






一、bert-base-chinese
bert-base-chinese是一款基于 BERT(Bidirectional Encoder Representations from Transformers)架构的预训练语言模型,专为中文自然语言处理任务而设计。BERT 是 Google 于 2018 年推出的具有开创性的预训练模型,借助大规模无监督训练方式,得以学习到极为丰富的语言表示。bert-base-chinese是 BERT 在中文语料上完成预训练的版本,内部包含 12 层 Transformer 编码器,拥有 110 万个参数。该模型在海量中文文本上进行了大规模预训练,因此可广泛应用于各类中文自然语言处理任务,诸如文本分类、命名实体识别、情感分析等等。
在运用bert-base-chinese模型时,既能够将其当作特征提取器,把输入文本转化为固定长度的向量表示,随后将这些向量输入至其他机器学习模型中开展训练或推断;也能够对bert-base-chinese进行微调,使其适配特定任务的训练。预训练的bert-base-chinese模型可通过 Hugging Face 的 Transformers 库来加载与使用。模型加载完毕后,可利用其encode方法将文本转换为向量表示,或者运用forward方法针对文本进行特定任务的预测。需留意的是,bert-base-chinese属于通用型中文语言模型,在某些特定任务上或许难以展现出卓越性能。在部分情形下,可能需要采用更大规模的模型,亦或是进行微调操作,以此获取更为理想的性能表现。
本文就将介绍如何微调bert-base-chinese模型来实现文本分类。
二、bert-base-chinese文本分类
我们先来看看bert-base-chinese模型文本分类的效果。代码如下:
BertForSequenceClassification是transformers库中用于序列分类任务的一个类。它基于 BERT 模型进行构建,主要用于将输入的序列(比如文本)分类到不同的类别中。这里将他分到三个类别中。同时下载他的分词器来进行分词。以此来构建基础模型。
from transformers import BertTokenizer, BertForSequenceClassification, AutoModelForSequenceClassification,
AutoTokenizer, pipeline
model = BertForSequenceClassification.from_pretrained('bert-base-chinese', num_labels=3)
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
classifier = pipeline('text-classification', model=model, tokenizer=tokenizer)
output = classifier('我今天心情很好')
print(output)
output = classifier('你好,我是AI助手')
print(output)
output = classifier('我今天很生气')
print(output)
输出如下:
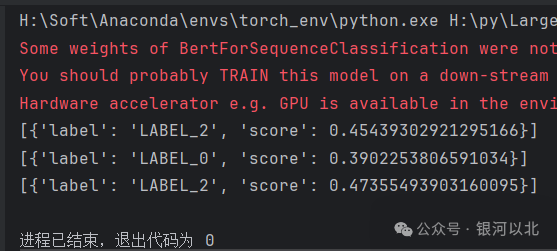
可以发现bert-base-chinese在实现文本分类的时候效果并不是很好。接下来,我们对该模型进行微调以实现文本分类。
三、bert-base-chinese微调
首先我们需要通过同样的方法来构建基础模型。然后通过语料样本来进行微调。这里我们使用lansinuote/ChnSentiCorp数据集。
lansinuote/ChnSentiCorp数据集是一个用于中文情感分析的数据集。该数据集汇集了来自网络平台的多样化评论数据,主要覆盖三大领域:酒店住宿体验、笔记本电脑使用评价以及书籍阅读感受。数据集分为训练集、验证集和测试集。其中,训练集包含约 9600 条数据,验证集和测试集各包含约 1200 条数据。每条数据包含一段评论文本和对应的情感标签,情感标签通常为二分类(如好评、差评),部分版本可能包含中性标签。
将lansinuote/ChnSentiCorp数据集下载之后,使用模型的分词器对其进行处理,将处理之后的数据放入模型进行训练,我们仅训练1轮看看效果。训练完之后再测试集上进行预测查看训练效果。并将模型保存。实现代码如下。
from transformers import BertTokenizer, BertForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset
import re
from sklearn.metrics import accuracy_score
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
mode = BertForSequenceClassification.from_pretrained('bert-base-chinese', num_labels=3)
dataset = load_dataset('lansinuote/ChnSentiCorp')
def clean_text(text):
text = re.sub(r'[^\w\s]+', ' ', text)
text = text.strip()
return text
dataset = dataset.map(lambda x: {'text': clean_text(x['text']), 'label': x['label']})
def tokenize_function(examples):
return tokenizer(examples['text'], padding='max_length', truncation=True, max_length=128)
encoded_dataset = dataset.map(tokenize_function, batched=True)
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=1,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
evaluation_strategy='epoch',
logging_dir='./logs'
)
trainer = Trainer(
model=mode,
args=training_args,
train_dataset=encoded_dataset['train'],
eval_dataset=encoded_dataset['validation'],
)
trainer.train()
trainer.evaluate(encoded_dataset['test'],metric_key_prefix='eval')
mode.save_pretrained('./sentiment_model')
tokenizer.save_pretrained('./sentiment_model')
训练效果如下,我们可以发现经过一轮训练,验证集上的loss降低到了0.2。
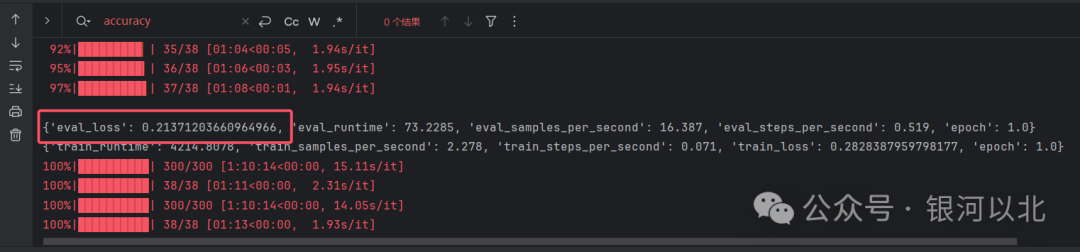
接下来我们使用训练之后的模型来对之前的语句进行评分,只需要加载训练之后的模型就好。代码实现如下:
from transformers import BertTokenizer, BertForSequenceClassification, AutoModelForSequenceClassification, \
AutoTokenizer, pipeline
mode_dir = './sentiment_model'
model = AutoModelForSequenceClassification.from_pretrained(mode_dir)
tokenizer = BertTokenizer.from_pretrained(mode_dir)
classifier = pipeline('text-classification', model=model, tokenizer=tokenizer)
output = classifier('我今天心情很好')
print(output)
output = classifier('你好,我是AI助手')
print(output)
output = classifier('我今天很生气')
print(output)
效果如下:
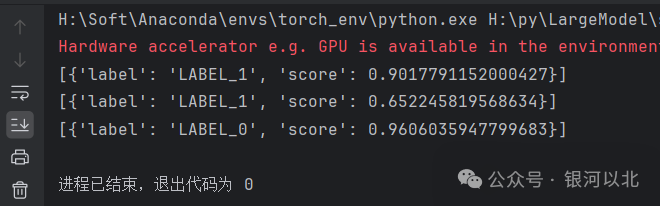
我们可以发现,使用lansinuote/ChnSentiCorp数据集对模型训练之后,模型在对文本分类方面的能力得到了大幅加强。
四、总结
模型微调只是针对某种下游任务,针对性的强化模型的能力,但是微调之后的模型在泛化能力上有所下降。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料。包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓

👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程扫描领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程扫描领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程扫描领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程扫描领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程扫描领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
这份完整版的 AI 大模型学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓

















 1458
1458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









