的构建端(build side),从而显著减少构建哈希表所需的内存和计算资源。
全局 Join 重排序功能
到了 25.9 版本,ClickHouse 进一步引入了全局 Join 重排序功能,在查询优化阶段能够自动决定多个表之间更优的连接顺序(构建端 vs 探测端)。
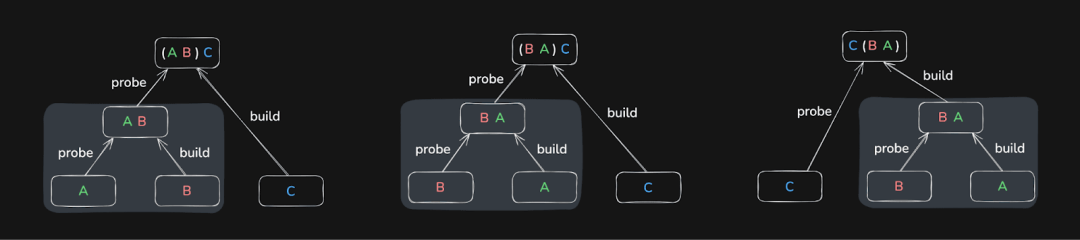
图 4: 多表连接下的全局 Join 重排序示意图
相比局部重排序,全局 Join 优化要复杂得多。随着连接表数量的增加,可能的连接顺序呈指数增长,因此 ClickHouse 无法对整个搜索空间进行穷举搜索。为了解决这一问题,系统采用了一种贪婪(greedy)优化算法,在保证效果的前提下快速收敛到一个性能足够优的连接顺序。
实现该算法的关键,是对 Join 列进行基数估算,也就是评估两个被连接表在执行时可能涉及的行数(考虑 WHERE 条件的影响)。ClickHouse 会结合存储引擎返回的行数估算和用户手动配置的列统计信息来完成这项任务。
当前版本下,列统计信息仍需手动创建(参考下方示例)。我们计划在未来版本中支持为新建表自动生成统计信息,以提升优化效果。
如何控制 Join 重排序
你可以通过以下两个参数设置来控制全局 Join 重排序行为:
-
query_plan_optimize_join_order_limit:指定最大允许重排序的 Join 表数量;
-
allow_statistics_optimize:是否允许使用列统计信息进行 Join 优化。
基准测试:TPC-H 查询表现
下面我们使用经典的 TPC-H Join 基准测试,验证全局 Join 重排序结合列统计信息后的性能表现。
我们在 AWS EC2 m6i.8xlarge 实例(32 核 vCPU、128 GiB 内存)上,分别创建了两个版本的 TPC-H 数据模型(scale factor 为 100):
-
无统计信息版本:使用默认 DDL 创建的 8 个 TPC-H 表;
-
有统计信息版本:在上述表的基础上添加了列级统计信息。
建表后,我们使用提供的脚本命令加载数据。
如果你也想尝试体验,链接中包含了建表和加载的全部命令。
CREATE DATABASE tpch_no_stats;
USE tpch_no_stats;
-- Create the 8 tables with the default DDL
-- Load data
CREATE DATABASE tpch_stats;
USE tpch_stats;
-- Create the 8 tables with extended DDL (with column statistics)
-- Load data
我们选用了一条包含 6 张表 Join 的 TPC-H 查询作为测试用例:
SELECT
n_name,
sum(l_extendedprice * (1 - l_discount)) AS revenue
FROM
customer,
orders,
lineitem,
supplier,
nation,
region
WHERE
c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND l_suppkey = s_suppkey
AND c_nationkey = s_nationkey
AND s_nationkey = n_nationkey
AND n_regionkey = r_regionkey
AND r_name = 'ASIA'
AND o_orderdate >= DATE '1994-01-01'
AND o_orderdate < DATE '1994-01-01' + INTERVAL '1' year
GROUP BY
n_name
ORDER BY
revenue DESC;
首先,在未启用列统计信息的表上执行查询:
USE tpch_no_stats;
SET query_plan_optimize_join_order_limit = 10;
SET allow_statistics_optimize = 1;
-- test_query
┌─n_name────┬─────────revenue─┐
1. │ VIETNAM │ 5310749966.867 │
2. │ INDIA │ 5296094837.7503 │
3. │ JAPAN │ 5282184528.8254 │
4. │ CHINA │ 5270934901.5602 │
5. │ INDONESIA │ 5270340980.4608 │
└───────────┴─────────────────┘
5 rows in set. Elapsed: 3903.678 sec. Processed 766.04 million rows, 16.03 GB (196.23 thousand rows/s., 4.11 MB/s.)
Peak memory usage: 99.12 GiB.
查询耗时超过一小时 🐌,并消耗了 99 GiB 主内存。
然后我们在启用统计信息的表上运行相同的查询:
USE tpch_stats;
SET query_plan_optimize_join_order_limit = 10;
SET allow_statistics_optimize = 1;
-- test_query
Query id: 5c1db564-86d0-46c6-9bbd-e5559ccb0355
┌─n_name────┬─────────revenue─┐
1. │ VIETNAM │ 5310749966.867 │
2. │ INDIA │ 5296094837.7503 │
3. │ JAPAN │ 5282184528.8254 │
4. │ CHINA │ 5270934901.5602 │
5. │ INDONESIA │ 5270340980.4608 │
└───────────┴─────────────────┘
5 rows in set. Elapsed: 2.702 sec. Processed 638.85 million rows, 14.76 GB (236.44 million rows/s., 5.46 GB/s.)
Peak memory usage: 3.94 GiB.
仅耗时 2.7 秒,性能提升约 1,450 倍,同时内存使用降低至原来的约 1/25。
Join 重排序:接下来的发展方向
目前的全局 Join 重排序功能只是 ClickHouse 迈出的第一步。当前版本仍依赖手动创建统计信息,未来的演进方向包括:
-
自动生成列统计信息 —— 摆脱手动配置的限制;
-
支持更多 Join 类型,例如外连接,以及对子查询的 Join;
-
引入更强的 Join 重排序算法 —— 能够应对更复杂、更大型的连接图场景。
更多精彩功能,敬请关注后续版本!
二级索引流式处理功能
由 Amos Bird 贡献
在 ClickHouse 25.9 版本之前,所有二级索引(如 minmax、set、布隆过滤器、向量索引、文本索引)都是在读取底层数据前先进行评估。
旧机制:顺序索引扫描
执行流程如下:
-
索引预扫描阶段:ClickHouse 会预先扫描所有二级索引条目,以判断哪些 granule(ClickHouse 中的最小处理单元,通常覆盖 8,192 行)可能包含匹配 WHERE 条件的记录。
-
查询执行阶段:系统将筛选出的 granule 传入查询引擎并进行处理,生成最终查询结果。
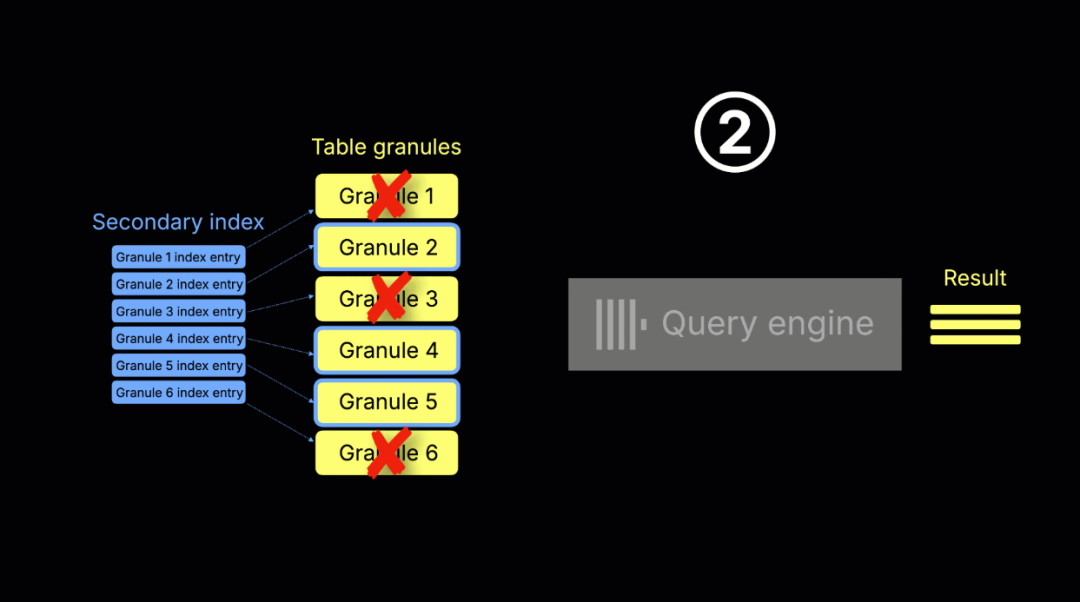
上图展示了上述流程:
① 索引扫描与 granule 选择:系统评估所有索引条目,仅选择可能命中的 granule,其余直接跳过。
② 查询执行:选中的 granule 被读取并处理,结果返回客户端。
尽管这种流程清晰有序,但也存在一些明显局限:
-
LIMIT 效率低:即使查询很快因 LIMIT 停止,ClickHouse 仍需提前扫描全部索引;
-
执行延迟高:索引分析在查询执行前发生,增加整体响应延迟;
-
扫描开销大:尤其在大表上执行高选择性过滤条件时,索引扫描本身的开销可能高于处理实际数据。
新机制:流式二级索引
ClickHouse 25.9 引入全新机制,将索引判断和数据读取交错进行,实现真正的流式处理方式。如下图所示:
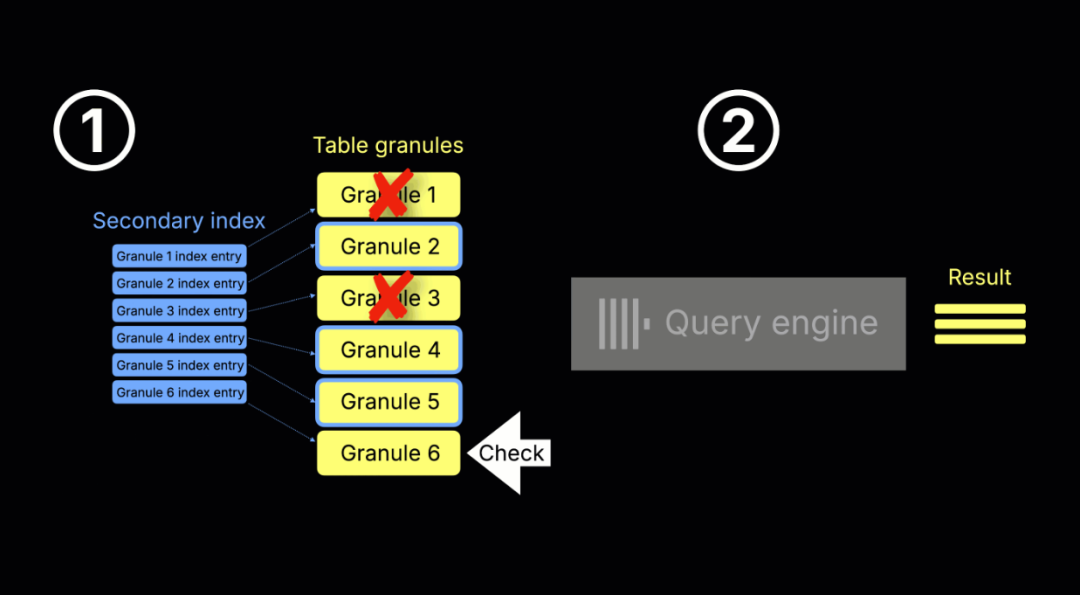
上图展示了新流程:
① 索引扫描与 granule 选择
② 查询执行(两者并发进行):
当 ClickHouse 准备读取某个 granule(通常已被主索引选中)时,会先检查对应的二级索引(如果存在)。
-
如果索引判定该 granule 可跳过,则不会读取;
-
否则,该 granule 会被加载并由查询引擎处理。
与此同时,系统继续评估下一批 granule,以流式方式持续推进查询。
这种并发双流机制 —— 一边读取数据 granule,一边检查其对应的二级索引 —— 被称为“流式二级索引”,由设置项 use_skip_indexes_on_data_read 控制启用。
(注:为便于展示,动画使用单线程引擎演示,实际执行中,ClickHouse 会使用多线程并发处理多个 granule。)
这一改进显著减少了等待时间和资源浪费。例如,当查询因为 LIMIT 条件提前终止时,系统能立即停止后续 granule 的索引判断与数据读取,有效提升整体执行效率。
演示:流式二级索引带来更快的查询性能
在此次版本发布的网络研讨会中,Alexey 向大家展示了流式二级索引在超大规模 ClickHouse 表中的性能优势。示例数据包含了数万亿条日志记录,来源于对 Pull Request 和 Commit 执行测试时产生的运行数据。在这些数据集中,单个二级索引压缩后体积甚至超过 6 TB。
考虑到在本地环境中难以还原如此大规模的场景,我们使用了一个简化的人工示例,方便用户自行复现。
我们在 AWS EC2 m6i.8xlarge 实例(32 核 vCPU,128 GiB 内存)上进行测试。
首先,创建一张表,包含一个 String 类型的字段,并在该列上添加了一个 Bloom Filter 索引:
CREATE TABLE test (
s String,
index s_idx s type bloom_filter(0.0001) granularity 1
)
ENGINE = MergeTree
ORDER BY ()
SETTINGS index_granularity = 1024;
随后向该表插入 10 亿行记录:
INSERT INTO test
SELECT if(number % 1024 == 0, 'needle', randomPrintableASCII(64))
FROM numbers_mt(1_000_000_000);
此时可以看到,Bloom Filter 索引的大小已超过 2 GiB:
SELECT
name,
type_full,
formatReadableSize(data_uncompressed_bytes) AS size
FROM system.data_skipping_indices
WHERE database = 'default' AND table = 'test';
┌─name──┬─type_full────────────┬─size─────┐
1. │ s_idx │ bloom_filter(0.0001) │ 2.21 GiB │
└───────┴──────────────────────┴──────────┘
为确保测试公平性,我们在每次查询前都清空了操作系统的页缓存(OS page cache)。
echo 3 | sudo tee /proc/sys/vm/drop_caches >/dev/null
在关闭流式索引功能(设置 use_skip_indexes_on_data_read = 0)的情况下,执行一个通过 LIMIT 1 筛选单条记录的查询,耗时约为 10 秒。
为了排除其他干扰变量,我们将 max_threads 设置为 1,并禁用了查询条件缓存(query condition cache),以最大化体现二级索引处理带来的差异。
SELECT * FROM test WHERE s = 'needle' LIMIT 1
SETTINGS
max_threads = 1,
use_query_condition_cache = 0, use_skip_indexes_on_data_read = 0;
┌─s──────┐
1. │ needle │
└────────┘
1 row in set. Elapsed: 10.173 sec. Processed 29.70 thousand rows, 2.14 MB (2.92 thousand rows/s., 210.00 KB/s.)
Peak memory usage: 8.90 MiB.
当启用流式索引(设置 use_skip_indexes_on_data_read = 1)后,执行相同的查询仅需约 2.4 秒 —— 性能提升超过 4 倍,且使用的内存也显著减少。
SELECT * FROM test WHERE s = 'needle' LIMIT 1
SETTINGS
max_threads = 1,
use_query_condition_cache = 0, use_skip_indexes_on_data_read = 1;
┌─s──────┐
1. │ needle │
└────────┘
1 row in set. Elapsed: 2.471 sec. Processed 29.70 thousand rows, 2.14 MB (12.02 thousand rows/s., 864.57 KB/s.)
Peak memory usage: 4.48 MiB.
这一性能提升主要来自以下两个机制的协同作用:
① 并发执行索引扫描与查询处理:启用流式索引后,ClickHouse 在扫描索引的同时即可处理匹配 granule,无需等待全部索引分析完成;
② 即时终止无效工作:一旦系统找到符合条件的首条记录(由于 LIMIT 1),就会立即停止对后续索引条目与 granule 的处理,最大限度避免资源浪费。
全新文本索引功能
由 Anton Popov、Elmi Ahmadov 和 Jimmy Aguilar Mena 贡献
自从我们在 2025 年 8 月发布《重构全文搜索》的博客文章后(https://clickhouse.com/blog/clickhouse-full-text-search),经过持续测试,我们对全文索引的理解有了更进一步的提升。很多我们原本认为已定型的设计方案,最终被证明只是通往更优架构的中间步骤。持续演进、大胆试验、快速反馈,是 ClickHouse 一贯的研发哲学:我们愿意早期发布原型、进行严谨测试,并不断打磨优化,直到真正打造出最快的解决方案。
此前基于 FST(有限状态转换器)的实现虽然在存储空间方面表现良好,但在执行效率上存在不足:它需要将大批量数据加载到内存中,且其数据组织方式未针对“跳过索引 granule”优化,导致查询分析较为低效。
在 ClickHouse 25.9 中,我们推出了全新的实验性文本索引,它支持流式处理,并以 granule 为单位组织数据结构,与跳过索引机制高度契合,从而带来更高效、更稳定的全文搜索体验。
启用该文本索引功能需配置以下参数:
SET allow_experimental_full_text_index;
我们将以 Hacker News 的公开数据集作为示例进行演示。首先可使用以下命令下载 CSV 文件:
wget https://datasets-documentation.s3.eu-west-3.amazonaws.com/hackernews/hacknernews.csv.gz
随后创建一张包含文本索引的表,并将索引应用于 text 字段:
CREATE TABLE hackernews
(
`id` Int64,
`deleted` Int64,
`type` String,
`by` String,
`time` DateTime64(9),
`text` String,
`dead` Int64,
`parent` Int64,
`poll` Int64,
`kids` Array(Int64),
`url` String,
`score` Int64,
`title` String,
`parts` Array(Int64),
`descendants` Int64,
INDEX inv_idx(text)
TYPE text(tokenizer = 'default')
GRANULARITY 128
)
ENGINE = MergeTree
ORDER BY time;
完成表结构后,导入数据:
INSERT INTO hackernews
SELECT *
FROM file('hacknernews.csv.gz', CSVWithNames);
可以通过以下语句检查当前记录数:
SELECT count()
FROM hackernews;
┌──count()─┐
│ 28737557 │ -- 28.74 million
└──────────┘
数据量接近 3,000 万条,适合用于测试查询性能。
我们接下来展示如何对 text 列执行搜索。hasToken 函数在检测到文本索引时会自动使用它进行加速;而 searchAll 与 searchAny 函数则要求字段必须建立文本索引才能使用。
如果我们希望查找发布关于 “OpenAI” 相关内容最多的用户,可以使用如下查询语句:
select by, count()
FROM hackernews
WHERE hasToken(text, 'OpenAI')
GROUP BY ALL
ORDER BY count() DESC
LIMIT 10;
┌─by──────────────┬─count()─┐
│ minimaxir │ 48 │
│ sillysaurusx │ 43 │
│ gdb │ 40 │
│ thejash │ 24 │
│ YeGoblynQueenne │ 23 │
│ nl │ 20 │
│ Voloskaya │ 19 │
│ p1esk │ 18 │
│ rvz │ 17 │
│ visarga │ 16 │
└─────────────────┴─────────┘
10 rows in set. Elapsed: 0.026 sec.
而如果在未启用文本索引的表上运行相同的查询,执行时间通常会延长约 10 倍。
10 rows in set. Elapsed: 1.545 sec. Processed 27.81 million rows, 9.47 GB (17.99 million rows/s., 6.13 GB/s.)
Peak memory usage: 172.15 MiB.
我们还可以进一步扩展条件,查找那些同时发布包含 “OpenAI” 和 “Google” 两个关键词的消息最多的用户,查询语句如下:
select by, count()
FROM hackernews
WHERE searchAll(text, ['OpenAI', 'Google'])
GROUP BY ALL
ORDER BY count() DESC
LIMIT 10;
┌─by──────────────┬─count()─┐
│ thejash │ 17 │
│ boulos │ 8 │
│ p1esk │ 6 │
│ sillysaurusx │ 5 │
│ colah3 │ 5 │
│ nl │ 5 │
│ rvz │ 4 │
│ Voloskaya │ 4 │
│ visarga │ 4 │
│ YeGoblynQueenne │ 4 │
└─────────────────┴─────────┘
10 rows in set. Elapsed: 0.012 sec.
数据湖改进
由 Konstantin Vedernikov、Smita Kulkarni 贡献
ClickHouse 25.9 对数据湖的支持进一步增强,包括:
-
支持 Apache Iceberg 的 ALTER UPDATE 和 DROP TABLE 子句;
-
新增系统表 iceberg_metadata_log;
-
支持 Apache Iceberg 数据文件格式 ORC 和 Avro;
-
支持 Azure 上的 Unity Catalog;
-
支持数据湖场景下的分布式 INSERT SELECT 操作。
arrayExcept
由 Joanna Hulboj 贡献
ClickHouse 25.9 引入了 arrayExcept 函数,用于计算两个数组之间的差集。如下所示是一个示例:
SELECT arrayExcept([1, 2, 3, 4], [1, 3, 5]) AS res;
┌─res───┐
│ [2,4] │
└───────┘
布尔类型设置
由 Thraeka 贡献
ClickHouse 25.9 还允许在定义布尔类型设置时省略参数。这意味着我们现在可以像下面这样使用更简洁的 DESCRIBE 输出:
SET describe_compact_output;
并且不再需要像 25.9 之前那样显式地指定为 true:
SET describe_compact_output = true;
如果要关闭某个设置,仍然需要将参数设置为 false。
支持指定 S3 存储类别
由 Alexander Sapin 贡献
在 ClickHouse 25.9 中,使用 S3 表引擎或表函数时,用户可以指定所使用的 AWS S3 存储类别(Storage Class)。
例如,如果希望 AWS 自动将数据迁移至最具性价比的访问层以降低存储成本,可以选择启用智能分层(Intelligent Tiering)。
CREATE TABLE test (s String)
ENGINE = S3('s3://mybucket/test.parquet',
storage_class_name = 'INTELLIGENT_TIERING');
INSERT INTO test VALUES ('Hello');
INSERT INTO FUNCTION s3('s3://mybucket/test.parquet',
storage_class_name = 'INTELLIGENT_TIERING')
VALUES('test');
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com


















 7133
7133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









