




 本文解析了神经网络的基本原理,包括逻辑回归、代价函数及其梯度计算,并通过实例展示了单层及多层神经网络的训练过程与效果对比。
本文解析了神经网络的基本原理,包括逻辑回归、代价函数及其梯度计算,并通过实例展示了单层及多层神经网络的训练过程与效果对比。
代价函数理解:
神经网络本质也是分类算法,但是比原来的逻辑回归复杂一点点。
所以其代价函数也只需要对逻辑回归的代价函数进行亿点点修改:
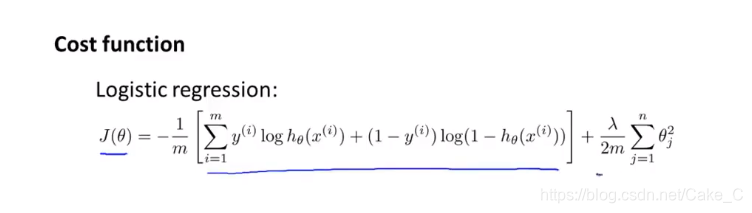
变成:
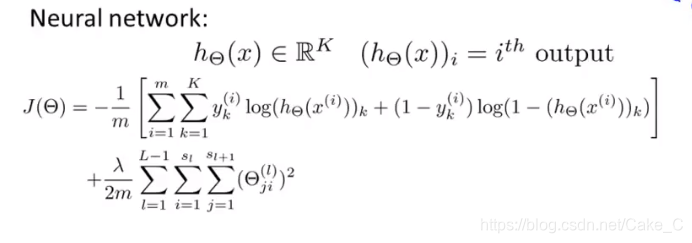
因为很长一下子接受不了,咱也是在草稿纸上演画了一会才懂:
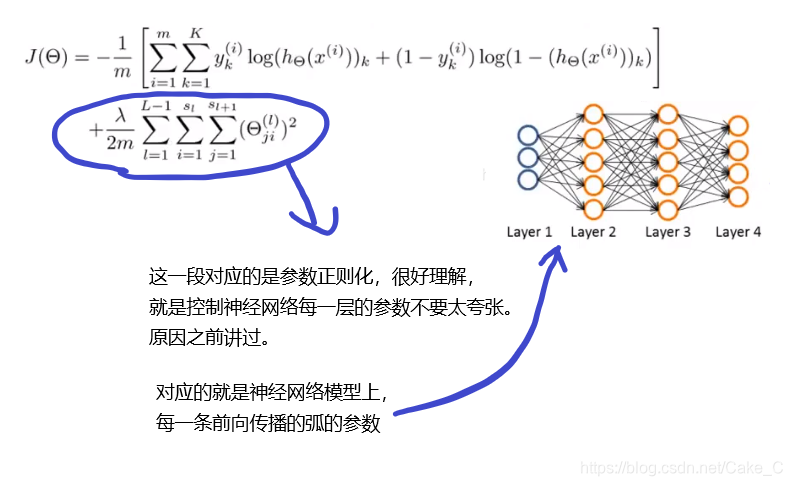
前面一大段求和看另外的图:
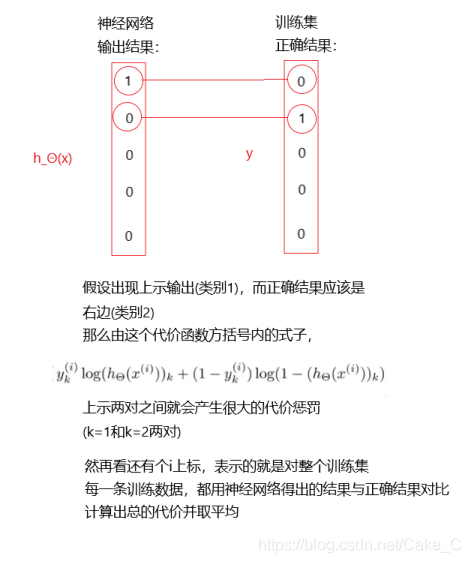
不过在真实的神经网络训练和测试中,至少在下面的简单的神经网络方法内,每个输出节点不可能完全为0或完全为1,此时认定最大的为1,其余为0。
这样一来,对神经网络的代价函数应该有了直观的印象和比较深刻的理解了。
那么之后对梯度下降应该能更好理解了。
数据预处理:
- 导包

- 载入训练集:(中文注释有详细解释)

- 写可视化函数以展示训练数据

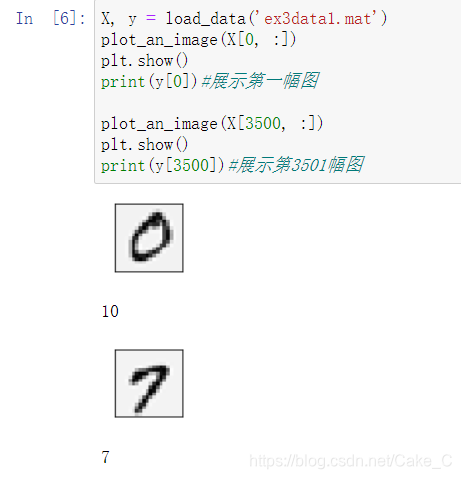
这是没有转置图片的效果:
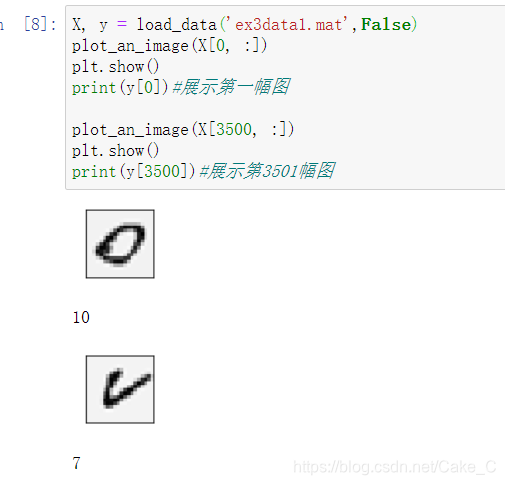
这里有个小注意点,因为在Matlab中下标是从1开始而非0,所以对图片0的结果用10来表示。(训练论文里是这么写的,因为这一点对训练数据集产生的影响还会在后面体现)
- 准备数据
每张图片的第一个位置前插入一个1,后面就知道这里其实是在添加偏置项Θ0

然后这边做了不少事情,看后面画的图

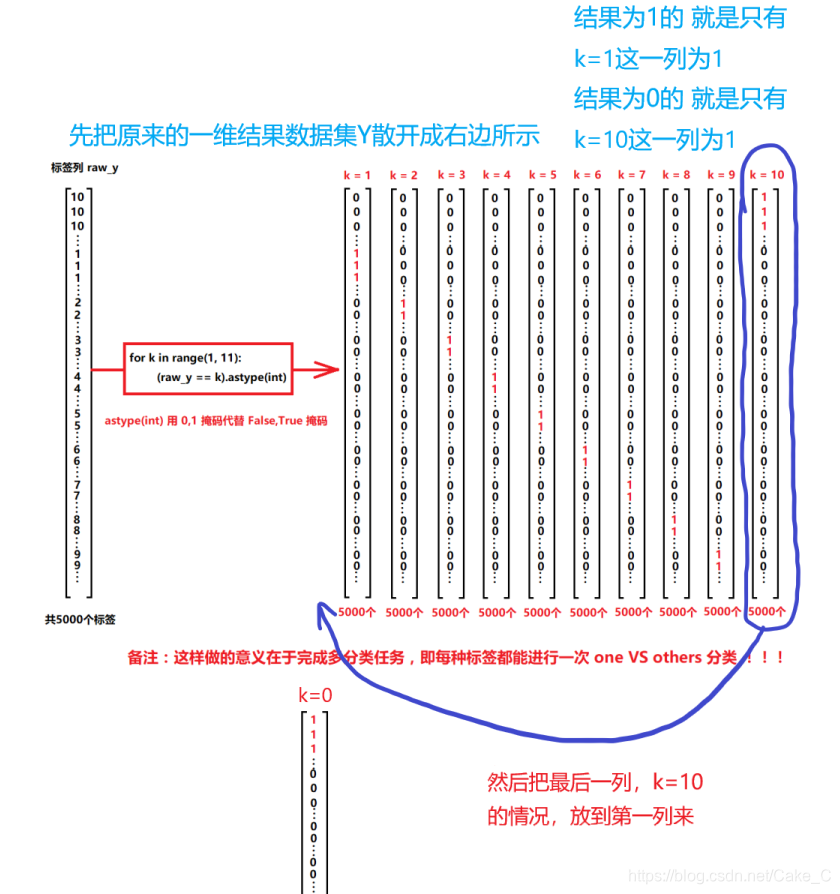
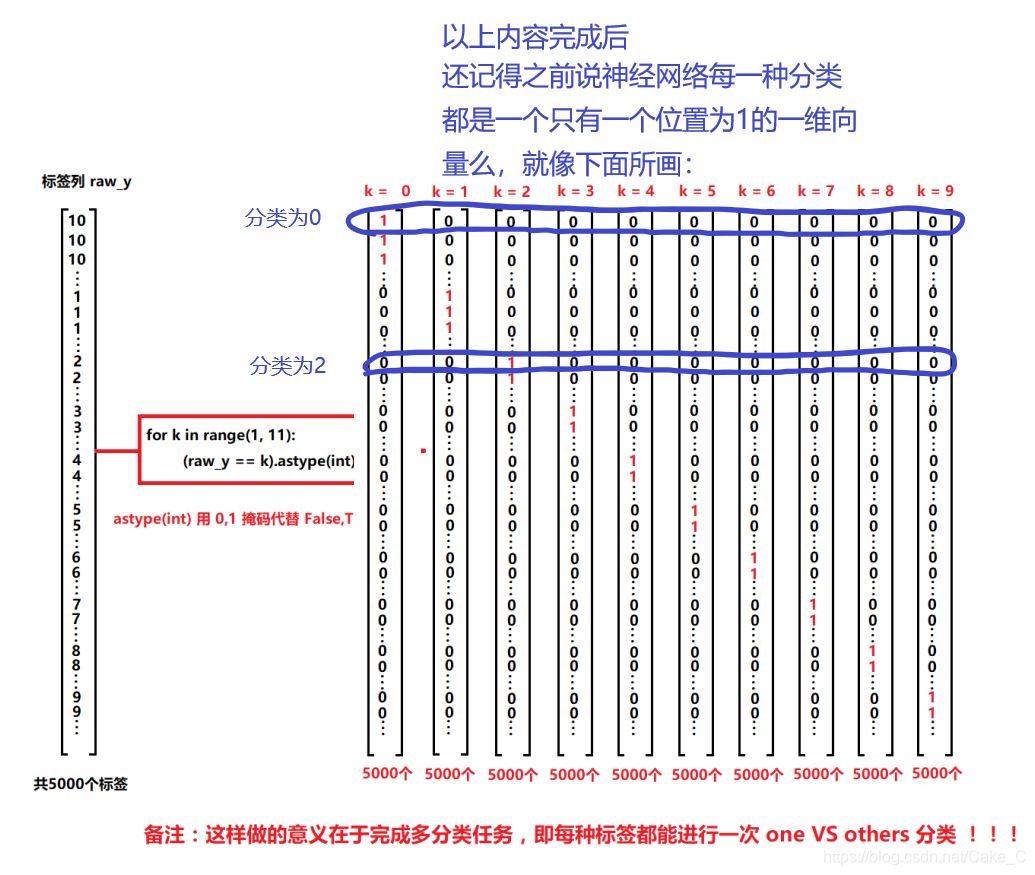
上面一通乱搞后,y就变成了下面的向量组形式,每一列为一个神经网络输出类别
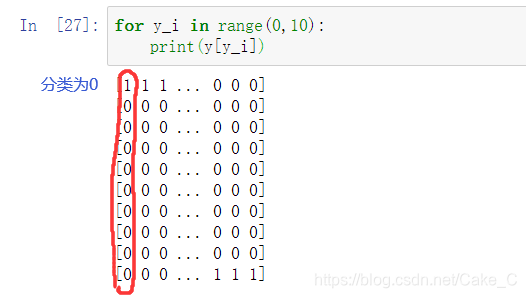
神经网络模型:
-
首先我们对训练模型进行一个顶层的把握:
对于这篇笔记里面的神经网络,我稍加思索,整体把握,发现这实际上是一个隐藏层为0的神经网络,也就是读入特征后直接就能计算输出结果向量了——所以这完全就是逻辑回归嘛!改变就没有中间层。所以考虑之后自己改一改多改几个隐藏层出来。
此外,
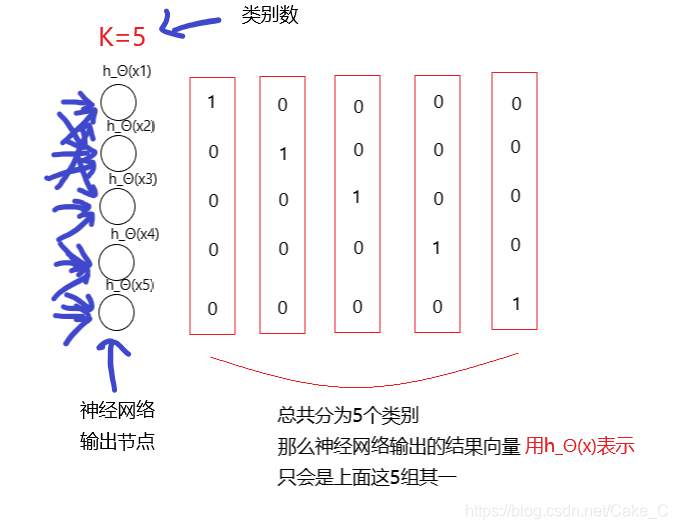
开头说神经网络是一种多维的分类算法,其本质还只是二维的01分类算法(0和1都是有效分类结果)
只不过每一次训练跑K次01分类就变成了K维分类算法。(这时每个分类结果用含有1个1的向量表示,整体表示一个有效分类结果)
因此先要对01分类有一个把握: -
这一段是计算这一坨东西的,但是其中K=1,代表就是01分类的代价函数求和项。
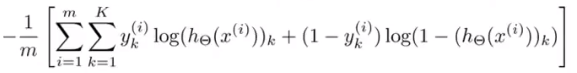

-
这里则是计算代价函数正则项,代码注释意思是对Θ0不进行正则限制。
同时在返回的时候计算前面的求和项,结果加起来一起返回出去
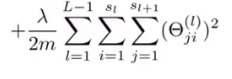
(内l是小写L表示λ,神他妈看成1)

-
因为没有隐藏层,所以实际上参数列表(Θ矩阵)只有一维,作为一个逻辑回归看待的话,梯度计算就很简单了:
逻辑回归的sigmoid函数

求和的梯度:

正则化的梯度:
中间有一句注释,表示就是其后一句语句所做事情的解释
具体内涵就是在正则化带来的Θ改变量向量(也就是带来的参数改变量数组)前加上一个0,表示不对Θ0进行正则化的修改。

-
上面代价函数也有了,梯度计算也有了,可以像之前一样调用一个自动优化函数帮助我们直接降低代价函数咧:
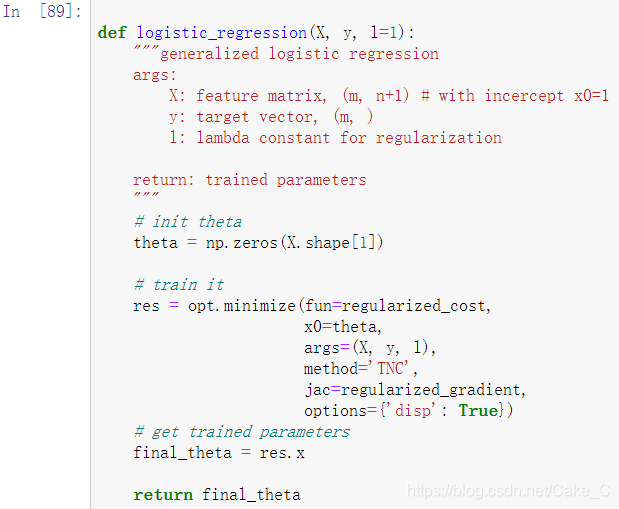
-
最后训练得到模型(其实就是一个Θ一维向量)
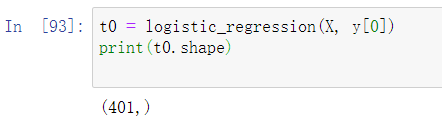
-
写一个简单的预测函数拿来预测


-
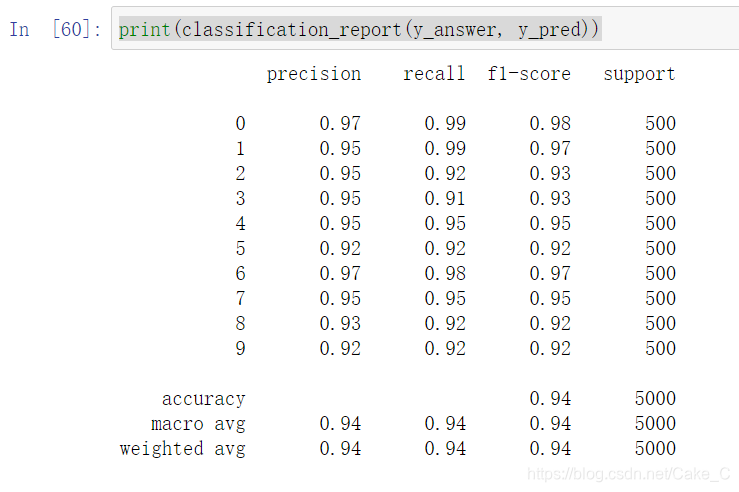
但是这种情况下,它只能识别是否是数字0:
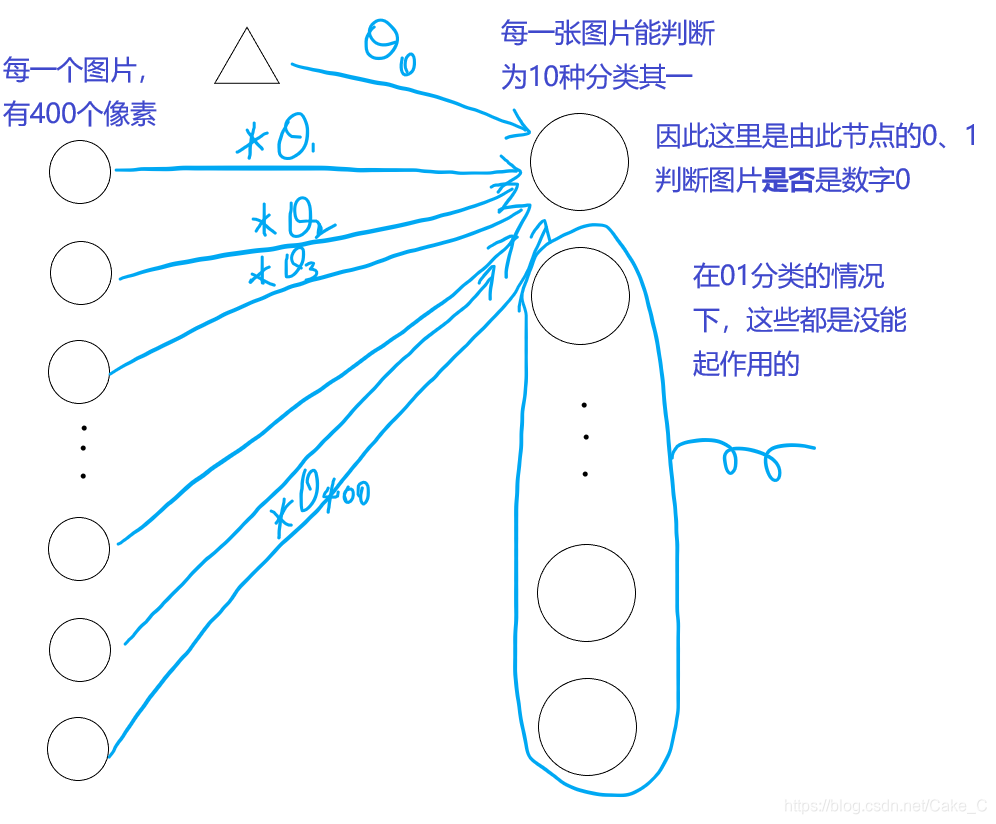
-
让它从01分类变成10维分类的方法,就是直接让整个模型对每一个输出节点跑一边上述训练:
(图中箭头的Θ参数都是不一样的。)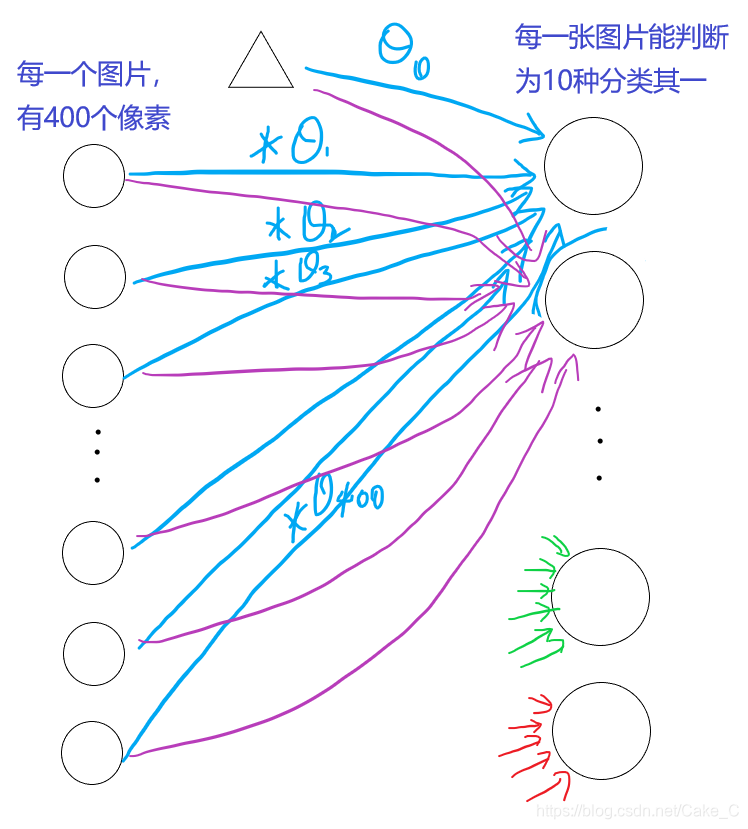
对应到代码里面:

-
形成了10*401的训练参数列表,训练完后,就可以测试预测了:
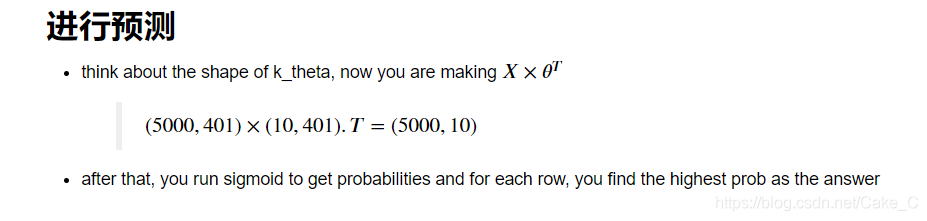
这段废话就是讲在这个没有隐藏层的模型下,可以直接用X(5000,401)与参数列表(401,10)做矩阵乘法,得到5000张图片各自的神经网络输出向量。
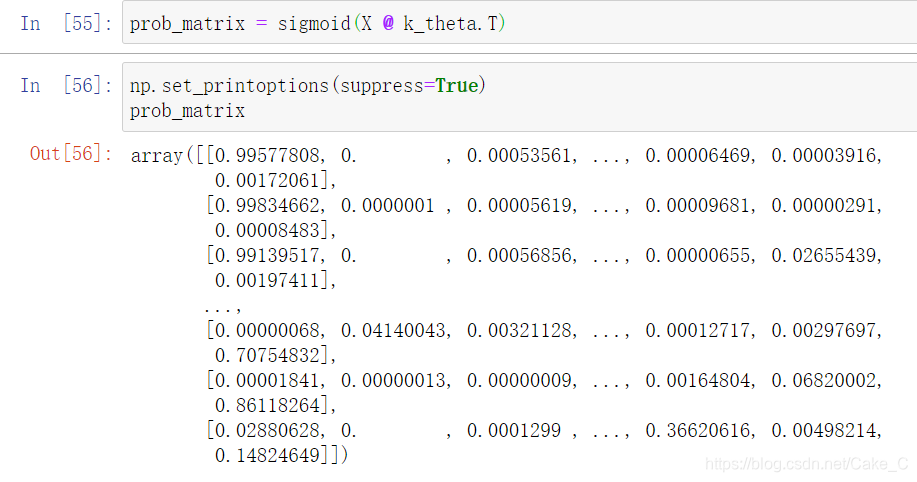
其每一行都是一组神经网络输出向量,某一行下标为 i 的值表示该行对应图片的数字为 i 的可能性。
含有隐藏层的神经网络模型:
这里因为没有讲到反向传播,所以只先体验一下前向传播的流程,其实和上面是一样一样的
- 这里就是两次隐藏层
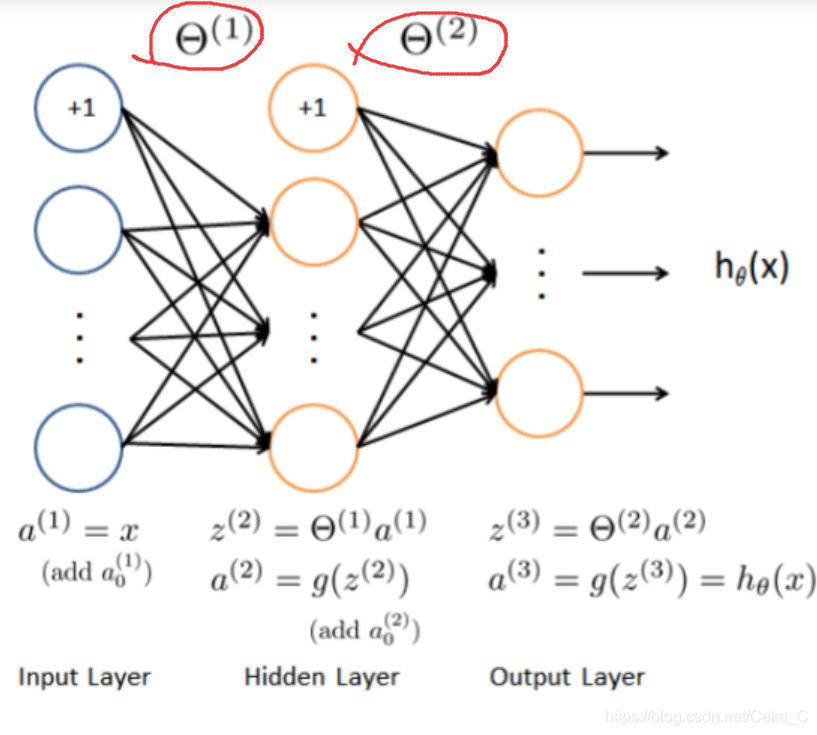
代码:
直接读取训练好的模型,Θ1和Θ2两组。
一个为(25401) 表示从一个400个特征的图片加一个偏置单元的图片,转化到25个特征的小一点的中间层,
另一个为(1026) 表示从25个特征的中间层加一个偏置单元,转化为10个输出节点值,组成神经网络输出向量。

然后这个训练好的模型是用的没有把图片转置的原始数据,所以重新读入一下数据

跑一边第一层,原来5000张图,每张400个特征+1的数据,变成5000张图,每张特征提取到25个。

提取到25个后加一个偏置单元(适应训练好的模型中偏置单元的出度),
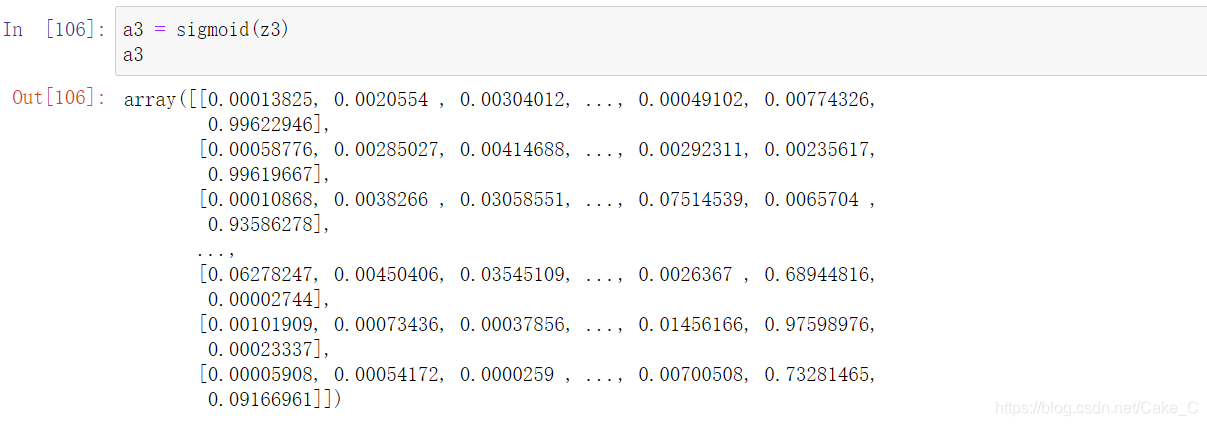
然后跑一边第二层

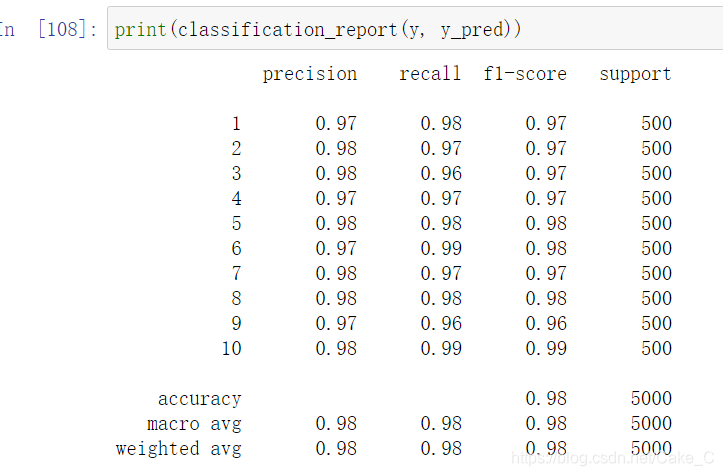
输出结果就是这样了
对于这个数据集,用没有隐藏层的神经网络模型和有一层神经网络模型的输出结果精确度比较
还是有一层的来的比较强一点

















 557
557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









