 测试ppyoloe小样本能力,10张图精度达69.8%
测试ppyoloe小样本能力,10张图精度达69.8%







近期公司有个项目,需要解决长尾样本的问题,所以测试了一下paddlepaddle小样本的能力。
环境::T4 、ubuntu 、cuda-11.6 、py3.9、 paddlepaddle-gpu==2.6.0、pip install opencv-python==4.5.5.64 -i https://pypi.tuna.tsinghua.edu.cn/simple 、 pip install numpy==1.23.0
预训练模型:ppyoloe_crn_s_obj365_pretrained.pdparams
数据集下载地址:五种水果目标检测数据集coco格式_数据集-飞桨AI Studio星河社区
1、数据集准备五种水果:蕃茄、核桃、桔子、龙眼、青枣。共300张图像,640*480.COCO格式

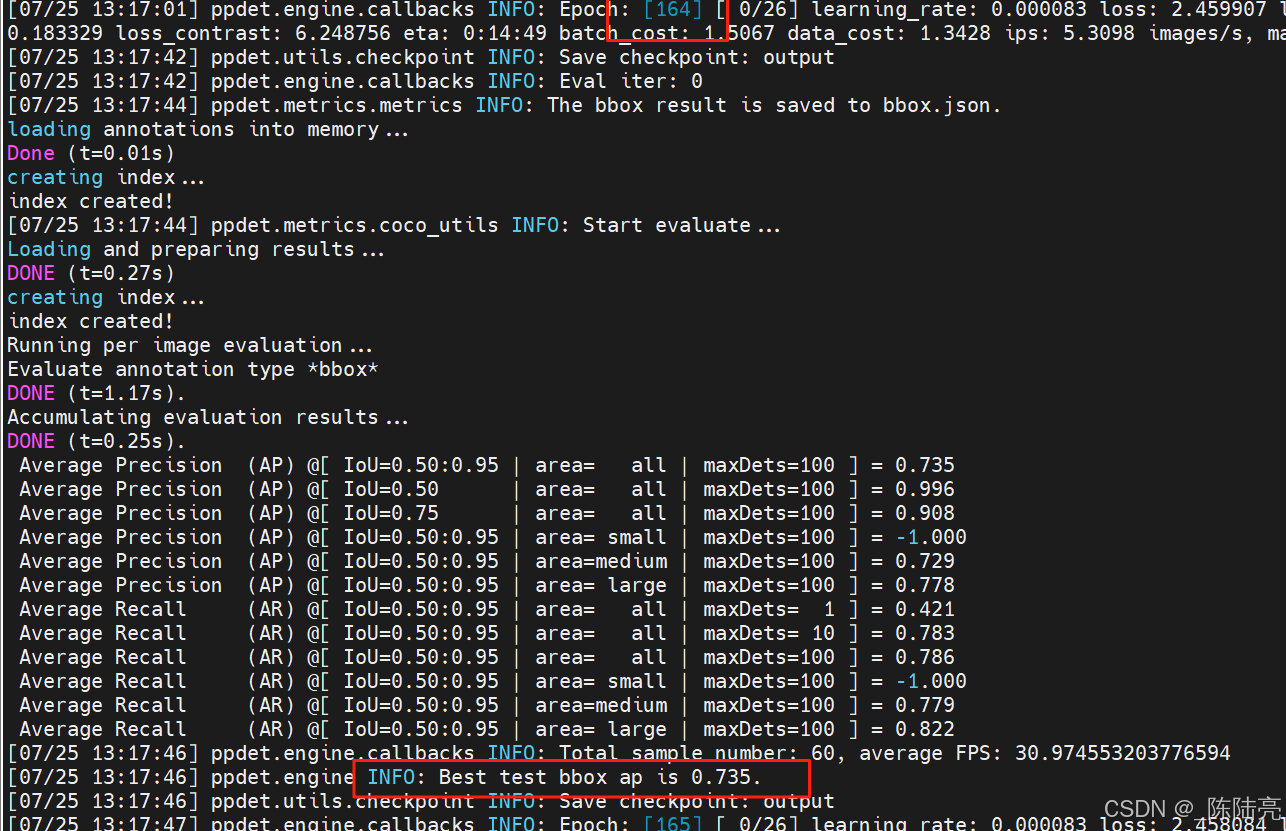
2、先正常训练一波
数据如下:165步0.735的%表现
3、用脚本每个coco类别从原train.json提取10张图片,代码:
import json
from collections import defaultdict
import argparse
import os
def create_small_sample_coco(original_json, output_json, samples_per_class=10):
"""
从COCO格式的标注文件中,为每个类别提取指定数量的样本,并生成新的COCO标注文件
参数:
original_json (str): 原始COCO标注文件路径
output_json (str): 输出的小样本COCO标注文件路径
samples_per_class (int): 每个类别提取的样本数量
"""
# 加载原始标注数据
with open(original_json, 'r', encoding='utf-8') as f:
coco_data = json.load(f)
# 确保必要的字段存在,不存在则添加默认值
required_fields = {
'info': {'description': 'Small sample dataset'},
'licenses': [{'id': 0, 'name': 'Unknown'}],
'categories': [],
'images': [],
'annotations': []
}
for field, default in required_fields.items():
if field not in coco_data:
print(f"警告: 标注文件缺少 '{field}' 字段,将使用默认值")
coco_data[field] = default
# 1. 统计每个类别的标注数量
category_counts = defaultdict(int)
for ann in coco_data['annotations']:
cat_id = ann['category_id']
category_counts[cat_id] += 1
# 检查是否有类别
if not category_counts:
print("错误: 标注文件中未找到任何类别或标注")
return
# 2. 为每个类别选择指定数量的样本
selected_images = set() # 存储被选中的image_id
category_samples = defaultdict(int) # 记录每个类别已选择的样本数
for ann in coco_data['annotations']:
cat_id = ann['category_id']
img_id = ann['image_id']
# 如果该类别已选样本数不足,且该图片尚未被选中
if category_samples[cat_id] < samples_per_class and img_id not in selected_images:
selected_images.add(img_id)
category_samples[cat_id] += 1
# 检查是否所有类别都已选够样本
if all(count >= samples_per_class for count in category_samples.values()):
break
# 3. 筛选出被选中的图片及其标注
filtered_images = [img for img in coco_data['images'] if img['id'] in selected_images]
filtered_annotations = [ann for ann in coco_data['annotations'] if ann['image_id'] in selected_images]
# 4. 构建新的COCO数据集
small_coco = {
'info': coco_data['info'],
'licenses': coco_data['licenses'],
'categories': coco_data['categories'],
'images': filtered_images,
'annotations': filtered_annotations
}
# 5. 保存新的标注文件
with open(output_json, 'w', encoding='utf-8') as f:
json.dump(small_coco, f, indent=2)
# 打印统计信息
print(f"成功创建小样本数据集!")
print(f"原始图片数量: {len(coco_data['images'])}")
print(f"筛选后图片数量: {len(filtered_images)}")
print(f"每个类别样本数: {samples_per_class}")
print(f"保存路径: {output_json}")
# 检查每个类别的实际样本数
actual_counts = defaultdict(int)
for ann in filtered_annotations:
actual_counts[ann['category_id']] += 1
# 映射类别ID到类别名称
id_to_name = {cat['id']: cat['name'] for cat in coco_data['categories']}
print("\n每个类别的实际样本数:")
for cat_id, count in actual_counts.items():
cat_name = id_to_name.get(cat_id, f"类别_{cat_id}")
print(f" {cat_name} (ID:{cat_id}): {count}个样本")
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='从COCO数据集中创建小样本数据集')
parser.add_argument('--input', '-i', required=True, help='原始COCO标注文件路径')
parser.add_argument('--output', '-o', required=True, help='输出的小样本COCO标注文件路径')
parser.add_argument('--samples', '-s', type=int, default=10, help='每个类别提取的样本数,默认为10')
args = parser.parse_args()
# 检查输入文件是否存在
if not os.path.exists(args.input):
print(f"错误: 输入文件 '{args.input}' 不存在")
exit(1)
# 检查输出目录是否存在,不存在则创建
output_dir = os.path.dirname(args.output)
if output_dir and not os.path.exists(output_dir):
os.makedirs(output_dir)
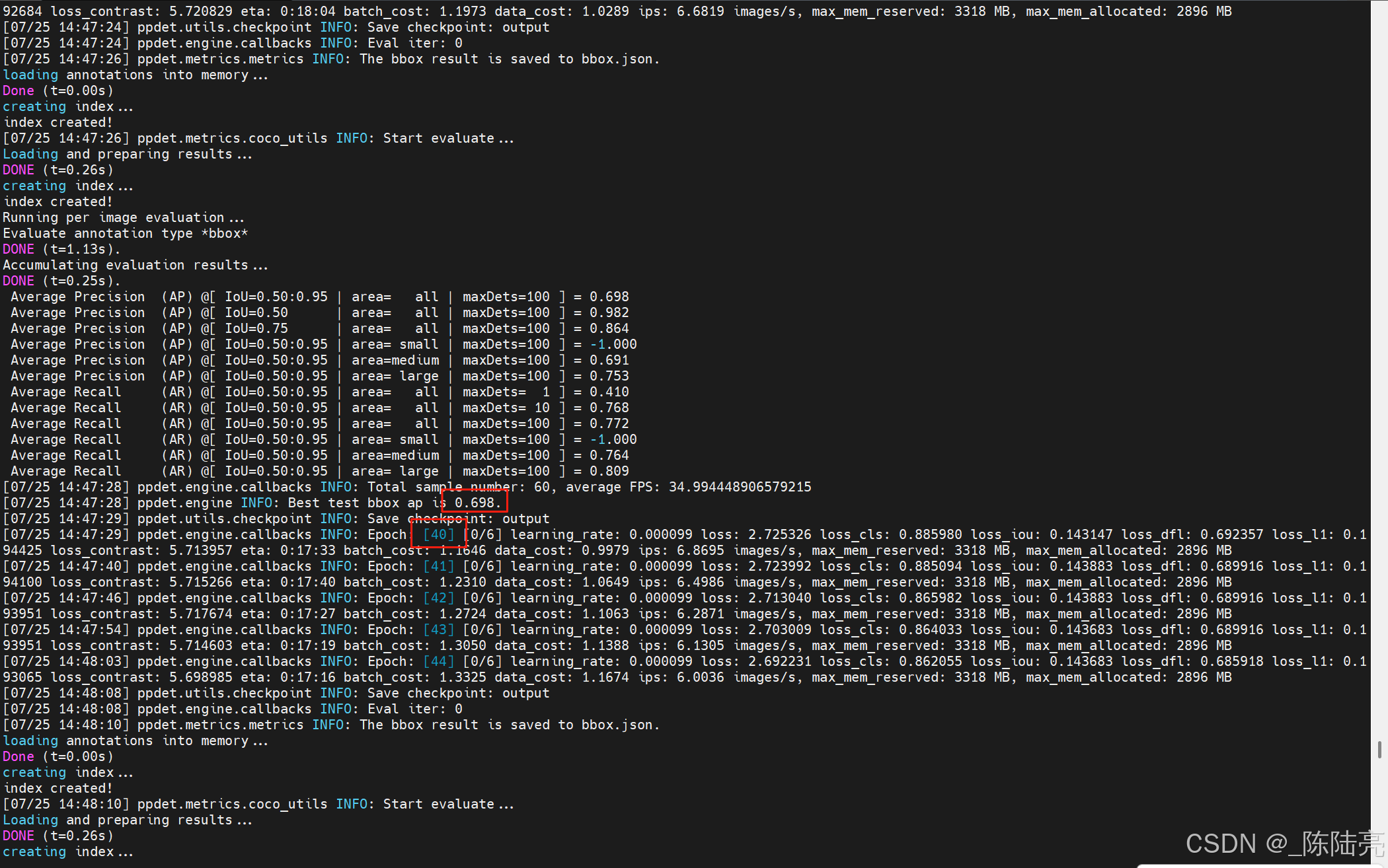
create_small_sample_coco(args.input, args.output, args.samples)4、再次训练
python tools/train.py -c configs/few-shot/ppyoloe_plus_crn_s_80e_contrast_pcb.yml --amp --eval --use_vdl=True --vdl_log_dir=./visdrone/在39步精度达到0.69%
5、预测一下
python tools/infer.py -c configs/few-shot/ppyoloe_plus_crn_s_80e_contrast_pcb.yml -o weights=output1/best_model.pdparams --infer_img=/home/PaddleDetection/dataset/coco/fruit5_coco/images/106.jpg

6、训练配置
_BASE_: [
'../datasets/coco_detection.yml',
'../runtime.yml',
'./_base_/optimizer_80e.yml',
'./_base_/ppyoloe_plus_crn.yml',
'./_base_/ppyoloe_plus_reader.yml',
]
log_iter: 100
snapshot_epoch: 5
weights: output/ppyoloe_plus_crn_s_80e_contrast_pcb/model_final
pretrain_weights: ./ppyoloe_crn_s_obj365_pretrained.pdparams
depth_mult: 0.33
width_mult: 0.50
epoch: 190
LearningRate:
base_lr: 0.0001
schedulers:
- !CosineDecay
max_epochs: 596
- !LinearWarmup
start_factor: 0.
epochs: 5
YOLOv3:
backbone: CSPResNet
neck: CustomCSPPAN
yolo_head: PPYOLOEContrastHead
post_process: ~
PPYOLOEContrastHead:
fpn_strides: [32, 16, 8]
grid_cell_scale: 5.0
grid_cell_offset: 0.5
static_assigner_epoch: 100
use_varifocal_loss: True
loss_weight: {class: 1.0, iou: 2.5, dfl: 0.5, contrast: 0.2}
static_assigner:
name: ATSSAssigner
topk: 9
assigner:
name: TaskAlignedAssigner
topk: 13
alpha: 1.0
beta: 6.0
contrast_loss:
name: SupContrast
temperature: 100
sample_num: 2048
thresh: 0.75
nms:
name: MultiClassNMS
nms_top_k: 1000
keep_top_k: 300
score_threshold: 0.01
nms_threshold: 0.7
num_classes: 5
metric: COCO
map_type: integral
TrainDataset:
!COCODataSet
image_dir: images
anno_path: /home/PaddleDetection/dataset/small.json
dataset_dir: /home/PaddleDetection/dataset/coco/fruit5_coco/
data_fields: ['image', 'gt_bbox', 'gt_class', 'is_crowd']
EvalDataset:
!COCODataSet
image_dir: images
anno_path: /home/PaddleDetection/dataset/coco/fruit5_coco/annotations/instance_val.json
dataset_dir: /home/PaddleDetection/dataset/coco/fruit5_coco/
TestDataset:
!ImageFolder
anno_path: /home/PaddleDetection/dataset/coco/fruit5_coco/annotations/instance_val.json
dataset_dir: /home/PaddleDetection/dataset/coco/fruit5_coco/



















 813
813

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











