






 本文探讨了多模态情感分析的新进展,提出一种多交互记忆网络,专门针对方面层面的情感理解,捕捉文本、图像数据的多重相关性,填补了现有研究的空白。
本文探讨了多模态情感分析的新进展,提出一种多交互记忆网络,专门针对方面层面的情感理解,捕捉文本、图像数据的多重相关性,填补了现有研究的空白。
随着多模态用户生成内容(如文本和图像)在互联网上的流行,多模态情感分析近年来受到了越来越多的研究关注。在方面层面的情感分析中,多模态数据通常比纯文本数据更重要,并且具有各种相关性,包括该方面对文本和图像带来的影响,以及与文本和图像相关的交互作用。然而,到目前为止,在方面层面和多模态情感分析的交叉点上还没有进行任何相关的工作,因此本文提出了方面级情感分析任务。
本文贡献:
(1)填补了方面级情感分析和多模态情感分析之间的空白。
(2)提出了一种多交互记忆网络来捕获多模态数据中的多重相关性。
模型:
本文的整体流程图如下所示,值得注意的是模型共有3-hop,1-hop与2-hop和3-hop的输入不同。
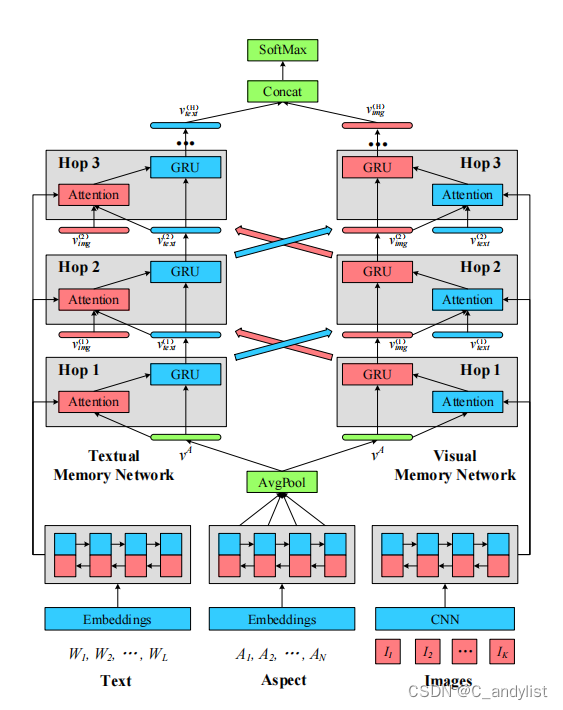
最左边代表文本的embediing,中间为方面项embedding,右面为图像的embedding。
文本的embedding:
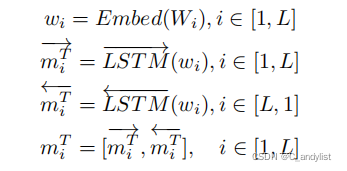
方面项的embedding:

特别的是本文为了消除多词影响?直接用了所有方面项单词的平均值:
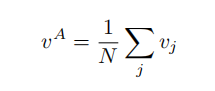
图像的embedding:
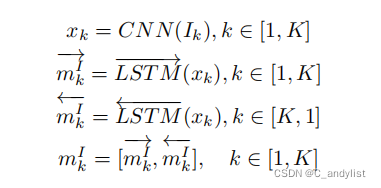
然后本文分别将方面项与文本和图像结合,我们仅给出与图像集合的公式,文本与其相似:
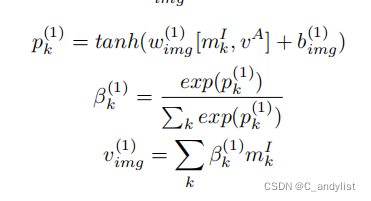
但本文的描述与模型图略有偏差,在第一层的没有GRU的计算,但在模型图中有,
然后是2-hop和3-hop的公式如下:
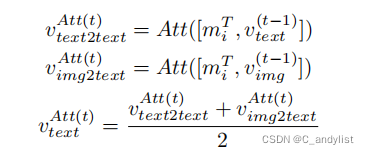
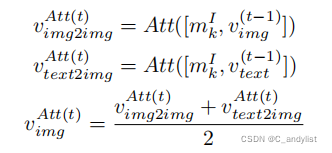
文本与图像的embedding中都包含有方面项信息,然后图-图,图-文,文-文,文-图按这个顺序来结合隐藏状态,之后将他们通过GRU连接起来:
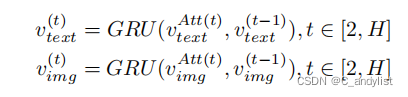
最后经过softmax来判断情感极性
![]()

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









