





本文字数:11241;估计阅读时间:29 分钟
作者:ClickHouse官方
本文在公众号【ClickHouseInc】首发
设计高效的模式是提升 ClickHouse 性能的关键,这需要在多个选项之间做出权衡。最佳的设计方案取决于查询类型、数据更新频率、延迟需求和数据量等因素。本指南将介绍一些模式设计的最佳实践和数据建模技巧,帮助您优化 ClickHouse 的性能。
Stack Overflow 数据集
本指南中的示例基于 Stack Overflow 数据集的一个子集。这些数据记录了从 2008 年到 2024 年 4 月间,Stack Overflow 上的每篇帖子、每次投票、每位用户、每条评论以及每个徽章。这些数据以 Parquet 格式存储,您可以通过以下 S3 存储桶获取:s3://datasets-documentation/stackoverflow/parquet/。
数据集中的主键和表间关系仅用于说明数据的关联和唯一性,并未通过约束强制执行(因为 Parquet 是文件格式,而不是数据库表格式)。
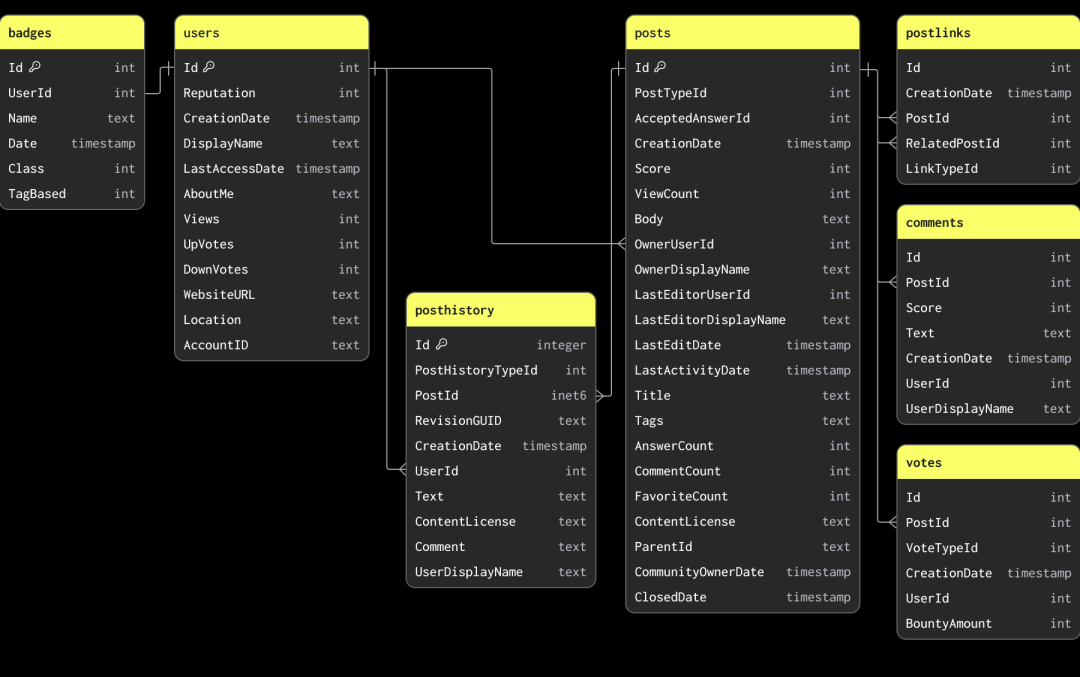
Stack Overflow 数据集包含多个相关表。在数据建模时,我们建议先加载主表。主表不一定是数据量最大的表,而是您预期大多数分析查询会针对的表。这样可以帮助您熟悉 ClickHouse 的核心概念和数据类型,尤其是如果您此前以 OLTP 数据库为主。这张主表可能会在添加更多表时重新建模,以便充分利用 ClickHouse 的功能并实现最佳性能。
为了说明教学目的,本指南中的模式设计是有意简化的。
建立初始模式
由于大部分分析查询都会针对 posts 表,我们将重点放在为该表定义模式。这些数据可以从公共 S3 存储桶获取:s3://datasets-documentation/stackoverflow/parquet/posts/*.parquet,其中每年数据存储在一个文件中。
从 S3 加载 Parquet 格式的数据是导入 ClickHouse 的首选方式。ClickHouse 对 Parquet 格式进行了优化,能够以每秒处理数千万行数据的速度从 S3 中读取并插入。
ClickHouse 提供了模式推断功能,可以自动识别数据类型。这一功能支持包括 Parquet 在内的所有数据格式。我们可以利用它,通过 s3 表函数和 DESCRIBE 命令来确定数据的 ClickHouse 类型。在下面的示例中,我们使用通配符模式 *.parquet 来读取 stackoverflow/parquet/posts 文件夹中的所有文件。
DESCRIBE TABLE s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/*.parquet')
SETTINGS describe_compact_output = 1
┌─name──────────────────┬─type───────────────────────────┐
│ Id │ Nullable(Int64) │
│ PostTypeId │ Nullable(Int64) │
│ AcceptedAnswerId │ Nullable(Int64) │
│ CreationDate │ Nullable(DateTime64(3, 'UTC')) │
│ Score │ Nullable(Int64) │
│ ViewCount │ Nullable(Int64) │
│ Body │ Nullable(String) │
│ OwnerUserId │ Nullable(Int64) │
│ OwnerDisplayName │ Nullable(String) │
│ LastEditorUserId │ Nullable(Int64) │
│ LastEditorDisplayName │ Nullable(String) │
│ LastEditDate │ Nullable(DateTime64(3, 'UTC')) │
│ LastActivityDate │ Nullable(DateTime64(3, 'UTC')) │
│ Title │ Nullable(String) │
│ Tags │ Nullable(String) │
│ AnswerCount │ Nullable(Int64) │
│ CommentCount │ Nullable(Int64) │
│ FavoriteCount │ Nullable(Int64) │
│ ContentLicense │ Nullable(String) │
│ ParentId │ Nullabl 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9686
9686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









