










一、下载Anaconda, VScode
1. Anaconda可以参考站内其他下载安装的教程,安装时主要注意几个勾要勾对,尤其是加入PATH的一定要勾。还有加入开始菜单的选项要记得勾,否则在开始菜单里面搜索不到。如果第一次安装没勾对,最省事的办法就是卸载重装。
2. VScode安装过程中都是中文,根据自己的需要勾选选项即可。
本教程只适用于英伟达显卡 (N卡)
二、VScode相关设置
1.设置页面为中文
进入这个插件页面,搜索简体中文插件下载即可。安装后参考本插件下载详情页面中的使用方法进行修改,如下图。设置完成后需要重启VScode以应用。

2.下载Python环境必须的插件
下图中的插件都需要同理搜索并安装

三、下载YOLOv10相关文件
原项目链接:https://github.com/THU-MIG/yolov10
参考我分享的这个网盘也可以进行相关资料的下载
1. 下载项目文件
下载"yolov10-main.zip"这个文件,解压缩完文件内容如下图("app_bak.py"这个文件是我自己的备份,官方文件没有,不用管)
2. 下载官方模型
下载网盘链接中的"官方模型.zip",解压完的文件如下图
3.将官方模型放到项目文件中
移动完之后如下图所示
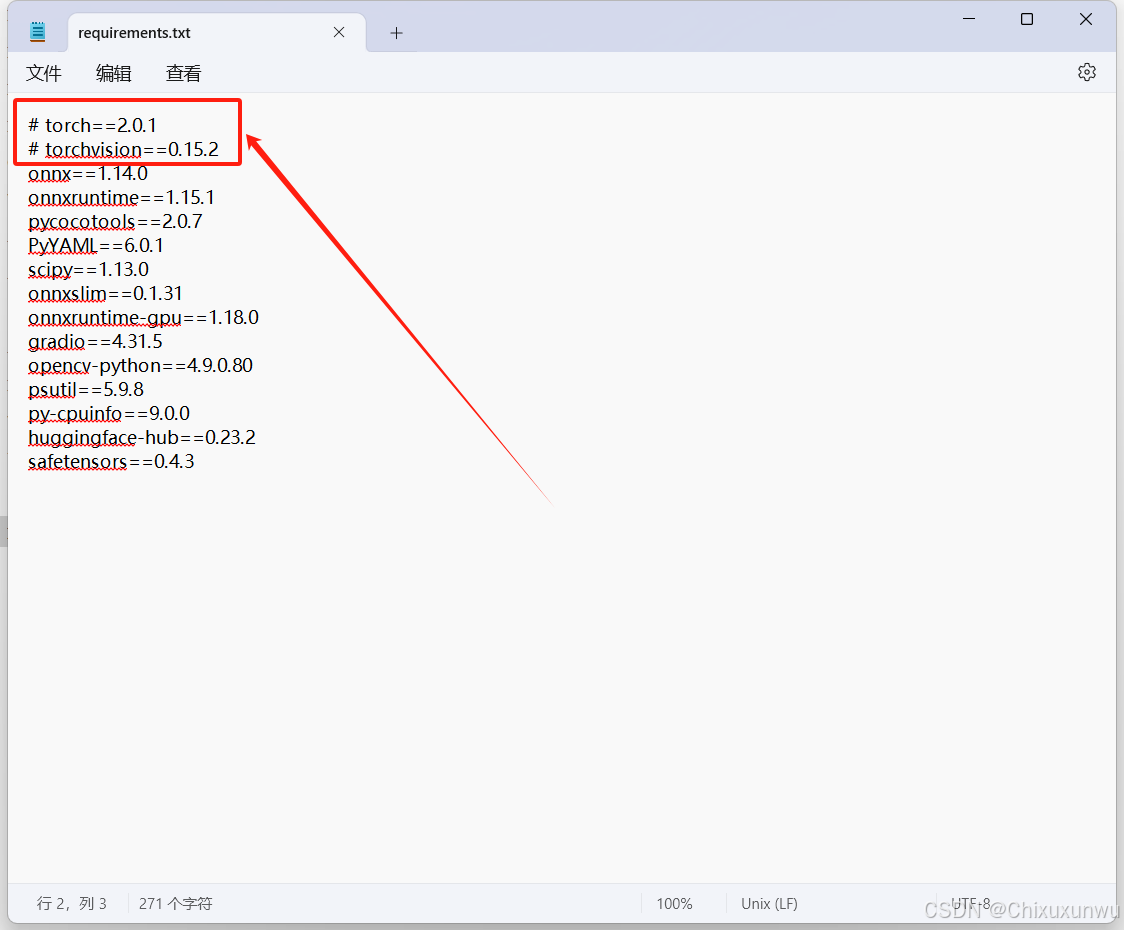
4. 修改项目文件根目录中的"requirements.txt"这个文件
如下图,用记事本打开,给前两行加上"#"以注释,因为这两个文件需要我们自己手动安装。一定要记得保存修改!!!
四、设置虚拟环境
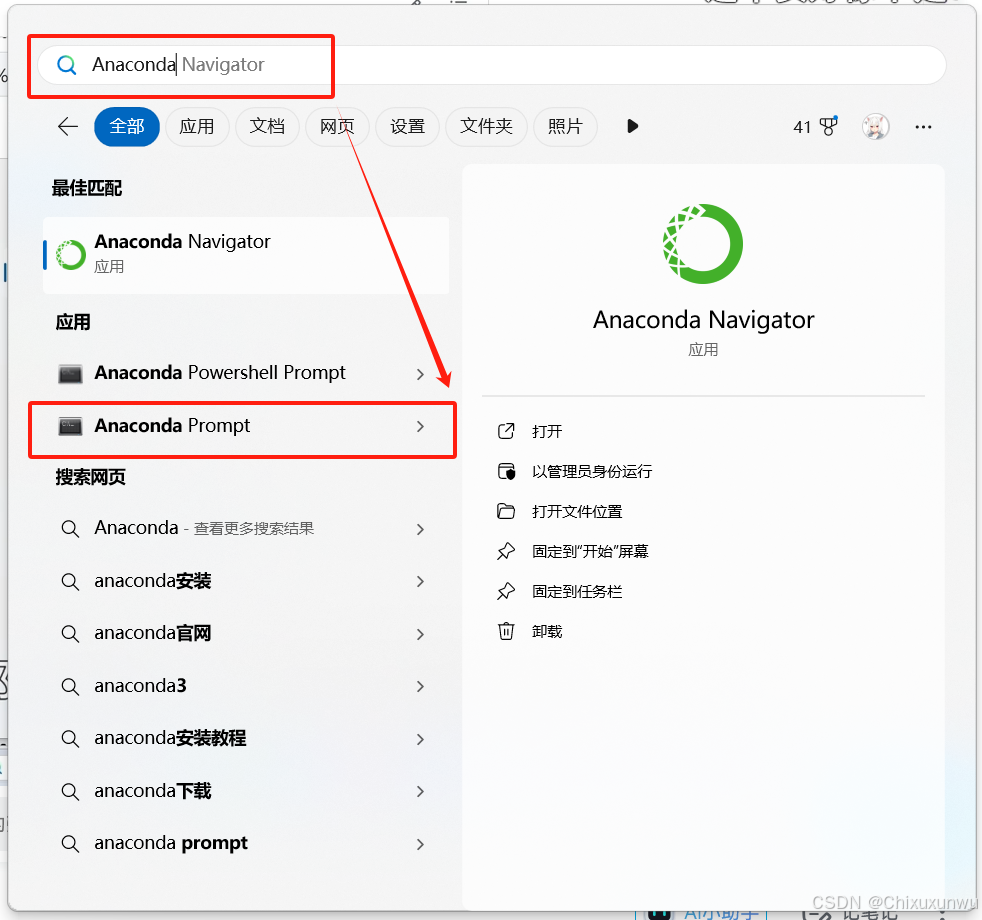
1. 在开始菜单中搜索"Anaconda Prompt"如下图打开
2. 在页面中输入以下指令 注意必须是指定"python=3.9"这个版本
conda create -n yolov10 python=3.9
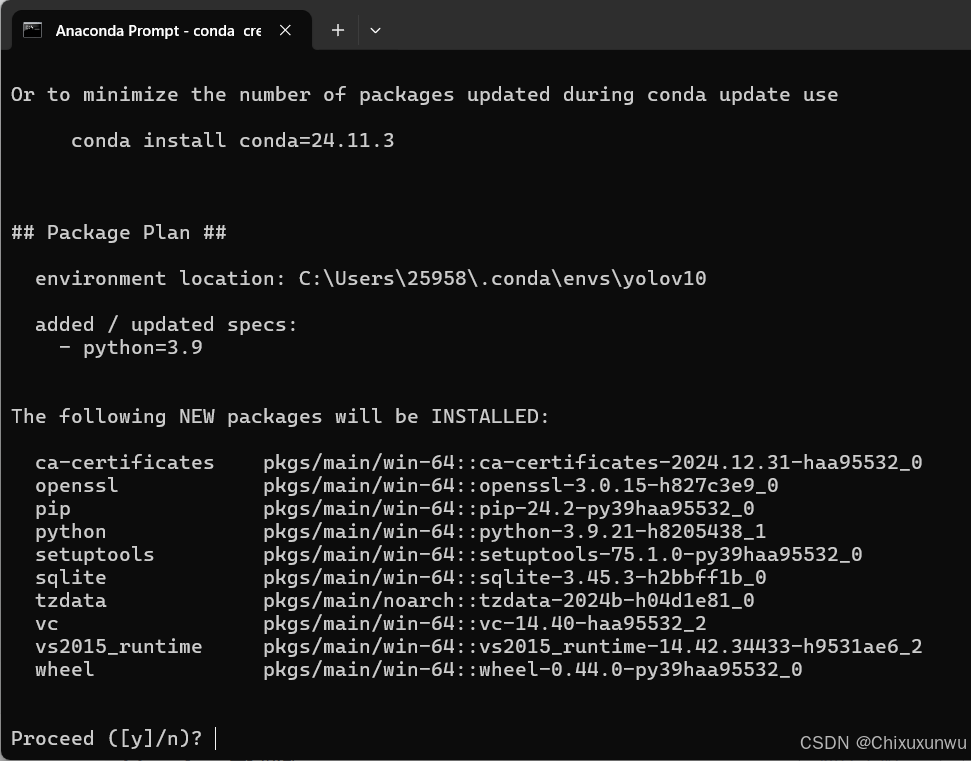
出现这一步时输入"y"以继续
3.输入下面的指令以激活环境
conda activate yolov10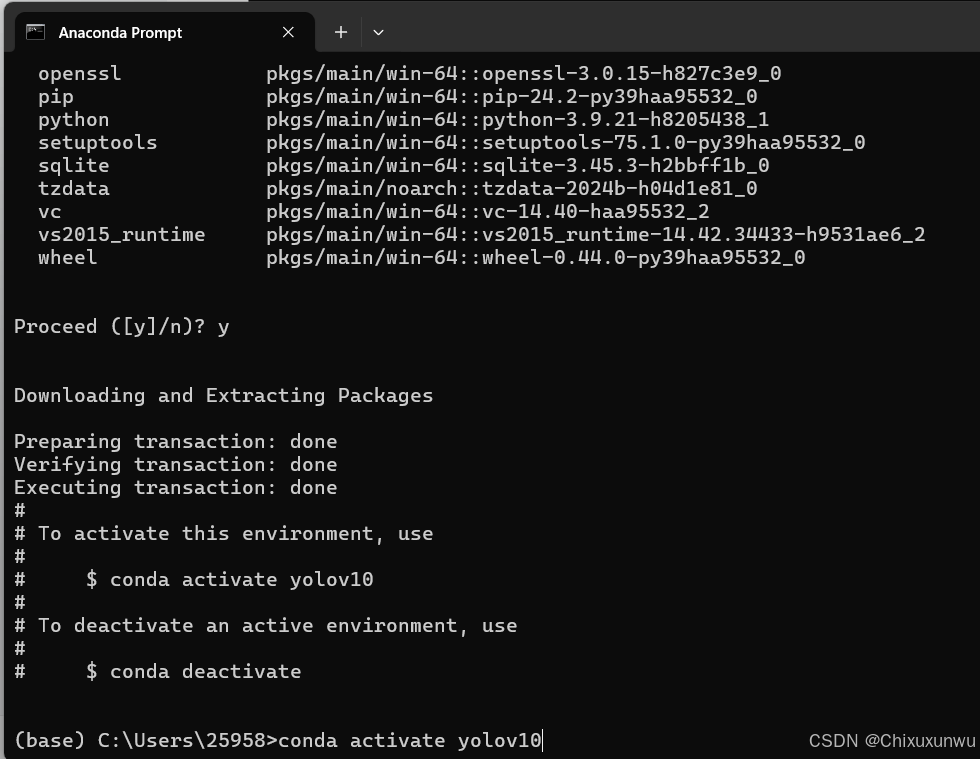
执行完成之后当我们发现小括号里变成了yolov10就代表成功了

五、安装相关的库和包
1. 查看自己的显卡信息
win+R再输入cmd打开,输入nvidia-smi
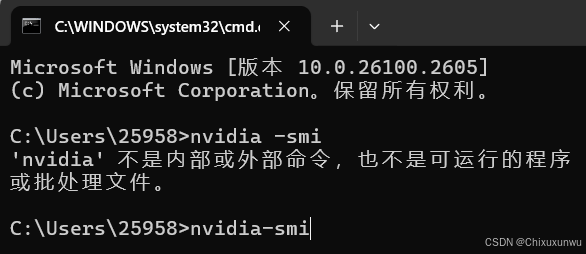
出现下图中的结果后,查看标注处的cuda版本 (如果没出现相应结果的,需要自行更新显卡驱动到最新版本)
确保自己的cuda版本高于11.8即可
2. 进入到Pytorch官网进行下载文件 网址:PyTorch
点击这里
点击下图标注处查看历史版本
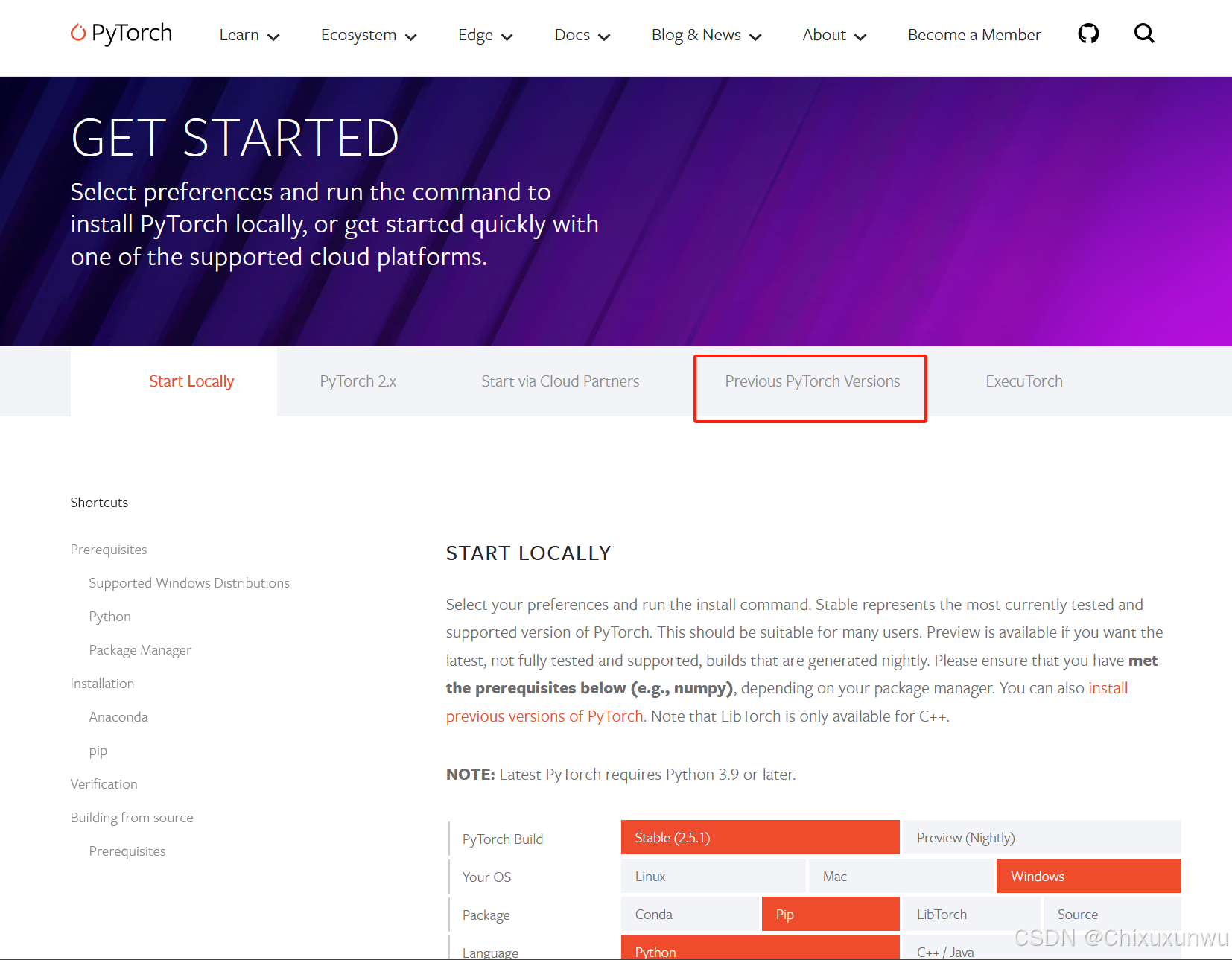
下滑找到"v2.0.1"这个版本,继续在"Wheel"这里找到"cuda=11.8"下方的这段命令
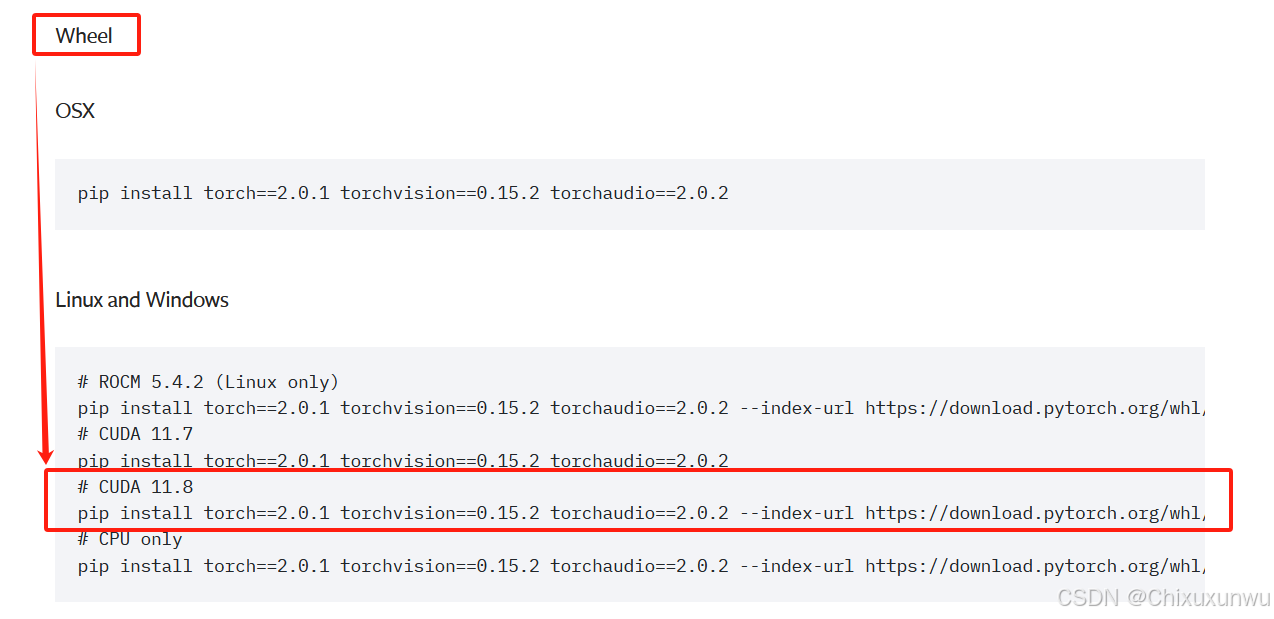
pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118把这段指令输入到之前带yolov10的那个命令框里

等待下载即可
3. 安装"requirements.txt"中的相关库包
进入项目文件的根目录 进入路径前一定要记得加cd

输入下面这行指令
pip install -r requirements.txt![]()
等待下载即可
4. 安装其他的库包
同样的,输入下面的指令
pip install -e.![]()
等待下载即可
下载时出现报错的解决方案:
1. 换源:
用win+R打开命令行,输入下面的指令,将下载源换成清华源,稳定性和下载速度都会提升
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple/在切换完了之后可以输入以下指令进行验证
pip config list配置成功后可以看到类似下面的结果

2. 检查是否开了加速器或者其他代理:
可以尝试关闭相关的加速器或者代理保证网络的纯净性
3. 如果以上方法都行不通的话:
可以尝试将网络连接至手机热点,可能会好使
六、在VScode中进行测试
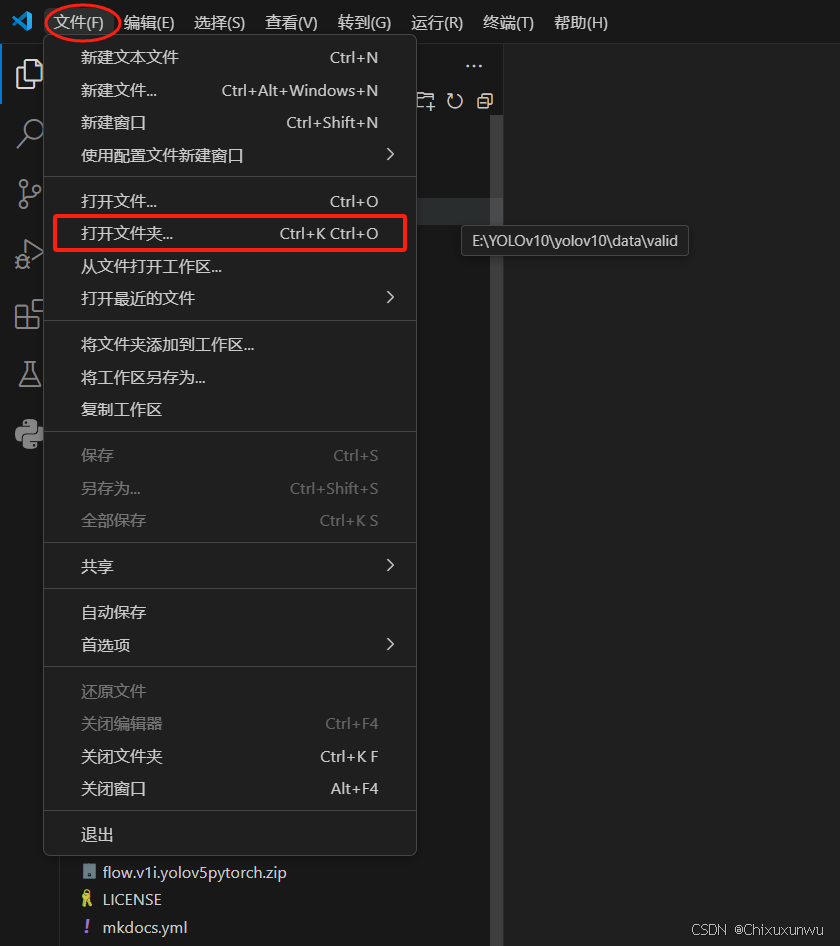
1. 点击"文件",打开根目录所在的文件夹,如下图所示
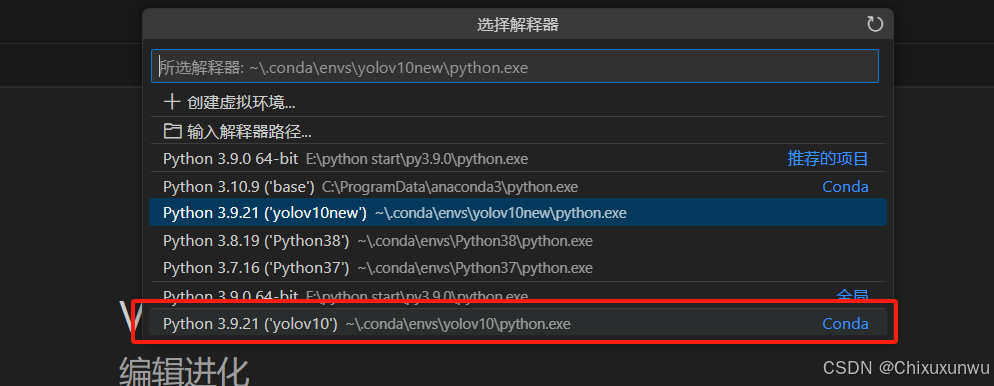
2. 选择Python解释器
按住Ctrl+Shfit+p, 在下图中的搜索栏中搜索解释器,并点击"选择解释器"

选择我们刚刚配置了的虚拟环境
右下角出现了下图所示的内容就是成功了

3. 在左侧的目录中选择app.py进行编辑
第一个函数中对于model的定义,一定要把原来的注释掉,在改成如下图中的内容
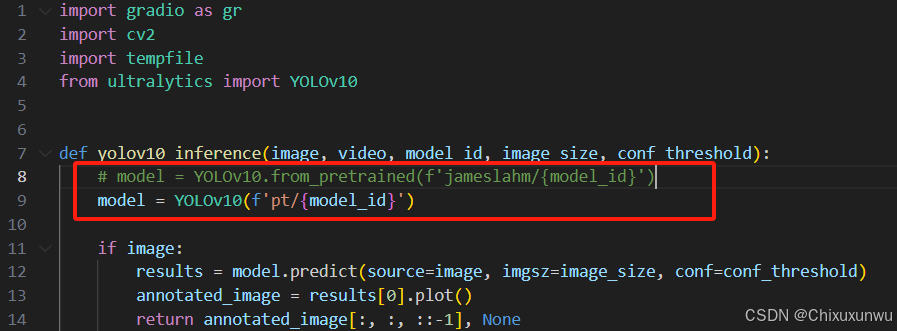
在定义app这个函数的代码中,一定要把没有加.pt后缀的全部给加上
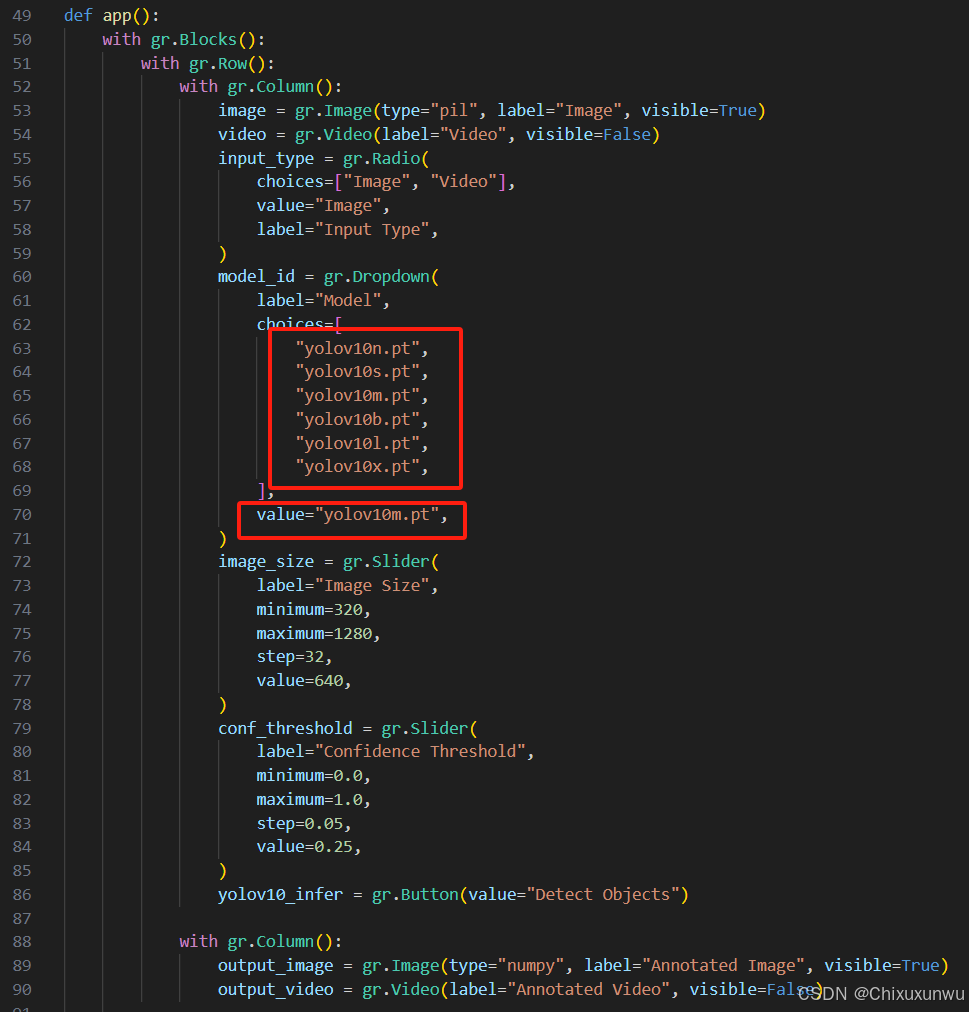
4. 运行app.py这个文件
在页面的右上角,点击如下图所示的按钮,即可运行

此时在下方会出现展示输出结果的终端
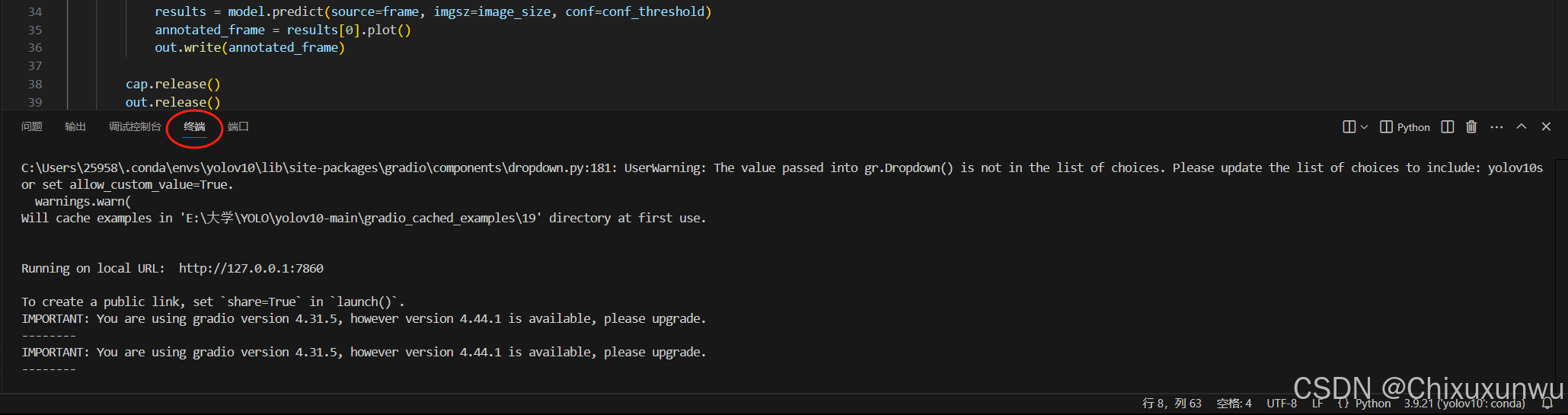
我们还可以发现输出了一个链接

复制到浏览器打开,我们就可以得到一个测试的网页,这个网页只能本地用
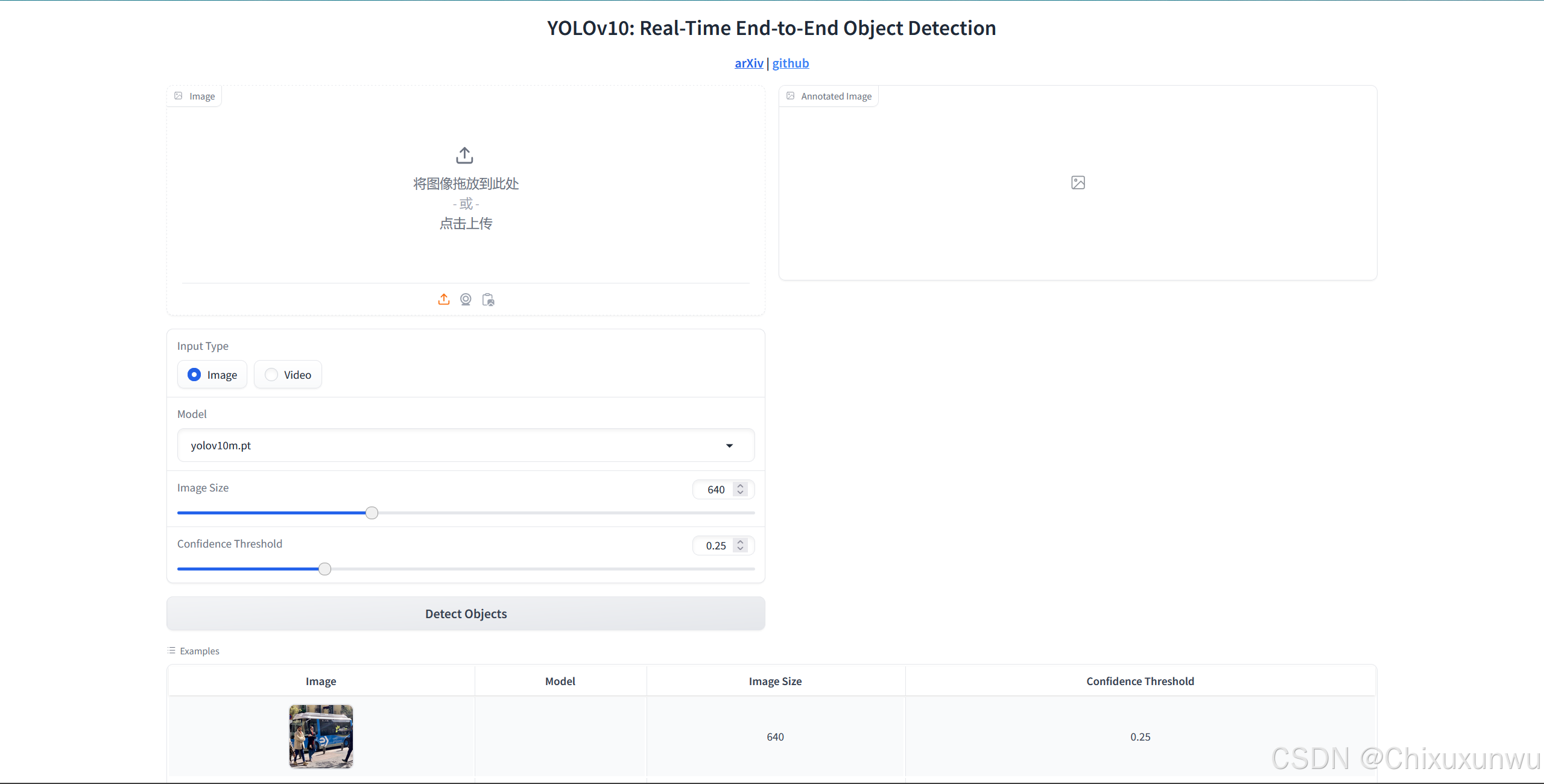
在这里我们可以选择官方的模型,从上到下,模型的精准度递增,检测的时间也会相应的增加
以下图为例,我们可以上传图片并得到目标检测的结果
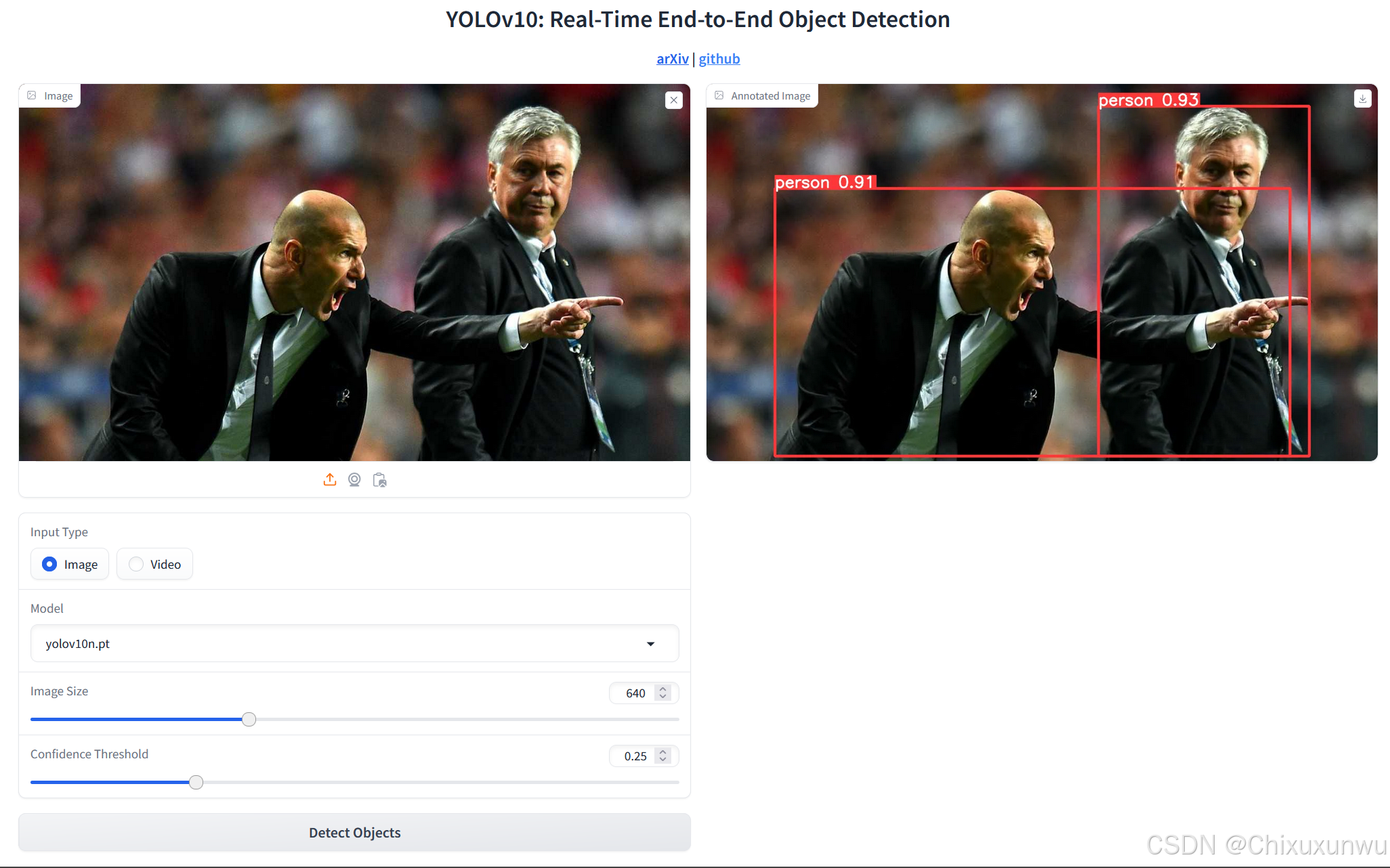
以上,我们YOLOv10的环境搭建和简单测试就已经全部进行完了。大家可以根据自己的数据集对模型进行训练
简单测试中的常见问题:
1. Connection errored out 这个报错
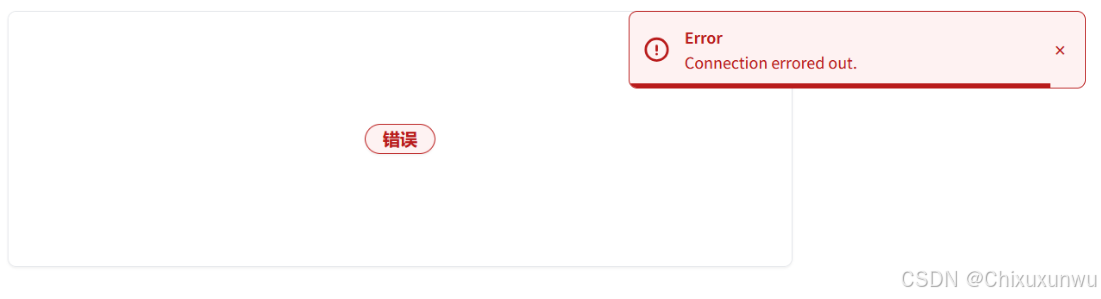
本人在第一次测试的时候也出现了这个问题,主要原因是库和包的版本不对,以及测试网页相关的Gradio没有更新导致的,解决方法如下:
1): 在(yolov10)的这个命令行中,重新输入之前安装requirements.txt和-e.的这两条指令,检查是不是有没有安装成功的库和包,如果装了的会提示已经安装了,不会重复安装
2): 检查之前安装的pytorch相关库包的版本,一定要保证是V2.0.1和cuda=11.8,不然很有可能出问题
3): 检查Gradio的版本,输入下图中的指令以更新Gradio
pip install --upgrade gradio![]()
出现类似的结果就代表更新成功了
![]()
七、通过Roboflow用来训练的数据集
1. 进入Roboflow的官网
网址:Roboflow: Computer vision tools for developers and enterprises
自行注册账号,有账号的直接登录即可
创建Workspace的时候选择免费的那一个就行
2. 新建一个自己的Project
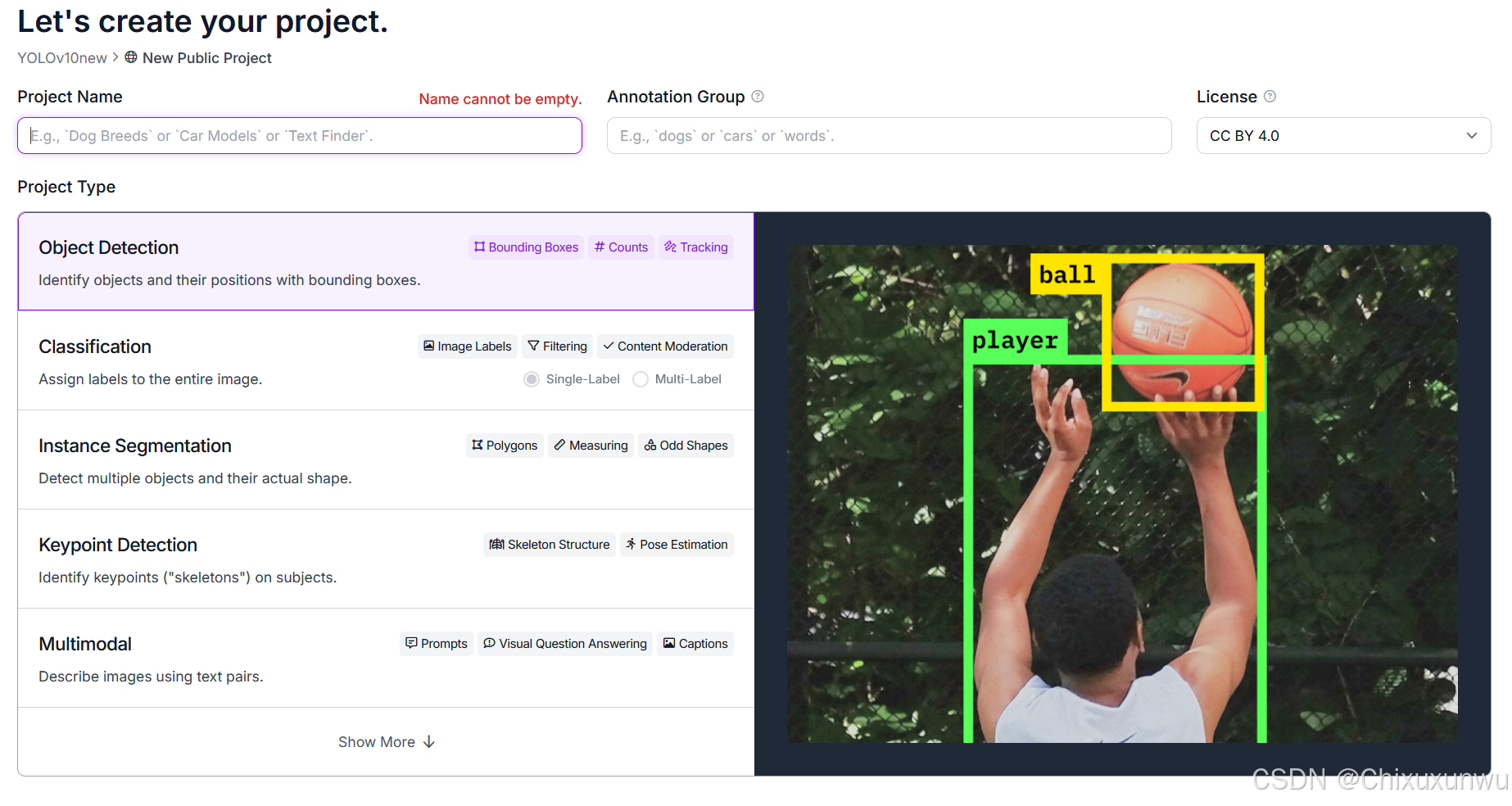
如下图所示进行创建

之后进入到如下图所示的页面按照需求填写相关信息即可
3. 寻找数据集
点击左下角的这个Universe进入社区,搜索自己想要的数据集
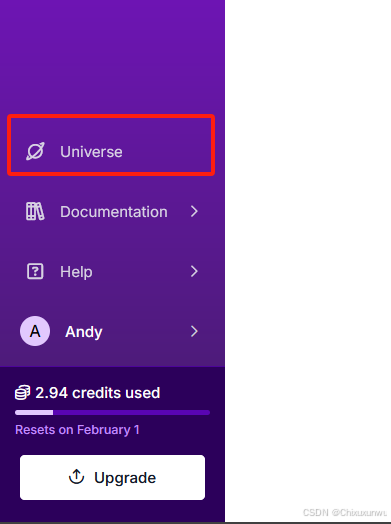
搜索自己需要的素材

例如我这里想找一个关于吉他琴型检测的数据集, 找到自己想要的点进去,最好是大一点的数据集
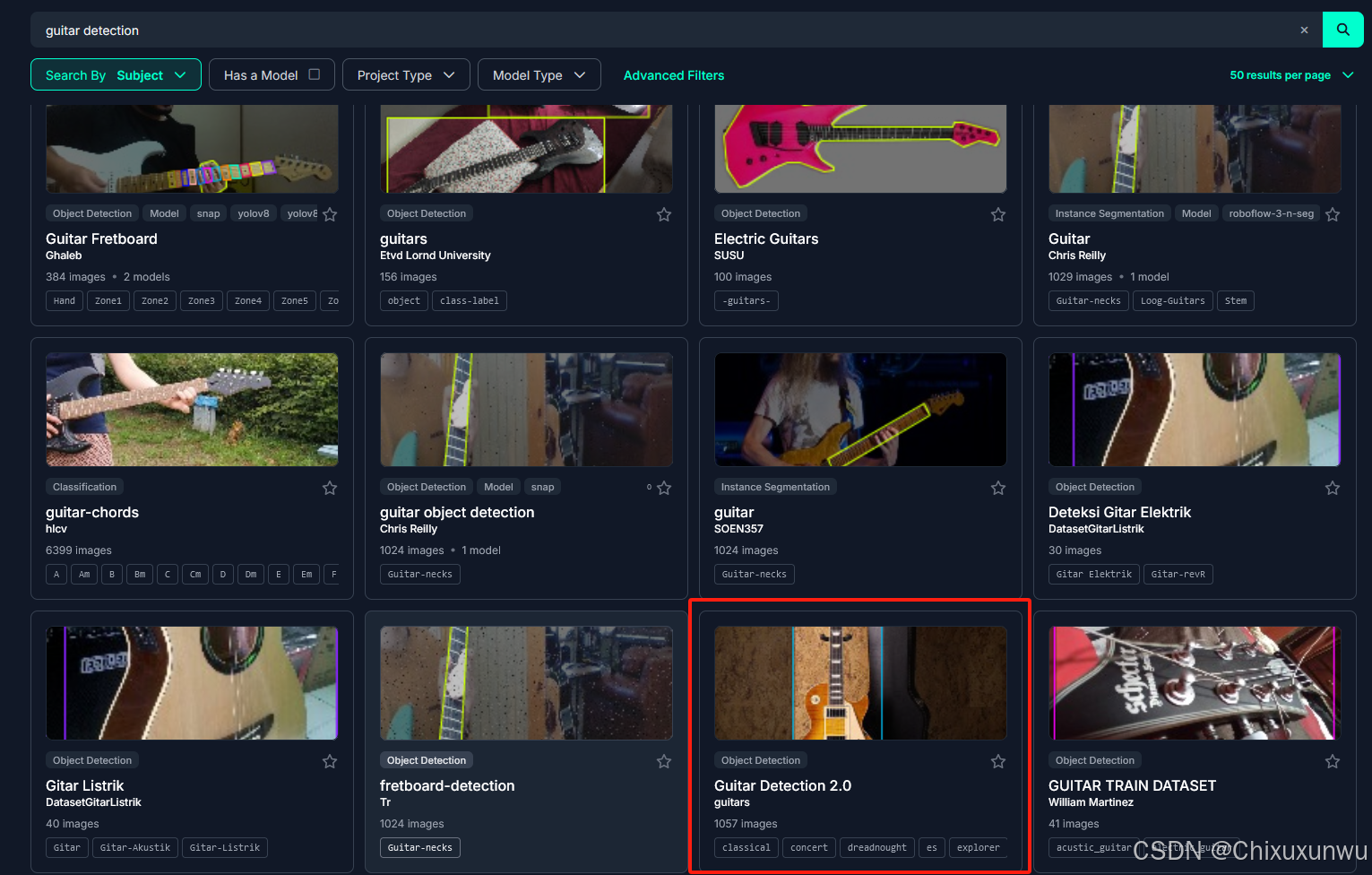
进去之后我们点下图所示的位置查看图片
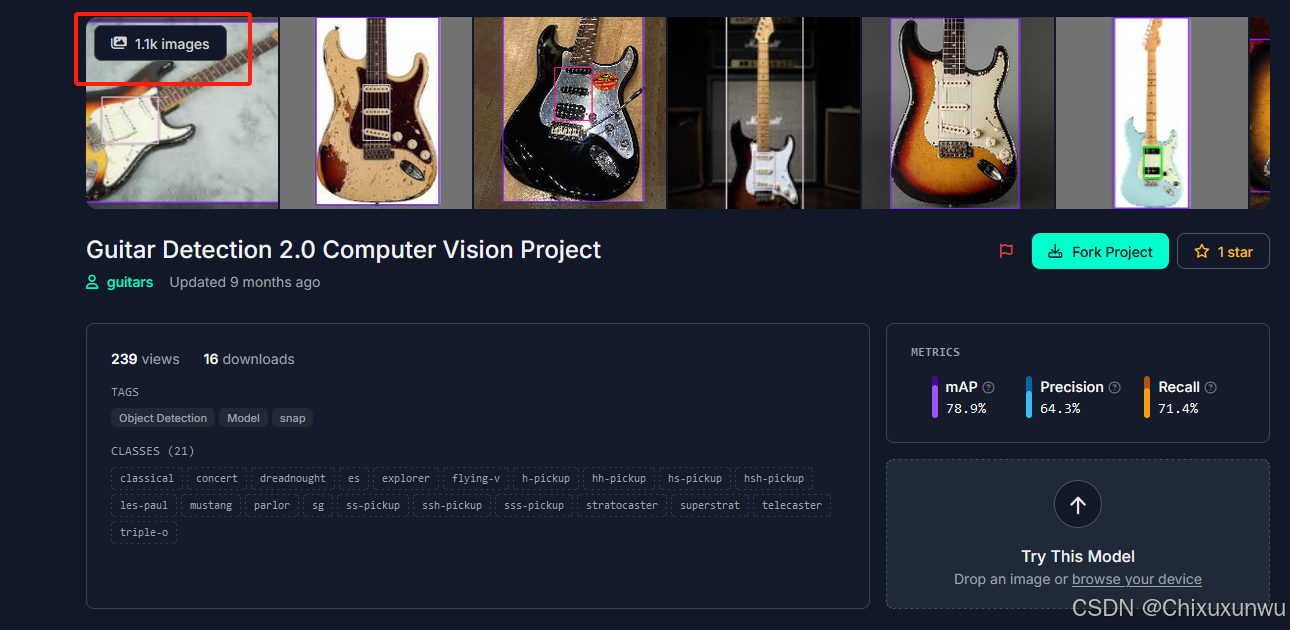
勾选你需要的图片,每一页点左上角的勾这个位置可以全选
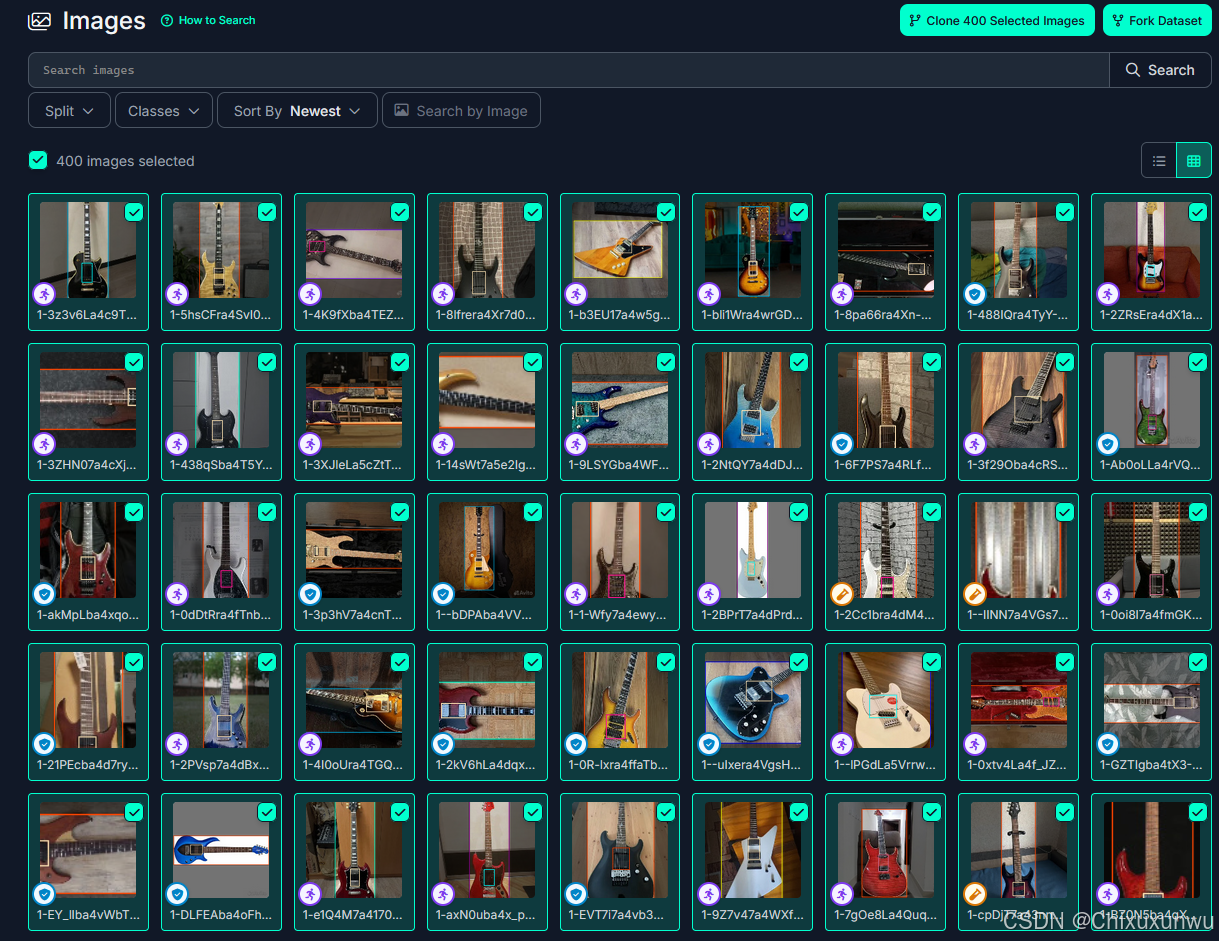
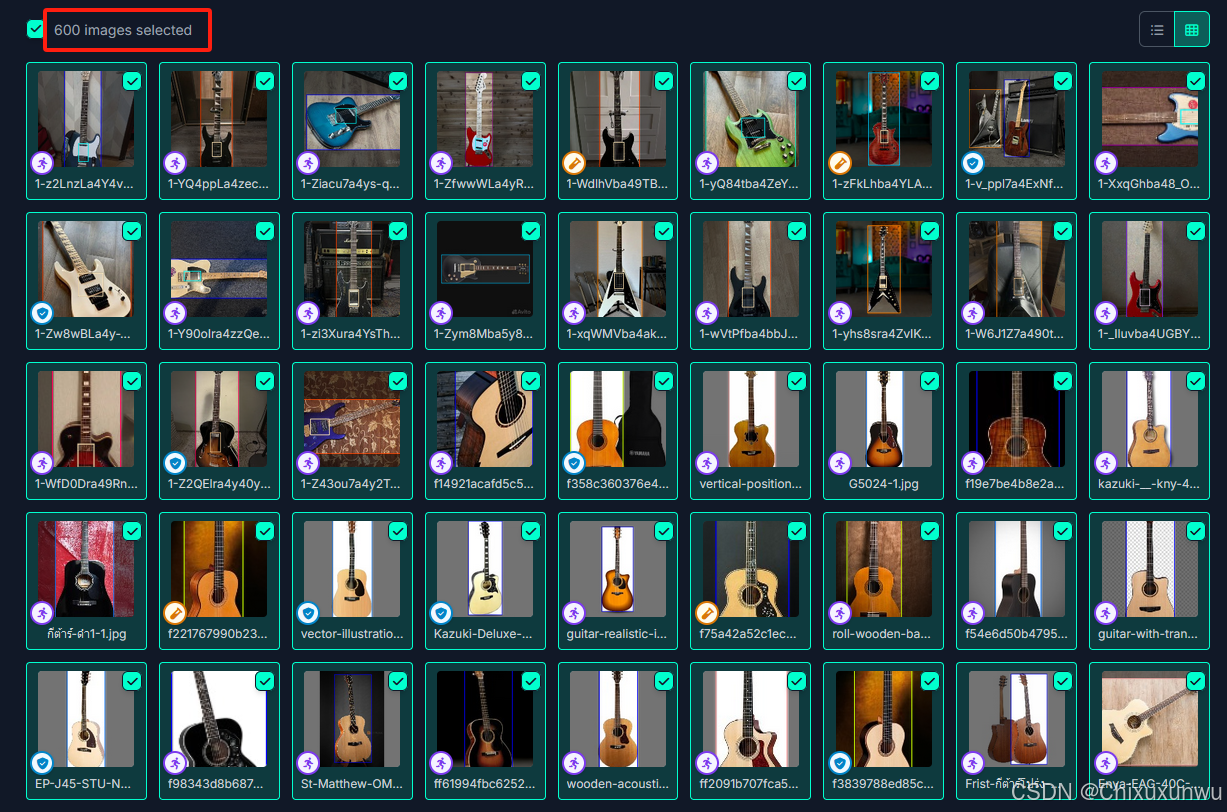
全部选完了之后我们点击右上角的这里,复制到我们的Project里面
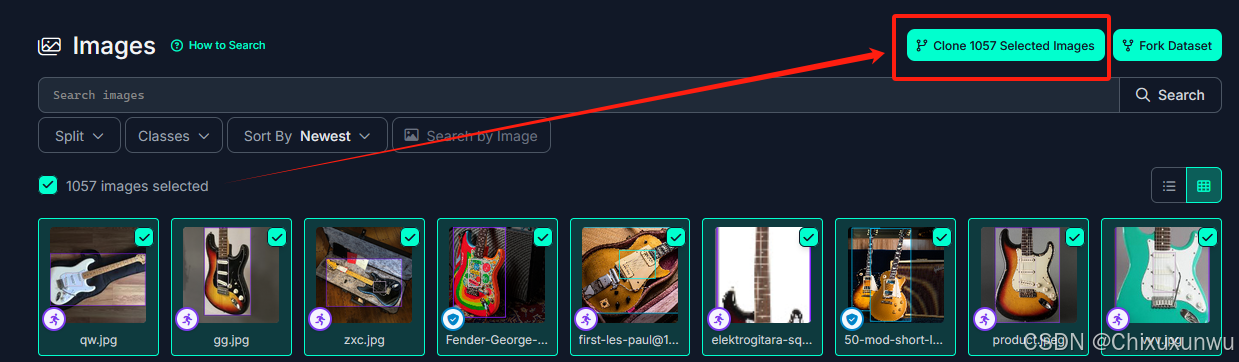
下一步这里我们需要勾选的是别人已经标注好了的图片,而不是原始的图片
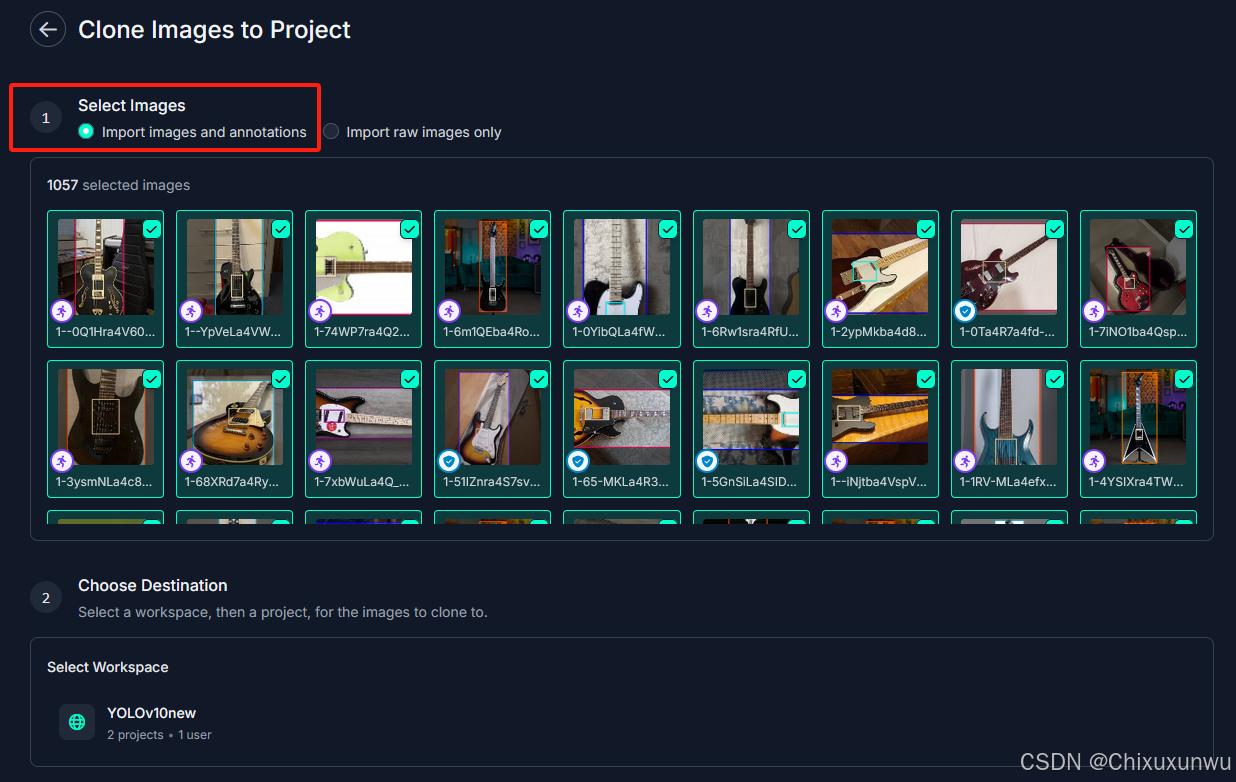
接着我们依次选到自己刚刚创建的Project那里
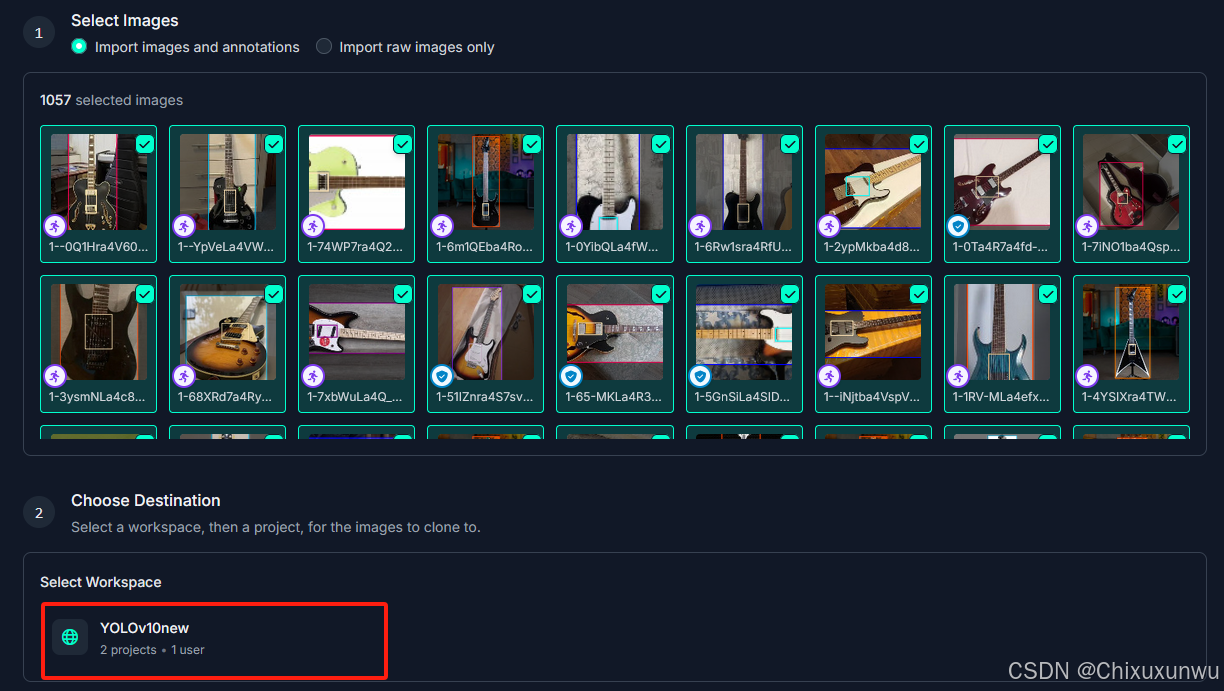
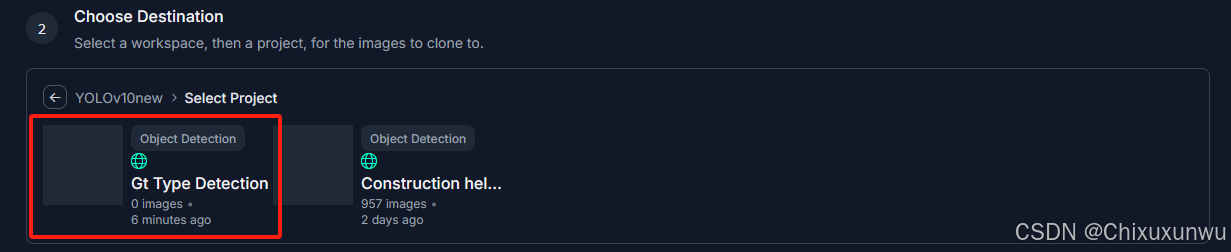
经过上面的操作之后我们点这个克隆
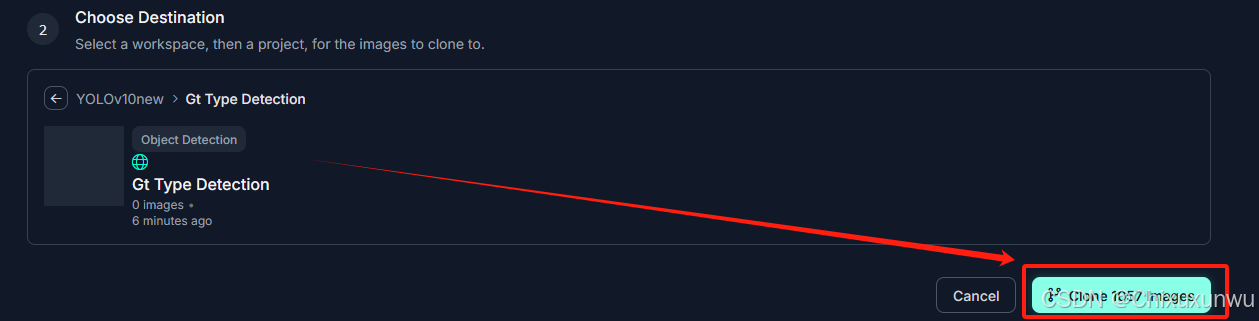
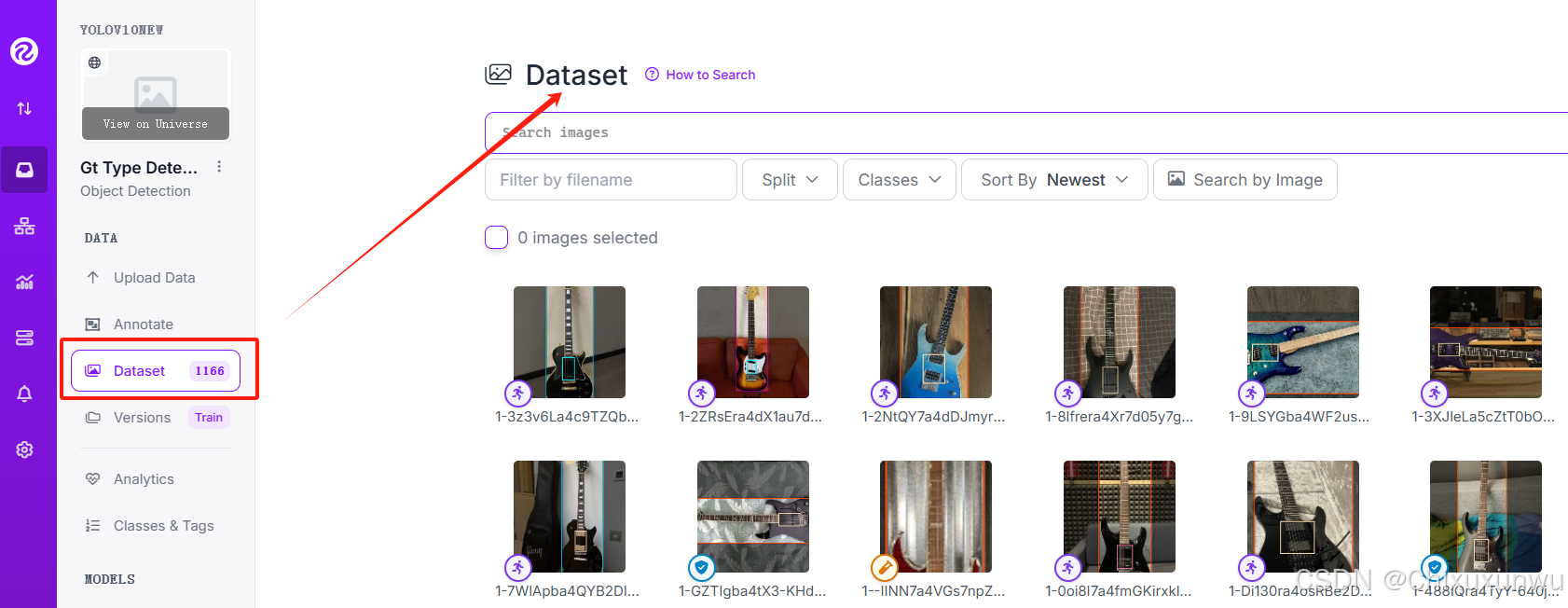
全部克隆完了之后,我们返回之前Workspace里的Project,在Dataset这个位置看到图片就代表成功了
如果在克隆的操作时出现了Error,可以尝试以下方法:
1): 换一个浏览器试试
2): 一次不要全选,可以几百个克隆一次,分多次进行克隆
3): 实在不行就只能换一个数据集试试了
4. 手动标注添加到数据集里
我们也可以在下图中的位置自己添加想要的图片到数据集里面
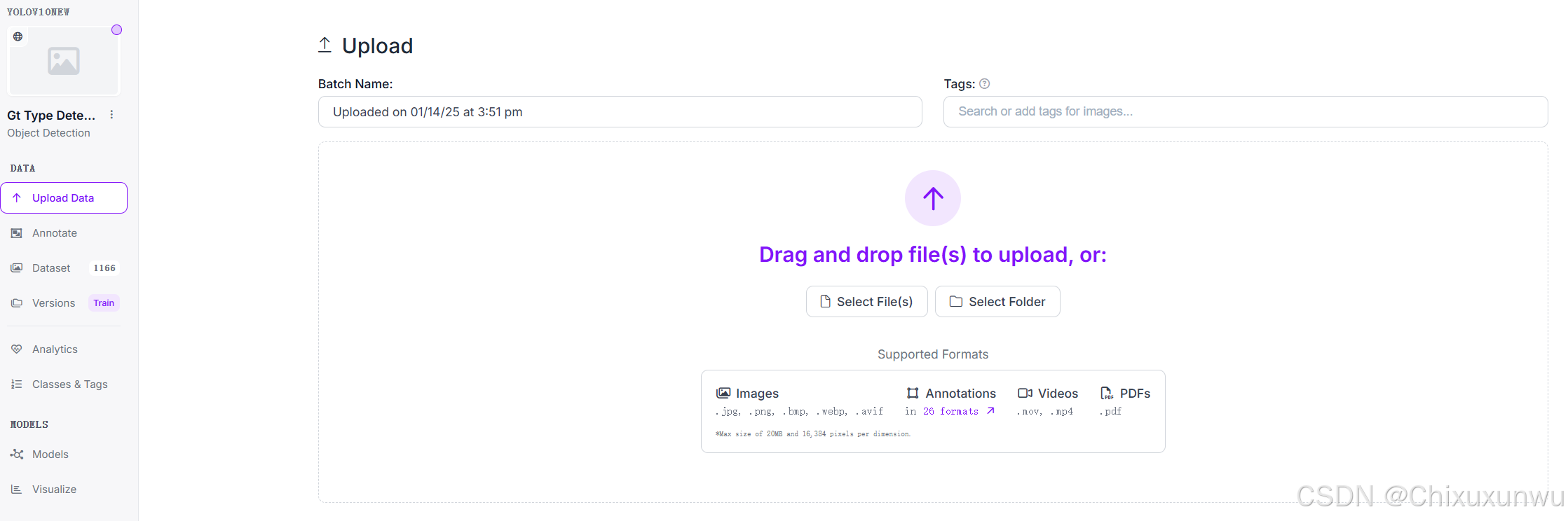
这里我已经上传了一张图片,点这里以继续,继续之后才会上传
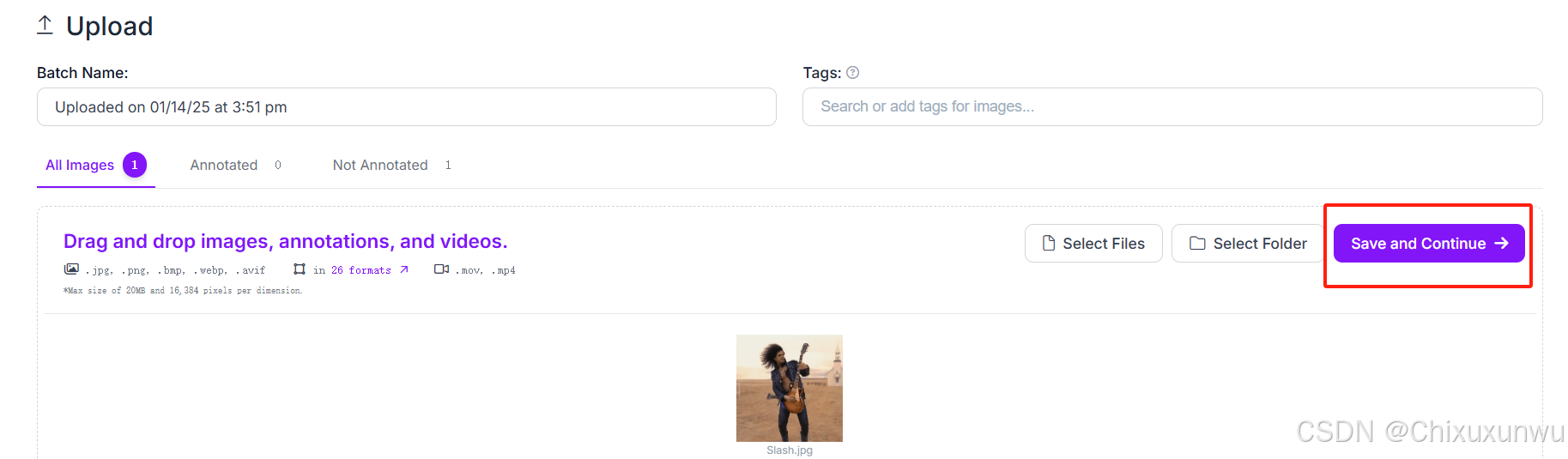
上传完成之后,浏览器的右边会弹出一个提示框,问我们要哪种标注方式,我们选择人工标注这一个
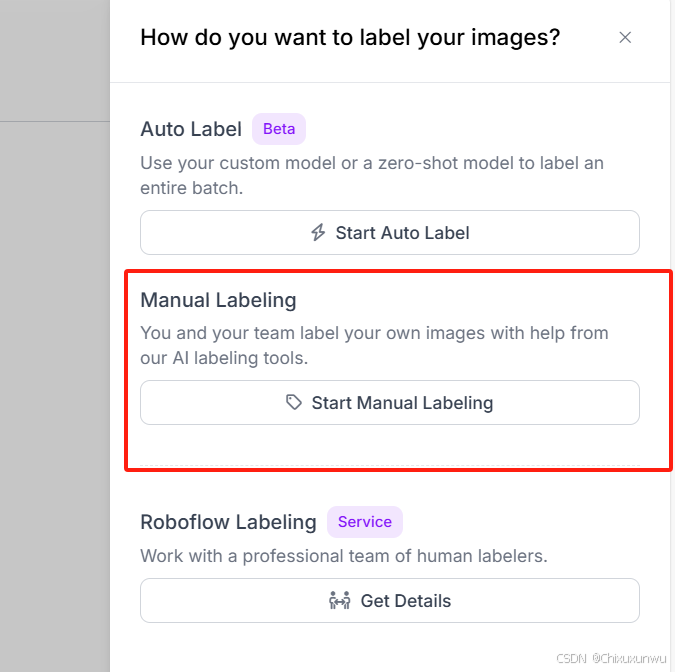
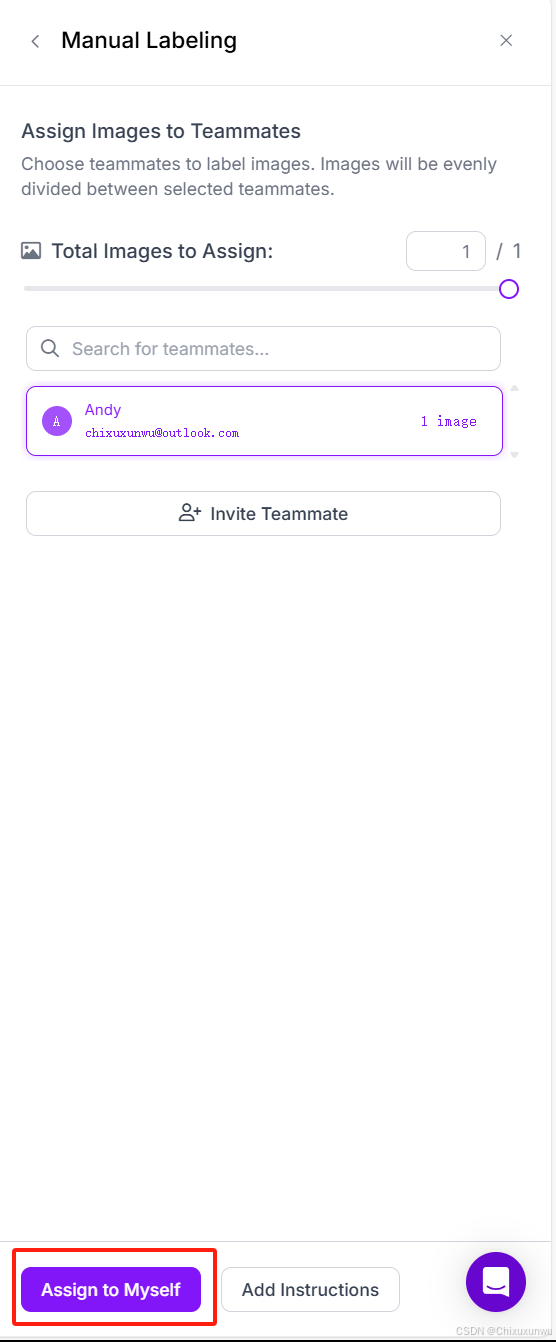
我们点击左侧的Annotate,在点击右边的Start开始标注

我们可以对手动框选的物体选择对应的标签,以及这张图片作为test, val还是train,标注完了之后直接点左上方的返回即可
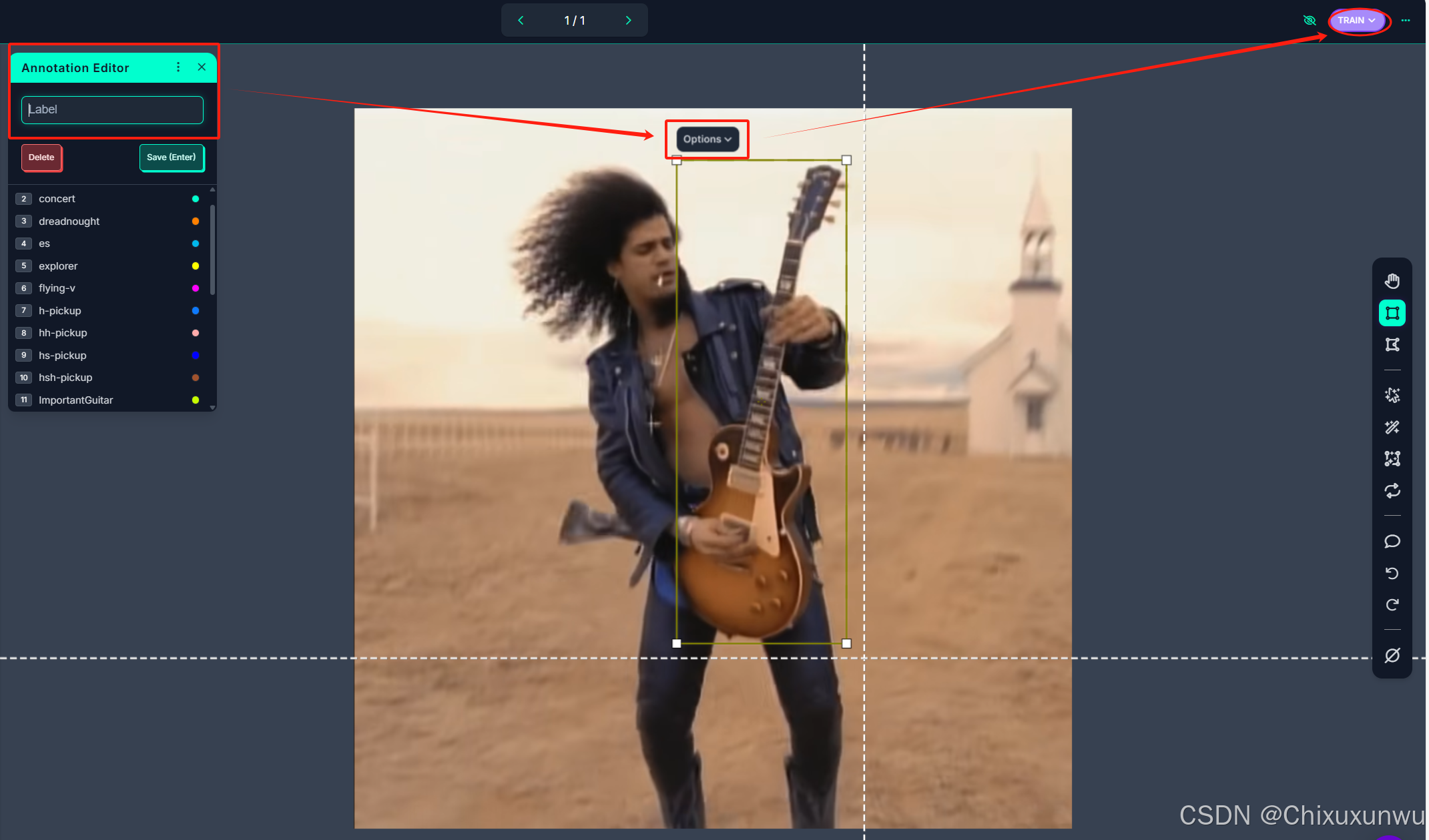
之后点击添加到数据集
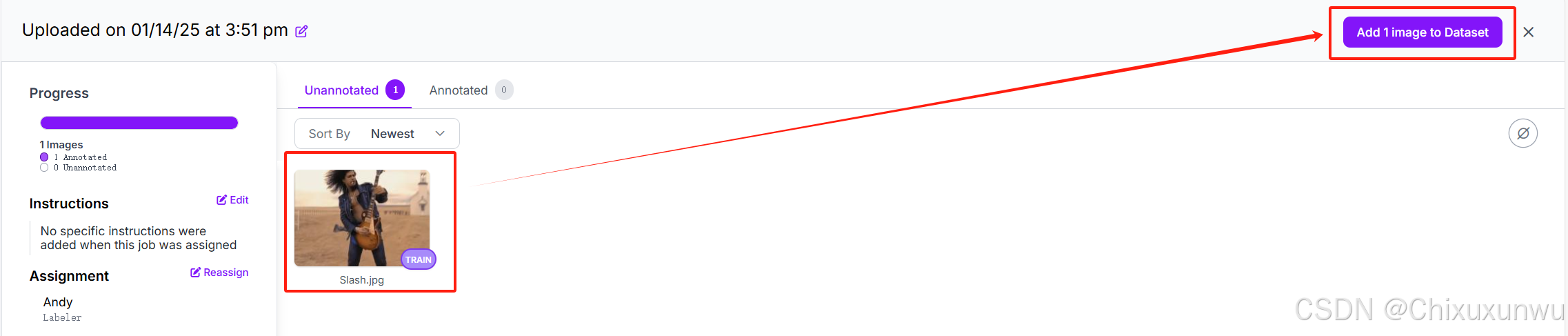
在保存的时候我们通常选第二项,如下图所示"Solit Images Between Train/Valid/Test"即按照预设的比例进行分类。如果想手动调整比例,就选"Use Existing Values",会根据你之前在标注时的设定保存
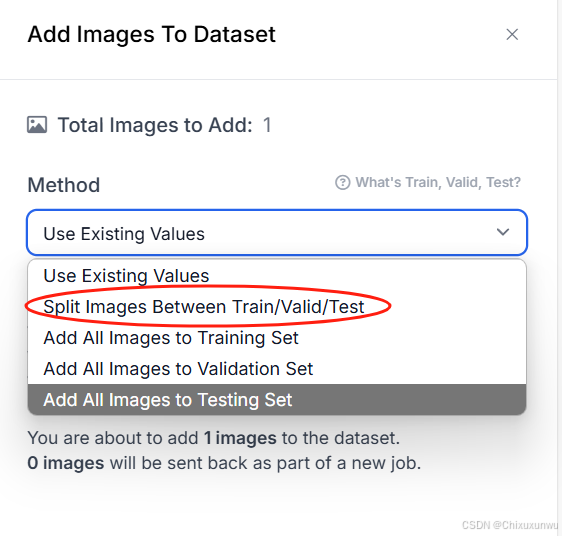
选择完了之后点击下面的添加即可
5. 使用Roboflow官方的模型对数据集进行训练
我们先点击Version进入到如下图所示的页面
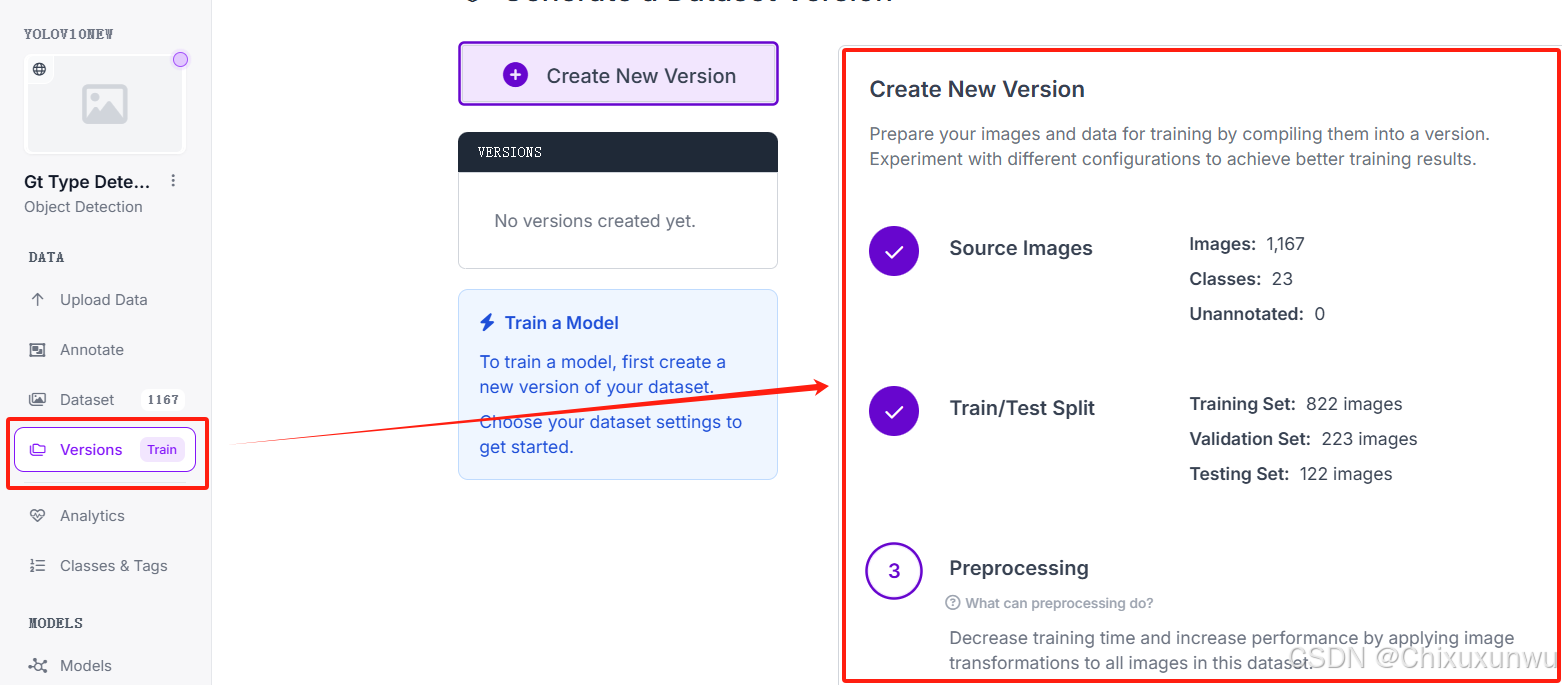
看到第三步这里,我们可以给图片添加滤镜 (Auto-Orient和Resize就这样默认即可,不用动)
当然不添加这个也行
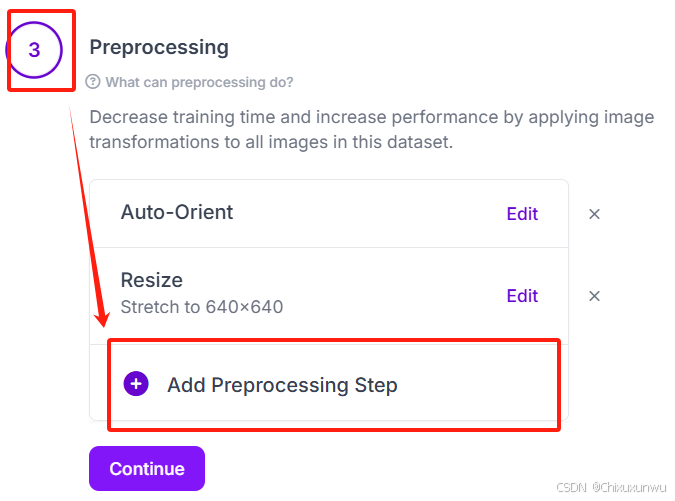
带有Upgrade字样的滤镜都是会员才能用的,普通用户选下图的这个就行
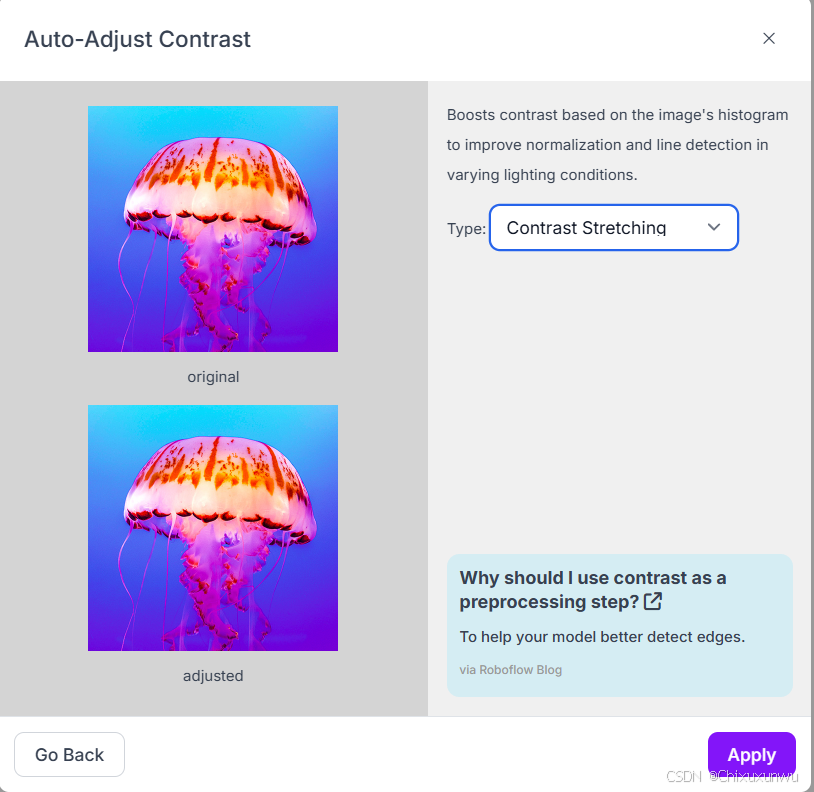
第四步这里就是通过处理图片增加数据集里的数据量
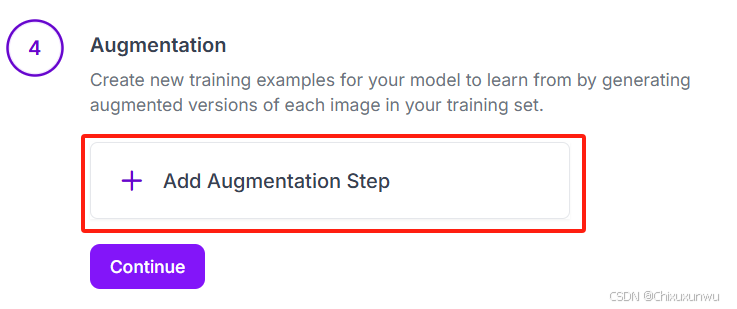
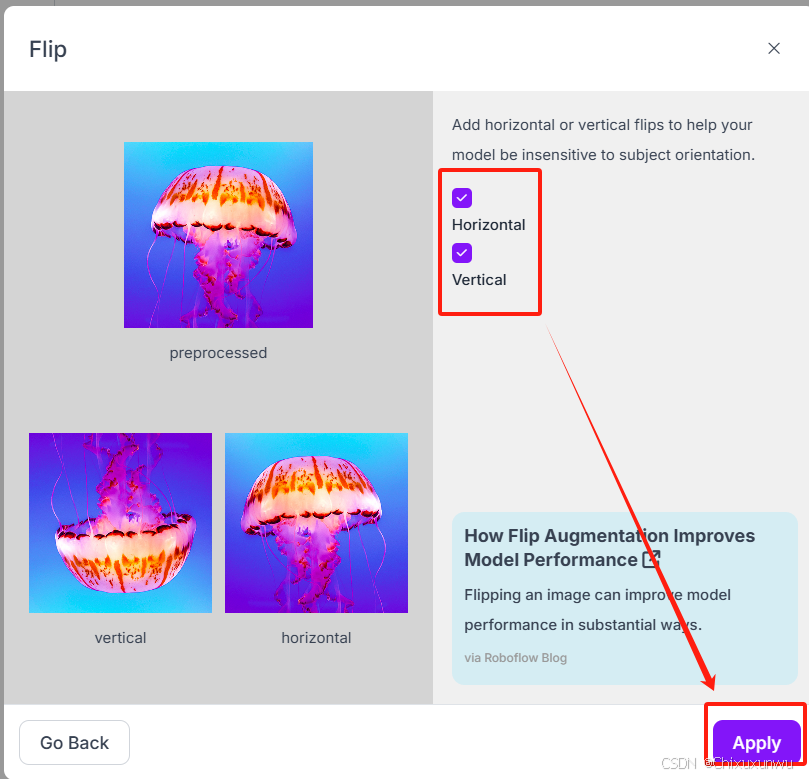
通常可以选这个,然后在下一步把vertical和horizontal都打钩
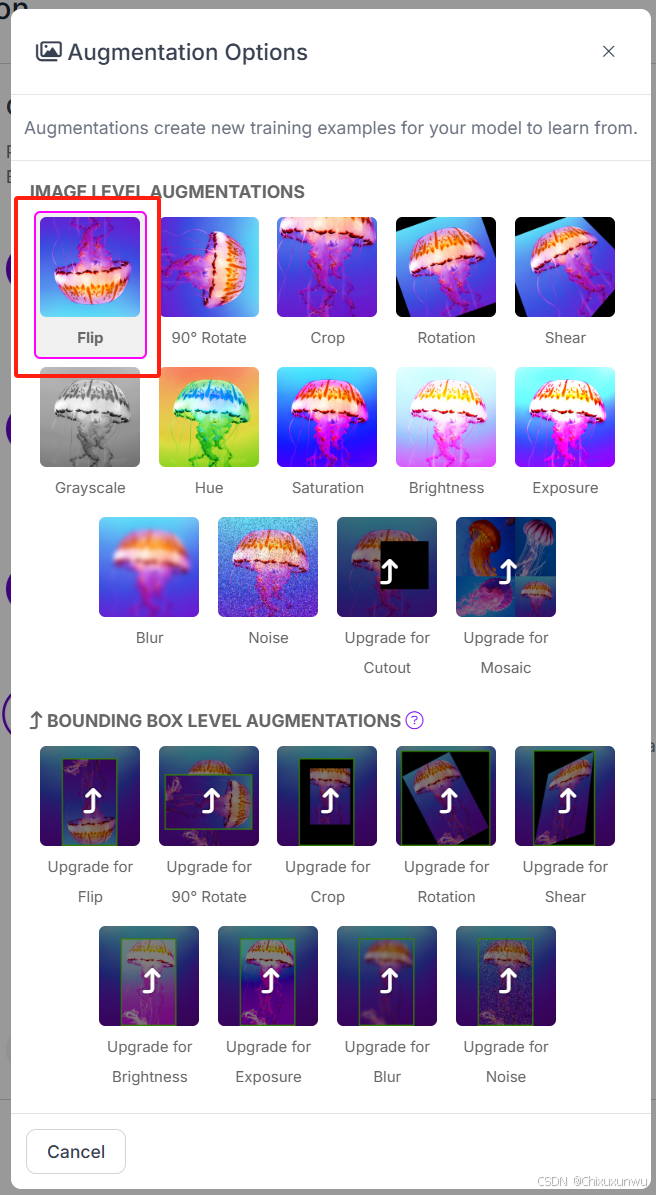
在第五步中,非会员建议选择如图的这个
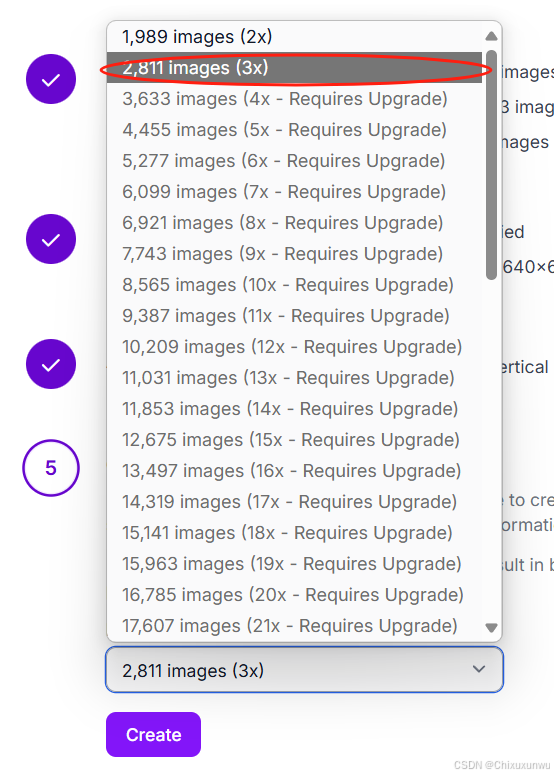
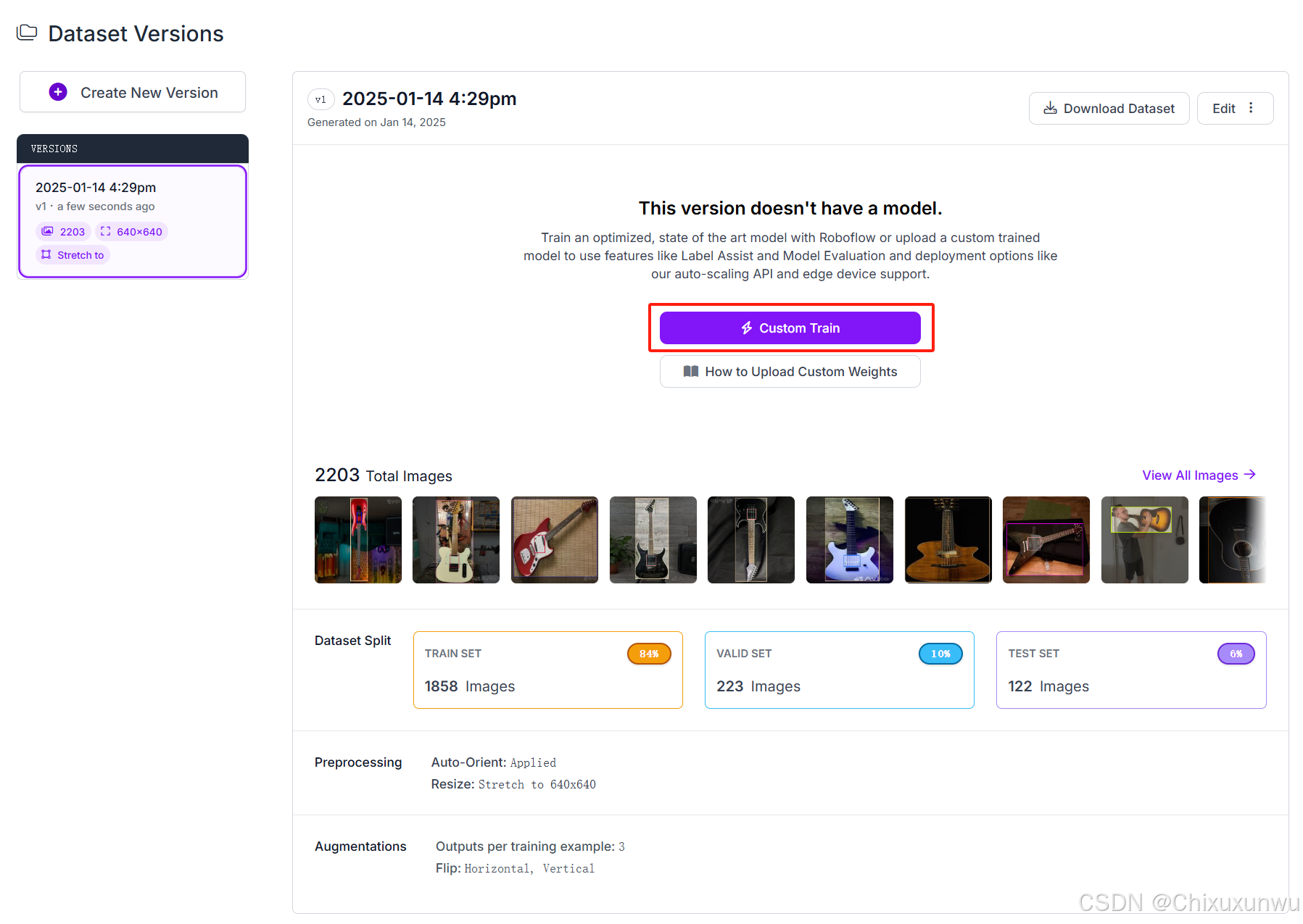
完成之后点击训练,并选择用官方的这个模型训练,之后选择Fast的这一项
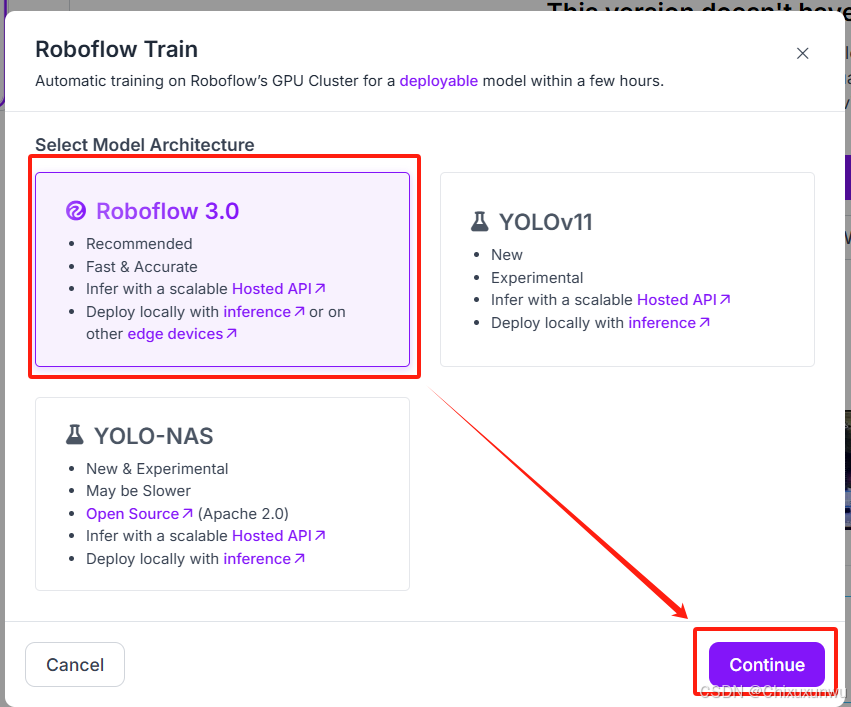
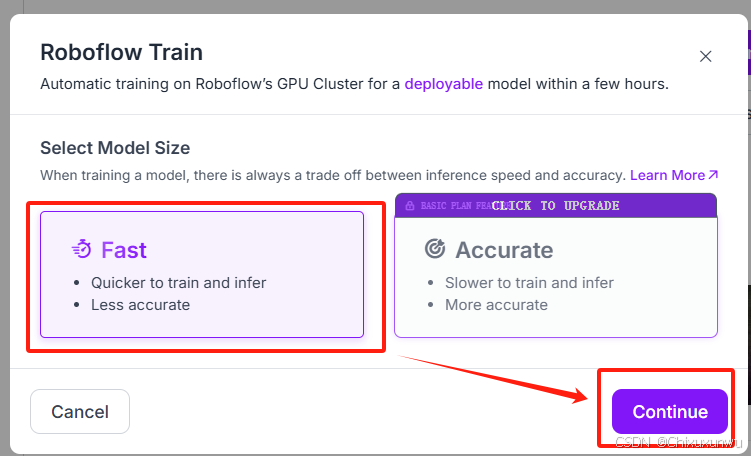
下面一个页面我们默认,不用管就行了。之后点击开始训练
之后官网会在他们的服务器帮我们训练,之后训练完会有邮件发到注册时所用的邮箱进行通知
下图的进度条读完之后就会开始训练了,时间通常会比较长,耐心等待邮件通知就行了
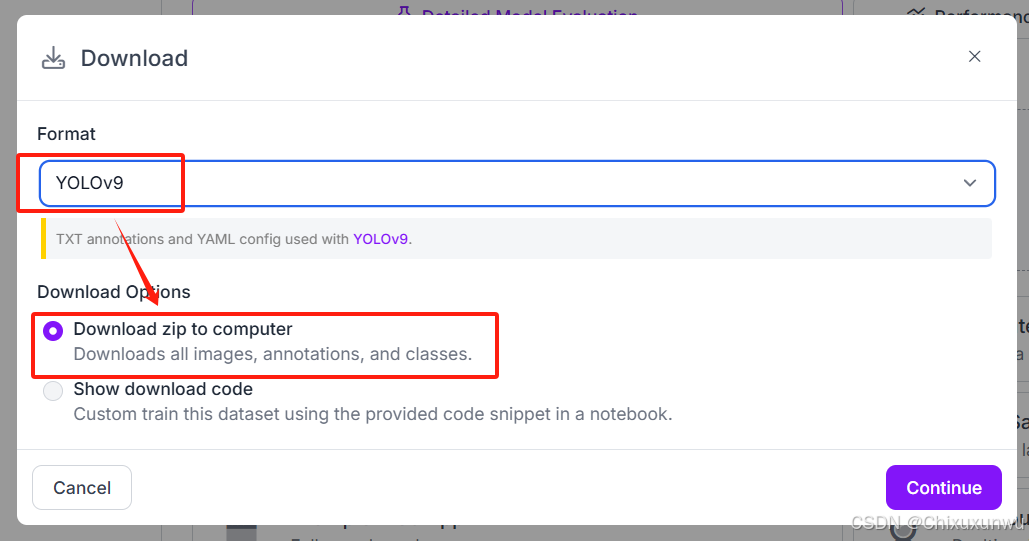
完成之后会变成这个界面,直接点击下载即可
上面我们可以选yolov9,下面直接选zip文件就可以了
经过上述步骤,我们就已经获得了Roboflow训练后的数据集,接下来我们还需要进行本地训练
八、本地训练最佳模型
1. 修改数据集中后缀为.yaml的文件
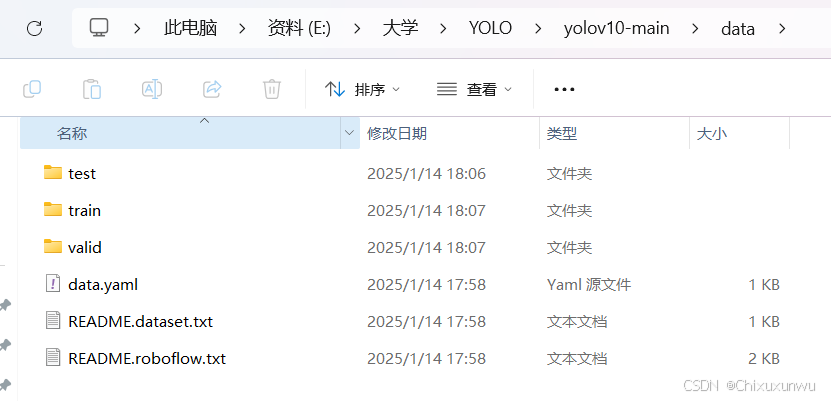
解压数据集后,里面的大致结构如下图所示
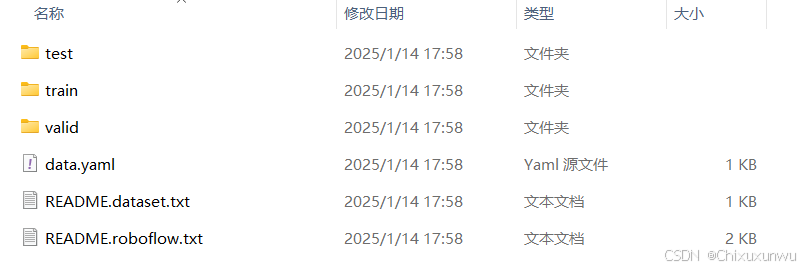
我们在项目文件的根目录下面建一个data的文件夹,把解压后的数据集放到里面
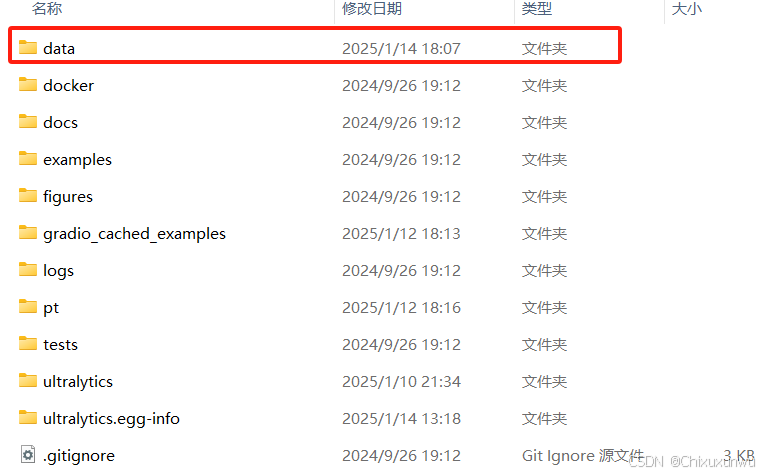
接下来我们需要打开VScode修改data.yaml这个文件。在根目录下找到这个文件并打开
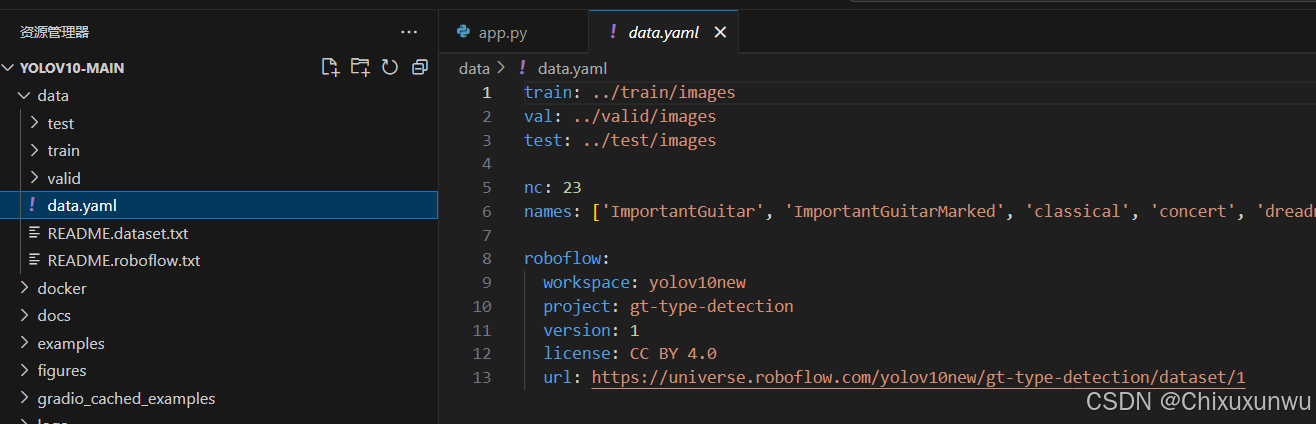
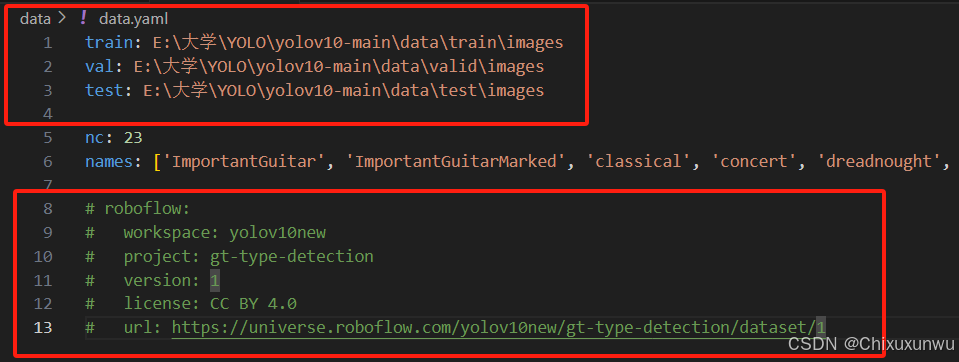
我们需要把train, val和test这三个路径改成自己文件夹的路径,我这边用的是绝对路径
并且我们还需要把下面这段内容给注释掉 (记得保存)
2. 查看C盘中的字体文件以及修改其中后缀为.yaml的文件
在查看之前一定要记得把这两个选项打开,因为AppData是隐藏文件夹
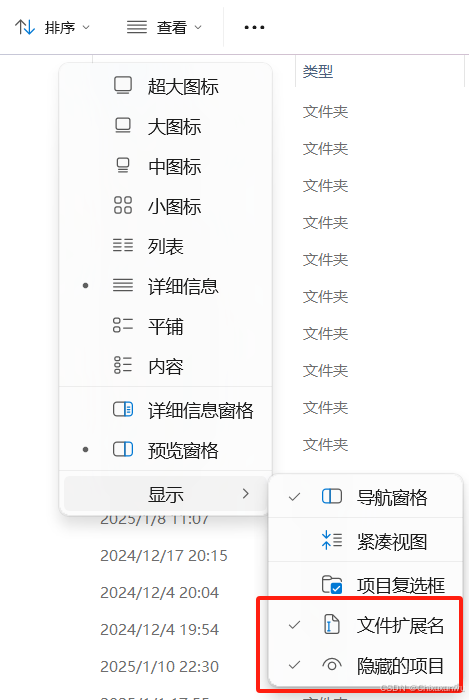
如下图,根据上面的路径可以找到下面的文件(这个文件我也会放到网盘里,自己电脑上没有的直接下载后放到这个路径下即可,不然后面本地训练模型的时候下载字体文件很有可能会卡死报错)
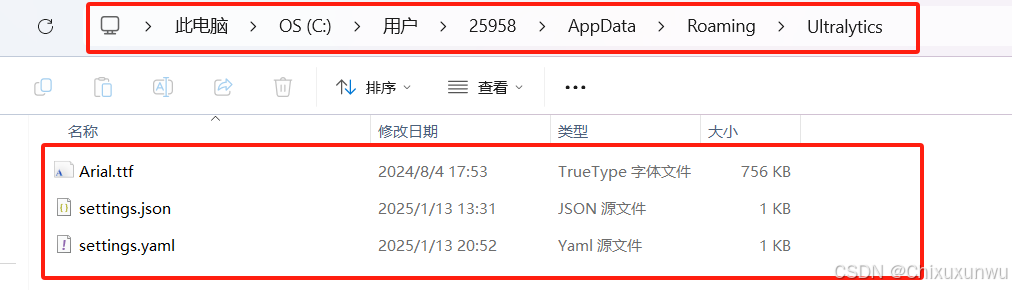
用VScode打开.yaml文件,把datasets_dir冒号后面改成 . 即可(记得保存)
3. 训练前检查pytorch有没有安装成功
在VScode中点击左上方的终端,打开一个新的终端
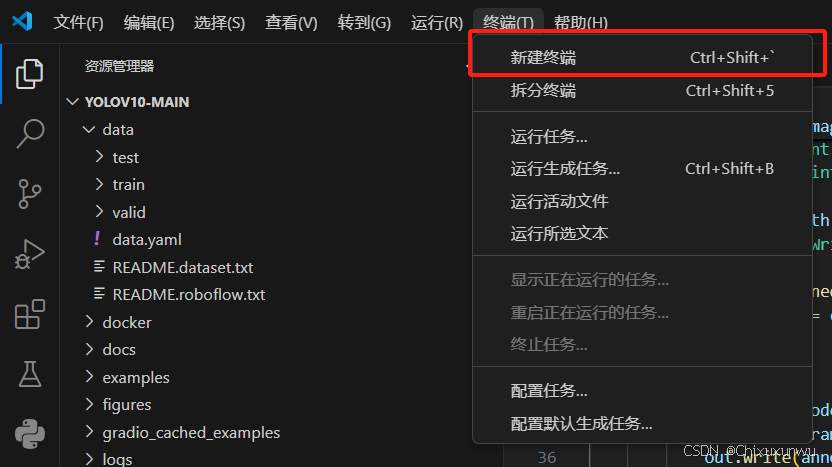
此时下面终端这里显示的是PS,我们想要让这里和之前命令行中的一样,以(yolov10)开头
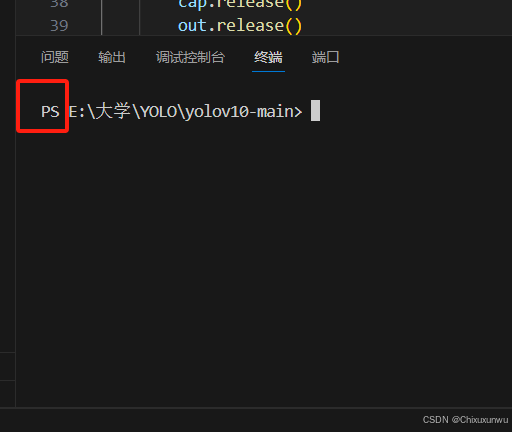
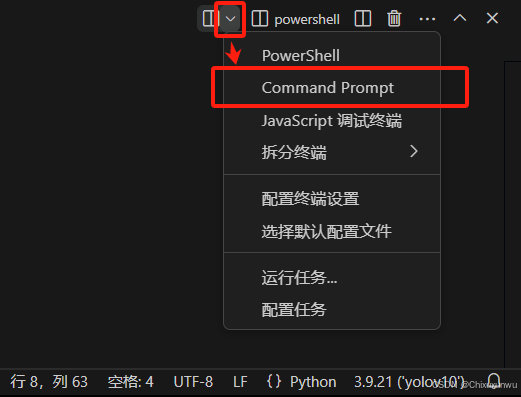
点击终端右侧如下图的按钮,选择命令提示符的这个选项。就可以达到我们想要的效果
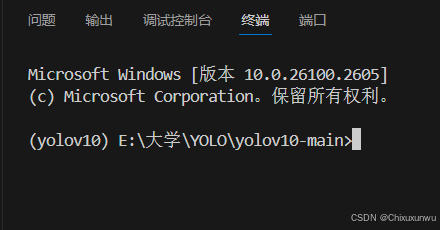
先输入python

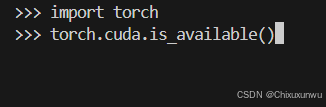
再引用torch这个库,调用torch.cuda.is_available()这个函数,结果是True则没问题。再输入exit()进行退出即可
4. 修改训练代码
训练代码可以参考这里给出的示例
yolo detect train data=E:\大学\YOLO\yolov10-main\data\data.yaml model=yolov10n.pt epochs=128 batch=30 imgsz=640 device=01): data后面的路径根据自己data.yaml存放的路径进行修改
2): model这里不一定要用n,几个官方模型都是可以的。
3): epochs设置的是训练的次数
4): batch根据自己显卡和内存的性能来就行,我是4060的笔记本,设置24时gpu的占用率在85%左右。imgsz这个不用改
5): device=0即调用一块显卡
5.进行训练
看到类似下图的结果,进度条在走并且Epoch在递增,即跑的没问题,等跑完就行了

可能碰到的问题
1) 权重文件未找到:
本人第一次跑也遇到了这样的问题,最后发现是Ultralytics没更新导致的
参考前面在VScode中打开命令提示符,输入下面的指令
pip install -U ultralytics更新后即可正常运行
2): 安装字体或yolov8模型不成功:
第一次训练时,会自动下载字体和yolov8的模型。但是经常下载不成功,亲测挂梯子下载会更容易一点
6. 应用训练文件
在如图所示的路径出找到best.pt文件并复制到根目录
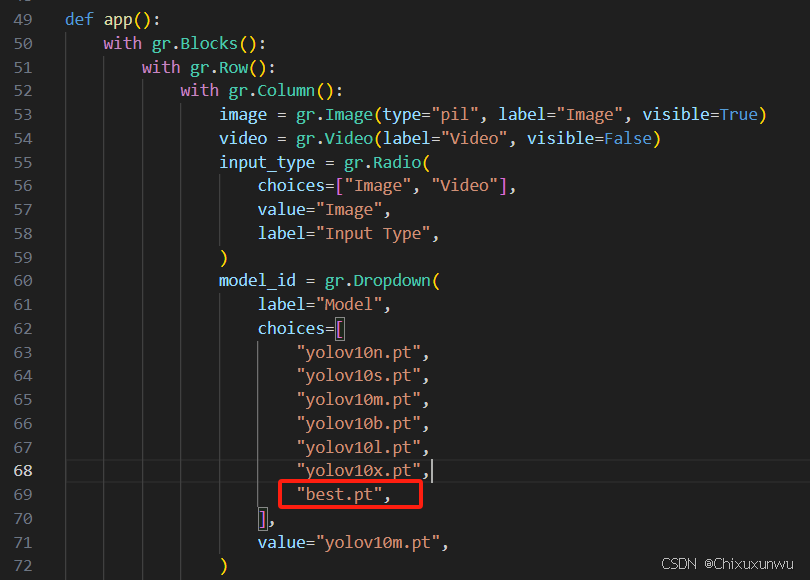
在app.py中找到下图的这个函数并且在choices中加一个best.pt
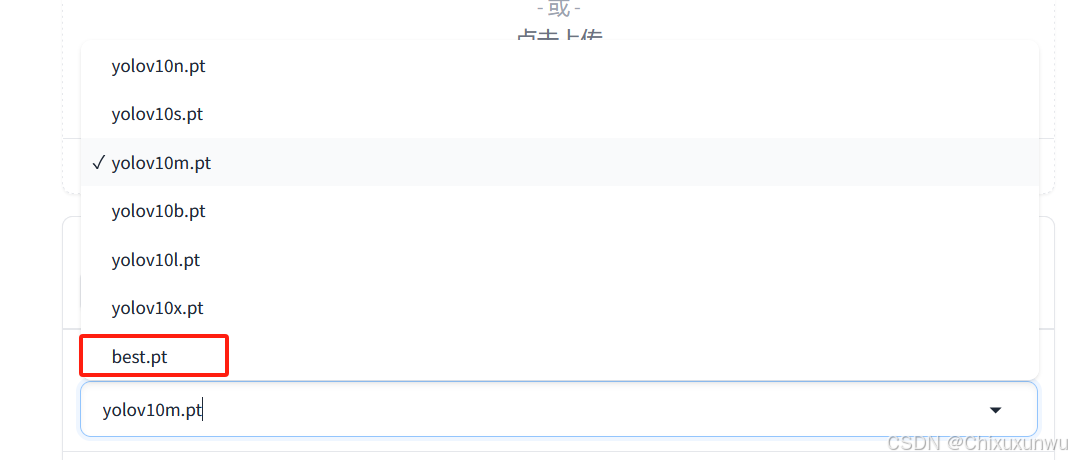
7.测试效果
运行app.py,在网页中找到这个最佳模型。网上找一张图片进行测试
可以识别出st琴型和单单双拾音器,还是挺准确的

九、相关资料网盘链接
链接:https://pan.quark.cn/s/a2f10fdda5c6
提取码:9C91

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









