




 本文介绍了人群密度估计的新数据集NWPU-Crowd,它是目前最大的人群计数数据集,包含多种复杂场景,提供公平的评估平台。文章还讨论了现有模型的挑战,如噪声抗性、类别间影响和极高密度估计,并介绍了C3F,一个基于Pytorch的开源人群计数框架,旨在促进该领域的研究。
本文介绍了人群密度估计的新数据集NWPU-Crowd,它是目前最大的人群计数数据集,包含多种复杂场景,提供公平的评估平台。文章还讨论了现有模型的挑战,如噪声抗性、类别间影响和极高密度估计,并介绍了C3F,一个基于Pytorch的开源人群计数框架,旨在促进该领域的研究。
人群密度估计-NWPU-Crowd数据集
该数据集是由Qi Wang等人于2020年1月10日公开,论文题为:NWPU-Crowd: A Large-Scale Benchmark for Crowd Counting.
数据集开源链接: http://www.crowdbenchmark.com/
论文开源代码链接:https://github.com/gjy3035/NWPU-Crowd-Sample-Code
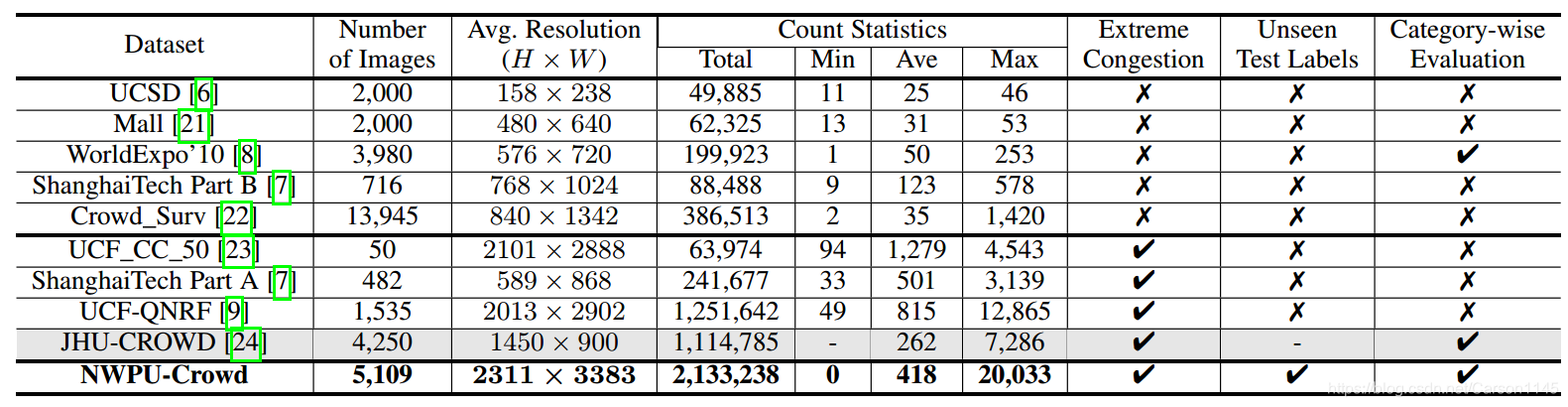
以往数据存在的问题
1. 数据集不足。基于CNN的方法都是需要庞大的数据集做支撑的,由于现存的人群密度数据集规模太小,基于深度学习的方法很难避免过拟合;
2. 没有一个相对公正的评价标准。像其他领域,KITTI,CityScapes和Microsoft COCO,允许研究人员提交测试集的结果进行公正的评价。所以一个公正的评价平台对于该领域的发展至关重要。
NWPU-Crowd数据集的优势
1. 目前为止在人群密度估计方面最大的数据集,拥有5109张图片和2133238个标注实体;
2. 内含一些负样本,比如极高密度的人群,这样可以提高训练模型的鲁棒性;
3. 图片的分辨率相比其他数据集更高;
4. 且单张图片的标注实体数量范围非常大,区间是[0,20033];
5. 提供了一个公平的平台网站,供研究人员提交测试集的计算结果,然后计算出MSE/MAE。
NWPU-Crowd与其他数据集的详细对比
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 38
38

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









